SQLServer2014のServicePack2は先月リリースされ(ここでリリースノートを読んでください)、新しいDBCCステートメントが含まれています:DBCC CLONEDATABASE 。 非常に簡単を提供するこのコマンドが導入されたのを見て、私はかなり興奮しました。 データベーススキーマをコピーする方法、統計を含む 、データベース内のデータに必要なすべてのスペースを必要とせずに、クエリパフォーマンスをテストするために使用できます。私はついにDBCC CLONEDATABASEをテストする時間を作りました。 制限を理解し、それはかなり楽しかったと言わざるを得ません。
基本
まず、AdventureWorks2014データベースのクローンを作成し、ソースデータベースに対してクエリを実行してから、クローンデータベースに対してクエリを実行しました。
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
I / OとTIMEの出力を見ると、ソースデータベースに対するクエリに時間がかかり、より多くのI / Oが生成されていることがわかります。どちらも、クローンデータベースにデータがないために予想されます。
/*ソースデータベース*/
SQL Serverの実行時間:
CPU時間=0ミリ秒、経過時間=0ミリ秒。
SQL Serverの解析およびコンパイル時間:
CPU時間=0ミリ秒、経過時間=4ミリ秒。
(影響を受ける121317行)
テーブル'SalesOrderHeader'。スキャンカウント0、論理読み取り371567、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'SalesOrderDetail'。スキャンカウント5、論理読み取り1361、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
(影響を受ける1行)
SQL Serverの実行時間:
CPU時間=686ミリ秒、経過時間=2548ミリ秒。
/*CLONEデータベース*/
SQL Serverの実行時間:
CPU時間=0ミリ秒、経過時間=0ミリ秒。
SQL Serverの解析およびコンパイル時間:
CPU時間=12ミリ秒、経過時間=12ミリ秒。
(影響を受ける行は0)
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'SalesOrderHeader'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'SalesOrderDetail'。スキャンカウント5、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
(影響を受ける1行)
SQL Serverの実行時間:
CPU時間=0ミリ秒、経過時間=83ミリ秒。
実行計画を見ると、実際の値(計画内を実際に移動したデータの量)を除いて、両方のデータベースで同じです。
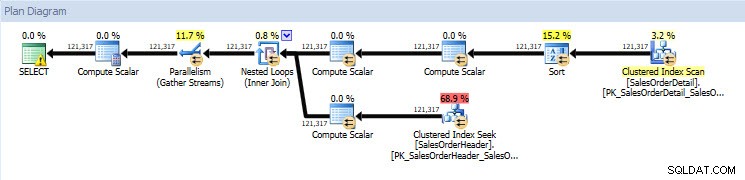
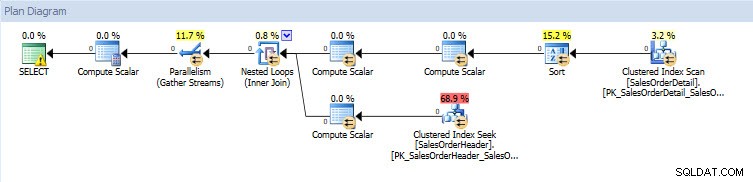
これは、DBCC CLONEDATABASEの値がここにあります 明らかです–データベースの空のコピーを誰にでも(Microsoft製品サポート、私の仲間のDBAなど)入手して、問題を再作成して調査させることができます。また、何百GBものディスク容量を必要としない可能性があります。それ。 Melissaの7月のT-SQL火曜日の投稿には、クローンプロセス中に何が起こるかについての詳細な情報が含まれているため、詳細についてはそれを読むことをお勧めします。
それですか?
