SQL Server 2014は、更新可能なクラスター化列ストアインデックス、遅延耐久性、バッファープール拡張機能など、DBAと開発者が環境でテストして使用することを楽しみにしていた多くの新機能をもたらしました。あまり議論されない機能は、増分統計です。パーティショニングを使用しない限り、これは実装できる機能ではありません。ただし、データベースにパーティション化されたテーブルがある場合は、増分統計が熱心に期待していた可能性があります。
注:Benjamin Nevarezは、2014年2月の投稿であるSQL Server 2014の増分統計で、増分統計に関連するいくつかの基本事項について説明しました。彼の投稿と2014年4月のリリース以降、この機能の動作に大きな変更はありませんが、増分統計を有効にすることがメンテナンスパフォーマンスにどのように役立つかを掘り下げる良い機会のようです。
増分統計は、パーティションレベルの統計と呼ばれることもあります。これは、SQLServerがパーティションに固有の統計を初めて自動的に作成できるためです。パーティショニングに関するこれまでの課題の1つは、1からnの場合でも、それでした。 テーブルのパーティションの場合、これらすべてのパーティションにわたるデータ分散を表す統計は1つだけでした。パーティションテーブルのフィルター処理された統計(パーティションごとに1つの統計)を作成して、データの分散に関するより適切な情報をクエリオプティマイザーに提供できます。ただし、これは手動のプロセスであり、新しいパーティションごとに自動的に作成するためのスクリプトが必要でした。
SQL Server 2014では、STATISTICS_INCREMENTALを使用します SQLServerにこれらのパーティションレベルの統計を自動的に作成させるオプション。ただし、これらの統計は、ご想像のとおり使用されていません。
2014年より前は、フィルター処理された統計を作成して、オプティマイザーにパーティションに関するより良い情報を提供することができたと前述しました。それらの増分統計?現在、オプティマイザでは使用されていません。クエリオプティマイザは、テーブル全体を表すメインヒストグラムを使用します。 (これを実証する投稿が来ます!)
では、増分統計のポイントは何ですか?最新のパーティションのデータのみが変更されていると想定する場合、理想的には、そのパーティションの統計のみを更新します。これをインクリメンタル統計で実行できるようになりました。その後、情報がメインのヒストグラムにマージされます。テーブル全体のヒストグラムは、統計を更新するためにテーブル全体を読み取る必要なしに更新されます。これは、メンテナンスタスクのパフォーマンスに役立ちます。
セットアップ
まず、パーティション関数とスキームを作成し、次にパーティション化する新しいテーブルを作成します。実稼働環境の場合と同じように、パーティション関数ごとにファイルグループを作成したことに注意してください。同じファイルグループにパーティションスキームを作成できます(例:PRIMARY )テストデータベースを簡単に削除できない場合。約4億行を追加するため、各ファイルグループのサイズも数GBです。
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
