@rob_farley最初に値で並べ替えてからフィールドを並べ替える最近のstackoverflowソリューション天才!個人的にありがとうございました。
— Joel Sacco(@ Jsac90)2016年8月11日
このツイートが届くのを見ました…
そして、データの注文についてStackOverflowに「最近」何も書いていなかったので、それが何を指しているのかを調べました。 私が書いたこの回答であることがわかりました 、受け入れられた答えではありませんでしたが、100票以上を集めました。
質問をしている人は、特定の行を最初に表示したいという非常に単純な問題を抱えていました。そして私の解決策は単純でした:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Joel Saccoを含め、人気のある回答だったようです(上記のツイートによると)。
表現を形成し、それによって順序付けするという考え方です。 ORDER BYは、それが実際の列であるかどうかを気にしません。 ORDER BY句で「列」を使用したい場合は、APPLYを使用して同じことを行うことができます。
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
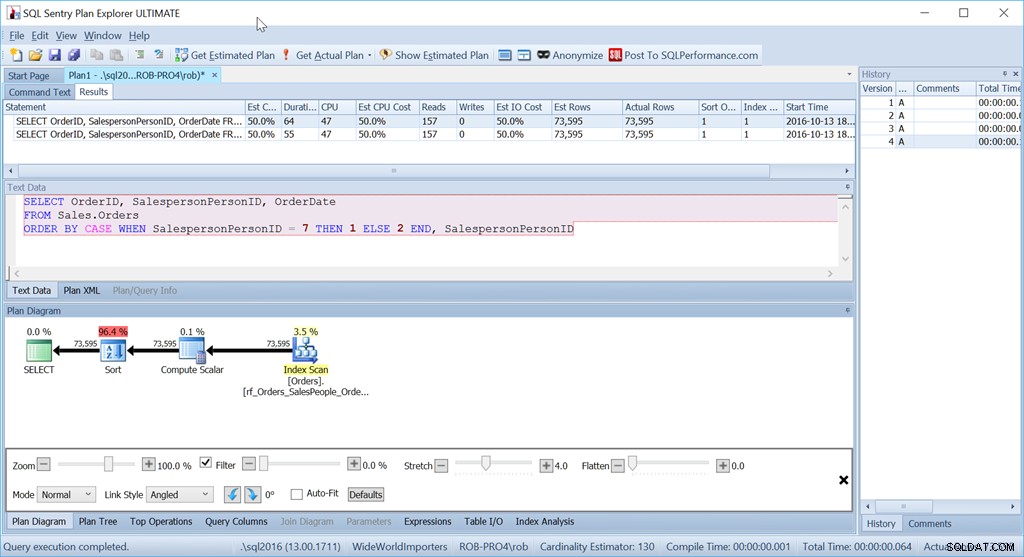
WideWorldImportersに対していくつかのクエリを使用すると、これら2つのクエリが実際にまったく同じである理由を示すことができます。 Sales.Ordersテーブルにクエリを実行し、営業担当者7の注文を最初に表示するように依頼します。また、適切なカバーインデックスを作成します:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
これら2つのクエリの計画は同じように見えます。それらは同じように実行されます–同じ読み取り、同じ式、それらは実際には同じクエリです。実際のCPUまたは期間にわずかな違いがある場合、それは他の要因によるまぐれです。
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
それでも、これは私がこの状況で実際に使用するクエリではありません。パフォーマンスが私にとって重要だった場合ではありません。 (通常はそうですが、データ量が少ない場合は、長い道のりでクエリを作成する価値があるとは限りません。)
気になるのは、そのソート演算子です。コストの96.4%です!
