インデックス作成は何をしますか?
インデックス付けは、順序付けされていないテーブルを、検索中のクエリの効率を最大化する順序にする方法です。
テーブルのインデックスが作成されていない場合、クエリでは行の順序が最適化されていると認識できない可能性が高いため、クエリは行を直線的に検索する必要があります。つまり、クエリはすべての行を検索して、条件に一致する行を見つける必要があります。ご想像のとおり、これには長い時間がかかる場合があります。すべての行を調べるのはあまり効率的ではありません。
たとえば、次の表は、完全に順序付けされていない架空のデータソースの表を表しています。
| company_id | ユニット | unit_cost |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1.95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
次のクエリを実行する場合:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
データベースは、17行すべてを、テーブルに表示される順序で、上から下に1つずつ検索する必要があります。したがって、company_idの潜在的なインスタンスをすべて検索するには 番号18、データベースはcompany_id内の18のすべての出現をテーブル全体で調べる必要があります 列。
これは、テーブルのサイズが大きくなるにつれて、ますます時間がかかるようになります。データの高度化に伴い、最終的に発生する可能性があるのは、10億行のテーブルが10億行の別のテーブルに結合されることです。クエリは、2倍の時間を費やして2倍の量の行を検索する必要があります。
これまでのデータ飽和の世界でこれがどのように問題になるかがわかります。テーブルのサイズが大きくなり、検索の実行時間が長くなります。
インデックス付けされていないテーブルを視覚的に表示した場合、クエリは次のようになります。
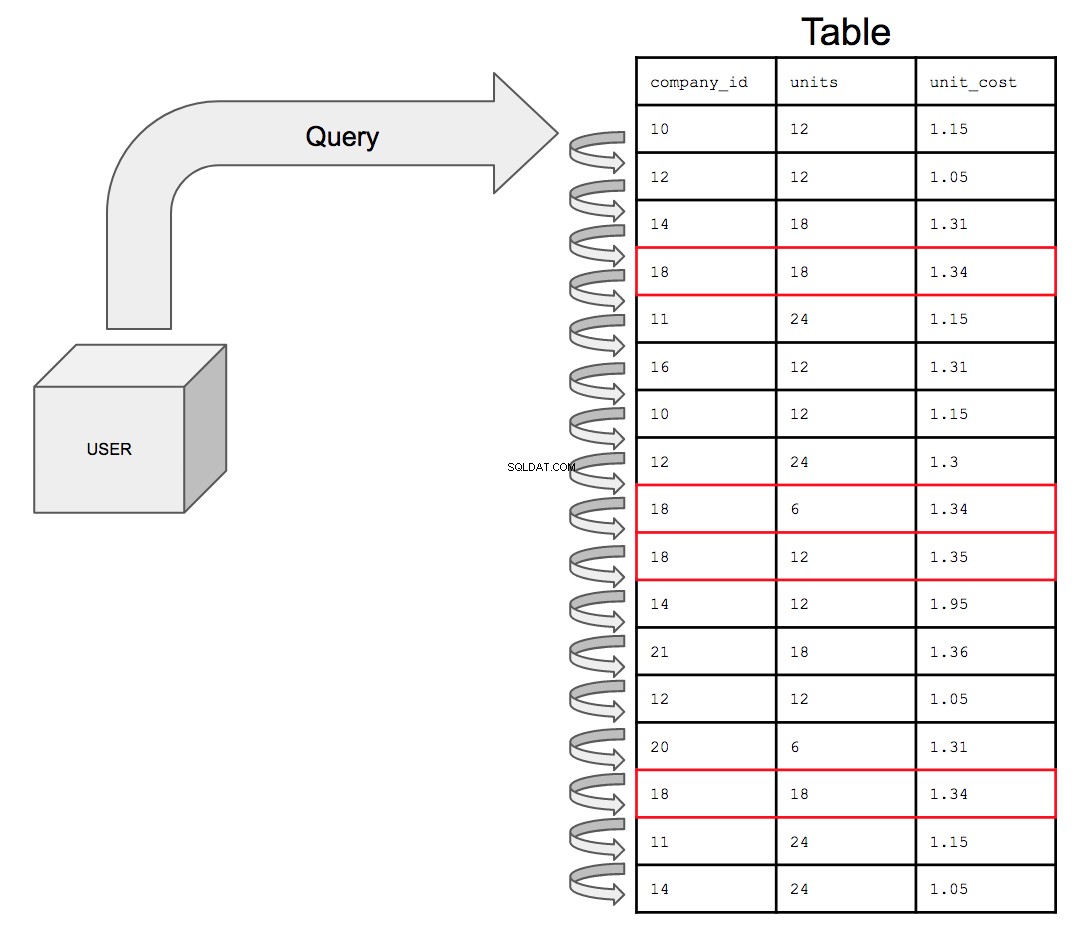
インデックス作成では、検索条件が表示されている列を並べ替えられた順序で設定して、クエリのパフォーマンスを最適化できるようにします。
company_idにインデックスを付ける 列の場合、テーブルは基本的に次のように「表示」されます。
| company_id | ユニット | unit_cost |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1.95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
これで、データベースはcompany_idを検索できます。 18に番号を付け、その行に要求されたすべての列を返し、次の行に移動します。次の行のcomapny_idの場合 数値も18の場合、クエリで要求されたすべての列が返されます。次の行のcompany_idの場合 20の場合、クエリは検索を停止することを認識し、クエリは終了します。
インデックス作成はどのように機能しますか?
