実行プランにbツリーインデックス構造のスキャンが含まれている場合、ストレージエンジンは 計画の実行時に、2つの物理アクセス戦略から選択できます。
- インデックスのbツリー構造に従います。または、
- 内部ページ割り当て情報を使用してページを検索します。
選択肢がある場合、ストレージエンジンは実行ごとに実行時の決定を行います。プランの再コンパイルはありません 考えを変えるために必要です。
b-tree戦略は、ツリーのルートから始まり、リーフレベルの端まで下降し(スキャンが順方向か逆方向かによって異なります)、インデックスのもう一方の端に到達するまでリーフレベルのページリンクをたどります。 。割り振り戦略は、索引割り振りマップ(IAM)構造を使用して、索引に割り振られたデータベース・ページを検索します。各IAMページは割り当てを単一の物理データベースファイルの4GB間隔にマップするため、インデックスに関連付けられたIAMチェーンをスキャンすると、物理ファイルの順序でインデックスページにアクセスする傾向があります(少なくともSQL Serverが判断できる限り)。
2つの戦略の主な違いは次のとおりです。
- Bツリースキャンは、インデックスキーの順序でクエリプロセッサに行を配信できます。 IAM駆動型スキャンはできません。
- 論理的に隣接するインデックスページも物理的に隣接していない場合(たとえば、インデックスでのページ分割の結果)、bツリースキャンは大きな先読みI/O要求を発行できない場合があります。
インデックスに対してbツリースキャンを常に使用できます。割り当て順序スキャンを利用できるようにするためによく引用される条件は次のとおりです。
- クエリプランでは、インデックスの順序付けられていないスキャンが許可されている必要があります。
- インデックスのサイズは64ページ以上である必要があります。そして、
-
TABLOCKのいずれか またはNOLOCKヒントを指定する必要があります。
最初の条件は、クエリオプティマイザがスキャンにOrdered:Falseのマークを付けている必要があることを意味します。 財産。スキャンにマークを付けるOrdered:False 実行計画からの正しい結果が必要ないことを意味します インデックスキーの順序で行を返すためのスキャン(ただし、便利な場合や必要な場合はそうすることができます)。
2番目の条件(サイズ)は、SQLServer2005以降にのみ適用されます。これは、IAM駆動型スキャンを実行するために一定の初期費用がかかるという事実を反映しているため、初期投資を返済するための潜在的な節約のために最小ページ数が必要です。 「64ページ」はdata_pagesの値を指します IN_ROW_DATAの場合 sys.allocation_unitsで報告されているアロケーションユニットのみ。
もちろん、おそらくより大きな先読みの考慮事項が実際にある場合にのみ、割り当て順序スキャンからの見返りがあります。 効果がありますが、SQLServerは現在この要素を考慮していません。特に、現在メモリにあるインデックスの量は考慮されておらず、インデックスがどの程度断片化されているかも考慮されていません。
3番目の条件は、おそらくリスト内で最も完全でない説明です。ヒントは実際には必須ではありません 、ただし、実際の要件を満たすために使用できます。データは変更されないことが保証されている必要があります。 スキャン中、または(もっと議論の余地がある)私たちは気にしないことを示さなければなりません 読み取りのコミットされていない分離レベルでスキャンを実行することにより、潜在的に不正確な結果について。
これらの説明があっても、割り当て順スキャンの条件のリストはまだ完全ではありません。重要な警告と例外がいくつかありますが、これらについては間もなく説明します。
デモ
次のクエリは、AdventureWorksサンプルデータベースを使用しています。
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Personテーブルには3,869ページが含まれていることに注意してください。実行後(実際の)計画は次のとおりです(SQL Sentry Plan Explorerに表示されます):
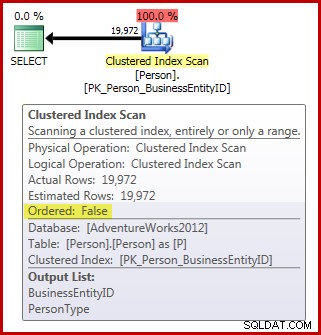
これまでの割り当て順序のスキャン要件に関して:
