私の「ひざまずくパフォーマンスチューニング」シリーズとは別に、状況によってはインデックスの断片化がどのように発生するかについて説明したいと思います。
インデックスの断片化とは何ですか?
ほとんどの人は、「インデックスの断片化」を、インデックスリーフページの順序が乱れている問題を意味すると考えています。次のキー値を持つインデックスリーフページは、データファイル内で現在調査中のインデックスリーフページに物理的に隣接しているページではありません。 。これは論理的断片化と呼ばれます(そして、一部の人々はそれを外部断片化と呼びます-私が好きではない紛らわしい用語です)。
論理断片化は、インデックスリーフページがいっぱいで、挿入または既存のレコードを長くするために(可変長列の更新から)そのページにスペースが必要な場合に発生します。その場合、ストレージエンジンは新しい空のページを作成し、行の50%(通常は常にではありません)を全ページから新しいページに移動します。この操作は両方のページにスペースを作成し、挿入または更新を続行できるようにします。これはページ分割と呼ばれます。単一の操作からの繰り返しのページ分割と、インデックスレベルをカスケードするページ分割を含む興味深い病理学的ケースがありますが、これらはこの投稿の範囲を超えています。
ページ分割が発生すると、通常、割り当てられた新しいページが分割されているページと物理的に隣接している可能性が非常に低いため、論理的な断片化が発生します。インデックスに多くの論理的な断片化がある場合、リーフページがデータファイルに順番に保存されていない場合、必要なページの物理的な読み取りを効率的に(複数ページの「先読み」読み取りを使用して)実行できないため、インデックススキャンの速度が低下します。 。
これがインデックスの断片化の基本的な定義ですが、ほとんどの人が考慮していない2番目の種類のインデックスの断片化があります。ページ密度が低いことです(内部断片化と呼ばれることもありますが、これもわかりにくい用語です)。
ページ密度は、インデックスリーフページに保存されているデータ量の尺度です。通常の50/50の場合にページ分割が発生すると、各リーフページ(分割ページと新しいページ)のページ密度はわずか50%になります。ページ密度が低いほど、インデックス内の空き領域が増えるため、無駄になっていると考えることができるディスク領域とバッファプールメモリが多くなります。私は数年前にこの問題についてブログを書きました、そしてあなたはそれについてここで読むことができます。
2種類のインデックスの断片化の基本的な定義を示したので、これらをまとめて単に「断片化」と呼びます。
この投稿の残りの部分では、明らかに断片化を引き起こす操作(つまり、ランダムな挿入とレコードの更新が長くなる)を回避している場合でも、クラスター化インデックスが断片化される可能性がある3つのケースについて説明します。
削除からの断片化
「クラスター化されたインデックスリーフページから削除すると、どのようにしてページ分割が発生しますか?」あなたは尋ねているかもしれません。通常の状況ではそうはなりません(そして、奇妙な病的なケースがないことを確認するために数分間考えていました!しかし、以下のセクションを参照してください…)ただし、削除するとページ密度が徐々に低くなる可能性があります。
クラスタ化されたインデックスにbigintIDキー値がある場合を想像してみてください。そのため、挿入は常にインデックスの右側に配置され、インデックスの前の部分に挿入されることはありません(ID値を再シードする人を除いて–潜在的に非常に問題があります!)。ここで、ワークロードが不要になったレコードをテーブルから削除するとします。その後、バックグラウンドゴーストクリーンアップタスクによってページ上のスペースが再利用され、空きスペースになります。
ランダムな挿入がない場合(テーブルに対してSET IDENTITY INSERTを有効にした後で、誰かがIDを再シードするか、使用するキー値を指定しない限り、このシナリオでは不可能です)、削除されたレコードから解放されたスペースを新しいレコードが使用することはありません。これは、クラスター化されたインデックスの初期の部分の平均ページ密度が着実に減少し、前述のように無駄なディスクスペースとバッファープールメモリの量が増加することを意味します。
ページ密度を「断片化」の一部と見なす限り、削除によって断片化が発生する可能性があります。
スナップショットアイソレーションからの断片化
SQL Server 2005では、スナップショットアイソレーションと読み取りコミットスナップショットアイソレーションの2つの新しいアイソレーションレベルが導入されました。これら2つのセマンティクスはわずかに異なりますが、基本的には、クエリでデータベースの特定の時点のビューを表示し、ロックの衝突のない選択を行うことができます。これは非常に単純化されていますが、私の目的には十分です。
これらの分離レベルを容易にするために、私が率いたMicrosoftの開発チームは、バージョニングと呼ばれるメカニズムを実装しました。バージョン管理が機能する方法は、レコードが変更されるたびに、変更前のバージョンのレコードがtempdbのバージョンストアにコピーされ、変更されたレコードの最後に14バイトのバージョン管理タグが追加されることです。タグには、レコードの以前のバージョンへのポインターと、特定のクエリが読み取るレコードの正しいバージョンを判別するために使用できるタイムスタンプが含まれています。繰り返しになりますが、非常に単純化されていますが、関心があるのは14バイトの追加だけです。
したがって、これらの分離レベルのいずれかが有効なときにレコードが変更されると、レコードのバージョン管理タグがまだない場合は、レコードが14バイト拡張される可能性があります。インデックスリーフページに14バイトを追加するための十分なスペースがない場合はどうなりますか?そうです、ページ分割が発生し、断片化が発生します。
とにかくレコードが変更されているので、とにかくサイズが変更されていた場合は、ページ分割が発生した可能性があります。いいえ–このロジックは、レコードの変更が可変長列のサイズを増やすことであった場合にのみ保持されます。固定長の列が更新されても、バージョン管理タグが追加されます!
