多くのクライアントサーバーアプリケーションの一般的なシナリオは、エンドユーザーが結果の並べ替え順序を指定できるようにすることです。最低価格のアイテムを最初に見たい人もいれば、最新のアイテムを最初に見たい人もいれば、アルファベット順に見たい人もいます。これは、Transact-SQLで達成するのが複雑なことです。これは、次のように言うことはできないためです。
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) = N'key_col', @SortDirection VARCHAR(4) = 'ASC' AS BEGIN ... ORDER BY @SortColumn; -- or ... ORDER BY @SortColumn @SortDirection; END GO
これは、T-SQLがこれらの場所の変数を許可しないためです。 @SortColumnを使用するだけで、次のようになります。
メッセージ1008、レベル16、状態1、行xORDER BY番号1で識別されるSELECT項目には、列の位置を識別する式の一部として変数が含まれています。変数は、列名を参照する式で並べ替える場合にのみ許可されます。
(エラーメッセージに「列名を参照する式」と表示されている場合は、あいまいに感じるかもしれませんが、同意します。ただし、これは変数が適切な式であることを意味するものではありません。)
@SortDirectionを追加しようとすると、エラーメッセージはもう少し不透明になります:
メッセージ102、レベル15、状態1、行x'@SortDirection'の近くの構文が正しくありません。
これを回避する方法はいくつかあります。最初の本能は、動的SQLを使用するか、CASE式を導入することです。しかし、ほとんどの場合と同様に、ある道を進むことを余儀なくされる可能性のある合併症があります。では、どちらを使用する必要がありますか?これらのソリューションがどのように機能するかを調べ、いくつかの異なるアプローチのパフォーマンスへの影響を比較してみましょう。
サンプルデータ
おそらくよく理解しているカタログビューsys.all_objectsを使用して、クロス結合に基づいて次のテーブルを作成し、テーブルを100,000行に制限しました(多くのページを埋めるデータが必要でしたが、クエリにそれほど時間はかかりませんでした)とテスト):
CREATE DATABASE OrderBy;
GO
USE OrderBy;
GO
SELECT TOP (100000)
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- a BIGINT with clustered index
s1.[object_id], -- an INT without an index
name = s1.name -- an NVARCHAR with a supporting index
COLLATE SQL_Latin1_General_CP1_CI_AS,
type_desc = s1.type_desc -- an NVARCHAR(60) without an index
COLLATE SQL_Latin1_General_CP1_CI_AS,
s1.modify_date -- a datetime without an index
INTO dbo.sys_objects
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]; (COLLATEのトリックは、多くのカタログビューに異なる列と異なる照合があるためです。これにより、このデモの目的で2つの列が一致することが保証されます。)
次に、最適化の前に、そのようなテーブルに存在する可能性のある一般的なクラスター化/非クラスター化インデックスのペアを作成しました(クロス結合によって重複が作成されるため、キーにobject_idを使用できません):
CREATE UNIQUE CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
ユースケース
上記のように、ユーザーはこのデータをさまざまな方法で並べ替えて表示したい場合があるので、サポートしたい(そしてサポートによって、つまりデモンストレーションする)典型的なユースケースをいくつか示しましょう:
- key_colの昇順**ユーザーが気にしない場合のデフォルト
- object_idで並べ替え(昇順/降順)
- 名前順(昇順/降順)
- type_descで並べ替え(昇順/降順)
- modify_date(昇順/降順)で並べ替え
key_colの順序はデフォルトのままにします。これは、ユーザーに設定がない場合に最も効率的であるためです。 key_colは任意の代理であり、ユーザーには何の意味もありません(また、それらにさらされることさえない可能性があります)ので、その列で逆ソートを許可する理由はありません。
機能しないアプローチ
誰かが最初にこの問題に取り組み始めたときに私が目にする最も一般的なアプローチは、クエリにフロー制御ロジックを導入することです。彼らはこれができることを期待しています:
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
IF @SortColumn = 'key_col'
key_col
IF @SortColumn = 'object_id'
[object_id]
IF @SortColumn = 'name'
name
...
IF @SortDirection = 'ASC'
ASC
ELSE
DESC; これは明らかに機能しません。次に、同様の構文を使用して、CASEが正しく導入されていないことがわかります。
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
WHEN 'name' THEN name
...
