一般的に言って、ソートの最良の種類は完全に回避されるものです。注意深いインデックス作成と、場合によってはクリエイティブなクエリの記述により、実行プランから並べ替え演算子の必要性を排除できることがよくあります。並べ替えるデータが大きい場合、この種の並べ替えを回避すると、パフォーマンスが大幅に向上する可能性があります。
2番目に優れた種類のソートは、回避できないものですが、適切な量のメモリを予約し、そのすべてまたはほとんどを使用して価値のあることを実行します。 価値がある 多くの形を取ることができます。場合によっては、ソートされた入力に対してはるかに効率的に機能する後の操作を有効にすることで、ソートがそれ自体の代償を超えることがあります。また、並べ替えが必要な場合もあります。可能な限り効率的にする必要があります。
次に、通常は避けたいソートがあります。必要以上に多くのメモリを予約するソートと、予約が少なすぎるソートです。後者の場合は、ほとんどの人が注目するケースです。メモリ内で必要な並べ替え操作を完了するために予約された(または使用可能な)メモリが不十分な場合、並べ替え演算子は、いくつかの例外を除いて、データ行を tempdbにスピルします。 。実際には、これはほとんどの場合、ソートページを物理ストレージに書き込むことを意味します(もちろん、後でそれらを読み戻すことも意味します)。
SQL Serverの最新バージョンでは、こぼれた並べ替えにより、実行後の計画に警告アイコンが表示されます。これには、こぼれたデータの量、関与したスレッドの数、およびこぼれたレベルに関する詳細が含まれる場合があります。
背景:流出レベル
使用可能なメモリが500MBしかない場合に、4000MBのデータを並べ替えるタスクを検討してください。もちろん、メモリ内のセット全体を一度に並べ替えることはできませんが、タスクを分割することはできます:
最初に500MBのデータを読み取り、そのセットをメモリに並べ替えてから、結果をディスクに書き込みます。これを合計8回実行すると、4000MBの入力全体が消費され、500MBのサイズのソートされたデータが8セット生成されます。 2番目のステップは、ソートされたデータセットの8方向のマージを実行することです。 マージに注意してください データは中間段階の特定の500MBセット内で必要に応じてソートされることが保証されているため、セットの単純な連結ではなく、が必要です。
原則として、8回のソート実行のそれぞれから一度に1行を読み取ってマージすることはできますが、これはあまり効率的ではありません。代わりに、各ソートの最初の部分を読み取り、メモリに戻します。たとえば、60MBです。これは、利用可能な500MBのうち8 x 60MB=480MBを消費します。その後、しばらくの間、メモリ内で8ウェイマージを効率的に実行し、最終的にソートされた出力を、まだ使用可能な20MBのメモリでバッファリングできます。各ソート実行メモリバッファが空になると、そのソート実行の新しいセクションがメモリに読み込まれます。すべての並べ替えの実行が完了すると、並べ替えが完了します。
含めることができるいくつかの追加の詳細と最適化がありますが、それはシングルパススピルとしても知られているレベル1スピルの基本的な概要です。最終的にソートされた出力を生成するには、データを1回余分にパスする必要があります。
現在、n-wayマージは、ローカルでソートされた中間セットの数を増やすだけで、理論的には任意のサイズ、任意の量のメモリに対応できます。問題は、「n」が増えると、データの小さなチャンクの読み取りと書き込みが行われることです。たとえば、400GBのデータを500MBのメモリに並べ替えるということは、800ウェイのマージのようなものであり、一度にメモリ内の並べ替えられた各中間セットから約0.6MBしかありません(800 x 0.6MB =480MB、出力バッファ)。
これを回避するには、複数のマージパスを使用できます。一般的な考え方は、最終的にソートされた出力ストリームを効率的に生成できるようになるまで、小さなチャンクを徐々に大きなチャンクにマージすることです。この例では、これは、一度に800個のファーストパスソートセットのうち40個をマージし、20個の大きなチャンクを生成し、それを再度マージして出力を形成することを意味する場合があります。データに対して合計2回の追加パスがある場合、これはレベル2の流出になります。幸いなことに、流出レベルを直線的に増加させると、ソートサイズが指数関数的に増加するため、ソートの流出レベルを深くする必要はほとんどありません。
「レベル15,000」の流出
この時点で、小さなメモリ許可と巨大なデータサイズのどのような組み合わせがレベル15,000のソートスピルを引き起こす可能性があるのか疑問に思われるかもしれません。インターネット全体を1MBのメモリに分類しようとしていますか?可能性はありますが、それをデモするのは非常に困難です。正直なところ、SQLServerでこのような本当に高い流出レベルが可能かどうかはわかりません。ここでの目標(確かにチート)は、SQLServerにレポートをさせることです。 レベル15,000の流出。
重要な要素は分割です。 SQL Server 2012以降、オブジェクトごとに(便利な)最大15,000パーティションが許可されています(15,000パーティションのサポートは2008SP2および2008R2 SP1でも利用できますが、データベースごとに手動で有効にする必要があり、すべてに注意する必要があります。警告)。
