
これも断片化ではありません
先月、予期しないクラスター化されたインデックスの断片化について書いたので、今回は、インデックスの断片化が発生しないようにするためにできることのいくつかについて説明したいと思います。前の投稿を読んで、そこで定義した用語に精通していることを前提としています。この記事の残りの部分では、「断片化」と言うときは、論理的な断片化と低ページ密度の問題の両方を指します。
適切なクラスターキーを選択してください
断片化を取り除くために操作するのに最も費用のかかるデータ構造は、テーブルのクラスター化されたインデックスです。これは、すべてのテーブルデータが含まれているため、最大の構造であるためです。断片化の観点からは、テーブルの挿入パターンに一致するクラスターキーを選択するのが理にかなっているため、スペースがないページで挿入が発生し、ページ分割が発生して断片化が発生する可能性はありません。
特定のテーブルに最適なクラスターキーを構成するものは多くの議論の対象ですが、一般に、クラスターキーに次の単純なプロパティがあれば間違いはありません。
- 狭い(つまり、列をできるだけ少なくする)
- 静的(つまり、更新することはありません)
- ユニーク
- 増え続ける
これは、すでにいっぱいになっているページでページ分割を引き起こす可能性のあるランダムな挿入を回避するため、断片化の防止に最も重要な、増え続けるプロパティです。このようなキーの選択の例としては、intID列とbigintID列、またはNEWSEQUENTIALID()関数からの順次GUIDがあります。
これらのタイプのキーを使用すると、新しい行のキー値がテーブル内の他のすべての行よりも高くなることが保証されるため、新しい行の挿入ポイントは、クラスター化インデックス構造の右端のページの最後になります。最終的に、新しい行がそのページを埋め、別のページがインデックスの右側に追加されますが、損傷を与えるページ分割は発生しません。
さて、増え続けることのないクラスター化されたインデックスキーがある場合、それを増え続けるものに変更するのは非常に複雑で口に合わない手順になる可能性があるので、心配しないでください。代わりに、私が説明するようなフィルファクターを使用できます。以下。
ちなみに、クラスターキーの選択とそのすべての影響についてのより深い洞察については、キンバリーのクラスタリングキーブログカテゴリ(下から上に読んでください)を確認してください。
インデックスキー列を更新しないでください
キー列が更新されるときはいつでも、それは単なるインプレース更新ではありませんが、オンラインや本の多くの場所ではそれが更新されていると言われています(間違っています)。新しいキー値は、行がインデックスに対して間違ったキー順序になっていることを意味するため、キー列をその場で更新することはできません。代わりに、キー列の更新は、新しいキー値を使用した完全な行の削除と完全な行の挿入に変換されます。新しい行が挿入されるページに十分なスペースがない場合、ページ分割が発生し、断片化が発生します。
テーブル行のクラスターキーを更新する必要があるのは貧弱な設計であるため、クラスター化インデックスではキー列の更新を回避するのは簡単です。ただし、非クラスター化インデックスの場合、テーブルの更新に非クラスター化インデックスが存在する列が含まれる場合は避けられません。そのような場合は、フィルファクターを使用する必要があります。
可変長列を更新しない
これは口で言うほど簡単ではありません。可変長の列を使用する必要があり、それらが更新される可能性がある場合は、列が大きくなり、更新された行のためにより多くのスペースが必要になる可能性があり、ページがすでにいっぱいの場合はページ分割につながります。
この場合、断片化を回避するためにできることがいくつかあります。
- 曲線因子を使用する
- すべての余分なパディングバイトのオーバーヘッドが断片化やフィルファクターの使用よりも問題が少ない場合は、代わりに固定長の列を使用してください
- プレースホルダー値を使用して列のスペースを「予約」します。これは、アプリケーションが新しい行を入力してから戻って詳細の一部を入力し、可変長の列を拡張する場合に使用できるトリックです。
- 更新の代わりに削除と挿入を実行します
フィルファクターを使用する
ご覧のとおり、断片化を回避する方法の多くは、アプリケーションやスキーマの変更を伴うため、口に合わないため、フィルファクターを使用すると、断片化を軽減する簡単な方法になります。
インデックスフィルファクタは、インデックスが作成、再構築、または再編成されたときに、各リーフレベルページに残す空きスペースの量を指定するインデックスの設定です。アイデアは、ページがいっぱいになってページ分割を必要とせずに、ランダムな挿入または行の拡張(バージョンタグが追加または更新された可変長列から)を可能にするのに十分な空き領域があるということです。ただし、最終的にはページがいっぱいになるため、インデックスを再構築または再編成して(一般にインデックスのメンテナンスの実行と呼ばれます)、定期的に空き領域を更新する必要があります。秘訣は、インデックスのメンテナンスの適切な周期性とともに、使用する適切な曲線因子を見つけることです。
フィルファクタの設定について詳しくは、MSDNのこちらをご覧ください。 (sp_configureを使用して)インスタンス全体のフィルファクターを設定するという罠にはまらないでください。これは、フラグメンテーションの問題がないインデックスであっても、すべてのインデックスがそのフィルファクター値を使用して再構築または再編成されることを意味します。キーが増え続ける大規模なクラスター化インデックスで、リーフレベルのスペースの30%が、決して発生しないランダムな挿入の準備のために無駄になることは望ましくありません。どのインデックスが実際に断片化の影響を受けているかを把握し、それらのフィルファクターのみを設定することをお勧めします。
私がこれについてあなたに与えることができる正しい答えや魔法の公式はありません。一般的に受け入れられている方法は、断片化が問題となるインデックスに70のフィルファクター(30%の空き領域を残すことを意味します)を設定し、フラグメンテーションが発生する速度を監視してから、フィルファクターまたはインデックスのメンテナンス頻度を変更することです。 (または両方)。
はい、これは、断片化を回避するためにインデックスのスペースを意図的に浪費していることを意味しますが、ページ分割のコストが高く、断片化がパフォーマンスに悪影響を与える可能性があることを考えると、これは適切なトレードオフです。はい、一部の人が言うかもしれませんが、SSDを使用している場合でも、これは依然として重要です。
概要
断片化の発生を回避するためにできる簡単なことがいくつかありますが、非クラスター化インデックスに入るとすぐに、またはスナップショットアイソレーションまたは読み取り可能なセカンダリを使用すると、断片化は醜い頭をもたげ、それを防ぐようにする必要があります。
ひざまずいて、すべてのインスタンスに70のフィルファクターを設定する必要があると考えないでください。前述のように、慎重に選択して設定する必要があります。
また、SQL Sentry FragmentationManagerを忘れないでください。SQLSentryFragmentationManagerを使用すると(Performance Advisorのアドオンとして)、断片化の問題がどこにあるかを把握し、それらに対処できます。たとえば、[インデックス]タブでは、最初に最も高い断片化でインデックスを簡単に並べ替えることができます(必要に応じて、行数列にフィルターを適用して、小さいテーブルを無視します):
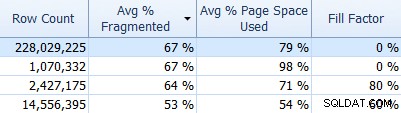
次に、これらのインデックスがデフォルトのフィルファクター(0%)を使用しているかどうか、またはデフォルト以外のフィルファクターを使用しているかどうかを確認します。これは、データとDMLパターンに適切に一致しない可能性があります。上記のスクリーンショットのどれが私が調査するのに最も興味があるかを推測させます。より適切なインデックスフィルファクターを実装することは、発見した問題に対処する最も簡単な方法です。