注:この投稿は元々、eBook、SQLServerの高性能テクニック第4巻でのみ公開されていました。eBookについてはこちらをご覧ください。
「SQLServerインスタンスの調整を試みる場合、どこから始めればよいですか?」という質問を定期的に受けます。私の最初の応答は、インスタンスの構成について尋ねることです。特定のものが適切に構成されていない場合、実行時間の長いクエリや高コストのクエリをすぐに調べ始めると、無駄な労力になる可能性があります。
管理者がSQLServerのデフォルトのインストールから変更する必要のある設定の多くを共有する場合に、管理者が見逃す一般的なことについてブログを書きました。パフォーマンス関連の項目については、次のことを確認する必要があることを伝えます。
- メモリ設定
- 統計の更新
- インデックスのメンテナンス
- 並列処理のMAXDOPとコストのしきい値
- tempdbのベストプラクティス
- アドホックワークロードに最適化
構成アイテムを通り過ぎたら、ファイルと待機の統計、および高コストのクエリを確認したかどうかを尋ねます。ほとんどの場合、応答は「いいえ」です–その情報をどのように見つけるかわからないという説明があります。
通常、SQL Serverを調整する必要があると誰かが言った場合の一般的な準拠は、実行速度が遅いことです。遅いとはどういう意味ですか?それは特定のレポート、特定のアプリケーション、またはすべてですか?それはちょうど起こり始めたのですか、それとも時間とともに悪化していますか?まず、メモリ、CPU、およびディスクの使用率が正常な場合と比較されるか、問題が発生し始めたばかりか、最近何が変わったかについて、通常のトリアージの質問をします。クライアントがベースラインをキャプチャしていない限り、現在の統計が異常であるかどうかを知るために比較するメトリックがありません。
私が作業しているほぼすべてのSQLServerは、複数のユーザーデータベースをホストしています。クライアントがSQLServerの実行速度が遅いと報告すると、ほとんどの場合、顧客に問題を引き起こしている特定のアプリケーションについて懸念します。ひざまずく反応は、その特定のデータベースにすぐに集中することですが、多くの場合、別のプロセスが貴重なリソースを消費し、アプリケーションのデータベースが影響を受けている可能性があります。たとえば、大規模なレポートデータベースがあり、誰かがディスクを飽和させ、CPUをスパイクし、プランキャッシュをフラッシュする大規模なレポートを開始した場合、そのレポートの生成中に他のユーザーデータベースの速度が低下することは間違いありません。
私はいつもファイルの統計を見ることから始めるのが好きです。 SQL Server 2005以降の場合、sys.dm_io_virtual_file_stats DMVにクエリを実行して、各データとログファイルのI/O統計を取得できます。このDMVは、fn_virtualfilestats関数を置き換えました。ファイルの統計情報を取得するには、PaulRandalがまとめたスクリプトを使用するのが好きです。一定期間のIOレイテンシーを取得します。このスクリプトはベースラインをキャプチャし、30分後に(WAITFOR DELAYセクションで期間を変更しない限り)統計をキャプチャし、それらの間のデルタを計算します。 Paulのスクリプトは、読み取りと書き込みのレイテンシーを決定するために少し計算を行います。これにより、読み取りと理解がはるかに簡単になります。
