今月初めに、私たち全員がやらなくてもよかったと思うことについてのヒントを公開しました。通常はユーザー定義関数(UDF)を含む、区切られた文字列から重複を並べ替えたり削除したりします。アルファベット順に(重複なしで)リストを再構成する必要がある場合もあれば、元の順序を維持する必要がある場合もあります(たとえば、不良インデックスのキー列のリストである可能性があります)。
両方のシナリオに対応する私のソリューションでは、数値テーブルと、ユーザー定義関数(UDF)のペアを使用しました。1つは文字列を分割し、もう1つは文字列を再構築します。ここでそのヒントを見ることができます:
- SQLServerの文字列からの重複の削除
もちろん、この問題を解決する方法は複数あります。私は、あなたがその構造データで立ち往生している場合に試すための1つの方法を提供しているだけでした。 Red-Gateの@Phil_Factorは、彼のアプローチを示す簡単な投稿でフォローアップしました。これは、関数と数値テーブルを避け、代わりにインラインXML操作を選択します。彼は、単一ステートメントのクエリを使用し、関数と行ごとの処理の両方を回避することを好むと述べています。
- SQLServerでの区切りリストの重複排除
次に、読者のSteve Mangiameliが、ヒントのコメントとしてループソリューションを投稿しました。彼の推論は、数値テーブルの使用は彼にとって過剰に設計されているように思われたというものでした。
私たち3人は全員、タスクを十分な頻度で、または任意のレベルの規模で実行している場合に通常非常に重要になるこの側面に対処できませんでした。パフォーマンス 。
テスト
インラインXMLとループのアプローチが、数値テーブルベースのソリューションと比較してどれだけうまく機能するかを知りたいと思ったので、いくつかのテストを実行するために架空のテーブルを作成しました。私の目標は5,000行で、平均文字列長は250文字を超え、各文字列には少なくとも10個の要素が含まれていました。非常に短い実験サイクルで、次のコードを使用してこれに非常に近いものを達成することができました。
