 成長して、私は記憶とパターンマッチングのスキルをテストするゲームが大好きでした。私の友人の何人かはサイモンを持っていましたが、私はアインシュタインと呼ばれるノックオフを持っていました。他の人はアタリタッチミーを持っていました、それはその時でさえ私が疑わしい命名決定であると知っていました。最近では、パターンマッチングは私とは大きく異なる意味を持ち、日常のデータベースクエリの高価な部分になる可能性があります。
成長して、私は記憶とパターンマッチングのスキルをテストするゲームが大好きでした。私の友人の何人かはサイモンを持っていましたが、私はアインシュタインと呼ばれるノックオフを持っていました。他の人はアタリタッチミーを持っていました、それはその時でさえ私が疑わしい命名決定であると知っていました。最近では、パターンマッチングは私とは大きく異なる意味を持ち、日常のデータベースクエリの高価な部分になる可能性があります。
私は最近、Stack Overflowについて、実際のところ、CHARINDEXであるかのようにユーザーが述べているコメントをいくつか見つけました。 LEFTよりもパフォーマンスが優れています またはLIKE 。あるケースでは、その人はDavid Lozinskiによる記事「SQL:LIKE vs SUBSTRING vs LEFT /RIGHTvsCHARINDEX」を引用しました。はい、この記事は、考案された例では、CHARINDEX 最高のパフォーマンスを発揮しました。しかし、私は常にそのような包括的なステートメントに懐疑的であり、1つの文字列関数が常にであるという論理的な理由を考えることができなかったためです。 他のすべてが同等である 、私は彼のテストを実行しました。案の定、私のマシンでは繰り返し異なる結果が得られました(クリックして拡大):
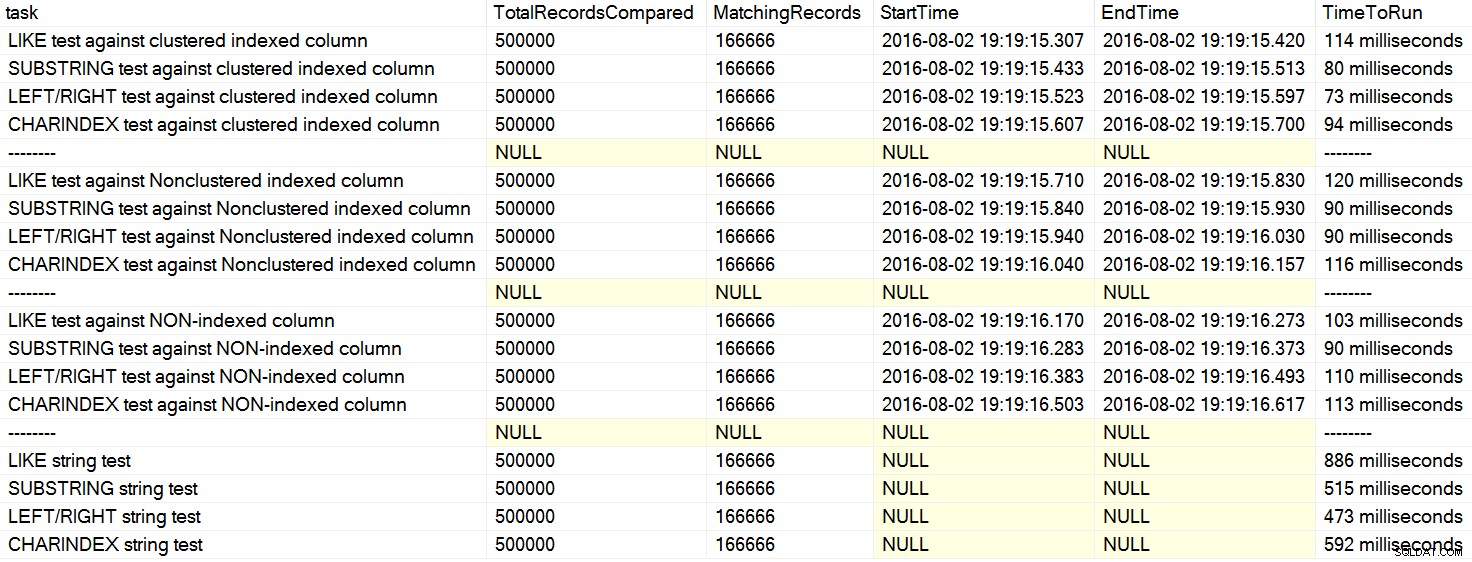 私のマシンでは、CHARINDEXが遅くなりました LEFT / RIGHT/SUBSTRINGより。
私のマシンでは、CHARINDEXが遅くなりました LEFT / RIGHT/SUBSTRINGより。
Davidのテストでは、基本的にこれらのクエリ構造を比較し、列値の最初または最後のいずれかで文字列パターンを探していました。生の期間の観点から:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
これらの句を見るだけで、CHARINDEXの理由がわかります。 効率が低下する可能性があります。他のアプローチで実行する必要のない複数の追加機能呼び出しが行われます。なぜこのアプローチがDavidのマシンで最高のパフォーマンスを発揮したのか、私にはわかりません。おそらく、彼は投稿されたとおりにコードを実行し、テスト間で実際にバッファーをドロップしなかったため、後者のテストはキャッシュされたデータの恩恵を受けました。
理論的には、CHARINDEX もっと簡単に表現できたかもしれません。例:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(しかし、これは実際には私のカジュアルなテストではさらに悪化しました。)
