ほぼ1年前から今日まで、SQL Serverでのページネーションのソリューションを投稿しました。これには、CTEを使用して問題の行のセットのキー値だけを見つけ、CTEからソーステーブルに結合して取得することが含まれていました。行のその「ページ」だけの他の列。これは、ユーザーが要求した順序付けをサポートする狭いインデックスがある場合、または順序付けがクラスタリングキーに基づいているが、必要な並べ替えをサポートするインデックスがない場合でもパフォーマンスが少し向上する場合に最も有益であることがわかりました。
それ以来、ColumnStoreインデックス(クラスター化と非クラスター化の両方)がこれらのシナリオのいずれかに役立つかどうか疑問に思いました。 TL; DR :この実験だけに基づいて、この投稿のタイトルに対する答えは、はっきりとしたいいえです。 。テストのセットアップ、コード、実行計画、またはグラフを見たくない場合は、私の分析が非常に特定のユースケースに基づいていることを念頭に置いて、私の要約にスキップしてください。
セットアップ
SQL Server 2016 CTP 3.2(13.0.900.73)がインストールされた新しいVMで、以前とほぼ同じセットアップを実行しましたが、今回は3つのテーブルのみを使用しました。まず、狭いクラスタリングキーと複数のサポートインデックスを備えた従来のテーブル:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
次に、クラスター化されたColumnStoreインデックスを持つテーブル:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
