SQL Server 2014の新機能である増分統計に関する前回の投稿では、それらがメンテナンスタスクの期間を短縮するのにどのように役立つかを示しました。これは、統計をパーティションレベルで更新でき、変更がテーブルのメインヒストグラムにマージされるためです。また、クエリオプティマイザーは、クエリプランを生成するときにこれらのパーティションレベルの統計を使用しないことにも注意しました。これは、人々が期待していたことかもしれません。増分統計がクエリオプティマイザによって使用される、または使用されないことを示すドキュメントはありません。それで、どうやって知っていますか?あなたはそれをテストする必要があります。 :-)
セットアップ
このテストの設定は前回の投稿と同様ですが、データが少なくなっています。データファイルのデフォルトサイズは小さく、スクリプトは数百万行のデータのみをロードすることに注意してください。
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
dbo.Ordersのクラスター化インデックスを作成する場合、STATISTICS_INCREMENTALなしで作成します。 オプションが有効になっているため、増分統計のない従来のパーティションテーブルから始めます。
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
次に、約400万行をロードします。これは、私のマシンでは1分弱かかります。
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
データの読み込み後、統計をFULLSCANで更新し(テスト用に可能な限り一貫性のあるヒストグラムを作成できるようにします)、各パーティションにあるデータを確認します。
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];

ほとんどのデータは2015パーティションにありますが、2012、2013、2014のデータもあります。ドキュメント化されていないDMV sys.dm_db_stats_properties_internalからの出力を確認すると 、パーティションレベルの統計が存在しないことがわかります:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal出力には、dbo.Ordersの統計が1つだけ表示されます
sys.dm_db_stats_properties_internal出力には、dbo.Ordersの統計が1つだけ表示されます
テスト
テストには、パーティションの削除が発生したことを確認し、統計に基づいて見積もりを確認するために使用できる簡単なクエリが必要です。クエリはデータを返しませんが、それは問題ではありません。オプティマイザーが考えたことに関心があります。 統計に基づいて返されます:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
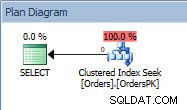 SELECTステートメントのクエリプラン
SELECTステートメントのクエリプラン
プランにはクラスター化インデックスシークがあり、プロパティを確認すると、4000行と推定され、2014年のデータを含むパーティション5にアクセスしたことがわかります。
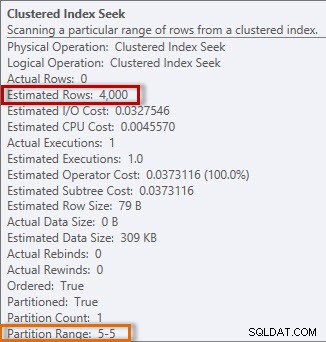 クラスター化インデックスシークからの推定情報と実際の情報
クラスター化インデックスシークからの推定情報と実際の情報