そして、なぜこれらがORであるのか 条件、わかりません。現実的には、ほとんどの場合、次の2種類のパターン検索のいずれかを実行しています。で始まる または含む (で終わるを探すことはあまり一般的ではありません )。そして、これらのほとんどの場合、ユーザーは最初からを希望するかどうかを前もって述べる傾向があります。 または含む 、少なくとも私のキャリアに携わってきたすべてのアプリケーションで。
OR を使用する代わりに、これらを別々のタイプのクエリとして分離することは理にかなっています。 はで始まるため、条件付き インデックスを利用できます(シークに十分適しているか、クラスター化されたインデックスよりも細いインデックスが存在する場合)が、で終わる できません(およびまたは 条件は、一般的にオプティマイザにレンチを投げる傾向があります)。 いいねを信頼できるなら 可能な場合はインデックスを使用し、ほとんどまたはすべての場合に上記の他のソリューションと同等またはそれ以上のパフォーマンスを発揮するために、このロジックを非常に簡単にすることができます。ストアドプロシージャは、検索対象のパターンと実行する検索のタイプの2つのパラメータを取ることができます(通常、文字列照合には4種類あります。開始、終了、包含、または完全一致)。
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
これにより、動的SQLを使用せずに潜在的な各ケースが処理されます。 OPTION (RECOMPILE) 「endswith」(ほぼ確実にスキャンする必要があります)用に最適化されたプランを「startswith」クエリに再利用したくない、またはその逆であるためです。また、推定値が正しいことも保証されます(「Sで始まる」は「QXで始まる」とはカーディナリティが大きく異なる可能性があります)。ユーザーが99%の確率で1つのタイプの検索を選択するシナリオがある場合でも、再コンパイルの代わりにここで動的SQLを使用できますが、その場合でも、パラメータースニッフィングに対して脆弱です。多くの条件付きロジッククエリでは、再コンパイルやフルオンの動的SQLが最も賢明なアプローチであることがよくあります(「キッチンシンク」に関する私の投稿を参照してください)。
テスト
最近、新しいWideWorldImportersサンプルデータベースを調べ始めたので、そこで独自のテストを実行することにしました。 ColumnStoreインデックスまたは時間履歴テーブルのない適切なサイズのテーブルを見つけるのは困難でしたが、Sales.Invoices 、70,510行あり、単純なnvarchar(20)があります。 CustomerPurchaseOrderNumberという列 テストに使うことにしました。 (なぜnvarchar(20) すべての値が5桁の数字である場合、私にはわかりませんが、パターンマッチングでは、下のバイトが数字を表すのか文字列を表すのかは実際には気になりません。)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| パターン | 行数 | テーブルの% |
| 「1」で始まる | 70,505 | 99.993% |