- プランには必要な
Ordered:Falseがあります 財産;と、 - テーブルには64ページ以上あります。しかし、
- スキャン中にデータが変更されないようにするために何もしていません。セッションがデフォルトの読み取りコミットを使用していると仮定します 分離レベルの場合、スキャンはコミットされていない読み取りで実行されていません。 分離レベルのいずれか。
結果として、このスキャンは、IAM駆動ではなく、bツリーをスキャンすることによって実行されると予想されます。クエリ結果は、これが当てはまる可能性が高いことを示しています:
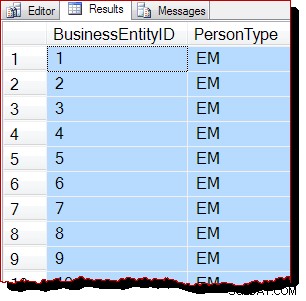
行はクラスター化インデックスキーの順序で返されます(BusinessEntityIDによる) )。この結果の順序は絶対に保証されないことを明確に述べる必要があります 、および信頼すべきではありません。注文された結果は、適切なトップレベルのORDER BYによってのみ保証されます 条項。
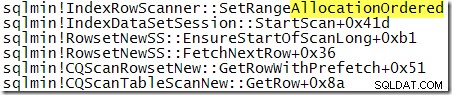
それにもかかわらず、観察された出力順序は、クラスター化インデックスのbツリー構造に従ってスキャンが今回実行されたことを示す状況証拠です。さらに証拠が必要な場合は、デバッガーを接続して、スキャン中にSQLServerが実行しているコードパスを確認できます。

コールスタックは、Bツリーに続くスキャンを明確に示しています。
テーブルロックヒントの追加
ここで、テーブルロックのヒントを含めるようにクエリを変更します。
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); デフォルトのロック読み取りコミット分離レベルでは、共有テーブルレベルのロックにより、データへの同時変更の可能性が防止されます。 IAM駆動型スキャンの3つの前提条件がすべて満たされているため、SQLServerが割り当て順序スキャンを使用することが期待されます。実行プランは以前と同じなので、繰り返しませんが、クエリ結果は確かに異なります:
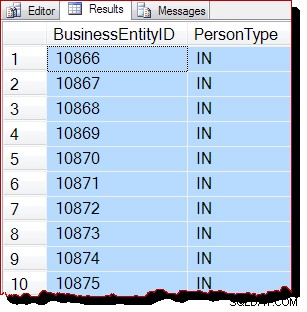
結果はまだ明らかにBusinessEntityIDによって順序付けられています 、ただし、開始点(10866)は異なります。実際、結果を下にスクロールすると、すぐにキーの順序が明らかにずれているセクションが見つかります。
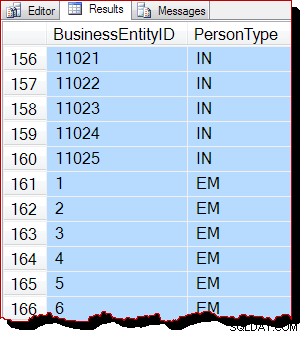
半順序は、一度にインデックスページ全体を処理する割り当て順序スキャンによるものです。 ページ内の結果 たまたまインデックスキー順に返されますが、スキャンされたページの順序が異なります。繰り返しになりますが、結果が異なる場合があることを強調しておく必要があります。トップレベルのORDER BYがないと、ページ内であっても出力順序が保証されません。 元のクエリで。
前に示したコールスタックと比較するために、これはSQLServerがTABLOCKを使用してクエリを処理している間に取得されたスタックトレースです。 ヒント:
実行をもう少し進めます:

明らかに、テーブルロックが指定されている場合、SQLServerは割り当て順スキャンを実行しています。実行後の計画に、実行時にどのタイプのスキャンが使用されたかが示されていないのは残念です。念のため、スキャンのタイプはストレージエンジンによって選択され、プランを再コンパイルしなくても実行ごとに変更できます。
3番目の条件を満たす他の方法
その前に、IAM駆動型スキャンを取得するには、スキャンの進行中にデータがスキャンの下で変更されないようにする必要があります。または、読み取りのコミットされていない分離レベルでクエリを実行する必要があります。読み取りコミットされた分離をロックするためのテーブルロックのヒントは、これらの要件の最初の要件を満たすのに十分であり、NOLOCK/READUNCOMMITTEDを使用することを簡単に示すことができます。 ヒントは、デモクエリを使用した割り当て順序スキャンも有効にします。
実際、3番目の条件を満たすには、次のような多くの方法があります。
- テーブルロックのみを許可するようにインデックスを変更する;
- データベースを読み取り専用にする(したがって、データが変更されないことが保証されます)。または、
