シリアル化可能 分離レベルは完全な保護を提供します データの整合性を脅かし、誤ったクエリ結果につながる可能性のある同時実行の影響から。シリアル化可能な分離を使用するということは、同時アクティビティなしで正しい結果を生成することを示すことができるトランザクションが、同時トランザクションの任意の組み合わせと競合するときに正しく実行され続けることを意味します。
これは非常に強力な保証です 、そしておそらく多くのT-SQLプログラマーの直感的なトランザクション分離の期待に一致するものです(実際には、これらの比較的少数が本番環境でシリアル化可能な分離を日常的に使用します)。
SQL標準では、はるかに弱い ACIDを提供する3つの追加の分離レベルが定義されています。 分離は、シリアル化可能よりも保証します。その見返りとして、同時実行性が高くなり、ブロッキング、デッドロック、コミット時の中止などの潜在的な副作用が少なくなります。
シリアル化可能な分離とは異なり、他の分離レベルは、観察される可能性のある特定の同時実行現象に関してのみ定義されます。シリアル化可能に次ぐ標準の分離レベルは、繰り返し可能な読み取りという名前です。 。 SQL標準では、このレベルのトランザクションでファントムと呼ばれる単一の同時実行現象が許可されると指定されています。 。
ACIDトランザクションプロパティの一般的な直感的な意味と現実の重要な違いを以前に見たように、ファントム現象には、よく理解されているよりも幅広い動作が含まれます。
シリーズのこの投稿では、繰り返し可能な読み取りによって提供される実際の保証について説明します。 分離レベルであり、発生する可能性のあるファントム関連の動作の一部を示しています。いくつかのポイントを説明するために、次の簡単なクエリ例を参照します。ここでの簡単なタスクは、テーブル内の行の総数をカウントすることです。
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
繰り返し読み取り
繰り返し可能な読み取り分離レベルの奇妙な点の1つは、ないことです。 実際には、読み取りが繰り返し可能であることを保証します 、少なくとも1つの一般的に理解されている意味で。これは、直感的な意味だけでは誤解を招く可能性がある別の例です。同じ繰り返し可能な読み取りトランザクション内で同じクエリを2回実行すると、実際には異なる結果が返される可能性があります。
それに加えて、SQL Serverの反復可能な読み取りの実装は、データセットの単一の読み取りが一部の行を見逃す可能性があることを意味します。 これは、クエリ結果で論理的に考慮する必要があります。間違いなく実装固有ですが、この動作はSQL標準に含まれる反復可能な読み取りの定義と完全に一致しています。
詳細を掘り下げる前にすぐに注意したい最後のことは、SQLServerでの繰り返し可能な読み取りはないということです。 データの特定の時点のビューを提供します。
繰り返し不可の読み取り
繰り返し可能な読み取り分離レベルは、データが変更されないことを保証します。 トランザクションの存続期間中一度読み取られた後 初めて。
その定義にはいくつかの微妙な点が含まれています。まず、後にデータを変更できます トランザクションが開始されますが、データが最初になる前 アクセスしました。第2に、トランザクションが論理的に適格なすべてのデータに実際に遭遇するという保証はありません。これらの両方の例がまもなく表示されます。
すぐに邪魔にならないようにする必要があるもう1つの予備的なものがあります。これは、使用するクエリの例と関係があります。公平を期すために、このクエリのセマンティクスは少しあいまいです。少し哲学的に聞こえるリスクがありますが、それは意味 テーブルの行数を数えるには?結果は、特定の時点でのテーブルの状態を反映する必要がありますか?この時点は、トランザクションの開始または終了、あるいは他の何かである必要がありますか?
これは少し厄介に思えるかもしれませんが、問題は、同時データ読み取りと変更をサポートするすべてのデータベースで有効なものです。サンプルクエリの実行には、任意の長い時間がかかる可能性があるため(たとえば、十分な大きさのテーブルやリソースの制約がある場合)、同時変更が可能であるだけでなく、避けられない可能性があります。 。
ここでの基本的な問題は、ファントムと呼ばれる同時実行現象の可能性です。 SQL標準で。テーブル内の行をカウントしているときに、別の同時トランザクションによって新しい行が挿入される場合があります すでに確認した場所、または変更 まだ確認していない行で、既に確認した場所に移動します。ファントムは、別のステートメントで2回目に読み取ったときに魔法のように表示される可能性のある行と考えることがよくありますが、その効果はそれよりもはるかに微妙な場合があります。
同時挿入の例
この最初の例は、同時挿入によって繰り返し不可がどのように生成されるかを示しています。 読み取りおよび/または行がスキップされる結果になります。テストテーブルに最初に5行が含まれていると想像してください。 以下に示す値を使用します:

ここで、分離レベルを繰り返し可能な読み取りに設定し、トランザクションを開始して、カウントクエリを実行します。ご想像のとおり、結果は5です。 。これまでのところ大きな謎はありません。
同じ繰り返し可能な読み取りトランザクション内で引き続き実行 、カウントクエリを再度実行しますが、今回は2番目の同時トランザクションが同じテーブルに新しい行を挿入しているときに実行します。次の図は、イベントのシーケンスを示しています。2番目のトランザクションでは、値2と6の行が追加されています(これらの値がすぐ上にないために目立つことに気付いたかもしれません):
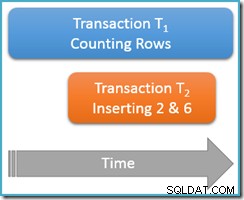
カウントクエリがシリアライズ可能で実行されていた場合 分離レベルの場合、5のいずれかをカウントすることが保証されます または7 行(その理由について復習が必要な場合は、このシリーズの前の記事を参照してください)。 孤立度の低いでの実行はどうですか 繰り返し可能な読み取りレベルは物事に影響しますか?
ええと、繰り返し可能な読み取り 分離により、カウントクエリの2回目の実行で、以前に読み取られたすべての行が表示され、以前と同じ状態になることが保証されます。キャッチは、繰り返し可能な読み取り分離が何もと言っていないことです トランザクションが新しい行(ファントム)をどのように処理するかについて。
行カウントトランザクション(T 1 )には、行がインデックスの昇順で検索される物理的な実行戦略があります。これは一般的なケースです。たとえば、順方向のbツリーインデックススキャンが実行エンジンで使用されている場合です。さて、トランザクションT 1の直後 行1と3を昇順でカウントし、トランザクションT 2 忍び込み、新しい行2と6を挿入してから、トランザクションをコミットする可能性があります。
この時点では主に論理的な動作について考えていますが、SQL Serverには、防止するための繰り返し可能な読み取りの実装のロックには何もありません。 トランザクションT2 これを行うことから。トランザクションT1によって取得された共有ロック 以前に読み取った行では、それらの行が変更されるのを防ぎますが、新しい行を防ぐことはできません。 カウントクエリによってテストされた値の範囲に挿入されないようにします(シリアル化可能な分離をロックする際のキー範囲ロックとは異なります)。
とにかく、2つの新しい行がコミットされた状態で、トランザクションT 1 昇順の検索を続行し、最終的に行4、5、6、および7に遭遇します。T 1に注意してください。 このシナリオでは新しい行6が表示されますが、表示されません 新しい行2(順序付けられた検索と、挿入が発生したときの位置による)
その結果、繰り返し可能な読み取り テーブルに6行が含まれていることをクエリレポートでカウントします (値1、3、4、5、6、および7)。この結果は、以前の5行の結果と一致していません。 同じトランザクション内で取得 。 2回目の読み取りでは、ファントム行6がカウントされましたが、ファントム行2は欠落していました。繰り返し可能な読み取りの直感的な意味については、これだけです。
同時更新の例
同様の状況は、同時の更新でも発生する可能性があります インサートの代わりに。テストテーブルがリセットされて、以前と同じ5行が含まれると想像してください。

今回は、カウントクエリを1回だけ実行します。 繰り返し可能な読み取りで 分離レベル。2番目の同時トランザクションは行を値5で更新して値2にします。
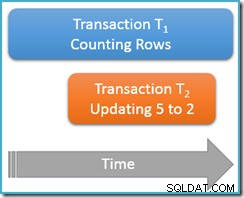
トランザクションT1 再び行のカウントを開始し、(昇順で)最初に行1と3に遭遇します。ここで、トランザクションT2がスリップインし、行5の値を2に変更して、コミットします。

変更を明確にするために、更新された行を以前と同じ位置に示しましたが、スキャンしているb-treeインデックスはデータを論理的な順序で維持しているため、実際の画像はこれに近くなります。

重要なのは、トランザクションT 1 は、この同じ構造を順方向に同時にスキャンしており、現在は直後に配置されています。 値3のエントリ。カウントクエリはそのポイントから前方にスキャンを続行し、行4と7を検索します(もちろん行5は検索しません)。
要約すると、このシナリオでは、カウントクエリで行1、3、4、および7が検出されました。 4行のカウントを報告します –これは奇妙なことです。テーブルには5行が含まれているようです。 全体!
同じ繰り返し可能な読み取りトランザクション内でカウントクエリを2回実行すると、5つが報告されます。 以前と同様の理由で、行。最後に、疑問に思われるかもしれませんが、同時削除では、繰り返し可能な読み取り分離の下でファントムベースの異常が発生する可能性はありません。
最終的な考え
前述の例は両方とも、インデックス構造の昇順スキャンを使用して、ファントムが繰り返し可能な読み取りに及ぼす可能性のある種類の影響の簡単なビューを示しています。 クエリ。これらの図は、スキャンの方向やbツリーインデックスが使用されたという事実に重要な方法で依存していないことを理解することが重要です。 しないにしてください 順序付けられたスキャンには何らかの責任があるため、回避する必要があるという見方を形成します。
同じ同時実行効果は、インデックス構造の降順スキャン、または他のさまざまな物理データアクセスシナリオで見られます。大まかに言うと、ファントム現象は、SQL標準によって、反復可能な読み取りレベルの分離でのトランザクションに対して特に許可されています(必須ではありません)。
すべてのトランザクションがシリアル化可能な分離によって提供される完全な分離保証を必要とするわけではなく、必要な場合に副作用を許容できるシステムは多くありません。それでも、さまざまな分離レベルが提供することを保証するものを正確に理解することは重要です。
次回
このシリーズの次のパートでは、SQLServerのデフォルトの分離レベルである読み取りコミットによって提供されるさらに弱い分離保証について説明します。 。
[シリーズ全体のインデックスを参照]