| 「2」で始まる | 5 | 0.007% |
| 「5」で終わる | 6,897 | 9.782% |
| 「30」で終わる | 749 | 1.062% |
表の値をざっと見て、非常に異なる数の行を生成する複数の検索条件を考え出しました。これにより、特定のアプローチでの転換点の動作を明らかにすることができます。右側は、私が見つけた検索クエリです。
上記の手順は、ORを使用するどのクエリよりも、考えられるすべての検索で全体的に間違いなく優れていることを証明したかったのです。 LIKEを使用しているかどうかに関係なく、条件付き 、LEFT/RIGHT 、SUBSTRING 、またはCHARINDEX 。私はDavidの基本的なクエリ構造を取り、それらをストアドプロシージャに入れました(彼の入力なしでは「contains」を実際にテストすることはできず、彼のORを作成する必要があることに注意してください。 ロジックは、私のロジックのバージョンとともに、同じ数の行を取得するためにもう少し柔軟です)。また、検索列に作成するインデックスを使用する場合と使用しない場合、およびウォームキャッシュとコールドキャッシュの両方で手順をテストすることも計画しました。
手順:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
また、検索パターンが文字列の最初または最後にある行を検索することが要件であると想定して、Davidの手順のバージョンを彼の当初の意図に忠実に作成しました。私はこれを簡単に行ったので、彼が書いたとおりにさまざまなアプローチのパフォーマンスを比較して、このデータセットで私の結果が私のシステムでの彼の元のスクリプトのテストと一致するかどうかを確認できました。この場合、彼のLIKE % + @pattern OR LIKE @pattern + %と単純に一致するため、私自身のバージョンを導入する理由はありませんでした。 バリエーション。
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO 手順が整っていれば、テストコードを生成できました。これは、元の問題と同じくらい楽しいことがよくあります。まず、ロギングテーブル:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
次に、さまざまなプロシージャと引数を使用して選択操作を実行するコード:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; 結果
これらのテストは、4つのCPUと32GBのRAMを搭載したWindows10(1511 / 10586.545)、SQL Server 2016(13.0.2149)を実行している仮想マシンで実行しました。テストの各セットを11回実行しました。ウォームキャッシュテストでは、最初の結果セットを破棄しました。これは、それらの一部が本当にコールドキャッシュテストであったためです。
結果をグラフ化してパターンを表示する方法に苦労しました。これは主に、パターンがなかったためです。ほぼすべての方法が、あるシナリオでは最良であり、別のシナリオでは最悪でした。次の表で、各列のパフォーマンスが最も良い手順と最も悪い手順を強調しましたが、結果が決定的なものとはほど遠いことがわかります。
