[パート1|パート2|パート3|パート4]
このシリーズのパート3では、IDENTITYの拡大を回避するための2つの回避策を示しました。 列– 1つは単に時間を稼ぐもので、もう1つはIDENTITYを放棄するものです。 完全に。前者は外部キーなどの外部依存関係を処理する必要がないようにしますが、後者はそれでもその問題に対処しません。この投稿では、どうしてもbigintに移行する必要がある場合のアプローチについて詳しく説明したいと思います。 、ダウンタイムを最小限に抑える必要があり、計画に十分な時間がありました。
すべての潜在的なブロッカーと最小限の中断の必要性のために、アプローチは少し複雑に見えるかもしれません、そして追加のエキゾチックな機能(例えば、パーティショニング、インメモリOLTP、またはレプリケーション)が使用されている場合にのみさらに複雑になります。
非常に高いレベルでは、アプローチはシャドウテーブルのセットを作成することです。ここで、すべての挿入はテーブルの新しいコピー(より大きなデータ型)に向けられ、2つのテーブルのセットの存在は同じように透過的です。アプリケーションとそのユーザーに対して可能な限り。
より詳細なレベルでは、一連の手順は次のようになります。
- 適切なデータ型を使用して、テーブルのシャドウコピーを作成します。
- パラメータにbigintを使用するように、ストアドプロシージャ(またはアドホックコード)を変更します。 (これには、ローカル変数、一時テーブルなどのパラメータリスト以外の変更が必要になる場合がありますが、ここではそうではありません。)
- 古いテーブルの名前を変更し、古いテーブルと新しいテーブルを結合する名前でビューを作成します。
- これらのビューには、トリガーの代わりにDML操作を適切なテーブルに適切に転送する機能があり、移行中にデータを変更できます。
- これには、インデックス付きビューからSCHEMABINDINGを削除する必要があり、既存のビューで新しいテーブルと古いテーブルを結合し、SCOPE_IDENTITY()に依存するプロシージャを変更する必要があります。
- 古いデータを新しいテーブルにチャンクで移行します。
- クリーンアップ。構成は次のとおりです。
- 一時ビューを削除します(これにより、INSTEAD OFトリガーが削除されます)。
- 新しいテーブルの名前を元の名前に戻します。
- SCOPE_IDENTITY()に戻るようにストアドプロシージャを修正します。
- 古い、現在は空のテーブルを削除します。
- SCHEMABINDINGをインデックス付きビューに戻し、クラスター化インデックスを再作成します。
ストアドプロシージャを介してすべてのデータアクセスを制御できれば、ビューとトリガーの多くを回避できる可能性がありますが、そのシナリオはまれであるため(100%信頼することは不可能です)、より難しいルートを示します。
初期スキーマ
このアプローチを可能な限りシンプルに保つために、シリーズの前半で説明したブロッカーの多くに対処しながら、このスキーマがあると仮定しましょう。
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO したがって、クラスター化されたIDENTITY列、クラスター化されていないインデックス、IDENTITY列に基づく計算列、インデックス付きビュー、および人事テーブルへの外部キーを持つ個別のHR /ダートテーブルを含む単純な人事テーブル(I必ずしもその設計を奨励しているわけではなく、この例で使用しているだけです)。これらはすべて、スタンドアロンの独立したテーブルがある場合よりもこの問題を複雑にするものです。
そのスキーマが整っているので、おそらくCRUDのようなことを行ういくつかのストアドプロシージャがあります。これらは何よりもドキュメントのためのものです。これらのプロシージャの変更が最小限になるように、基になるスキーマに変更を加えます。これは、アプリケーションからアドホックSQLを変更することは不可能であり、必要ではない可能性があるという事実をシミュレートするためです(テーブルとビューを検出できるORMを使用していない限り)。
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO 次に、元のテーブルに5行のデータを追加しましょう。
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
ステップ1-新しいテーブル
ここでは、EmployeeID列のデータ型、IDENTITY列の初期シード、および名前の一時的な接尾辞を除いて、元のテーブルをミラーリングして、新しいテーブルのペアを作成します。
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); ステップ2–プロシージャパラメータを修正する