データを追加する前に、クラスター化されたインデックスを作成します。構文にはWITH (STATISTICS_INCREMENTAL = ON)が含まれていることに注意してください。 オプション:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
ここで注目すべき興味深い点は、ALTER TABLEを見ると MSDNのエントリには、このオプションは含まれていません。 ALTER INDEXでのみ見つけることができます エントリ…しかし、これは機能します。レターのドキュメントに従いたい場合は、次のコマンドを実行します。
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
パーティションスキームのクラスター化されたインデックスが作成されたら、データを読み込み、パーティションごとに存在する行数を確認します(これには7分以上かかることに注意してください)。 私のラップトップでは、使用可能なストレージの量(および時間)に応じて、追加する行を少なくすることをお勧めします):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
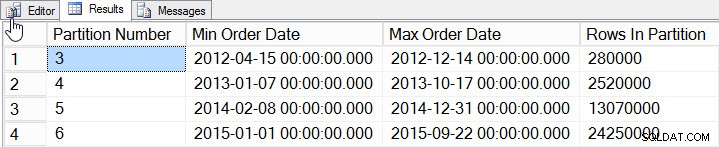
2012年から2015年までのデータを追加し、2014年と2015年には大幅に多くのデータを追加しました。統計がどのようになるか見てみましょう:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
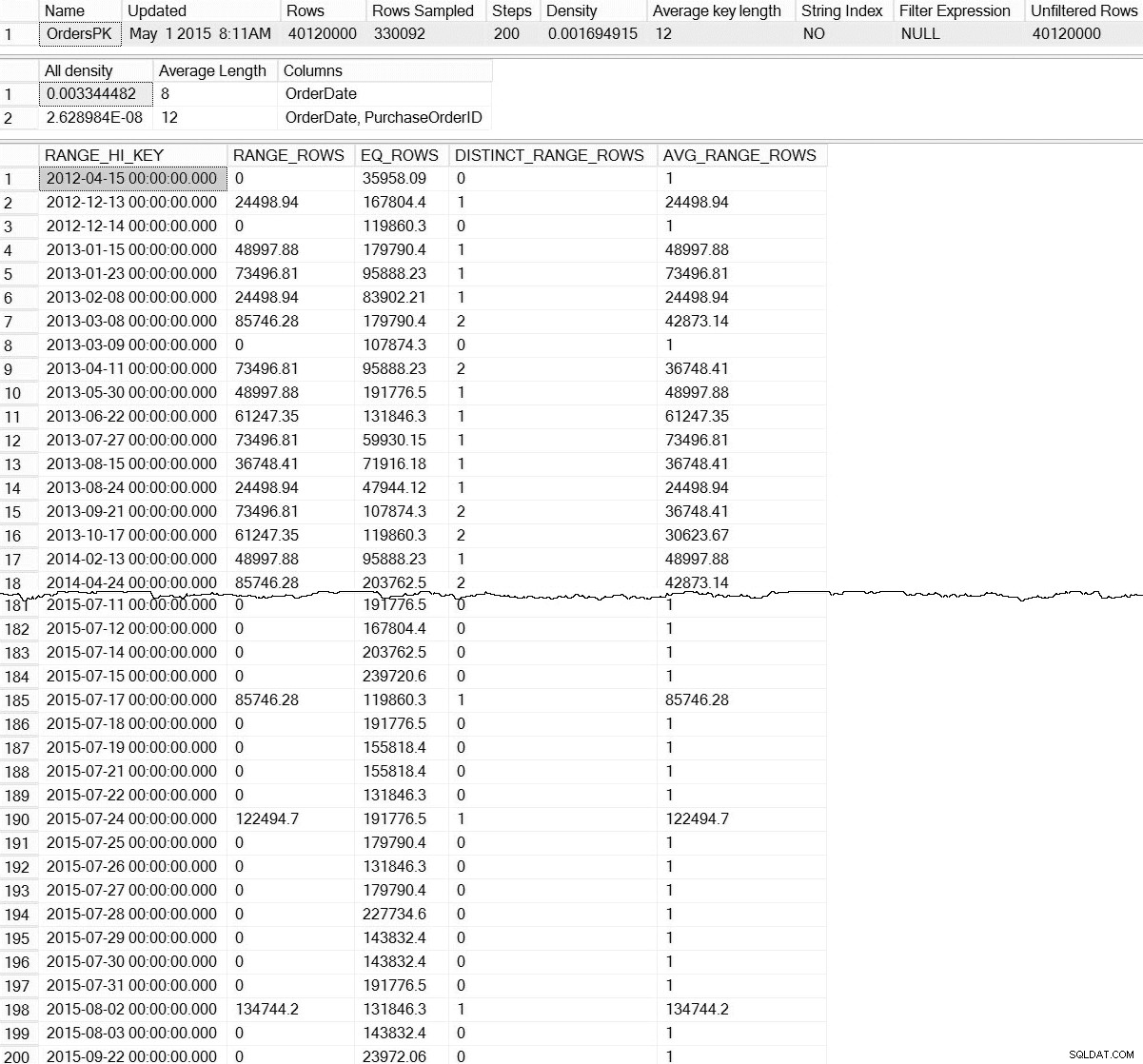 dbo.OrdersのDBCCSHOW_STATISTICS出力(クリックして拡大)
dbo.OrdersのDBCCSHOW_STATISTICS出力(クリックして拡大)
デフォルトのDBCC SHOW_STATISTICS コマンドでは、パーティションレベルの統計に関する情報はありません。恐れるな;私たちは完全に運命づけられているわけではありません–文書化されていない動的管理機能sys.dm_db_stats_properties_internalがあります 。文書化されていないということは、サポートされていないことを意味し(DMFのMSDNエントリはありません)、Microsoftからの警告なしにいつでも変更できることを忘れないでください。とはいえ、増分統計に何が存在するかを理解するための適切なスタートです。
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 dm_db_stats_properties_internalからのヒストグラム情報(クリックして拡大)
dm_db_stats_properties_internalからのヒストグラム情報(クリックして拡大)
これはもっと面白いです。ここでは、パーティションレベルの統計(およびそれ以上)が存在するという証拠を見ることができます。このDMFは文書化されていないため、何らかの解釈を行う必要があります。今日は、出力の最初の7行に焦点を当てます。最初の行は、テーブル全体のヒストグラムを表します(rowsに注意してください)。 4,000万の値)、後続の行は各パーティションのヒストグラムを表します。残念ながら、partition_number このヒストグラムの値は、sys.dm_db_index_physical_statsのパーティション番号と一致していません 右ベースのパーティショニングの場合(左ベースのパーティショニングの場合は適切に相関します)。また、この出力にはlast_updatedも含まれていることに注意してください およびmodification_counter 列。トラブルシューティングに役立ち、経過時間や行の変更に基づいて統計をインテリジェントに更新するメンテナンススクリプトを開発するために使用できます。