最初に必要なのは、15,000要素のパーティション関数と関連するパーティションスキームです。本当に巨大なインラインコードブロックを回避するために、次のスクリプトは動的SQLを使用して必要なステートメントを生成します。
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); スクリプトは、セットアップが15,000パーティションで問題が発生した場合に備えて、より少ない数に変更するのに十分簡単です(特に、後で説明するように、メモリの観点から)。次の手順は、単一の整数列を持つ通常の(パーティション化されていない)ヒープテーブルを作成し、1〜15,000を含む整数をそのテーブルに入力することです。
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; それは100msかそこらで完了するはずです。利用可能な数値テーブルがある場合は、代わりにそれを自由に使用して、よりセットベースのエクスペリエンスを実現してください。ベーステーブルへの入力方法は重要ではありません。 15,000レベルのスピルを取得するには、テーブルにパーティション化されたクラスター化インデックスを作成するだけです。
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
実行時間は、使用しているストレージシステムに大きく依存します。私のラップトップでは、数年前のかなり一般的なコンシューマーSSDを使用すると、約20秒かかります。これは、合計で15,000行しか処理していないことを考えるとかなり重要です。かなりひどいI/Oパフォーマンスを備えたかなり低スペックのAzureVMでは、同じテストに20分近くかかりました。
分析
インデックスビルドの実行プランは次のとおりです。
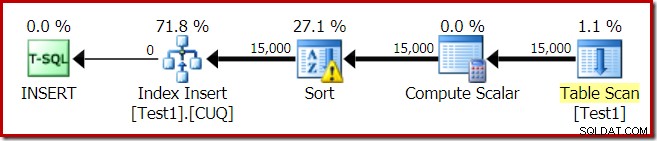
テーブルスキャンは、ヒープテーブルから15,000行を読み取ります。 Compute Scalarは、内部関数RangePartitionNew()を使用して、各行の宛先インデックスパーティション番号を計算します。 。並べ替えは計画の中で最も興味深い部分なので、詳しく見ていきます。
まず、プランエクスプローラーに表示される並べ替えの警告:

SSMSからの同様の警告(スクリプトの別の実行から取得):
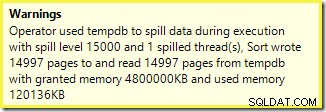
最初に注意することは、約束されたように、15,000ソートの流出レベルの報告です。これは完全に正確ではありませんが、詳細は非常に興味深いものです。このプランの並べ替えには、Partition IDがあります 通常は存在しないプロパティ:
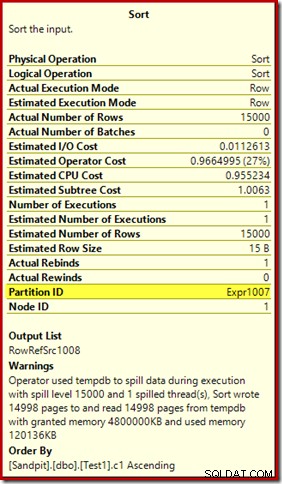
このプロパティは、ComputeScalarの内部パーティショニング関数の定義と同じに設定されます。
これは非同盟のインデックスビルドです 、ソースと宛先のパーティション配置が異なるためです。この場合、ソースヒープテーブルはパーティション化されていませんが、宛先インデックスはパーティション化されているため、この違いが生じます。結果として、実行時に15,000の個別のソートが作成されます。空でないターゲットパーティションごとに1つです。これらの各ソートスピルはレベル1になり、SQL Serverはこれらすべてのスピルを合計して、最終的なソートスピルレベルを15,000にします。
15,000の個別のソートは、大容量メモリの付与を説明します。各ソートインスタンスの最小サイズは40ページで、40 x 8KB=320KBです。したがって、15,000ソートには、最低でも15,000 x 320KB=4,800,000KBのメモリが必要です。これは、単一の整数列を含む15,000行をソートするクエリ専用に予約されている4.6GBのRAMを恥ずかしがり屋です。そして、1行しか受け取らないにもかかわらず、各ソートはディスクに流出します!インデックスの構築に並列処理が使用された場合、メモリの付与はスレッドの数によってさらに膨らむ可能性があります。また、単一の行が1ページに書き込まれることにも注意してください。これは、tempdbに書き込まれたページとtempdbから読み取られたページの数を示しています。報告されたページ数が15,000未満であることが多いことを意味する、競合状態があるようです。
もちろん、この例はエッジケースを反映していますが、各ソートが、指定されたメモリでソートするのではなく、単一の行をスピルする理由を理解するのは依然として困難です。おそらくこれは何らかの理由で設計によるものであるか、または単にバグである可能性があります。いずれにせよ、4.6GBのメモリ許可と15,000レベルの流出で、ある種の数百KBのデータに非常に長い時間がかかるのを見るのはまだ非常に面白いです。実稼働環境で遭遇しない限り、多分。とにかく、それは知っておくべきことです。