そうです。バージョン管理が行われているときに、固定長の列を更新すると、レコードが拡張され、ページの分割や断片化が発生する可能性があります。さらに興味深いのは、削除によって14バイトのタグも追加されるため、バージョニングが使用されているときにクラスター化されたインデックスで削除するとページ分割が発生する可能性があることです。
ここで重要なのは、いずれかの形式のスナップショットアイソレーションを有効にすると、以前は断片化の可能性がなかったクラスター化インデックスで突然断片化が発生し始める可能性があるということです。
読み取り可能なセカンダリからの断片化
最後に説明したいのは、SQLServer2012で追加された可用性グループ機能の一部である読み取り可能なセカンダリを使用することです。
読み取り可能なセカンダリを有効にすると、セカンダリレプリカに対して行うすべてのクエリは、内部でスナップショットアイソレーションを使用するように変換されます。これにより、リカバリコードが進行中にロックを取得するため、クエリがプライマリレプリカからのログレコードの継続的な再生をブロックするのを防ぎます。
これを行うには、セカンダリレプリカのレコードに14バイトのバージョン管理タグが必要です。ログの再生が機能するように、すべてのレプリカが同一である必要があるため、問題があります。まあ、完全ではありません。バージョン管理タグの内容は、それらを作成したインスタンスでのみ使用されるため、関連性がありません。ただし、セカンダリレプリカはバージョン管理タグを追加できず、レコードが長くなります。これにより、ページ上のレコードの物理的なレイアウトが変更され、ログの再生が中断されます。ただし、バージョン管理タグがすでに存在する場合は、何も壊さずにスペースを使用できます。
まさにそれが起こります。 Storage Engineは、プライマリレプリカに追加することで、セカンダリレプリカに必要なバージョン管理タグがすでに存在することを確認します。
データベースの読み取り可能なセカンダリレプリカが作成されるとすぐに、プライマリレプリカのレコードが更新されると、レコードに空の14バイトのタグが追加されるため、すべてのログレコードで14バイトが適切に考慮されます。 。タグは何にも使用されませんが(プライマリレプリカ自体でスナップショットアイソレーションが有効になっている場合を除く)、タグが作成されたためにレコードが拡張され、ページがすでにいっぱいになっている場合は…
はい、読み取り可能なセカンダリを有効にすると、プライマリレプリカでスナップショットアイソレーションを有効にした場合と同じ効果(フラグメンテーション)が発生します。
概要
GUIDをクラスターキーとして使用したり、テーブル内の可変長列を更新したりすることを避けているため、クラスター化インデックスが断片化の影響を受けないとは思わないでください。上で説明したように、クラスター化インデックスで断片化の問題を引き起こす可能性のある他のワークロードと環境要因に注意する必要があります。
ここで、ひざまずいて、レコードを削除したり、スナップショットアイソレーションを使用したり、読み取り可能なセカンダリを使用したりしないでください。それらはすべて断片化を引き起こす可能性があることを認識し、それを検出、削除、および軽減する方法を知っている必要があります。
SQLSentryにはクールなツールであるFragmentationManagerがあり、これをPerformance Advisorのアドオンとして使用して、断片化の問題がどこにあるかを把握し、それらに対処するのに役立てることができます。チェックすると、断片化に驚かれるかもしれません。簡単な例として、ここでは、個々のパーティションレベルに至るまで、断片化がどれだけ存在するか、どのくらいの速さでそのようになったか、存在するパターン、およびシステムの無駄なメモリに実際に与える影響を視覚的に確認できます。
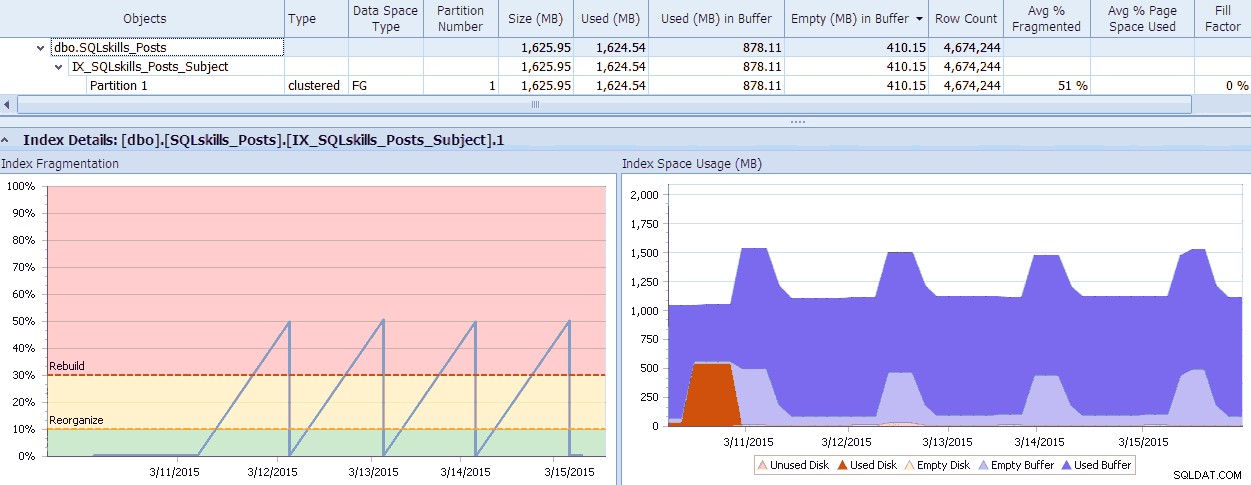 SQL Sentry Fragmentation Managerデータ(クリックして拡大)
SQL Sentry Fragmentation Managerデータ(クリックして拡大)
次の投稿では、断片化と、断片化を軽減して問題を軽減する方法について詳しく説明します。