そして最後に、すべての列をカバーする非クラスター化ColumnStoreインデックスを持つテーブル:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); ColumnStoreインデックスを持つ両方のテーブルについて、「PhoneBook」ソートでのより高速なシークをサポートするインデックス(姓、名)を省略していることに注意してください。
テストデータ
次に、以前の投稿で再利用したスクリプトに基づいて、最初のテーブルに1,000,000行のランダムな行を入力しました。
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; 次に、そのテーブルを使用して、他の2つにまったく同じデータを入力し、すべてのインデックスを再構築しました。
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
各テーブルの合計サイズ:
| テーブル | 予約済み | データ | インデックス |
|---|---|---|---|
| お客様 | 463,200 KB | 154,344 KB | 308,576 KB |
| Customers_CCI | 117,280 KB | 30,288 KB | 86,536 KB |
| Customers_NCCI | 349,480 KB | 154,344 KB | 194,976 KB |
そして、関連するインデックスの行数/ページ数(電子メールの一意のインデックスは、他の何よりも自分のデータ生成スクリプトをベビーシッターするためにありました):
| テーブル | インデックス | 行 | ページ |
|---|---|---|---|
| お客様 | PK_Customers | 1,000,000 | 19,377 |
| お客様 | PhoneBook_Customers | 1,000,000 | 17,209 |
| お客様 | Active_Customers | 808,012 | 13,977 |
| Customers_CCI | PK_CustomersCCI | 1,000,000 | 2,737 |
| Customers_CCI | Customers_CCI | 1,000,000 | 3,826 |
| Customers_NCCI | PK_CustomersNCCI | 1,000,000 | 19,377 |
| Customers_NCCI | Customers_NCCI | 1,000,000 | 16,971 |
手順
次に、ColumnStoreインデックスが急降下してシナリオのいずれかを改善するかどうかを確認するために、以前と同じクエリセットを実行しましたが、3つのテーブルすべてに対して実行しました。私は少なくとも少し賢くなり、動的SQLを使用して2つのストアドプロシージャを作成し、テーブルのソースと並べ替え順序を受け入れました。 (私はSQLインジェクションをよく知っています。これは、これらの文字列がエンドユーザーからのものである場合、本番環境で行うことではないので、そうすることを推奨するものと見なさないでください。これらのテストでは問題にならない密閉された環境。)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
