
T-SQL Tuesday#78はWendy Pastrickによってホストされており、今月の課題は単に「何か新しいことを学び、それについてブログを書く」ことです。彼女の宣伝文句はSQLServer2016の新機能に傾いていますが、私はそれらの多くについてブログに書いたり発表したりしていたので、私がいつも本当に興味を持っていた他の何かを直接探求したいと思いました。
特定のシナリオでは、ヒープがクラスター化されたインデックスよりも優れている可能性があると複数の人が述べているのを見てきました。私はそれに反対することはできません。しかし、私が見た興味深い理由の1つは、RIDルックアップがキールックアップよりも高速であるということです。私はクラスター化インデックスの大ファンであり、ヒープの大ファンではないので、これにはいくつかのテストが必要だと感じました。
では、テストしてみましょう!
1つはクラスター化された主キーを持ち、もう1つはクラスター化されていない主キーを持っていることを除いて、2つのテーブルを使用してデータベースを作成するのがよいと思いました。いくつかの行をテーブルにロードし、ループ内の一連の行を更新し、インデックスから選択する(キーまたはRIDルックアップのいずれかを強制する)時間を計ります。
システム仕様
この質問はよく出てくるので、このシステムに関する重要な詳細を明確にするために、私はPCIeストレージに支えられた32GBのRAMを備えた8コアVMを使用しています。 SQLServerのバージョンは2014SP1CU6であり、特別な構成の変更やトレースフラグは実行されていません:
Microsoft SQL Server 2014(SP1-CU6)(KB3144524)– 12.0.4449.0(X64)2016年4月13日12:41:07
Copyright(c)Microsoft Corporation
Developer Edition(64-ビット)Windows NT 6.3
データベース
自動拡張イベントがテストに干渉するのを防ぐために、データとログファイルの両方に十分な空き領域があるデータベースを作成しました。また、トランザクションログへの影響を最小限に抑えるために、データベースを単純リカバリに設定しました。
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
テーブル
私が言ったように、主キーがクラスター化されているかどうかだけが異なる2つのテーブル。
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
ランタイムをキャプチャするためのテーブル
CPUとそのすべてを監視することはできましたが、実際の好奇心はほとんどの場合実行時にあります。そこで、各テストの実行時間をキャプチャするためのロギングテーブルを作成しました:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
挿入テスト
では、2,000行を100回挿入するのにどのくらい時間がかかりますか? sys.all_objectsからかなり基本的なデータを取得しています 、および手順、機能などの定義を引き出します。
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; 更新テスト
更新テストでは、クラスター化インデックスへの書き込み速度とヒープへの書き込み速度を行ごとにテストしたかっただけです。そこで、200行のランダムな行を#tempテーブルにダンプし、その周りにカーソルを作成しました(#tempテーブルは、テーブルの両方のバージョンで同じ200行が更新されることを保証するだけであり、おそらくやり過ぎです)。
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; 選択テスト
したがって、上記で、Nameを使用してインデックスを作成したことがわかりました。 各テーブルのキー列として。大量の行のルックアップを実行するコストを評価するために、出力を変数に割り当てる(ネットワークI / Oとクライアントのレンダリング時間を排除する)クエリを作成しましたが、インデックスの使用を強制します:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; これについては、テスト結果を照合する前に、計画のいくつかの興味深い側面を示したいと思いました。それらを個別に直接実行すると、次の比較指標が提供されます。

期間は単一のステートメントにとって重要ではありませんが、それらの読み取りを見てください。低速のストレージを使用している場合、これは小規模なものやローカル開発用SSDでは見られない大きな違いです。
次に、SQL Sentry Plan Explorerを使用して、2つの異なるルックアップを示すプラン:

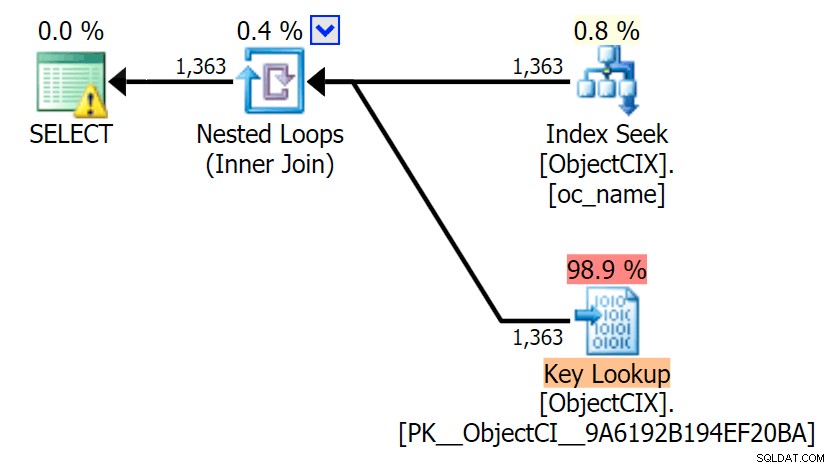
計画はほぼ同じように見え、Statistics I / Oをキャプチャしていない限り、SSMSでの読み取りの違いに気付かない場合があります。 2つのルックアップの推定I/Oコストでさえ、類似していた–キールックアップで1.69、RIDルックアップで1.59。 (両方のプランの警告アイコンは、カバーインデックスがないことを示しています。)
ルックアップを強制せず、SQL Serverが何をすべきかを決定できるようにすると、どちらの場合も標準スキャンが選択されます。インデックスの欠落の警告はなく、読み取りがどれだけ近いかを確認します。