ここでの手順(および、より大きな整数型をすでに使用している場合を除き、アドホックコード)は、将来、整数の上限を超えるEmployeeID値を受け入れることができるように、非常に小さな変更が必要になります。これらの手順を変更する場合は、単に新しいテーブルに向けることができると主張することもできますが、私は、既存の永続的なものへの*最小限の*侵入で究極の目標を達成できると主張しようとしています。コード。
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO ステップ3–ビューとトリガー
残念ながら、これを黙って行うことはできません。ほとんどの操作は並行して、同時使用に影響を与えることなく実行できますが、SCHEMABINDINGのため、インデックス付きビューを変更し、後でインデックスを再作成する必要があります。
これは、SCHEMABINDINGを使用し、いずれかのテーブルを参照する他のオブジェクトにも当てはまります。操作の開始時にインデックスなしのビューに変更し、プロセスで複数回ではなく、すべてのデータが移行された後にインデックスを再構築することをお勧めします(テーブルの名前は複数回変更されるため)。実際、私がやろうとしているのは、プロセスの期間中、新しいバージョンと古いバージョンのEmployeesテーブルを結合するようにビューを変更することです。
もう1つ行う必要があるのは、一時的にSCOPE_IDENTITY()の代わりに@@IDENTITYを使用するようにEmployee_Addストアドプロシージャを変更することです。これは、「従業員」への新しい更新を処理するINSTEAD OFトリガーには、SCOPE_IDENTITY()値の可視性がないためです。もちろん、これは、@@IDENTITYに影響を与えるafterトリガーがテーブルにないことを前提としています。うまくいけば、これらのクエリをストアドプロシージャ内で変更できるか(INSERTを新しいテーブルにポイントするだけで済みます)、アプリケーションコードはそもそもSCOPE_IDENTITY()に依存する必要がありません。
オブジェクトが流動的である間、トランザクションが侵入しようとしないように、SERIALIZABLEでこれを実行します。これは主にメタデータのみの操作のセットであるため、迅速に行う必要があります。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; ステップ4–古いデータを新しいテーブルに移行する
データをチャンクに移行して、同時実行性とトランザクションログの両方への影響を最小限に抑え、私の古い投稿「大規模な削除操作をチャンクに分割する」から基本的な手法を借用します。これらのバッチもSERIALIZABLEで実行します。つまり、バッチサイズに注意する必要があります。簡潔にするために、エラー処理は省略しました。
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; 結果:
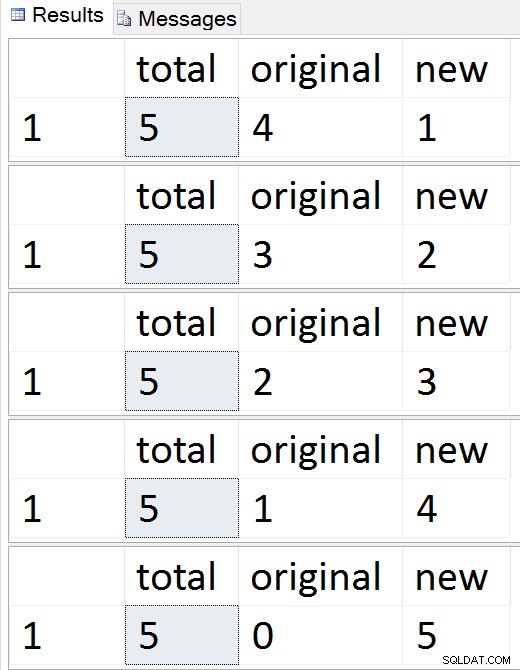 行が1つずつ移行するのを確認する
行が1つずつ移行するのを確認する
そのシーケンス中はいつでも、挿入、更新、および削除をテストでき、それらは適切に処理される必要があります。移行が完了したら、残りのプロセスに進むことができます。
ステップ5–クリーンアップ
一時的に作成されたオブジェクトをクリーンアップし、Employees / EmployeeFileを適切な第一級市民として復元するには、一連の手順が必要です。これらのコマンドの多くは単なるメタデータ操作です。インデックス付きビューにクラスター化されたインデックスを作成することを除いて、すべて瞬時に実行する必要があります。
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO この時点で、すべてが通常の操作に戻るはずですが、統計の更新、インデックスの再構築、キャッシュからの計画の削除など、主要なスキーマ変更後の一般的なメンテナンスアクティビティを検討することをお勧めします。
結論
これは、単純な問題であるはずの問題に対するかなり複雑な解決策です。ある時点で、SQL Serverによって、IDENTITYプロパティの追加/削除、新しいターゲットデータ型でのインデックスの再構築、関係を犠牲にすることなく関係の両側の列の変更などが可能になることを願っています。それまでの間、このソリューションが役立つかどうか、または別のアプローチがあるかどうかを知りたいと思います。
正気が私のアプローチをチェックするのを手伝ってくれたJamesLupolt(@jlupoltsql)に大声で叫び、彼自身の実際のテーブルの1つで究極のテストを行いました。 (うまくいきました。Jamesに感謝します!)
—
[パート1|パート2|パート3|パート4]