実際には、クエリのパフォーマンスを最適化するために、クエリ条件が変更されるたびにデータベーステーブルが並べ替えられるわけではありません。これは非現実的です。実際には、インデックスによってデータベースがデータ構造を作成します。データ構造タイプはBツリーである可能性が非常に高いです。 Bツリーの利点は数多くありますが、私たちの目的の主な利点は、ソート可能であるということです。データ構造を順番に並べ替えると、上記で指摘した明らかな理由により、検索がより効率的になります。
インデックスが特定の列にデータ構造を作成する場合、他の列はデータ構造に格納されないことに注意することが重要です。上記の表のデータ構造には、company_idのみが含まれます。 数字。ユニットとunit_cost データ構造には保持されません。
データベースは、テーブル内の他のどのフィールドを返すかをどのように認識しますか?
データベースインデックスには、メモリ内の追加情報の場所の単なる参照情報であるポインタも格納されます。基本的に、インデックスはcompany_idを保持します そして、メモリディスク上のその特定の行のホームアドレス。インデックスは実際には次のようになります:
| company_id | ポインタ |
|---|---|
| 10 | _ 123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _ 138 |
| 12 | _ 124 |
| 12 | _ 130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _ 131 |
| 14 | _ 133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _ 131 |
| 18 | _132 |
| 18 | _ 137 |
| 20 | _ 136 |
| 21 | _ 134 |
そのインデックスを使用すると、クエリはcompany_idの行のみを検索できます。 18の列があり、ポインターを使用すると、テーブルに移動して、そのポインターが存在する特定の行を見つけることができます。次に、クエリはテーブルに移動して、条件を満たす行に要求された列のフィールドを取得できます。
検索が視覚的に表示された場合、次のようになります。
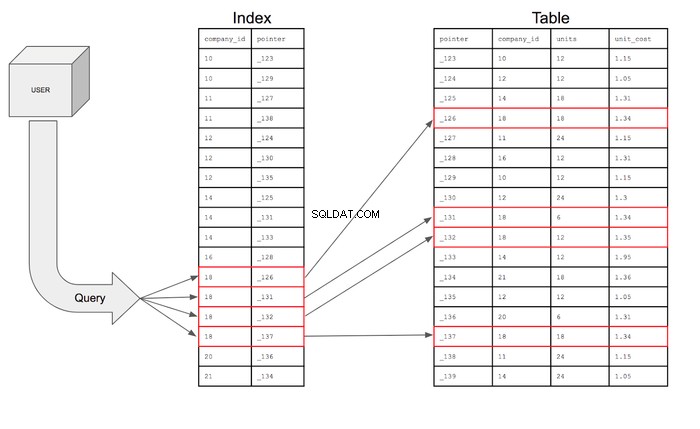
- インデックス作成により、検索条件の列とポインターを含むデータ構造が追加されます
- ポインタは、残りの情報を含む行のメモリディスク上のアドレスです
- インデックスデータ構造は、クエリの効率を最適化するために並べ替えられます
- クエリはインデックス内の特定の行を検索します。インデックスは、残りの情報を見つけるポインタを参照します。
- インデックスにより、クエリが検索する必要のある行数が17行から4行に減ります。