誤解を招く15,000レベルの流出レポートは、ほとんどの場合、ショープランの出力における表現の制限に帰着します。基本的な問題は、繰り返しアクションが発生する多くの場所で発生する問題です。たとえば、ネストされたループの内側が結合します。これらの場合、全体の合計ではなく、より正確な内訳を確認できると確かに役立ちます。時間の経過とともに、この領域は少し改善されたため、スレッドごと、または一部の操作のパーティションごとに、より多くの計画情報が得られるようになりました。しかし、まだ長い道のりがあります。
ここでは、15,000の個別のレベル1の流出が、1つの15,000のレベルの流出として報告されることはまだ役に立ちません。
テストバリエーション
この記事では、特定の操作例をより効率的にすることよりも、プラン情報の制限と極端な数のパーティションを使用した場合のパフォーマンス低下の可能性を強調することについて詳しく説明しますが、興味深いバリエーションもいくつかあります。 。
オンライン、tempdbで並べ替え
ONLINE = ON, SORT_IN_TEMPDB = ONで同じパーティションインデックス作成操作を実行する 同じ膨大なメモリの付与と流出に悩まされることはありません:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
ONLINEを使用することに注意してください それだけでは十分ではありません。実際、その結果、以前と同じ計画になり、すべて同じ問題が発生します。 plus 各インデックスパーティションをオンラインで構築するための追加のオーバーヘッド。私にとって、その結果、実行時間は1分をはるかに超えます。 Goodnessは、I/Oパフォーマンスが非常に高い低スペックのAzureインスタンスでどれくらいの時間がかかるかを知っています。
とにかく、ONLINE = ON, SORT_IN_TEMPDB = ONの実行プラン は:

ソートは、宛先パーティション番号が計算される前に実行されます。パーティションIDプロパティがないため、通常の並べ替えです。操作全体は約10秒間実行されます(作成するパーティションはまだたくさんあります)。予約するメモリは3MB未満で、最大816KBを使用します。 4.6GBと15,000回の流出を大幅に改善しました。
最初にインデックスを作成し、次にデータを作成します
最初にデータをヒープテーブルに書き込むことで、同様の結果を得ることができます。
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; 次に、空のパーティション化されたクラスター化テーブルを作成し、ヒープからデータを挿入します。
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; これには約10秒かかり、2 MBのメモリが付与され、こぼれることはありません:
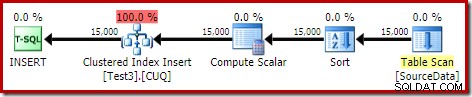
もちろん、(パーティション化されていない)ソーステーブルにインデックスを付け、データをインデックス順に挿入することで、並べ替えを完全に回避することもできます(最適な並べ替えは、並べ替えではありません。覚えておいてください)。
パーティション化されたヒープ、次にデータ、次にインデックス
この最後のバリエーションでは、最初にパーティションヒープを作成し、15,000のテスト行をロードします。
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; そのスクリプトは1〜2秒間実行されますが、これはかなり良いことです。最後のステップは、パーティション化されたクラスター化インデックスを作成することです。
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
これは、パフォーマンスの観点からも、ショープラン情報の観点からも、完全な災害です。操作自体は1分弱で実行され、次の実行プランがあります。

これは、同じ場所に配置された挿入プランです。コンスタントスキャンには、各パーティションIDの行が含まれています。ループの内側は、ヒープの現在のパーティションをシークします(はい、ヒープのシーク)。ソートにはパーティションIDプロパティがあり(これはループの反復ごとに一定ですが)、パーティションごとのソートと望ましくないスピル動作があります。ヒープテーブルの統計警告は偽物です。
挿入プランのルートは、1MBのメモリ許可が予約されており、最大144KBが使用されていることを示しています。
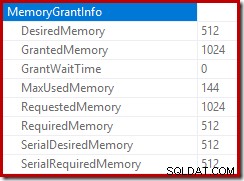
並べ替え演算子は、レベル15,000の流出を報告しませんが、それ以外の場合は、関連するループごとの反復計算を完全に混乱させます。

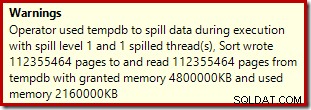
実行中にメモリ許可DMVを監視すると、このクエリは実際には1MBのみを予約し、ループの各反復で最大144KBが使用されることがわかります。 (対照的に、最初のテストでの4.6GBのメモリ予約は完全に本物です。)もちろん、これは混乱を招きます。
問題は(前述のとおり)、SQL Serverが、多くの反復で何が起こったかをレポートするのに最適な方法について混乱することです。反復ごとのパーティションごとの計画パフォーマンス情報を含めることはおそらく実用的ではありませんが、現在の配置が時々混乱する結果を生み出すという事実から逃れることはできません。この種の情報をより一貫性のある形式で報告するためのより良い方法がいつか見つかることを願っています。