必要なメンテナンスを最小限に抑える
現時点での増分統計の主な価値は、テーブル全体の統計を更新する必要なしに(したがって、テーブル全体を読み取ることなく)、パーティションの統計を更新し、それらをテーブルレベルのヒストグラムにマージする機能です。これが実際に動作することを確認するために、最初に2015年のデータを保持するパーティションであるパーティション5の統計を更新します。次に、かかった時間を記録し、sys.dm_io_virtual_file_statsのスナップショットを作成します。 発生するI/Oの量を確認する前後のDMF:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
出力:
SQL Serverの実行時間:CPU時間=203ミリ秒、経過時間=240ミリ秒。
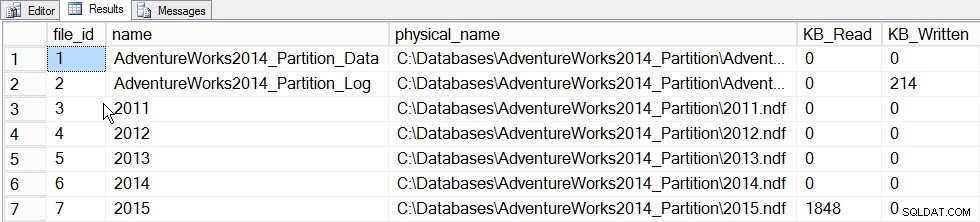 1つのパーティションを更新した後のFile_statsデータ
1つのパーティションを更新した後のFile_statsデータ
sys.dm_db_stats_properties_internalを見ると 出力すると、last_updatedであることがわかります 2015ヒストグラムとテーブルレベルヒストグラムの両方(および後で調査するための他のいくつかのノード)で変更されました:
 dm_db_stats_properties_internalからのヒストグラム情報を更新
dm_db_stats_properties_internalからのヒストグラム情報を更新
次に、FULLSCANで統計を更新します テーブルの場合、file_statsのスナップショットを前後に作成します:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
出力:
SQL Serverの実行時間:CPU時間=12720ミリ秒、経過時間=13646ミリ秒
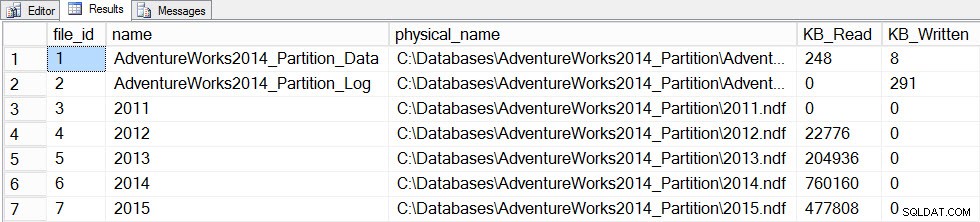
更新にはかなり長い時間がかかり(数百ミリ秒に対して13秒)、より多くのI/Oが生成されました。 sys.dm_db_stats_properties_internalを確認すると ここでも、last_updatedが見つかります すべてのヒストグラムで変更:
 フルスキャン後のdm_db_stats_properties_internalからのヒストグラム情報
フルスキャン後のdm_db_stats_properties_internalからのヒストグラム情報
概要
増分統計は、クエリオプティマイザが各パーティションに関する情報を提供するためにまだ使用していませんが、パーティションテーブルの統計を管理するときにパフォーマンス上の利点を提供します。一部のパーティションの統計のみを更新する必要がある場合は、それらだけを更新できます。次に、新しい情報がテーブルレベルのヒストグラムにマージされ、テーブル全体を読み取るコストをかけずに、オプティマイザに最新の情報を提供します。今後、これらのパーティションレベルの統計が オプティマイザによって使用されます。しばらくお待ちください…