オプティマイザーは、この場合、スキャンがシーク+ルックアップよりもはるかに安価になることを知っています。効果のためだけに変数の割り当てにLOB列を選択しましたが、非LOB列を使用した場合も結果は同様でした。
テスト結果
Timingsテーブルを配置すると、テストを複数回簡単に実行でき(12個のテストを実行しました)、次のクエリを使用してテストの平均を取得できました。
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
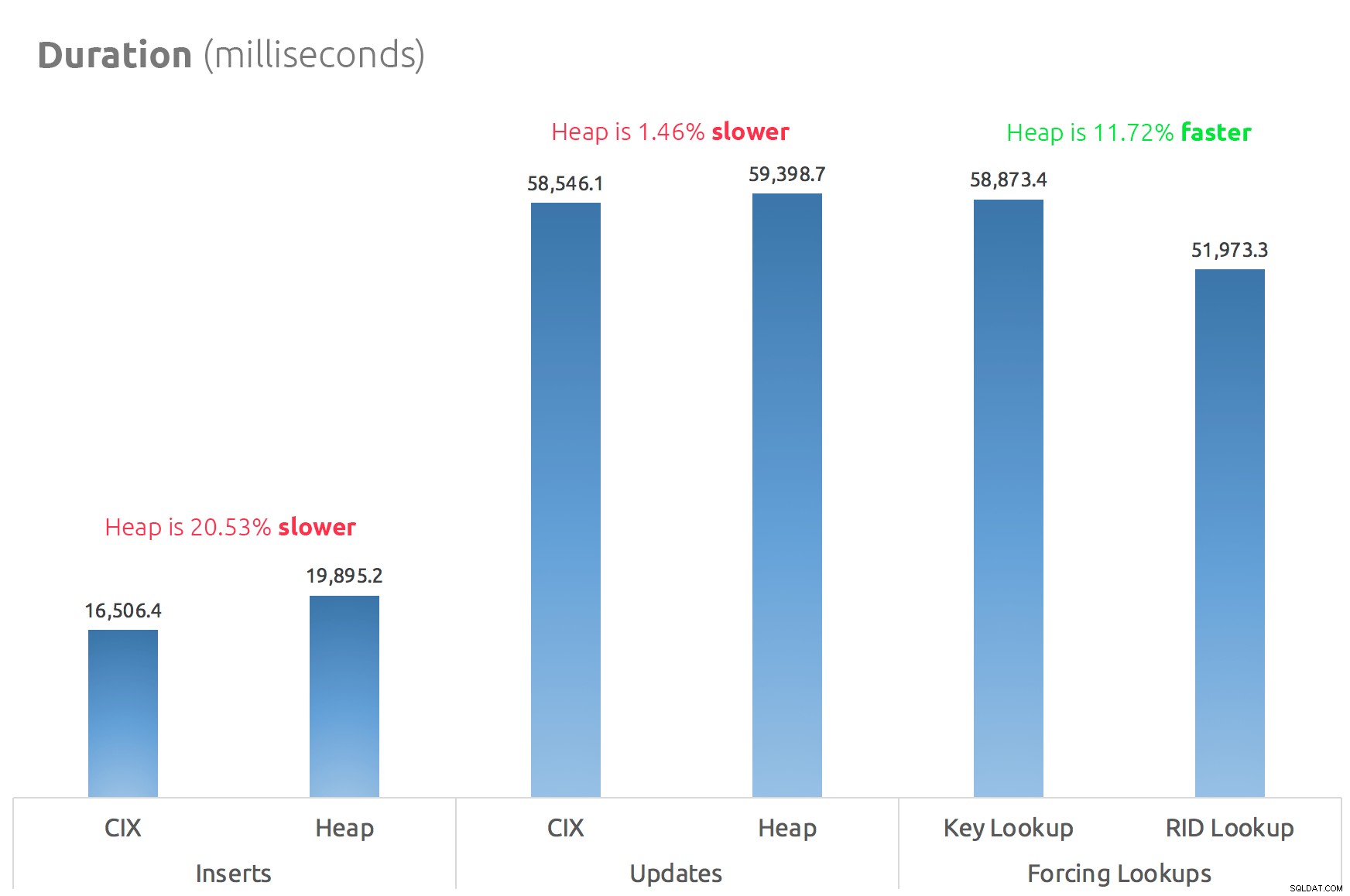
簡単な棒グラフは、それらがどのように比較されるかを示しています。
結論
したがって、噂は真実です。少なくともこの場合、RIDルックアップはキールックアップよりも大幅に高速です。 file:page:slotに直接移動すると、BツリーをたどるよりもI / Oの点で明らかに効率的です(最新のストレージを使用していない場合は、デルタがはるかに目立つ可能性があります)。
それを利用し、他のすべてのヒープの側面を取り入れたいかどうかは、ワークロードによって異なります。ヒープは、書き込み操作に少しコストがかかります。しかし、これはではありません 決定的–これは、テーブル構造、インデックス、およびアクセスパターンによって大きく異なる可能性があります。
ここでは非常に単純なことをテストしました。これについて気が向いている場合は、実際のワークロードを自分のハードウェアでテストして自分で比較することを強くお勧めします(カバーするインデックスが存在する場合は同じワークロードをテストすることを忘れないでください。ルックアップを完全に排除できれば、全体的なパフォーマンスが大幅に向上する可能性があります)。重要なすべての指標を必ず測定してください。私が期間に焦点を合わせているからといって、それがあなたが最も気にする必要があるものであるという意味ではありません。 :-)