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 これにより、次のようなサンプル行を含むテーブルが作成されました(値は切り捨てられます):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
データ全体として、次のプロファイルがありました。これは、潜在的なパフォーマンスの問題を明らかにするのに十分なはずです。
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
varcharに切り替えたことに注意してください ここからnvarchar 元の記事では、PhilとSteveが提供したサンプルはvarcharを想定しているためです。 、255文字または8000文字で制限される文字列、1文字の区切り文字など。私のレッスンでは、誰かの関数を取得してパフォーマンスの比較に含める場合、変更はわずかであるという難しい方法を学びました。可能–理想的には何もありません。実際には、私は常にnvarcharを使用します 可能な限り長い文字列については何も想定しないでください。この場合、最長の文字列は2,905文字しかないため、データが失われることはなく、このデータベースにはUnicode文字を使用するテーブルや列がありません。
次に、関数を作成しました(数値テーブルが必要です)。ある読者が私のヒントの関数の問題を発見しました。区切り文字は常に1文字であると想定し、ここで修正しました。また、ほぼすべてをvarchar(8000)に変換しました 文字列の種類と長さの観点から競技場を平準化する。
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO 次に、スカラー関数を完全に回避するために、上記の2つの関数を組み合わせた単一のインラインテーブル値関数を作成しました。これは、元の記事で実行したかったことです。 (確かにすべてではありません スカラー関数は大規模にひどいものであり、例外はほとんどありません。)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
CASEの変動を避けるために、2つの並べ替えの選択肢のそれぞれに専用のインラインTVFの個別のバージョンも作成しました。 表現しましたが、劇的な影響はまったくありませんでした。
次に、Steveの2つの関数を作成しました。
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
次に、Philの直接クエリをテストリグに配置します(彼のクエリは<をエンコードしていることに注意してください) <として XML解析エラーから保護しますが、>はエンコードしません または& –問題のある文字が含まれる可能性のある文字列から保護する必要がある場合に備えて、プレースホルダーを追加しました):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
テストリグは、基本的にこれら2つのクエリと、次の関数呼び出しでした。それらがすべて同じデータを返すことを検証したら、スクリプトにDATEDIFFを散在させました。 出力してテーブルに記録しました:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above 次に、2つの異なるシステム(1つは8GBのクアッドコア、もう1つは32GBの8コアVM)でパフォーマンステストを実行し、いずれの場合もSQLServer2012とSQLServer2016 CTP 3.2(13.0.900.73)の両方で実行しました。
結果
私が観察した結果は、次のグラフにまとめられています。このグラフは、各タイプのクエリの期間をミリ秒単位で示し、アルファベット順と元の順序、4つのサーバーとバージョンの組み合わせ、および各順列に対する一連の15回の実行を示しています。クリックして拡大:
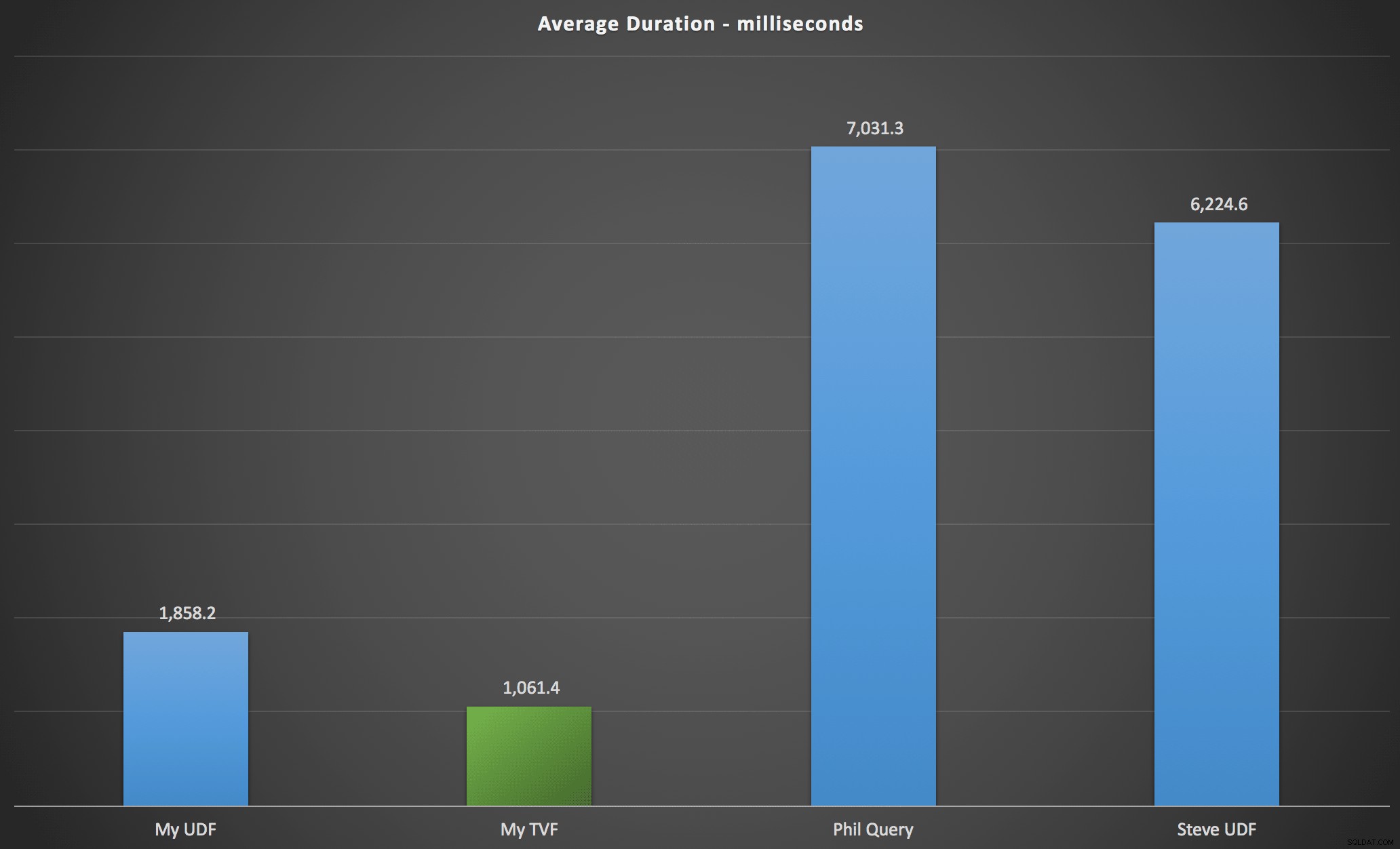
これは、数値表が過剰に設計されていると見なされているものの、実際に最も効率的なソリューションを生み出したことを示しています(少なくとも期間に関して)。もちろん、これは、元の記事のネストされた関数よりも最近実装した単一のTVFの方が優れていましたが、どちらのソリューションも2つの選択肢を巡回しています。
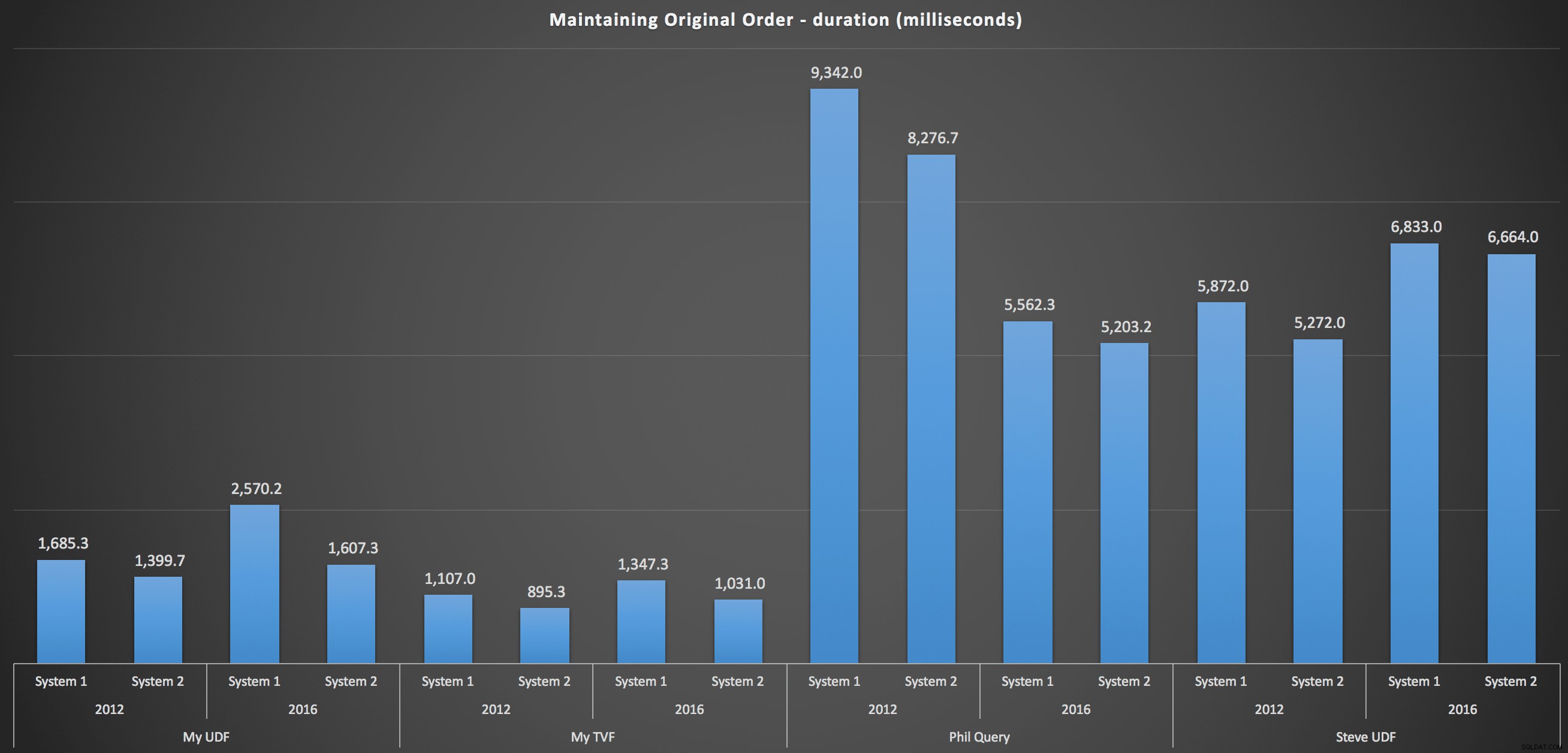
詳細については、元の順序を維持するための各マシン、バージョン、クエリタイプの内訳を次に示します。
…そしてアルファベット順にリストを再組み立てするために:
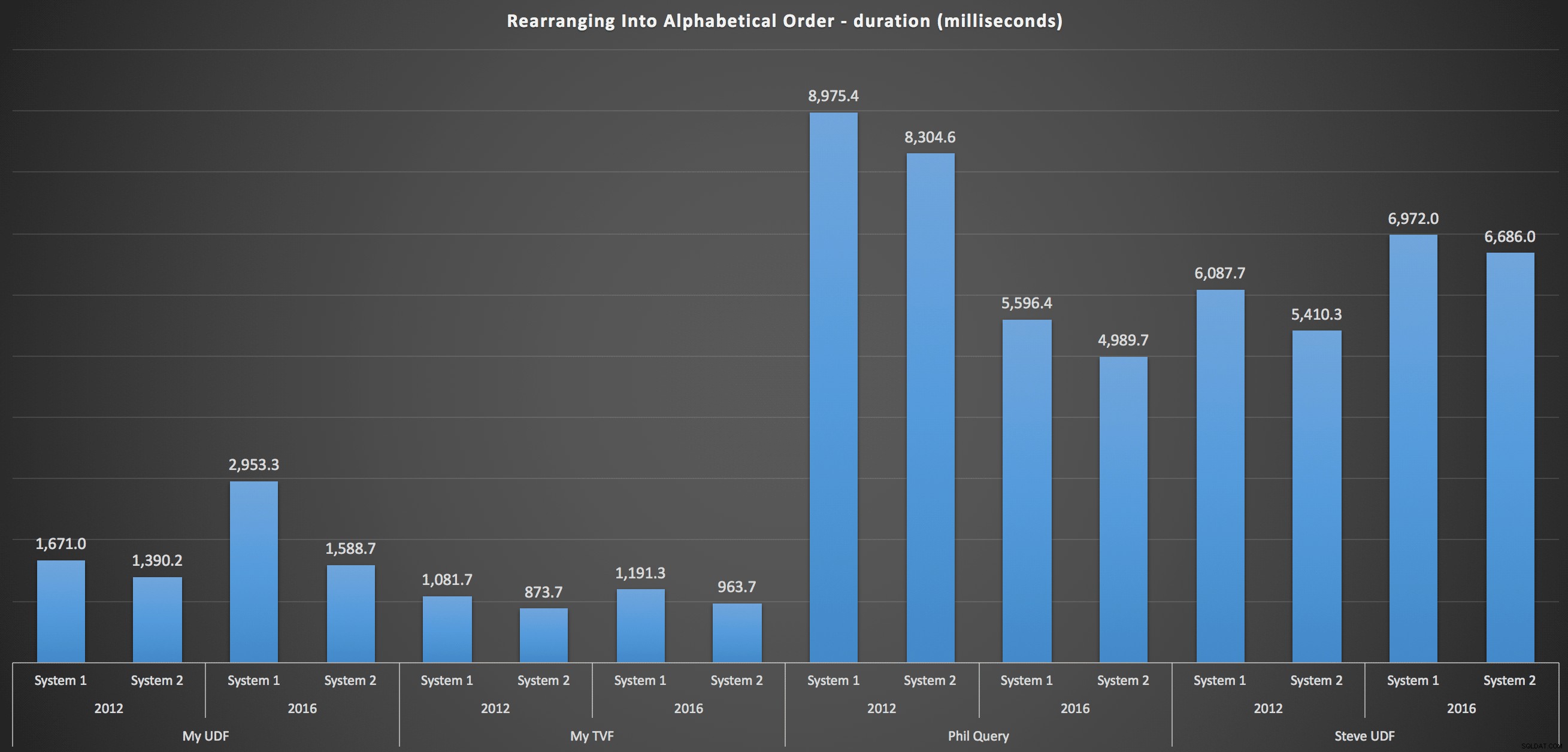
これらは、並べ替えの選択が結果にほとんど影響を与えなかったことを示しています。どちらのグラフも実質的に同じです。入力データの形式を考えると、並べ替えをより効率的にするために想像できるインデックスがないため、これは理にかなっています。これは、どのようにスライスしたり、どのようにデータを返したりしても、反復的なアプローチです。しかし、一部の反復アプローチは一般的に他のアプローチよりも悪い可能性があることは明らかであり、必ずしもUDF(または数値の表)を使用してそのようにするわけではありません。
結論
SQL Serverにネイティブの分割および連結機能が導入されるまでは、ユーザー定義関数を含め、あらゆる種類の直感的でないメソッドを使用して作業を実行します。一度に1つの文字列を処理している場合、大きな違いは見られません。ただし、データがスケールアップするにつれて、さまざまなアプローチをテストする価値があります(たとえば、上記の方法が最適であることを示唆しているわけではありません。たとえば、CLRも調べていません。このシリーズの他のT-SQLアプローチ)。