前回の投稿では、グループ化された連結に対するいくつかの効率的なアプローチを示しました。今回は、FOR XML PATHを使用して簡単に実行できる、この問題のいくつかの追加の側面について説明したいと思います。 アプローチ:リストを並べ替え、重複を削除します。
カンマ区切りのリストを並べ替えたいと思う方法がいくつかあります。リスト内のアイテムをアルファベット順に並べたい場合があります。私は以前の投稿ですでにそれを示しました。しかし、実際には出力に導入されていない他の属性でソートしたい場合もあります。たとえば、リストを最新のアイテムから順に並べたい場合があります。簡単な例を見てみましょう。ここでは、EmployeesテーブルとCoffeeOrdersテーブルがあります。数日間、1人の注文を入力してみましょう:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
ORDER BYを指定せずに既存のアプローチを使用する場合 、任意の順序を取得します(この場合、挿入された順序で行が表示される可能性がありますが、データセットが大きい場合やインデックスが多い場合などはそれに依存しません):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
結果(ORDER BYを指定しない限り、*異なる*結果が得られる可能性があることに注意してください。 ):
ジャック|ラージダブルダブル、ミディアムダブルダブル、ラージバニララテ、ミディアムダブルダブル
リストをアルファベット順に並べたい場合は、簡単です。 ORDER BY c.OrderDetailsを追加するだけです :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
結果:
名前|注文ジャック|ラージダブルダブル、ラージバニララテ、ミディアムダブルダブル、ミディアムダブルダブル
結果セットに表示されない列で並べ替えることもできます。たとえば、最新のコーヒー注文で最初に注文できます:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
結果:
名前|注文ジャック|ミディアムダブルダブル、ラージバニララテ、ミディアムダブルダブル、ラージダブルダブル
私たちがよくやりたいもう1つのことは、重複を削除することです。結局のところ、「ミディアムダブルダブル」を2回見る理由はほとんどありません。 GROUP BYを使用すると、これを排除できます。 :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
さて、これは出力をアルファベット順に並べるのに*起こります*が、これも信頼できません:
名前|注文ジャック|ラージダブルダブル、ラージバニララテ、ミディアムダブルダブル
この方法での注文を保証したい場合は、もう一度ORDERBYを追加するだけです。
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
結果は同じです(ただし、繰り返しますが、これはこの場合の偶然の一致です。この順序が必要な場合は、常にそう言ってください):
名前|注文ジャック|ラージダブルダブル、ラージバニララテ、ミディアムダブルダブル
しかし、重複を排除し、リストを最新のコーヒーの注文で並べ替える場合はどうでしょうか。あなたの最初の傾向は、GROUP BYを維持することかもしれません ORDER BYを変更するだけです 、このように:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