- セッションの変更
READ UNCOMMITTEDへの分離レベル 。
ただし、このテーマにはもっと興味深いバリエーションがあります。つまり、前述の3つの条件を修正する必要があります…
行バージョン管理の分離レベル
AdventureWorksデータベースで読み取りコミットスナップショットアイソレーション(RCSI)を有効にし、TABLOCKを使用してテストを実行します もう一度ヒントを(コミットされた分離の読み取り時):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
RCSIがアクティブな場合、インデックス順 スキャンはTABLOCKで使用されます 、直前に見た割り当て順序スキャンではありません。その理由はTABLOCKです ヒントはテーブルレベルの共有ロックを指定しますが、RCSIが有効になっている場合、共有ロックはありません 取られます。共有テーブルロックがないと、スキャンの進行中にデータが同時に変更されないようにするという要件を満たしていないため、割り当て順のスキャンを使用できません。
ただし、RCSIが有効になっている場合は、割り当て順スキャンを実行できます。 1つの方法は、TABLOCKXを使用することです。 ヒント(テーブルレベルの排他的 ロック)TABLOCKの代わりに 。 TABLOCKを保持することもできます ヒントを付けて、READCOMMITTEDLOCKのような別のものを追加します 、またはREPEATABLE READ またはSERIALIZABLE … 等々。これらはすべて、 RCSIのメリットを失うという犠牲を払って、共有テーブルロックを取得することで同時変更の可能性を防ぐことで機能します。 。 NOLOCKを使用して、割り当て順序スキャンを実行することもできます。 またはREADUNCOMMITTED もちろんヒント。
スナップショットアイソレーション(SI)での状況は、RCSIと非常によく似ており、スペース上の理由から詳細には調査されていません。
TABLESAMPLEは常に*割り当て順序スキャンを実行します
TABLESAMPLE 条項は、これまでに説明した多くのことに対する興味深い例外です。
TABLESAMPLEの指定 句always*は、RCSIまたはSIの下でも、ヒントがなくても、割り当て順序スキャンを実行します。明確にするために、TABLESAMPLEを使用した結果の割り当て順序スキャン RCSI / SIセマンティクスを保持します–スキャンは行バージョンを使用し、読み取りは書き込みをブロックしません(逆も同様です)。
2つ目の驚きは、TABLESAMPLE 常に*IAM駆動型スキャンを実行しますテーブルのページ数が64ページ未満の場合でも 。ドキュメントは少なくともSYSTEMを示唆しているので、これはある程度意味があります サンプリング方法はIAM構造を使用します(したがって、割り当て順序スキャンを実行する以外に選択肢はありません):
SYSTEMは、ISO規格で指定されている実装に依存するサンプリング方法です。 SQL Serverでは、これが使用可能な唯一のサンプリング方法であり、デフォルトで適用されます。 SYSTEMは、ページベースのサンプリング方法を適用します。この方法では、テーブルからランダムなページのセットがサンプルとして選択され、それらのページのすべての行がサンプルサブセットとして返されます。
* ROWSの場合は例外が発生します またはPERCENT TABLESAMPLEの仕様 句は、テーブルの100%を意味するように機能します。より多くのROWSを指定する メタデータが示すよりも、現在テーブルにあることも機能しません。 TABLESAMPLE SYSTEM (100 PERCENT)を使用する または同等のものはありません 割り当て順序のスキャンを強制します。
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
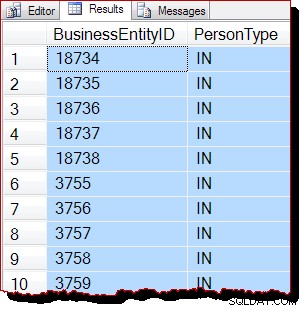
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); 結果:
TOPおよびSETROWCOUNTの効果
つまり、これらはどちらも、割り当て順序スキャンを使用するかどうかの決定に影響を与えません。スキャンされるページが64ページ未満であることが「明らか」である場合、これは意外に思われるかもしれません。