次に、より動的なSQLを作成して、古いストアドプロシージャと新しいストアドプロシージャの両方を、必要な3つの並べ替え順序すべてで、異なるページ番号で呼び出すために必要な呼び出しのすべての組み合わせを生成しました(必要なことをシミュレートするため)。ソート順の最初、中間、および最後に近いページ)。 PRINTをコピーできるように ランタイムメトリックを取得するために、出力してSQL Sentry Plan Explorerに貼り付け、このバッチを2回実行しました。1回はprocedures P_Oldを使用したCTE 、そして再びP_CTEを使用します 。
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
これにより、次のような出力が生成されました(古いメソッド(P_Oldに対して合計36回の呼び出し) )、および新しいメソッド(P_CTEの36回の呼び出し )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
私は知っています、これはすべて非常に面倒です。すぐにパンチラインに到達することを約束します。
結果
これらの36ステートメントの2つのセットを取得し、プランエクスプローラーで2つの新しいセッションを開始し、各セットを複数回実行して、ウォームキャッシュからデータを取得し、平均を取得していることを確認しました(コールドキャッシュとウォームキャッシュも比較できますが、ここに十分な変数があります)。
サポートするグラフや計画を表示することなく、いくつかの簡単な事実をすぐに伝えることができます。
- 「古い」方法が新しいCTE方法に勝るシナリオはありませんでした どんな種類のインデックスが存在しても、以前の投稿で宣伝しました。そのため、少なくとも期間(エンドユーザーが最も気にする1つのメトリック)に関して、結果の半分を事実上無視することが容易になります。