OrderDateなので、これは機能しません クエリの一部としてグループ化または集約されません:
列「dbo.CoffeeOrders.OrderDate」は、集計関数にもGROUP BY句にも含まれていないため、ORDERBY句では無効です。
確かにクエリを少し醜くする回避策は、最初に注文を個別にグループ化し、次に従業員ごとにそのコーヒー注文の最大日付の行のみを取得することです。
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
結果:
名前|注文ジャック|ミディアムダブルダブル、ラージバニララテ、ラージダブルダブル
これにより、重複を排除し、実際にはリストにないものでリストを並べ替えることで、両方の目標を達成できます。
パフォーマンス
これらのメソッドが、より堅牢なデータセットに対してどれほどうまく機能しないのか疑問に思われるかもしれません。テーブルに100,000行を入力し、追加のインデックスなしでどのように機能するかを確認してから、クエリをサポートするために少しインデックスを調整して同じクエリを再度実行します。したがって、最初に、1,000人の従業員に100,000行を分散させます。
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; 次に、各クエリを2回実行して、2回目の試行のタイミングを確認します(ここで信頼を飛躍させ、理想的な世界では、プライムされたキャッシュを使用すると仮定します) )。これらをSQLSentryPlan Explorerで実行しました。これは、個々のクエリの時間を計って比較するのに最も簡単な方法であるためです。
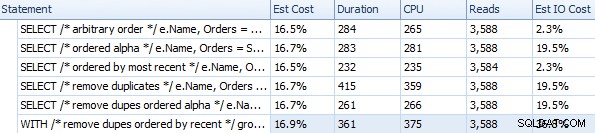 さまざまなFORXMLPATHアプローチの期間およびその他のランタイムメトリック
さまざまなFORXMLPATHアプローチの期間およびその他のランタイムメトリック
ここで実際に何が行われているのかを考えると、これらのタイミング(期間はミリ秒単位)は実際にはそれほど悪くはありません。最も複雑な計画は、少なくとも視覚的には、重複を削除し、最新の順序で並べ替えたもののようです。
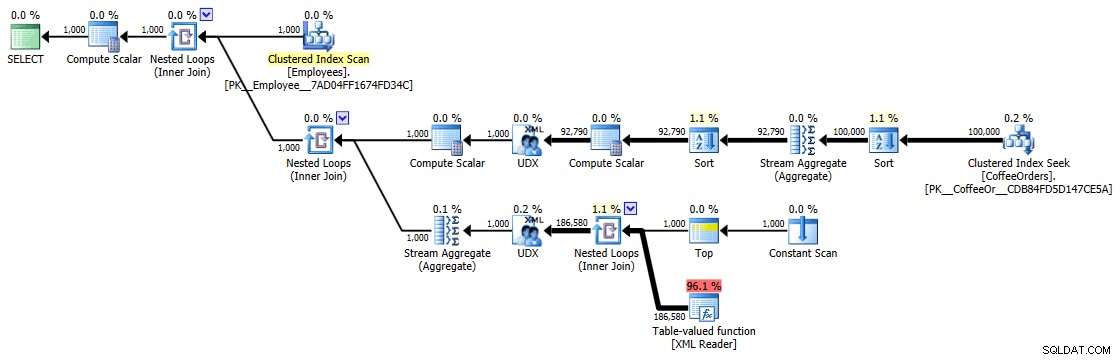 グループ化およびソートされたクエリの実行プラン
グループ化およびソートされたクエリの実行プラン
しかし、ここで最も高価な演算子であるXMLテーブル値関数でさえすべてCPUのようです(クエリプランの詳細で実際の作業のどれだけが公開されているかはわかりませんが):
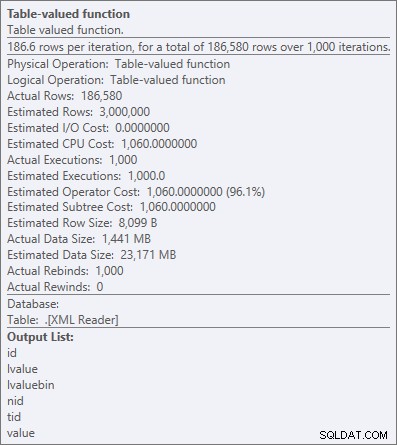 XMLテーブル値関数の演算子プロパティ
XMLテーブル値関数の演算子プロパティ
ほとんどのシステムはI/Oバウンドおよび/またはメモリバウンドであり、CPUバウンドではないため、「すべてのCPU」は通常は問題ありません。私がよく言うように、ほとんどのシステムでは、CPUヘッドルームの一部をメモリまたはディスクと交換します(OPTION (RECOMPILE)が好きな理由の1つです 広範囲にわたるパラメータスニッフィングの問題の解決策として)
とはいえ、CodePlexのGROUP_CONCAT CLRアプローチから得られる同様の結果に対してこれらのアプローチをテストし、プレゼンテーション層で集計と並べ替えを実行することを強くお勧めします(特に、正規化されたデータを何らかの種類で保持している場合)キャッシングレイヤーの)。