たとえば、次のクエリはどちらもIAM駆動型スキャンを使用して、スキャンから5行を返します。
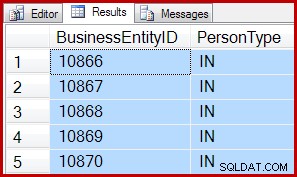
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; 結果はどちらも同じです:
これは、TOP およびSET ROWCOUNT クエリは可能性があります スキャンされるページが64ページ未満の場合でも、割り当て順序スキャンを設定するオーバーヘッドが発生します。緩和策として、選択述語がスキャンにプッシュされたより複雑なTOPクエリは、割り当て順序スキャンの恩恵を受ける可能性があります。スキャンで10,000ページを処理して、一致する最初の5行を見つける必要がある場合でも、割り当て順序スキャンが成功する可能性があります。
インスタンス全体のすべての*割り当て順序スキャンの防止
これは意図的に行う可能性が高いことではありませんが、すべてのデータベースのすべての*ユーザークエリの割り当て順序スキャンを防止するサーバー設定があります。
思われるかもしれませんが、問題の設定はカーソルしきい値サーバー構成オプションであり、BooksOnlineに次の説明があります。
カーソルしきい値オプションは、カーソルキーセットが非同期で生成されるカーソルセットの行数を指定します。カーソルが結果セットのキーセットを生成すると、クエリオプティマイザはその結果セットに対して返される行数を推定します。クエリオプティマイザが、返される行の数がこのしきい値よりも大きいと推定した場合、カーソルは非同期で生成され、カーソルが引き続き入力されている間、ユーザーはカーソルから行をフェッチできます。それ以外の場合、カーソルは同期的に生成され、クエリはすべての行が返されるまで待機します。
cursor thresholdの場合 オプションが-1(デフォルト)以外に設定されている場合、SQLServerインスタンス上のデータベース内のユーザークエリに対して割り当て順序スキャンは発生しません。
つまり、非同期カーソルポピュレーションが有効になっている場合、IAM駆動のスキャンは行われません。
*例外は(100%以外)TABLESAMPLE クエリ。統計の作成と統計の更新のためにシステムによって生成された内部クエリも、割り当て順のスキャンを引き続き使用します。
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
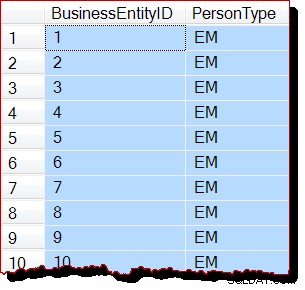
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; 結果(割り当て順序スキャンなし):
非同期カーソルポピュレーションは、何らかの理由で割り当て順序スキャンではうまく機能しないと推測することしかできません。この制限がカーソル以外のすべてのユーザークエリに影響することはまったく予想外です。 でも。おそらく、SQL Serverが、クエリが外部で発行されたAPIカーソルの一部として実行されているかどうかを検出するのは難しいですか?誰が知っている。
この副作用がどこかで公式に文書化されていればいいのですが、BooksOnlineのどこに行くべきかを正確に知ることは困難です。このため、割り当て順序スキャンを使用していない本番システムはいくつあるのでしょうか。それほど多くはないかもしれませんが、あなたは決して知りません。
まとめとして、ここに要約があります。次の場合、割り当て順スキャンを利用できます。
- サーバーオプション
cursor threshold–1(デフォルト)に設定されます。 そして - クエリプランスキャン演算子には、
Ordered:Falseがあります 財産; そして - 合計data_pages
IN_ROW_DATAの 割り当て単位は少なくとも64です。 そして - どちらか:
- SQL Serverには、同時変更が不可能であるという許容可能な保証があります。 または
- スキャンは、読み取りのコミットされていない分離レベルで実行されています。
上記のすべてに関係なく、TABLESAMPLEを使用したスキャン 句は常に割り当て順のスキャンを使用します(本文に記載されている1つの技術的な例外を除く)。