- 結果の最後にページングするときに、ColumnStoreインデックスがうまく機能しませんでした –それらは最初にのみ、そしていくつかの場合にのみ利益を提供しました。
- 主キーで並べ替える場合 (クラスター化されているかどうかに関係なく)、ColumnStoreインデックスの存在は役に立ちませんでした –繰り返しますが、期間の観点から。
これらの要約が邪魔にならないように、期間データのいくつかの断面を見てみましょう。最初に、名前の降順でクエリの結果を並べ替え、次に電子メールで並べ替えます。既存のインデックスを使用して並べ替えることはできません。グラフからわかるように、パフォーマンスには一貫性がありませんでした。ページ数が少ない場合は、クラスター化されていないColumnStoreが最適でした。より高いページ番号では、従来のインデックスが常に勝ちました:
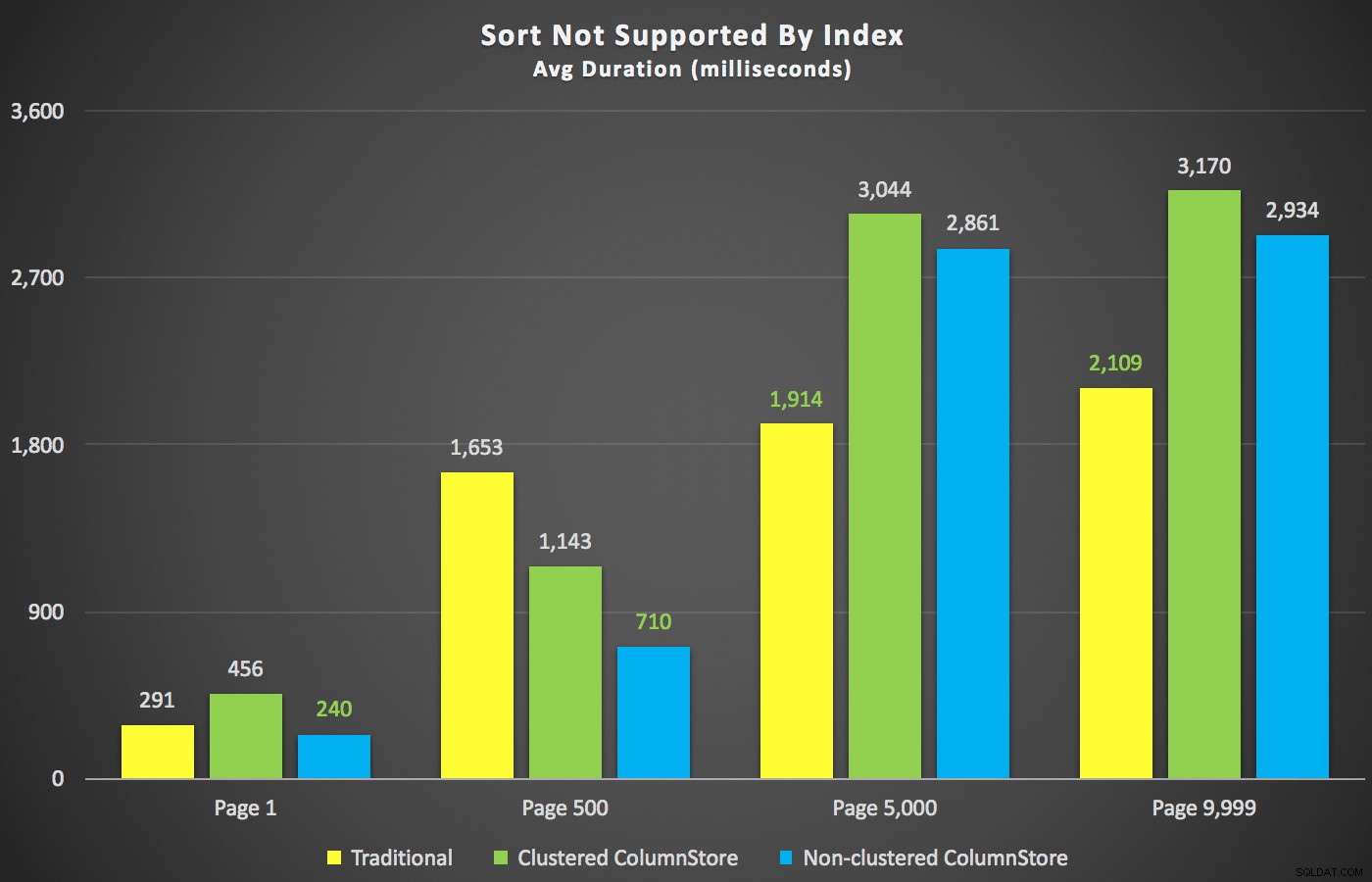 さまざまなページ番号とさまざまなインデックスタイプの期間(ミリ秒)
さまざまなページ番号とさまざまなインデックスタイプの期間(ミリ秒)
次に、3つの異なるタイプのインデックスを表す3つのプラン(プラン間の主な違いを強調するためにPhotoshopによってグレースケールが追加されています):
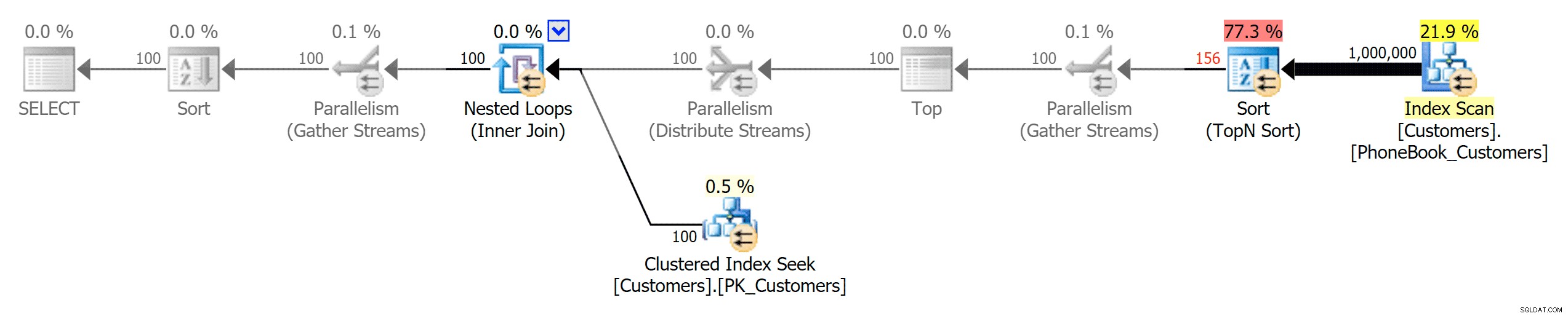


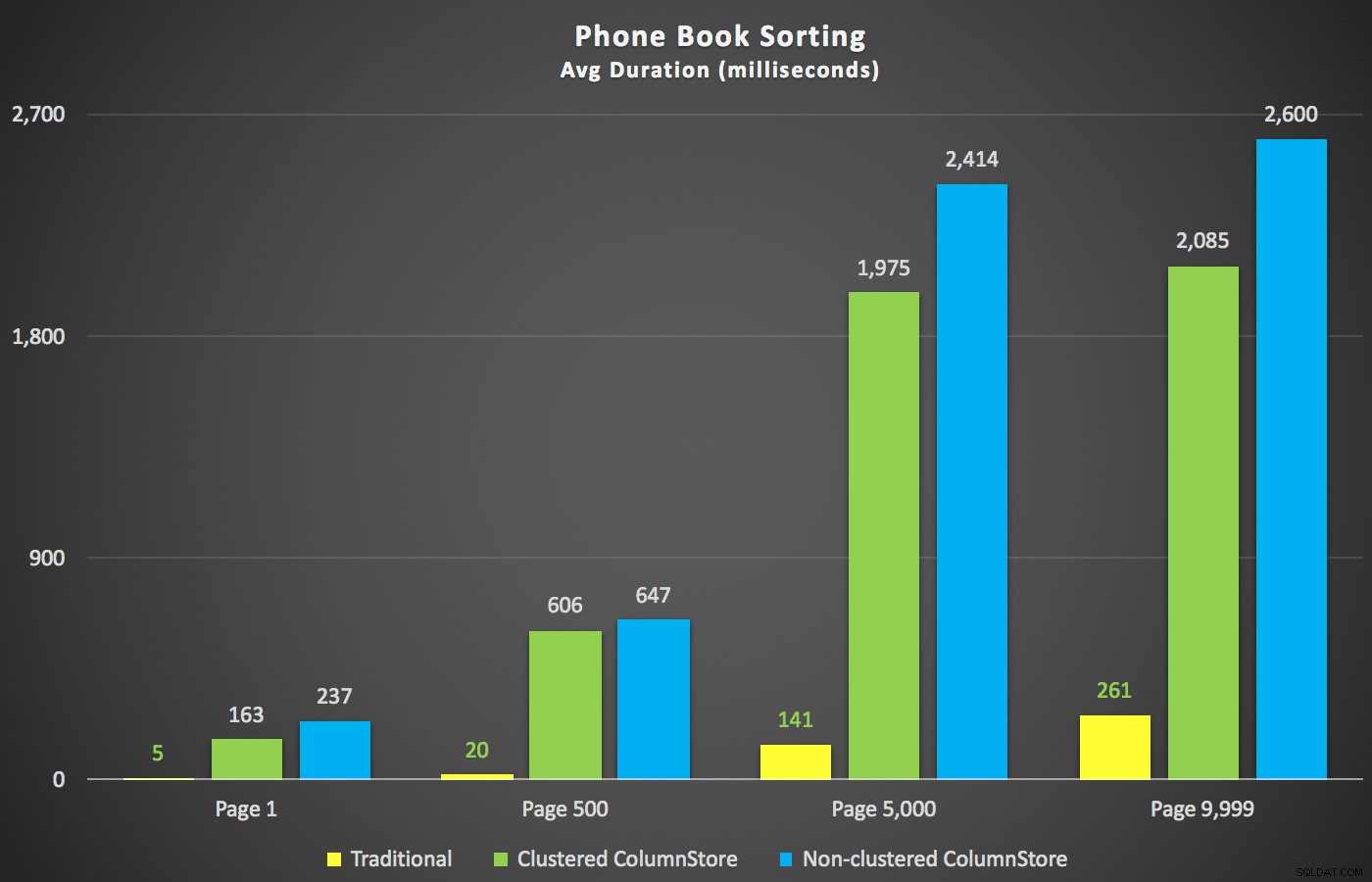
テストを開始する前から、私がもっと興味を持ったシナリオは、電話帳の並べ替えアプローチ(姓、名)でした。この場合、ColumnStoreインデックスは、実際には結果のパフォーマンスに非常に悪影響を及ぼしました。