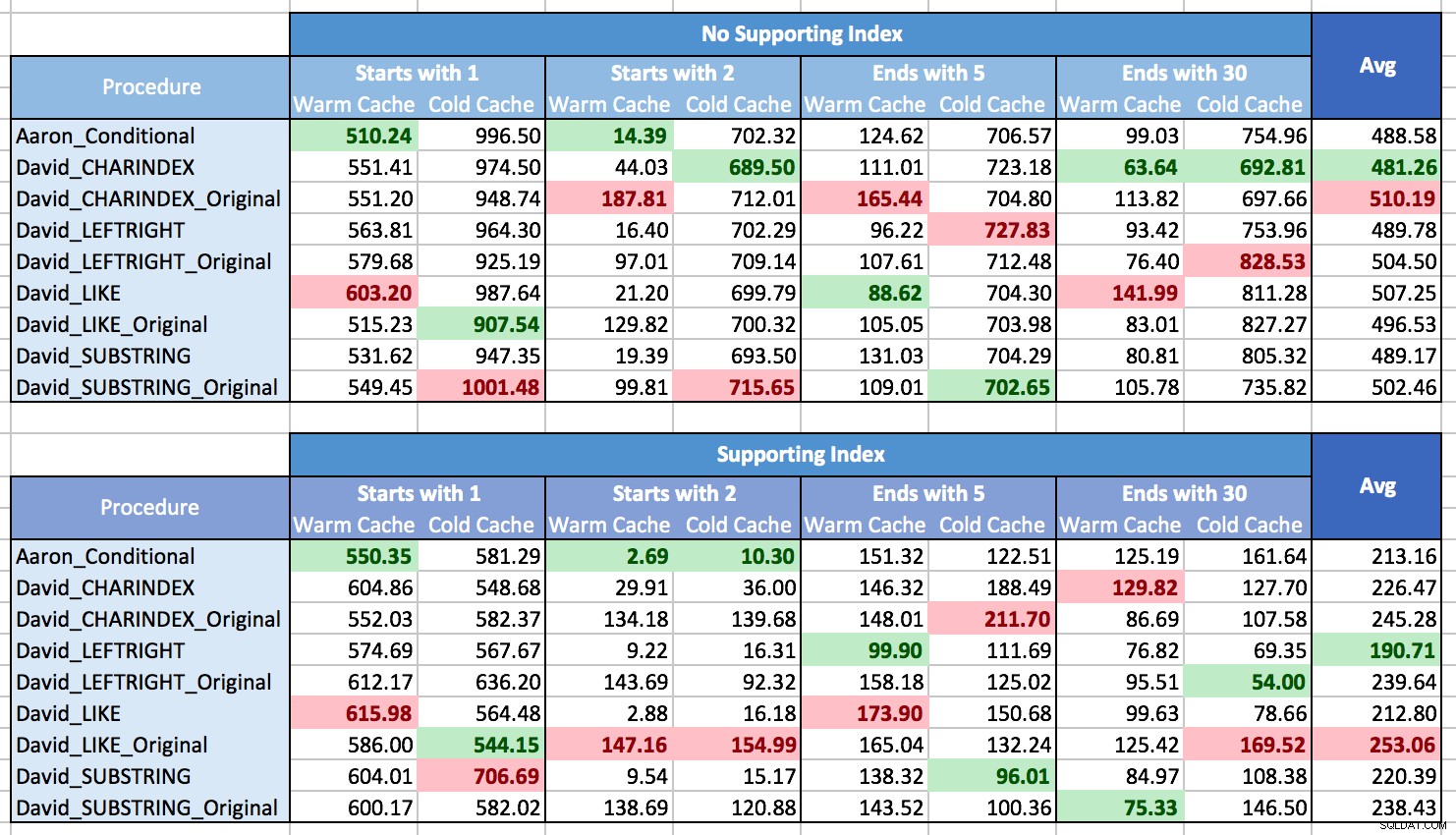 これらのテストでは、CHARINDEXが勝った場合と、勝たなかった場合がありました。
これらのテストでは、CHARINDEXが勝った場合と、勝たなかった場合がありました。
私が学んだことは、全体として、さまざまな状況に直面する場合(サポートするインデックスがあるかどうかに関係なく、さまざまなタイプのパターンマッチングで、データが常にメモリにあるとは限らない)、実際には存在しないということです。明確な勝者であり、平均してパフォーマンスの範囲はかなり小さいです(実際、ウォームキャッシュが常に役立つとは限らないため、結果を取得するよりもレンダリングのコストの影響が大きいと思われます)。個々のシナリオでは、私のテストに依存しないでください。ハードウェア、構成、データ、および使用パターンを考慮して、いくつかのベンチマークを自分で実行します。
警告
これらのテストで考慮しなかったことがいくつかあります:
- クラスター化と非クラスター化 。クラスター化インデックスが文字列の最初または最後に対してパターンマッチング検索を実行している列にある可能性は低く、シークはどちらの場合もほぼ同じであるため(スキャン間の違いはほとんどありません)インデックス幅とテーブル幅の関数である)、非クラスター化インデックスを使用してのみパフォーマンスをテストしました。この違いだけでパターンマッチングに大きな違いが生じる特定のシナリオがある場合は、お知らせください。
- MAXタイプ 。
varchar(max)内の文字列を検索する場合 /nvarchar(max)、これらはインデックス付けできないため、値の一部を表すために計算列を使用しない限り、スキャンが必要になります–で始まる、で終わる、または含むを探しているかどうか。パフォーマンスのオーバーヘッドが文字列のサイズと相関する場合でも、タイプが原因で追加のオーバーヘッドが発生する場合でも、テストは行いませんでした。
- 全文検索 。私はこことtehreでこの機能を試してみましたが、綴ることはできますが、私の理解が正しければ、これはノンストップワード全体を検索していて、文字列のどこにあるかを気にしない場合にのみ役立ちます。見つかった。テキストの段落を保存していて、「Y」で始まり、「the」という単語を含む、または疑問符で終わるすべての段落を検索したい場合は、役に立ちません。
概要
このテストから離れて私が行うことができる唯一の包括的なステートメントは、文字列パターンマッチングを実行するための最も効率的な方法についての包括的なステートメントがないということです。私は柔軟性と保守性のための条件付きアプローチに偏っていますが、すべてのシナリオでパフォーマンスの勝者ではありませんでした。私にとっては、パフォーマンスのボトルネックにぶつかり、すべての手段を追求しているのでない限り、一貫性を保つためにアプローチを使用し続けます。上で提案したように、シナリオが非常に狭く、期間のわずかな違いに非常に敏感な場合は、独自のテストを実行して、どの方法が一貫して最高のパフォーマンスを発揮するかを判断する必要があります。