しかし…DBCC CLONEDATABASEでもっとできること ?つまり、これは素晴らしいことですが、データベースの空のコピーを使用して実行できることは他にもたくさんあると思います。 DBCC CLONEDATABASEのドキュメントを読んだ場合 、次の行が表示されます:
私が最初に考えたのは、「クエリオプティマイザ–うーん…これをアップグレードをテストするためのオプションとして使用できますか ?」
クローンデータベースは読み取り専用ですが、とにかくいくつかのオプションを変更しようと思いました。たとえば、互換モードを変更できれば、SQLServer2014とSQLServer2016の両方でCEの変更をテストできるので非常に便利です。
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
エラーが発生しました:
メッセージ3906、レベル16、状態1データベースが読み取り専用であるため、データベース「AdventureWorks2014_CLONE」の更新に失敗しました。
メッセージ5069、レベル16、状態1
ALTERDATABASEステートメントが失敗しました。
うーん。リカバリーモデルを変更できますか?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
私は出来ます。それは公平ではないようです。ええと、それは読み取り専用です、私はそれを変更できますか?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
はい!興奮しすぎる前に、ここにあるドキュメントからこのメモを残しておきましょう:
注 DBCC CLONEDATABASEから生成された新しく生成されたデータベースは、実動データベースとしての使用はサポートされておらず、主にトラブルシューティングと診断の目的で使用されます。データベースの作成後に、クローンデータベースをデタッチすることをお勧めします。ドキュメントからこの行を繰り返し、太字にして、わかりやすいが非常に重要として赤くします。 リマインダー:
DBCC CLONEDATABASEから生成された新しく生成されたデータベースは、本番データベースとしての使用はサポートされておらず、主にトラブルシューティングと診断を目的としています。それは私にとっては問題ありません。私はこれを本番環境に使用するつもりはありませんでしたが、今ではテストに使用できます。これで、互換モードを変更できます。また、テストのために、互換モードをバックアップして別のインスタンスに復元することもできます。
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
これは大きいです。
前回の投稿では、トレースフラグ2389と、新しいCardinality Estimatorを使用したテストについて説明しました。これは、友人の皆さんが必要であるためです。 アップグレードする前に、新しいCEでテストする必要があります。テストせず、アップグレードの一環として互換モードを120(SQL Server 2014)または130(SQL Server 2016)に変更した場合、次のような事態が発生した場合、消防モードで作業するリスクがあります。新しいCEでの回帰。さて、あなたは大丈夫かもしれません、そしてあなたがアップグレードした後、パフォーマンスはさらに良くなるかもしれません。でも…確信したくないですか?
アップグレード前のテストについて言及すると、テストを実行する環境がないと言われることがよくあります。私はあなたの何人かがテスト環境を持っていることを知っています。 Test、Dev、QA、UATを持っていて、他に何を知っている人もいます。ラッキーです。
テストするテスト環境がまったくないとおっしゃる方のために、DBCC CLONEDATABASEを紹介します。 。このコマンドを使用すると、データベースのクローンに対して最も頻繁に実行されるクエリとヘビーヒッターを実行しないという言い訳はできません。テスト環境がなくても、自分のマシンがあります。クローンデータベースを本番環境からバックアップし、クローンを削除し、バックアップをローカルインスタンスに復元してから、テストします。クローンデータベースはディスク上のスペースをほとんど占有せず、データがないため、メモリやI/Oの競合は発生しません。あなたは クローンのクエリプランを本番データベースのクエリプランと比較して検証できます。さらに、SQL Server 2016で復元する場合は、クエリストアをテストに組み込むことができます。クエリストアを有効にし、元の互換モードでテストを実行してから、互換モードをアップグレードして再度テストします。クエリストアを使用して、クエリを並べて比較できます。 (今、椅子で踊っていると言えますか?)
考慮事項
繰り返しになりますが、これは本番環境で使用するものではなく、使用しないことはわかっていますが、現在の状態ではDBCC CLONEDATABASEであるため、繰り返しになります。 完全ではありません 。これは、サポートされているオブジェクトの下のKB記事に記載されています。メモリ最適化テーブルやファイルテーブルなどのオブジェクトはコピーされません。フルテキストはサポートされません。
現在、クローンデータベースには欠点があります。そのデータベースのインデックスの再構築または統計の更新を誤って実行した場合は、テストデータが消去されただけです。おそらく最初に本当に欲しかったものである元の統計が失われます。たとえば、SalesOrderHeaderでクラスター化されたインデックスの統計を今すぐ確認すると、次のようになります。
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 SalesOrderHeaderの元の統計
SalesOrderHeaderの元の統計
ここで、そのテーブルに対して統計を更新すると、次のようになります。
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 SalesOrderHeaderの更新された(空の)統計
SalesOrderHeaderの更新された(空の)統計
追加の安全性として、統計の自動更新を無効にすることをお勧めします:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
意図せずに統計を更新した場合は、DBCC CLONEDATABASEを実行してください。 バックアップと復元のプロセスを実行するのはそれほど難しくなく、すぐに自動化されます。
データベースにデータを追加できます。これは、統計(さまざまなサンプルレート、フィルタリングされた統計など)を試したい場合や、テーブルのデータのコピーを保持するのに十分なストレージがある場合に役立ちます。
データベースにデータがない場合、明らかに代表的な期間とI/Oデータを確実に取得することはできません。それで大丈夫です。実際のリソース使用量に関するデータが必要な場合は、すべてのデータを含むデータベースのコピーが必要です。 DBCC CLONEDATABASE クエリのパフォーマンスをテストすることです。それでおしまい。これは、従来のアップグレードテストに代わるものではありませんが、SQLServerがさまざまなバージョンと互換性モードでクエリを最適化する方法を検証するための新しいオプションです。ハッピーテスト!