ここでのColumnStoreプランは、サポートされていない並べ替えについて、上記の2つのColumnStoreプランのミラーイメージに近いものです。理由はどちらの場合も同じです。並べ替えをサポートするインデックスがないため、スキャンや並べ替えに費用がかかります。
そこで次に、ColumnStoreインデックスを使用してテーブルにサポートする「PhoneBook」インデックスを作成し、これらのシナリオのいずれかで別の計画や実行時間を短縮できるかどうかを確認しました。これらの2つのインデックスを作成してから、再構築しました:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
新しい期間は次のとおりです。
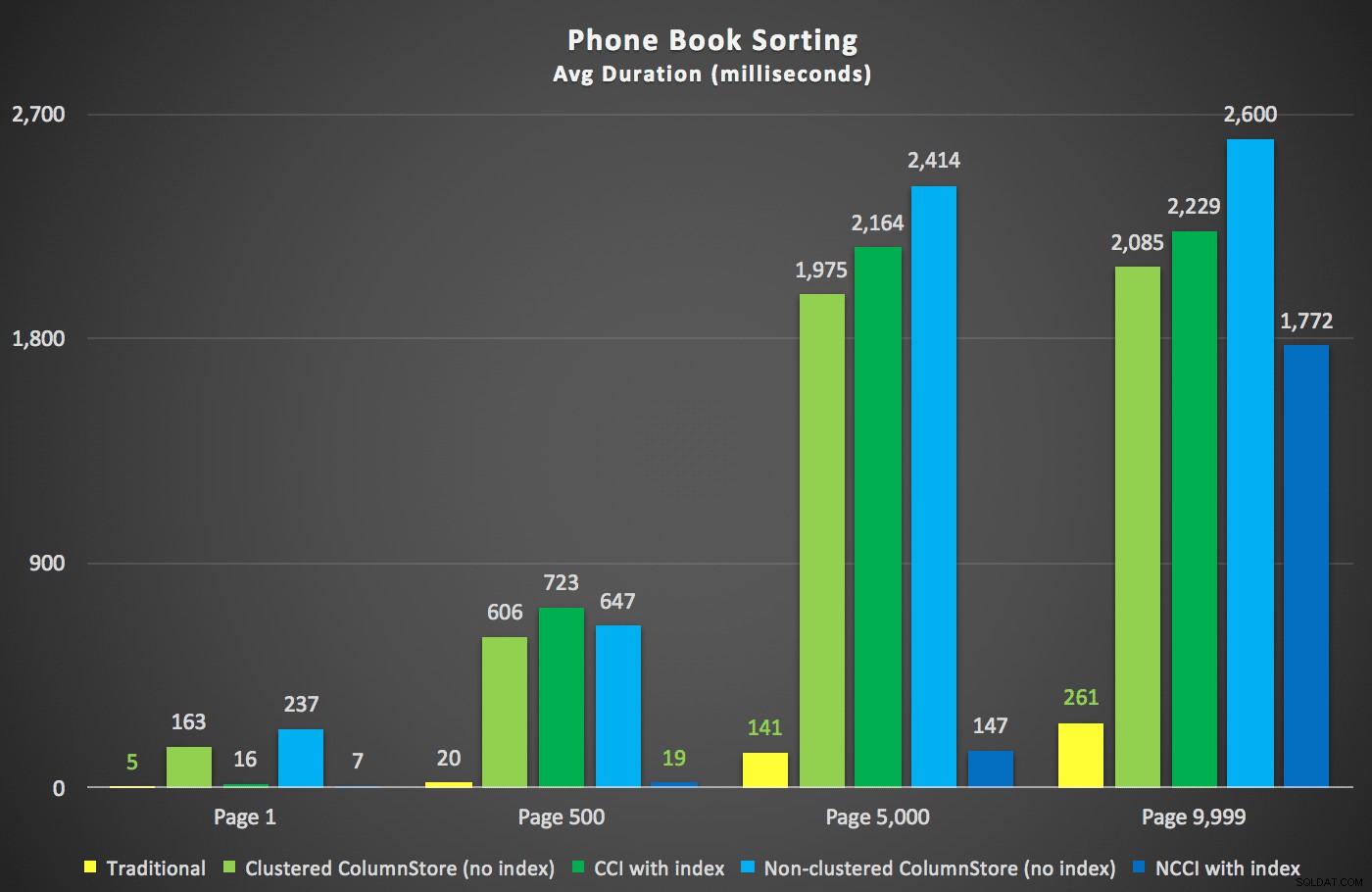
ここで最も興味深いのは、クラスター化されていないColumnStoreインデックスを持つテーブルに対するページングクエリが、テーブルの中央を超えるまで、従来のインデックスと歩調を合わせているように見えることです。計画を見ると、5,000ページで、従来のインデックススキャンが使用されており、ColumnStoreインデックスが完全に無視されていることがわかります。
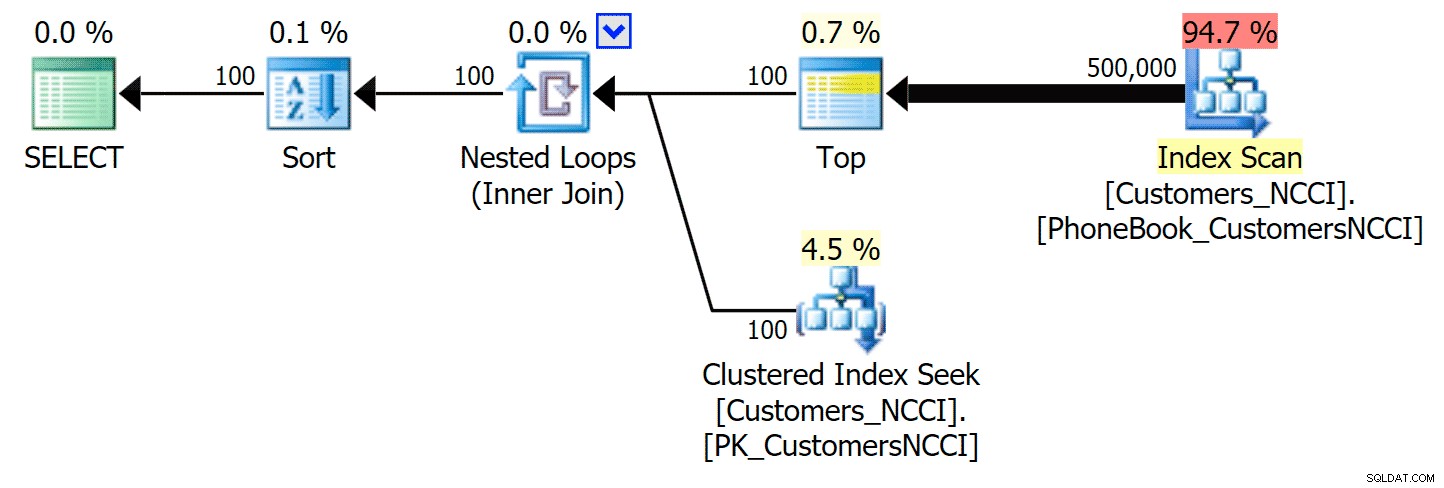
しかし、5,000ページの中間点と9,999ページのテーブルの「終わり」の間のどこかで、オプティマイザーは一種の転換点に達し、まったく同じクエリに対して、クラスター化されていないColumnStoreインデックスをスキャンすることを選択しています。 :
