読み取り専用ファイルグループに格納されている1つ以上のパーティションでテーブルパーティションを使用すると、SQLの更新ステートメントと削除ステートメントがエラーで失敗する場合があります。もちろん、これは、変更のいずれかが読み取り専用ファイルグループへの書き込みを必要とする場合に予想される動作です。ただし、変更が読み取り/書き込みとしてマークされたファイルグループに制限されているこのエラー状態が発生する可能性もあります。
サンプルデータベース
この問題を示すために、後で読み取り専用としてマークする単一のカスタムファイルグループを使用して単純なデータベースを作成します。テストインスタンスに合わせてファイル名パスを追加する必要があることに注意してください。
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; 分配関数とスキーム
ここで、2000年1月1日より前のデータを含む行を転送する基本的なパーティショニング関数とスキームを作成します。 読み取り専用パーティションに。その後のデータは、読み取り/書き込みプライマリファイルグループに保持されます:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); 範囲右の指定は、境界値が2000年1月1日の行が読み取り/書き込みパーティションにあることを意味します。
パーティション化されたテーブルとインデックス
これで、テストテーブルを作成できます:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); テーブルの日時列にはクラスター化された主キーがあり、その列でもパーティション化されています。他の2つの整数列には、同じ方法でパーティション化された非クラスター化インデックスがあります(インデックスはベーステーブルと整列されます)。
サンプルデータ
最後に、サンプルデータの行をいくつか追加し、2000より前のデータパーティションを読み取り専用にします。
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
次のテスト更新ステートメントを使用して、読み取り専用パーティションのデータを変更できないことを確認できますが、dtのデータは変更できません。 2000年1月1日以降の値は次のように書き込むことができます:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'};の値をリセットします。 予期しない障害
2つの行があります。1つは読み取り専用(1999-12-31)です。および1つの読み取り/書き込み(2000-01-01):

次のクエリを試してください。正常に更新したのと同じ書き込み可能な「2000-01-01」行を識別しますが、異なるwhere句の述語を使用します:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
推定(実行前)計画は次のとおりです。

4つの(!)コンピューティングスカラーは、この説明では重要ではありません。これらは、クラスター化インデックス更新オペレーターに到達する各行に対して非クラスター化インデックスを維持する必要があるかどうかを判断するために使用されます。
さらに興味深いのは、この更新ステートメントが失敗するということです。 次のようなエラーが発生します:
メッセージ652、レベル16、状態1テーブル"dbo.Test"(RowsetId 72057594039042048)のインデックス "PK_dbo_Test__c1_dt"は、変更できない読み取り専用ファイルグループ( "ReadOnlyFileGroup")にあります。
パーティションの削除ではありません
以前にパーティション化を使用したことがある場合は、「パーティションの削除」が理由である可能性があると考えているかもしれません。ロジックは次のようになります:
前のステートメントでは、パーティション化列のリテラル値がwhere句で提供されていたため、SQLServerはアクセスするパーティションをすぐに決定できます。 where句を変更して、パーティショニング列を参照しないようにすることで、SQLServerがクラスター化インデックススキャンを使用してすべてのパーティションにアクセスするように強制しました。
一般的にはそれはすべて真実ですが、ここで更新ステートメントが失敗する理由ではありません。
予想される動作は、SQLServerが読み取りできる必要があることです。 クエリ実行中のすべてのパーティションから。データ変更操作は失敗のみする必要があります 実行エンジンが実際に変更しようとした場合 読み取り専用ファイルグループに保存されている行。
説明のために、前のクエリに小さな変更を加えましょう:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; where句は以前とまったく同じです。唯一の違いは、現在(意図的に)パーティショニング列をそれ自体と等しく設定していることです。これにより、その列に格納されている値は変更されませんが、結果には影響します。アップデートは成功になりました (より複雑な実行計画ではありますが):