私のラップトップでは、AdventureWorks2014データベースのコピーをUSBドライブに復元して、ディスク速度を遅くしました。次に、それに対して負荷を生成するプロセスを開始しました。以下の結果を見ると、データファイルの書き込みレイテンシが240ミリ秒で、ログファイルの書き込みレイテンシが46ミリ秒です。これほど高いレイテンシーは厄介です。
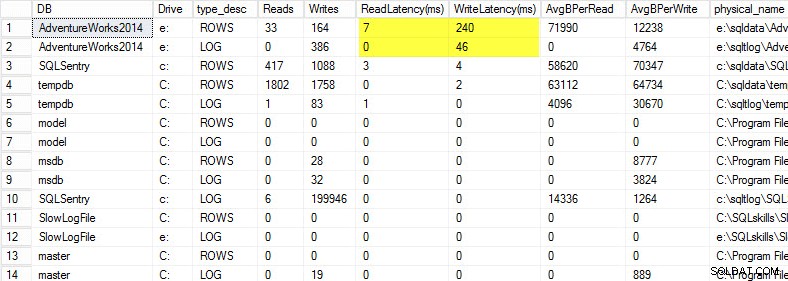
以前の投稿で共有したように、20ミリ秒を超えるものはすべて不良と見なす必要があります:読み取り/書き込みレイテンシの監視。私の読み取りレイテンシーはまともですが、AdventureWorks2014データベースは書き込みが遅いという問題があります。この場合、書き込みを生成しているものと、I/Oサブシステムのパフォーマンスを調査します。これが過度に高い読み取りレイテンシーであった場合、クエリのパフォーマンス(たとえば、インデックスの欠落からの読み取りが非常に多いのはなぜですか)と、全体的なI/Oサブシステムのパフォーマンスの調査を開始します。
I / Oサブシステムの全体的なパフォーマンスを知ることは重要であり、それが何ができるかを知る最良の方法は、ベンチマークを行うことです。 Glenn Berryは、SQLServerのI/Oパフォーマンスを分析する彼の記事でこれについて説明しています。グレンは、レイテンシー、IOPS、スループットについて説明し、ストレージのベースラインに使用できる無料のツールであるCrystalDiskMarkを紹介します。
ファイル統計のパフォーマンスを確認した後、発生したすべての待機に関する情報を返すDMV sys.dm_os_wait_statsを使用して、待機統計を確認するのが好きです。このために、PaulRandalが一定期間のブログ投稿の待機統計をキャプチャする際に提供する別のスクリプトに目を向けます。 Paulのスクリプトは、私たちのために少し計算を行いますが、さらに重要なことに、通常は気にしない多くの良性の待機を除外します。このスクリプトにもWAITFORDELAYがあり、30分に設定されています。待機統計を読み取るのは少し難しい場合があります。パーセンテージに基づいて待機が多いように見える場合もありますが、平均待機は非常に短いため、心配する必要はありません。
同じロードプロセスを開始し、以下に示す待機統計をキャプチャしました。これらの待機タイプの多くの説明については、Paulのブログ投稿の別の1つを読んだり、統計を待機したり、どこが痛いのか、およびこのブログの彼の投稿のいくつかを教えてください。
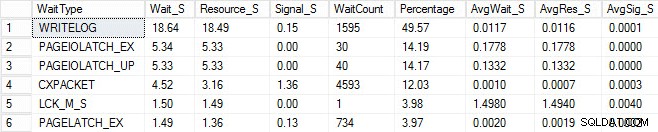
この不自然な出力では、PAGEIOLATCH待機は、I / Oサブシステムのボトルネックを示している可能性がありますが、メモリの問題、代わりにシークするテーブルスキャン、またはその他の多くの問題である可能性もあります。私の場合、データベースをUSBスティックに保存しているので、ディスクの問題であることがわかります。 LCK_M_Sの待機時間は非常に長いですが、待機のインスタンスは1つだけです。私のWRITELOGも私が見たいよりも高いですが、USBスティックの遅延の問題を知っていると理解できます。これはCXPACKETの待機も示しており、ひざまずく反応があり、並列処理/ MAXDOPの問題があると考えるのは簡単ですが、AvgWait_Sカウンターは非常に低くなっています。トラブルシューティングの待機を使用する場合は注意してください。問題ではないことを教えてくれるだけでなく、問題を探すためにどこに行くべきかについての指示を与えるためのガイドにしましょう。適切なトラブルシューティングとは、複数の領域の動作を相互に関連付けて問題を絞り込むことです。