END CASE @SortDirection WHEN 'ASC' THEN ASC ELSE DESC END; これは近いですが、2つの理由で失敗します。 1つは、CASEが特定のデータ型の値を1つだけ返す式であるということです。これにより、互換性のないデータ型がマージされるため、CASE式が壊れます。もう1つは、動的SQLを使用せずに、この方法でソート方向を条件付きで適用する方法がないことです。
機能するアプローチ
私が見た3つの主要なアプローチは次のとおりです。
互換性のあるタイプと方向をグループ化する
ORDER BYでCASEを使用するには、互換性のあるタイプと方向の組み合わせごとに異なる式が必要です。この場合、次のようなものを使用する必要があります:
CREATE PROCEDURE dbo.Sort_CaseExpanded
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END DESC,
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END DESC,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'ASC' THEN modify_date
END,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'DESC' THEN modify_date
END DESC;
END あなたは、すごい、それは醜いコードだと言うかもしれません、そして私はあなたに同意します。これが、多くの人がフロントエンドにデータをキャッシュし、プレゼンテーション層にさまざまな順序でデータを調整させる理由だと思います。 :-)
文字列以外のすべてのタイプを正しく並べ替えられる文字列に変換することで、このロジックをもう少し折りたたむことができます。例:
CREATE PROCEDURE dbo.Sort_CaseCollapsed
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END DESC;
END それでも、それはかなり醜い混乱であり、異なるソート方向を処理するには、式を2回繰り返す必要があります。また、そのクエリでOPTION RECOMPILEを使用すると、パラメータスニッフィングに悩まされるのを防ぐことができると思います。デフォルトの場合を除いて、ここで行われている作業の大部分がコンパイルされるわけではありません。
ウィンドウ関数を使用してランクを適用する
AndriyMからこの巧妙なトリックを発見しましたが、潜在的な順序付け列がすべて互換性のあるタイプである場合に最も役立ちます。そうでない場合、ROW_NUMBER()に使用される式も同様に複雑です。最も賢い部分は、昇順と降順を切り替えるために、ROW_NUMBER()に1または-1を掛けるだけです。この状況では、次のように適用できます。
CREATE PROCEDURE dbo.Sort_RowNumber
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
;WITH x AS
(
SELECT key_col, [object_id], name, type_desc, modify_date,
rn = ROW_NUMBER() OVER (
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM dbo.sys_objects
)
SELECT key_col, [object_id], name, type_desc, modify_date
FROM x
ORDER BY rn;
END
GO ここでも、OPTIONRECOMPILEが役立ちます。また、これらのケースの一部では、さまざまなプランによってタイの処理が異なることに気付く場合があります。たとえば、名前で並べ替える場合、通常、重複する名前の各セット内でkey_colが昇順で表示されますが、表示される場合もあります。値が混同されました。同点の場合により予測可能な動作を提供するために、いつでも追加のORDERBY句を追加できます。最初の例にkey_colを追加する場合は、key_colがORDER BYに2回リストされないように、式にする必要があることに注意してください(たとえば、key_col + 0を使用してこれを行うことができます)。
>動的SQL
多くの人が動的SQLについて留保しています–読むことは不可能であり、SQLインジェクションの温床であり、計画キャッシュの肥大化につながり、ストアドプロシージャを使用する目的を損ないます…これらのいくつかは単に真実ではなく、いくつかは軽減するのは簡単です。上記の手順のいずれにも同じように簡単に追加できる検証をここに追加しました:
CREATE PROCEDURE dbo.Sort_DynamicSQL
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
-- reject any invalid sort directions:
IF UPPER(@SortDirection) NOT IN ('ASC','DESC')
BEGIN
RAISERROR('Invalid parameter for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
-- reject any unexpected column names:
IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date')
BEGIN
RAISERROR('Invalid parameter for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';';
EXEC sp_executesql @sql;
END パフォーマンスの比較
すべてのシナリオを簡単にテストできるように、上記の各プロシージャのラッパーストアドプロシージャを作成しました。 4つのラッパープロシージャは次のようになりますが、プロシージャ名はもちろん異なります。
CREATE PROCEDURE dbo.Test_Sort_CaseExpanded AS BEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- default EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC'; END
次に、SQL Sentry Plan Explorerを使用して、次のクエリを使用して実際の実行プラン(およびそれに伴うメトリック)を生成し、このプロセスを10回繰り返して、合計期間を合計しました。
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; EXEC dbo.Test_Sort_CaseExpanded; --EXEC dbo.Test_Sort_CaseCollapsed; --EXEC dbo.Test_Sort_RowNumber; --EXEC dbo.Test_Sort_DynamicSQL; GO 10
また、最初の3つのケースをOPTION RECOMPILEでテストし(動的SQLのケースでは、毎回新しいプランになることがわかっているため、あまり意味がありません)、4つのケースすべてをMAXDOP 1でテストして、並列処理の干渉を排除しました。結果は次のとおりです。
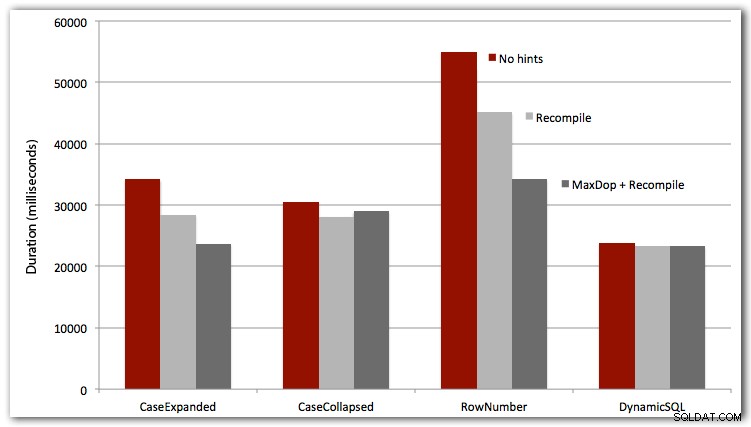
結論
完全なパフォーマンスを得るには、動的SQLが毎回優先されます(ただし、このデータセットではわずかな差があります)。 ROW_NUMBER()アプローチは賢いものでしたが、各テストで敗者でした(申し訳ありませんがAndriyM)。
ページングを気にせずに、WHERE句を導入する場合はさらに楽しくなります。これらの3つは、単純な検索クエリとして始まるものに複雑さを導入するための完璧な嵐のようなものです。クエリの順列が多いほど、読みやすさをウィンドウの外に投げ出し、動的SQLを「アドホックワークロード用に最適化」設定と組み合わせて使用して、プランキャッシュ内の使い捨てプランの影響を最小限に抑える必要があります。