オプティマイザーは、新しい分割、並べ替え、および折りたたみ演算子を導入し、影響を受ける可能性のある各非クラスター化インデックスを個別に維持するために必要な機構を追加しました(ワイドまたはインデックスごとの戦略を使用)。
Clustered Index Scanのプロパティは、両方のパーティションを示しています 読み取り時にアクセスされたテーブルの数:
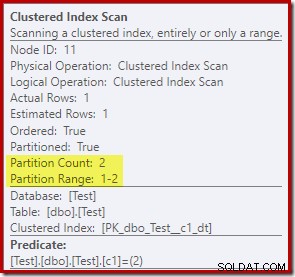
対照的に、Clustered Index Updateは、書き込みのために読み取り/書き込みパーティションのみがアクセスされたことを示しています。
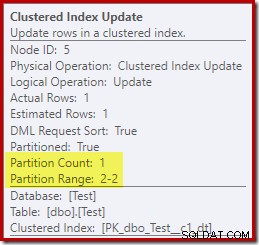
非クラスター化インデックス更新演算子のそれぞれは、同様の情報を示します。実行時に書き込み可能なパーティション(#2)のみが変更されたため、エラーは発生しませんでした。
明らかにされた理由
新しい計画は成功します成功しません 非クラスター化インデックスは個別に維持されるため。 または 一意のインデックスで一時的な重複キーエラーを回避するために必要なSplit-Sort-Collapseの組み合わせが(直接)原因ですか。
本当の理由は、前回の記事「更新クエリの最適化」で簡単に述べたものです。これは、行セット共有として知られる内部最適化です。 。これを使用すると、Clustered Index Updateは、プランの読み取り側のClustered Index Scan、Seek、またはKeyLookupと同じ基盤となるストレージエンジンの行セットを共有します。
行セット共有の最適化により、SQLServerはオフラインまたは読み取り専用のファイルグループをチェックします。 読むとき。 Clustered Index Updateが個別の行セットを使用するプランでは、オフライン/読み取り専用チェックは、更新(または削除)イテレーターで各行に対してのみ実行されます。
文書化されていない回避策
まず、面白くてこっけいな、しかし実用的でないものを邪魔にならないようにしましょう。
共有行セットの最適化は、クラスター化されたインデックスのシーク、スキャン、またはキールックアップからのルートがパイプラインである場合にのみ適用できます。 。ブロッキングまたはセミブロッキング演算子は使用できません。言い換えると、次の行が読み取られる前に、各行が読み取り元から書き込み先に到達できる必要があります。
念のため、失敗したのサンプルデータ、ステートメント、実行プランを次に示します。 再度更新:
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

ハロウィーンの保護
計画にブロッキングオペレーターを導入する1つの方法は、この更新に明示的なハロウィーン保護(HP)を要求することです。ブロッキング演算子を使用して読み取りと書き込みを分離すると、行セット共有の最適化が使用されなくなります(パイプラインなし)。文書化されておらず、サポートされていない(テストシステムのみ!)トレースフラグ8692は、明示的なHP用のEagerテーブルスプールを追加します:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
実際の実行プラン(エラーがスローされなくなったために使用可能)は次のとおりです。

以前の正常な更新で見られたSplit-Sort-Collapseの組み合わせでの並べ替えは、そのインスタンスで行セットの共有を無効にするために必要なブロックを提供します。
アンチ行セット共有トレースフラグ
行セット共有の最適化を無効にする、文書化されていない別のトレースフラグがあります。これには、潜在的に高価なブロッキング演算子を導入しないという利点があります。もちろん、実際には使用できません(Microsoftサポートに連絡して、有効にすることを推奨する書面を入手しない限り)。それにもかかわらず、娯楽目的のために、ここに動作中のトレースフラグ8746があります:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
そのステートメントの実際の実行計画は次のとおりです。