ファイルを確認して統計を待った後、見つけた問題に基づいて高コストのクエリを掘り下げ始めます。このために、私はグレンベリーの診断情報クエリに目を向けます。これらの一連のクエリは、多くのコンサルタントが使用する頼りになるスクリプトです。グレンとコミュニティは、可能な限り情報を提供し、堅牢にするための更新を常に提供しています。私のお気に入りのクエリの1つは、実行回数でキャッシュされた上位のクエリです。高いtotal_logical_readsと相まって高いexecution_countを持つクエリまたはストアドプロシージャを見つけるのが大好きです。これらのクエリに調整の機会がある場合は、サーバーにすぐに大きな違いをもたらすことができます。また、スクリプトには、論理読み取りの合計による上位キャッシュSPと、物理読み取りの合計による上位キャッシュSPも含まれています。これらは両方とも、実行回数が多い読み取り数が多い場合に適しているため、I/Oの数を減らすことができます。
Glennのスクリプトに加えて、Adam Machanicのsp_whoisactiveを使用して、現在実行されているものを確認するのが好きです。
パフォーマンスの調整には、ファイルと待機の統計や高コストのクエリを確認するだけではありませんが、そこから始めたいと思います。これは、環境を迅速にトリアージして、問題の原因を特定し始める方法です。完全に確実に調整する方法はありません。すべての本番DBAに必要なのは、排除するために実行するもののチェックリストと、システムの状態を分析するために実行するための非常に優れたスクリプトのコレクションです。ベースラインを持つことは、正常な動作と異常な動作をすばやく除外するための鍵です。私の親友であるErinStellatoは、SQL Serverと呼ばれるPluralsightのコース全体を持っています。ベースラインの設定とキャプチャについてサポートが必要な場合は、ベンチマークとベースラインを作成します。
さらに良いことに、SQL Sentry Performance Advisorのような最先端のツールを入手して、プロファイリングとトレンド分析のための履歴情報を収集して保存するだけでなく、上記のすべての詳細に簡単にアクセスできるようにします。アクティビティを組み込みまたはユーザー定義のベースラインと比較し、指を離さずにインデックスを効率的に維持し、非常に堅牢なカスタム条件アーキテクチャに基づいて応答をアラートまたは自動化する機能。次のスクリーンショットは、パフォーマンスアドバイザダッシュボードの履歴ビューを示しています。ディスク待機はオレンジ色で、データベースI / Oは右下にあり、ベースラインはすべてのグラフの現在と前の期間を比較しています(クリックして拡大):
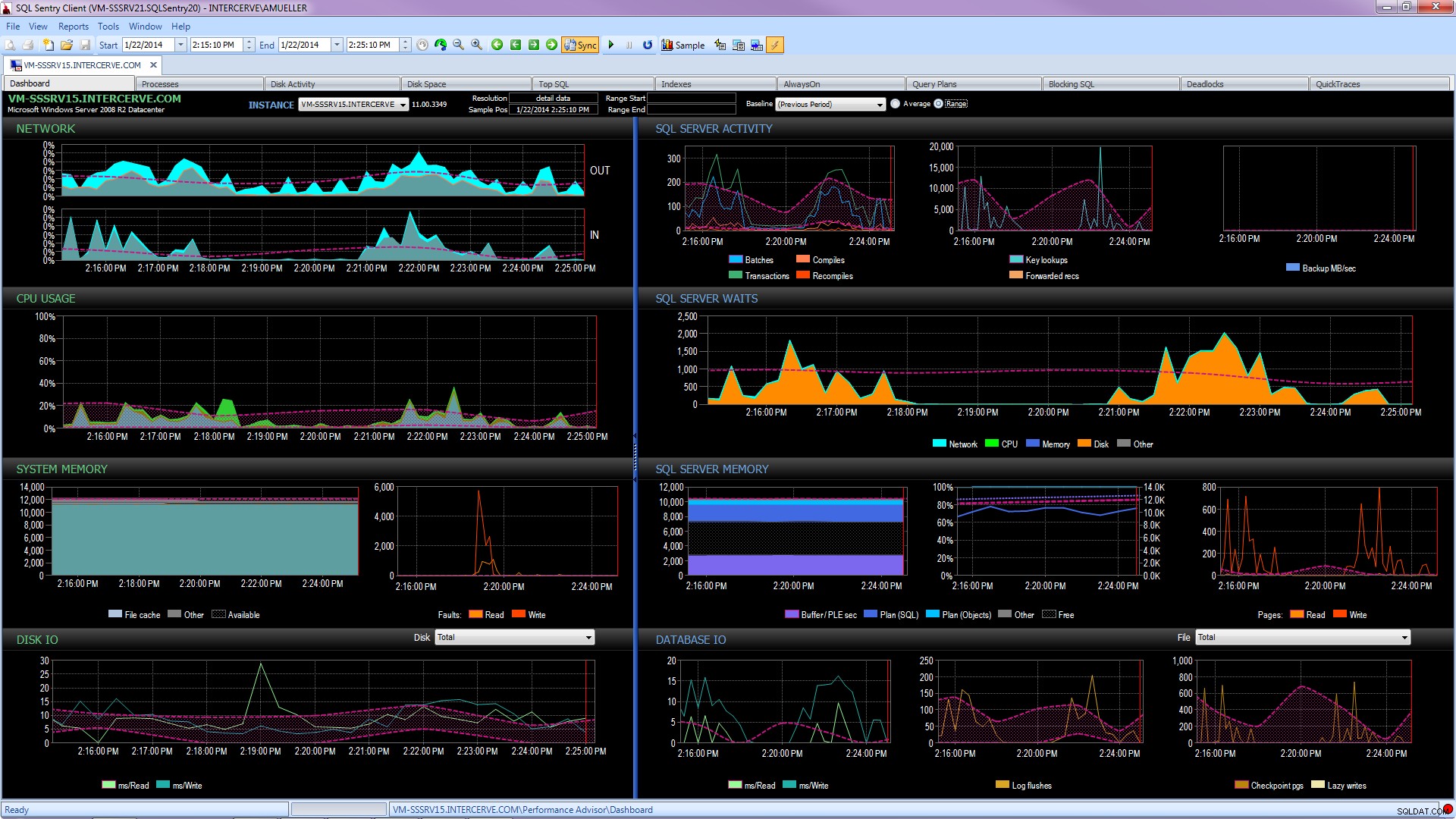
品質監視ツールは無料ではありませんが、可能性のあるクエリ、ジョブ、アラートではなく、サーバーのパフォーマンスの問題に集中できるようにする多数の機能とサポートを提供します。 パフォーマンスの問題に集中できるようになりますが、問題が正しく解決された場合に限ります。多くの場合、車輪の再発明を行わないことには大きな価値があります。