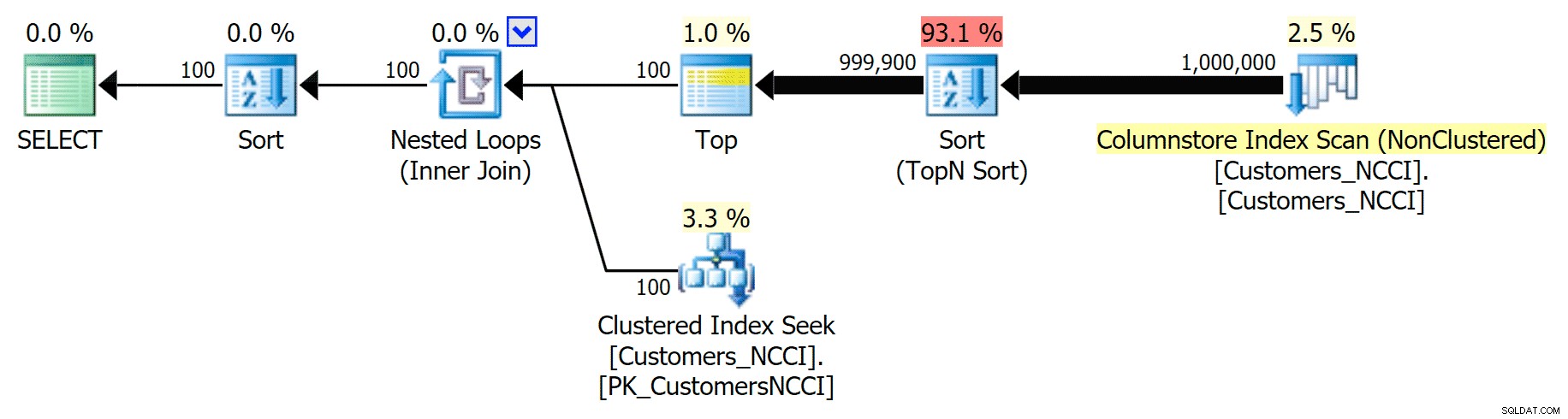 電話帳プランの「ヒント」とColumnStoreインデックスの使用
電話帳プランの「ヒント」とColumnStoreインデックスの使用
これは、主にソート操作のコストが原因で、オプティマイザーによるそれほど大きな決定ではないことが判明しました。通常のインデックスをヒントにすると、期間がどれだけ良くなるかがわかります。
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... これにより、上記の最初の計画とほぼ同じ次の計画が生成されます(ただし、出力が多いという理由だけで、スキャンのコストはわずかに高くなります):
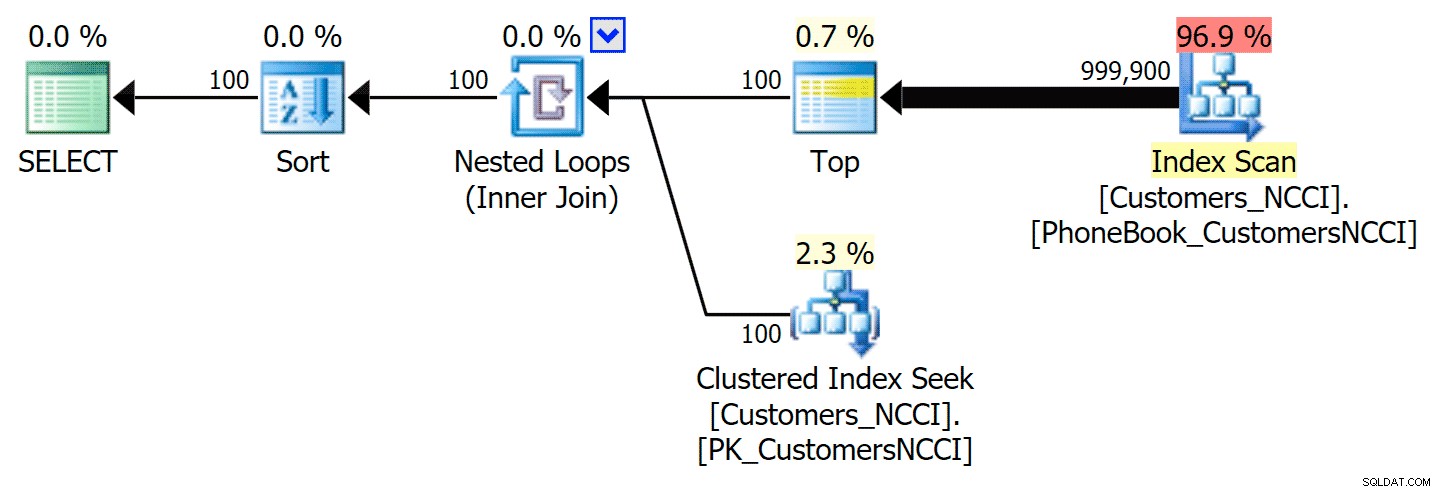
OPTION(IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX)を使用して同じことを実現できます。 明示的なインデックスヒントの代わりに。これは、そもそもColumnStoreインデックスがないことと同じであることに注意してください。
結論
上記のいくつかのエッジケースでは、ColumnStoreインデックスが(ほとんど)効果を発揮しない可能性がありますが、これらがこの特定のページネーションシナリオに適しているとは思えません。最も重要なことは、ColumnStoreは圧縮による大幅なスペース節約を示していますが、並べ替えの要件があるため、実行時のパフォーマンスは素晴らしいものではないと思います(これらの並べ替えは、SQL Server 2016の新しい最適化であるバッチモードで実行されると推定されます)。