ここでの違いを理解するために、さまざまな値(必要に応じて実際に保存されている値を変更する値)を自由に試してみてください。以前の投稿で述べたように、文書化されていないトレースフラグ8666を使用して、実行プランの行セット共有プロパティを公開することもできます。
削除ステートメントで行セット共有エラーを確認する場合は、同じwhere句を使用しながら、update句とset句をdeleteに置き換えるだけです。
サポートされている回避策
トレースフラグを使用せずに、実際のクエリで行セットの共有が適用されないようにするための潜在的な方法はいくつもあります。コアの問題には共有およびパイプライン化されたクラスター化インデックスの読み取りおよび書き込みプランが必要であることがわかったので、おそらく独自のプランを考え出すことができます。それでも、ここで特に見る価値のある例がいくつかあります。
強制インデックス/カバーリングインデックス
自然な考え方の1つは、プランの読み取り側に、クラスター化されたインデックスの代わりに非クラスター化されたインデックスを使用するように強制することです。記述されているように、インデックスヒントをテストクエリに直接追加することはできませんが、テーブルのエイリアスを作成すると、次のことが可能になります。
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
where句の述語列c1に非クラスター化インデックスがあるため、これはクエリオプティマイザーが最初に選択すべきソリューションのように見えるかもしれません。実行プランは、オプティマイザーが選択した理由を示しています。
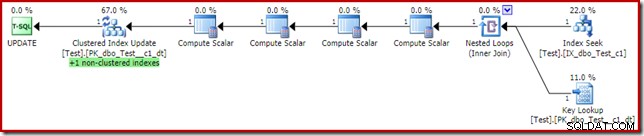
キールックアップのコストは、オプティマイザーがクラスター化されたインデックスを読み取りに使用するように説得するのに十分です。列c2の現在の値をフェッチするにはルックアップが必要であるため、ComputeScalarsは非クラスター化インデックスを維持する必要があるかどうかを判断できます。
非クラスター化インデックス(キーまたはインクルード)に列c2を追加すると、問題を回避できます。オプティマイザーは、クラスター化されたインデックスではなく、現在カバーしているインデックスを選択します。
とはいえ、どの列が必要になるかを予測したり、セットがわかっていてもそれらすべてを含めることが常に可能であるとは限りません。 c2はset句にあるため、この列が必要であることを忘れないでください 更新ステートメントの。クエリがアドホックである場合(たとえば、ユーザーによって送信された場合やツールによって生成された場合)、これを堅牢なオプションにするために、すべての非クラスター化インデックスにすべての列を含める必要があります。
上記のキールックアップを使用したプランの興味深い点の1つは、ないことです。 エラーを生成します。これは、共有行セットを使用したキールックアップとクラスター化インデックスの更新にも関わらずです。その理由は、非クラスター化インデックスシークがc1=2の行を前に配置するためです。 キールックアップはクラスター化されたインデックスにアクセスします。オフライン/読み取り専用ファイルグループの共有行セットチェックは引き続きルックアップで実行されますが、読み取り専用パーティションにはアクセスしないため、エラーはスローされません。最後の(関連する)関心のあるポイントとして、インデックスシークは両方のパーティションに接触しますが、キールックアップは1つにしかヒットしないことに注意してください。
読み取り専用パーティションを除く
簡単な解決策は、パーティションの削除に依存することです。これにより、プランの読み取り側が読み取り専用パーティションに接触することはありません。これは、明示的な述語を使用して実行できます。たとえば、次のいずれかです。
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 すべてのクエリを変更してパーティション除去述語を追加することが不可能または不便な場合は、ビューを介した更新などの他のソリューションが適している場合があります。例:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; ビューを使用することの1つの欠点は、ベーステーブルの読み取り専用部分を対象とする更新または削除が、エラーで失敗するのではなく、影響を受ける行なしで成功することです。テーブルまたはビューでトリガーを使用する代わりに、状況によってはその回避策になる場合がありますが、さらに問題が発生する可能性もあります…しかし、私は逸脱します。
前述のように、サポートされる可能性のあるソリューションは多数あります。この記事のポイントは、行セットの共有がどのように予期しない更新エラーを引き起こしたかを示すことです。