特に2014年4月のデータの領域で、dbo.Ordersテーブルのヒストグラムを見ると、2014-04-01のステップがないことがわかります。したがって、オプティマイザーは、ステップを使用してその日付の行数を推定します。 2014-04-24の場合、AVG_RANGE_ROWS は4000です(2014-02-14から2014-04-23までのいずれかの値の場合、オプティマイザーは4000行が返されると推定します)。
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
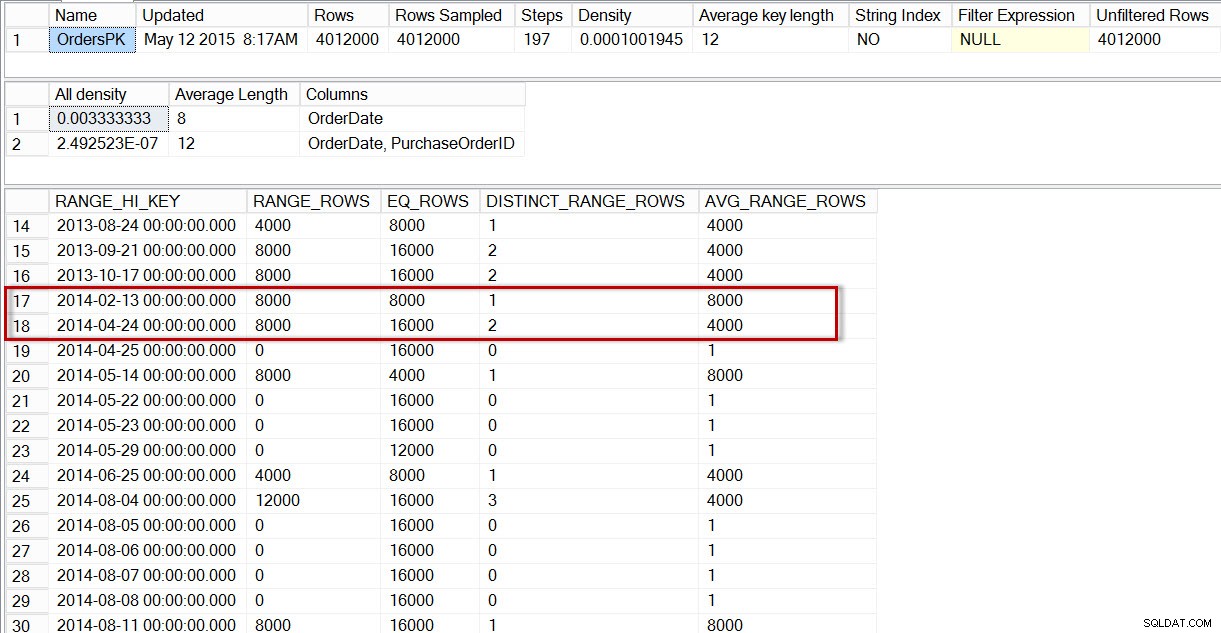 dbo.Ordersヒストグラムでの分布
dbo.Ordersヒストグラムでの分布
見積もりと計画は完全に期待されています。インクリメンタル統計を有効にして、何が得られるか見てみましょう。
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
sys.dm_db_stats_properties_internalに対してクエリを再実行した場合 、増分統計を確認できます:
 sys.dm_db_stats_properties_internalは増分統計情報を表示します
sys.dm_db_stats_properties_internalは増分統計情報を表示します
次に、クエリを再実行してdbo.Ordersを実行し、DBCC FREEPROCCACHEを実行します。 まず、プランが再利用されていないことを完全に確認します:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
同じ計画と同じ見積もりが得られます:
SELECTステートメントのクエリプラン
クラスター化インデックスシークからの推定情報と実際の情報
dbo.Ordersのメインヒストグラムを確認すると、以前とほぼ同じヒストグラムが表示されます。
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
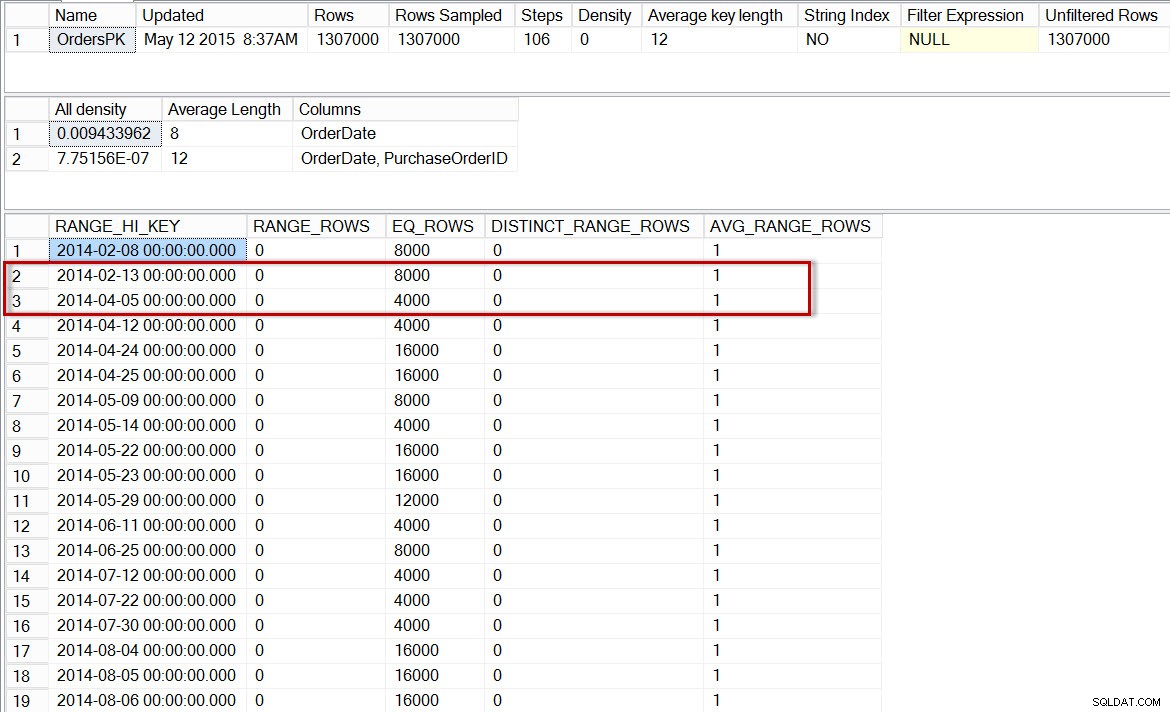 増分統計を有効にした後の、dbo.Ordersのヒストグラム
増分統計を有効にした後の、dbo.Ordersのヒストグラム
次に、2014年のデータを含むパーティションのヒストグラムを確認しましょう(文書化されていないトレースフラグ2309を使用してこれを行うことができます。これにより、DBCC SHOW_STATISTICSへの追加の引数としてパーティション番号を指定できます。 ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
増分統計を有効にした後の、dbo.Ordersの2014パーティションのヒストグラム>
ここでも、2014-04-01のステップはありませんが、RANGE_ROWSは0であることがわかります。 2014-02-13から2014-04-05の間、AVG_RANGE_ROWS オプティマイザーがパーティションレベルの統計にヒストグラムを使用していた場合、2014-04-01の行数の見積もりは1になります。
注:クエリプランで使用されていると識別されたパーティションは5ですが、DBCC SHOW_STATISTICSに気付くでしょう。 ステートメントはパーティション6を参照します。この仮定は、統計メタデータの不整合(0ベースと1ベースのカウントが原因である可能性が高い一般的な1つずつのエラー)であり、将来修正される場合とされない場合があります。現時点ではトレースフラグが文書化されておらず、実稼働環境での使用は推奨されていないことを理解してください。
概要
SQL Server 2014リリースでの増分統計の追加は、パーティション化されたテーブルのカーディナリティ推定を改善するための正しい方向への一歩です。ただし、これまでに示したように、増分統計の現在の値は、クエリオプティマイザーによってまだ使用されていないため、メンテナンス期間の短縮に制限されています。