一般に、これは調査とテストに費やす時間がはるかに長くなる可能性があります。以前の記事をピギーバックする際に、私はできるだけ変更を加えたくありませんでした。たとえば、その転換点を見つけたいと思います。また、これらは(VMのサイズとメモリの制限のために)正確に大規模なテストではないこと、そして多くのことを推測しておいたことを認めたいと思います。実行時のメトリック(主に簡潔にするためですが、継続時間に常に比例するとは限らない読み取りのチャートが実際にわかるとは限りません)。これらのテストでは、SSDの豪華さ、十分なメモリ、常にウォームキャッシュ、およびシングルユーザー環境も想定しています。シミュレートされた同時実行性を使用しながら、低速のディスクとメモリの少ないインスタンスを備えたより大きなサーバーで、より多くのデータに対してより多くのテストを実行したいと思います。
とは言うものの、これは、ColumnStoreがそもそも解決に役立つように設計されていないシナリオである可能性もあります。これは、従来のインデックスを使用した基本的なソリューションが、ColumnStoreの操舵室ではなく、狭い行のセットを引き出すのにすでにかなり効率的であるためです。おそらく、マトリックスに追加する別の変数はページサイズです。上記のすべてのテストは一度に100行をプルしますが、基になるテーブルの大きさに関係なく、一度に10,000行または100,000行を超えるとどうなりますか?
>ColumnStoreインデックスを追加するだけでOLTPワークロードが改善されたという状況はありますか?これらはデータウェアハウススタイルのワークロード向けに設計されていることは知っていますが、他の場所でメリットが見られた場合は、シナリオについて聞いて、テストリグに差別化要因を組み込むことができるかどうかを確認したいと思います。