単にSalespersonPersonIDで注文するかどうかを検討してください:
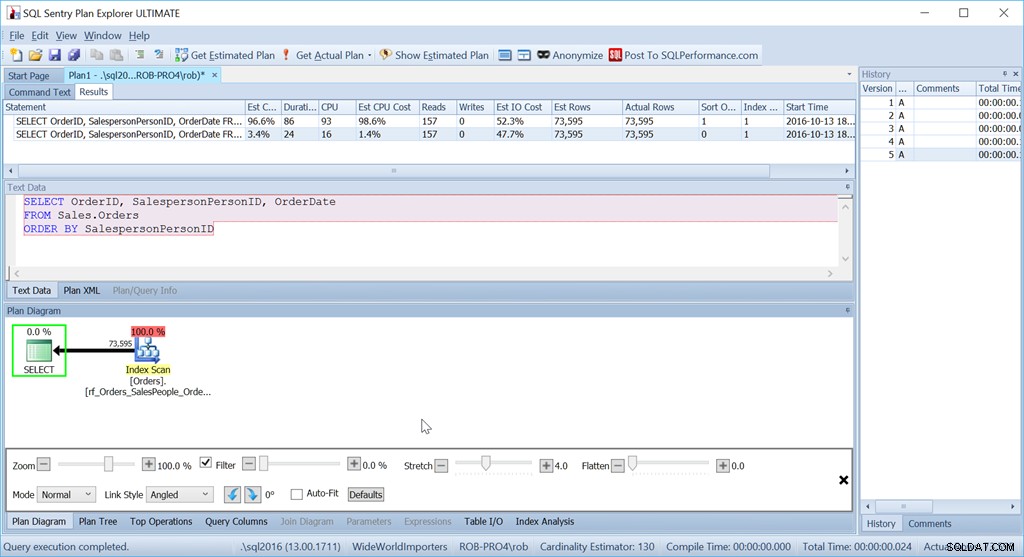
この単純なクエリの推定CPUコストはバッチの1.4%であるのに対し、カスタムソートされたバージョンは98.6%であることがわかります。それは70倍悪いです。ただし、読み取りは同じです–それは良いことです。持続時間ははるかに悪く、CPUも同様です。
私はSortsが好きではありません。彼らは厄介かもしれません。
ここでのオプションの1つは、計算列をテーブルに追加してインデックスを作成することですが、ORM、Power BI、またはSELECT *を実行するものなど、テーブル上のすべての列を検索するすべてのものに影響を与えます。 。ですから、それはそれほど素晴らしいことではありません(ただし、非表示の計算列を追加することができれば、ここで非常に優れたオプションになります)。
もう1つのオプションは、より長蛇の列があり(一部の人は私に合っていると示唆するかもしれませんが、もしあなたがそう思ったなら:Oi!そんなに失礼なことはしないでください!)、より多くの読み取りを使用します。これを行う必要がありました。
73,595の注文が山積みで、営業担当者の注文で並べ替えられていて、最初に特定の営業担当者と一緒に返品する必要がある場合は、注文を無視せずにすべてを並べ替えるだけで、まずは飛び込んで営業担当者7用のものを見つけます–それらを元の順序に保ちます。次に、営業担当者7ではなかったものではないものを見つけます–次にそれらを置き、再びそれらをすでにあった順序に保ちますin。
T-SQLでは、これは次のように行われます。
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; これにより、2セットのデータが取得され、それらが連結されます。ただし、クエリオプティマイザーは、2つのセットが連結されると、SalespersonPersonIDの順序を維持する必要があることを認識できるため、その順序を維持する特別な種類の連結を実行します。これはマージ結合(連結)結合であり、計画は次のようになります。
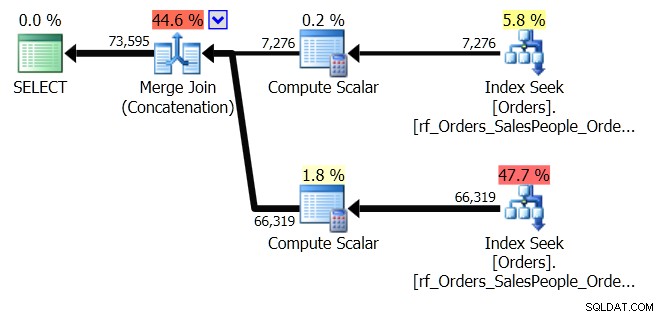
あなたはそれがはるかに複雑であることがわかります。ただし、Sort演算子がないことにも気付くと思います。マージ結合(連結)は、各ブランチからデータをプルし、正しい順序のデータセットを生成します。この場合、最初に営業担当者7の7,276行すべてをプルし、次に残りの66,319行をプルします。これが必要な注文だからです。各セット内で、データはSalespersonPersonIDの順序であり、データが流れるときに維持されます。
先に述べたように、より多くの読み取りを使用します。 2つのクエリを比較してSETSTATISTICSIO出力を表示すると、次のように表示されます。
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。表「順序」。スキャンカウント1、論理読み取り157、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
表'順序'。スキャンカウント3、論理読み取り163、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
「カスタムソート」バージョンを使用すると、157回の読み取りを使用して、インデックスを1回スキャンするだけです。 「UnionAll」メソッドを使用すると、3つのスキャンが行われます。1つはSalespersonPersonID =7、1つはSalespersonPersonID <7、もう1つはSalespersonPersonID> 7です。2番目のインデックスシークのプロパティを確認すると、最後の2つを確認できます。
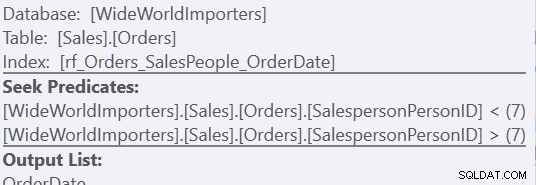
しかし、私にとっては、ワークテーブルがないことでメリットが得られます。
推定CPUコストを見てください:

並べ替えを完全に回避した場合、1.4%ほど小さくはありませんが、カスタム並べ替え方法よりも大幅に改善されています。
しかし、警告の言葉…
そのインデックスを別の方法で作成し、OrderDateをインクルード列ではなくキー列として使用したとします。
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
現在、私の「UnionAll」メソッドは意図したとおりに機能しません。
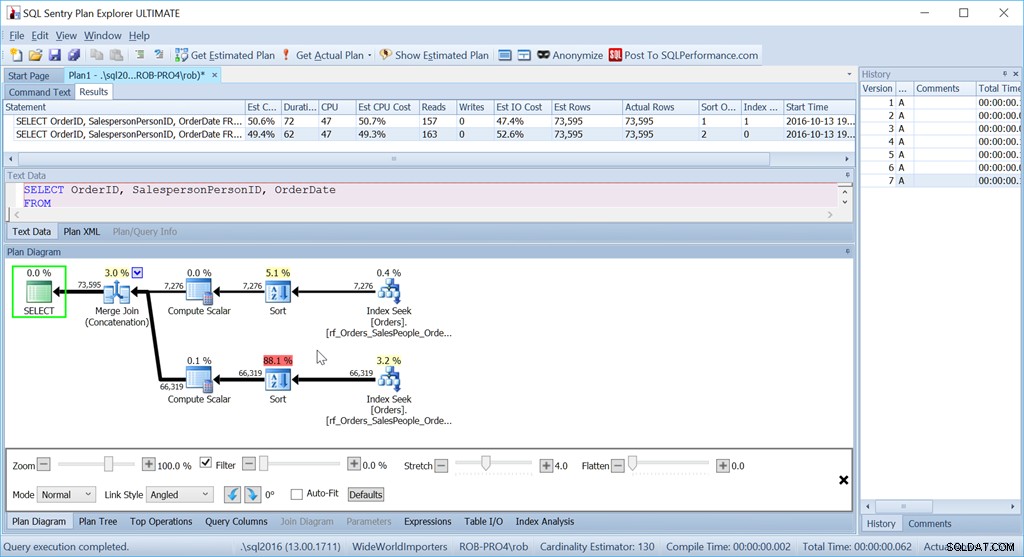
以前とまったく同じクエリを使用しているにもかかわらず、私の素敵なプランには2つの並べ替え演算子があり、元のスキャン+並べ替えバージョンとほぼ同じくらいパフォーマンスが悪くなっています。
この理由は、マージ結合(連結)演算子の癖であり、手がかりはソート演算子にあります。

これは、SalespersonPersonIDの後に、テーブルのクラスター化されたインデックスキーであるOrderIDが続く順序です。これは一意であることがわかっているため、これを選択します。これは、SalespersonPersonID、OrderDate、OrderIDの順に並べ替える列のセットが小さいためです。これは、3回のインデックス範囲スキャンによって生成されるデータセットの順序です。クエリオプティマイザがそこにあるより良いオプションに気付かないときの1つ。
このインデックスを使用すると、優先プランを作成するために、OrderDateで並べ替えられたデータセットも必要になります。
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
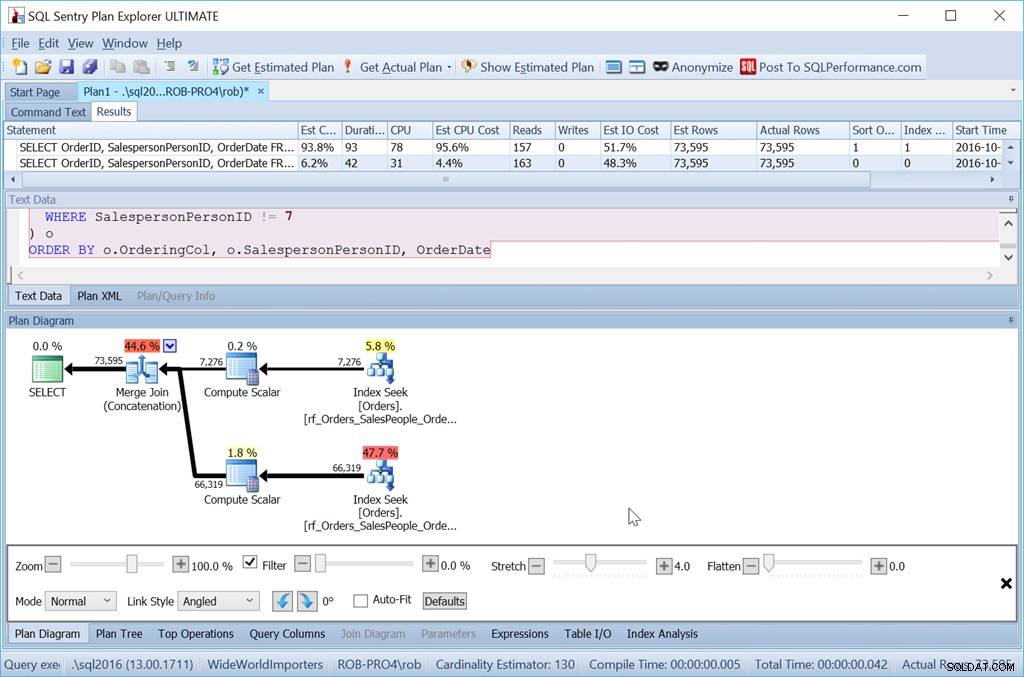
ですから、それは間違いなくもっと努力です。クエリは私が書くのに長く、読み取りが多く、余分なキー列のないインデックスが必要です。しかし、それは確かに速いです。行がさらに増えると、影響はさらに大きくなり、並べ替えがtempdbに流出するリスクを冒す必要もありません。
小さなセットの場合、私のStackOverflowの答えはまだ良いです。ただし、その並べ替え演算子のパフォーマンスが低下している場合は、Union All / Merge Join(連結)メソッドを使用します。