クエリのパフォーマンスを見ると、SQL Serverには多くの優れた情報源があり、私のお気に入りの1つはクエリプラン自体です。特にSQLServer2012以降の最後のいくつかのリリースでは、新しいバージョンごとに実行プランに詳細が含まれています。拡張機能のリストは増え続けていますが、ここに私が価値があると思ったいくつかの属性があります:
- NonParallelPlanReason(SQL Server 2012)
- 残りの述語プッシュダウン診断(SQL Server 2012 SP3、SQL Server 2014 SP2、SQL Server 2016 SP1)
- tempdb流出診断(SQL Server 2012 SP3、SQL Server 2014 SP2、SQL Server 2016)
- 有効なトレースフラグ(SQL Server 2012 SP4、SQL Server 2014 SP2、SQL Server 2016 SP1)
- オペレータークエリ実行統計(SQL Server 2014 SP2、SQL Server 2016)
- 1つのクエリで有効な最大メモリ(SQL Server 2014 SP2、SQL Server 2016 SP1)
SQL Serverの各バージョンに存在するものを表示するには、[Showplan Schema]ページにアクセスしてください。このページでは、SQLServer2005以降の各バージョンのスキーマを確認できます。
私はこの余分なデータをすべて気に入っていますが、一部の情報は、推定されたもの(tempdb流出情報など)よりも実際の実行計画に関連していることに注意することが重要です。トラブルシューティングのために実際の計画を取得して使用できる日もあれば、推定された計画を使用する必要がある日もあります。 SQL Serverのプランキャッシュから、その推定プラン(問題のある実行に使用された可能性のあるプラン)を取得することがよくあります。また、特定のクエリまたはセットまたはクエリを調整する場合は、個々のプランをプルすることが適切です。しかし、パターンの観点からチューニング作業をどこに集中させるべきかについてのアイデアが必要な場合はどうでしょうか?
SQL Serverプランキャッシュは、パフォーマンスチューニングに関しては膨大な情報源であり、単にトラブルシューティングを行って、システムで何が実行されているかを理解しようとすることを意味するのではありません。この場合、私は、クエリプラン列にXMLとして格納されているsys.dm_exec_query_planにあるプラン自体からのマイニング情報について話しています。
このデータをsys.dm_exec_sql_text(クエリのテキストを簡単に表示できるようにする)およびsys.dm_exec_query_stats(実行統計)からの情報と組み合わせると、ヘビーヒッターであるクエリや実行するクエリだけでなく、突然検索を開始できます。最も頻繁に使用されますが、特定の結合タイプ、インデックススキャンを含むプラン、またはコストが最も高いプラン。これは一般にプランキャッシュのマイニングと呼ばれ、これを行う方法について説明しているブログ投稿がいくつかあります。私の同僚のJonathanKehayiasは、XMLを書くのは嫌いですが、プランキャッシュをマイニングするためのクエリを含むいくつかの投稿があります:
- プランキャッシュからの「並列処理のコストしきい値」の調整
- プランキャッシュでの暗黙的な列変換の検索
- プランキャッシュ内のどのクエリが特定のインデックスを使用しているかを見つける
- SQLプランキャッシュの詳細:不足しているインデックスの検索
- プランキャッシュ内のキールックアップの検索
プランキャッシュの内容を調べたことがない場合は、これらの投稿のクエリから始めるとよいでしょう。ただし、プランキャッシュには制限があります。たとえば、クエリを実行し、プランをキャッシュに入れないようにすることができます。たとえば、アドホックワークロードの最適化オプションを有効にしている場合、最初の実行時に、コンパイルされたプランのスタブは、完全にコンパイルされたプランではなく、プランのキャッシュに保存されます。ただし、最大の課題は、プランのキャッシュが一時的なものであるということです。 SQL Serverには、プランキャッシュを完全にクリアしたり、データベース用にクリアしたりできるイベントが多数あります。プランは、使用しない場合はキャッシュからエージングアウトするか、再コンパイル後に削除することができます。これに対抗するには、通常、プランキャッシュを定期的にクエリするか、スケジュールに基づいてコンテンツをテーブルにスナップショットする必要があります。
これは、SQLServer2016でクエリストアを使用して変更されます。
ユーザーデータベースでクエリストアが有効になっている場合、そのデータベースに対して実行されたクエリのテキストとプランがキャプチャされ、内部テーブルに保持されます。現在実行されているものの一時的なビューではなく、以前に実行されたものの長期的な全体像を把握しています。保持されるデータの量は、CLEANUP_POLICY設定によって決定されます。デフォルトは30日です。わずか数時間のクエリ実行を表すプランキャッシュと比較すると、クエリストアデータはゲームチェンジャーです。
いくつかのインデックス分析を行っているシナリオを考えてみましょう。いくつかのインデックスが使用されておらず、欠落しているインデックスDMVからいくつかの推奨事項があります。欠落しているインデックスDMVは、どのクエリが欠落しているインデックスの推奨を生成したかについての詳細を提供しません。 JonathanのFindingMissingIndexes投稿からのクエリを使用して、プランキャッシュにクエリを実行できます。これをローカルSQLServerインスタンスに対して実行すると、以前に実行したいくつかのクエリに関連する2行の出力が得られます。

プランエクスプローラーでプランを開くことができます。SELECT演算子に警告が表示されます。これは、インデックスが欠落しているためです。
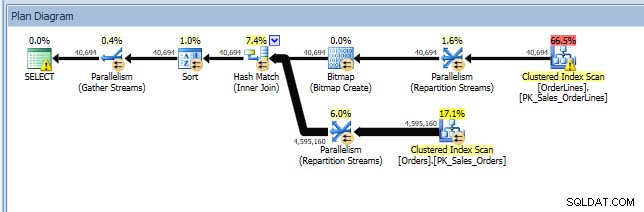
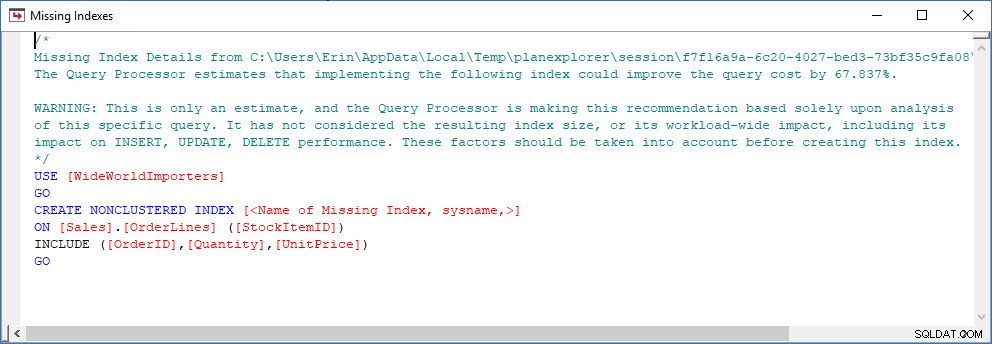
これは素晴らしいスタートですが、繰り返しになりますが、私の出力はキャッシュにあるものに依存します。 Jonathanのクエリを取得してクエリストア用に変更し、デモのWideWorldImportersデータベースに対して実行できます。
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
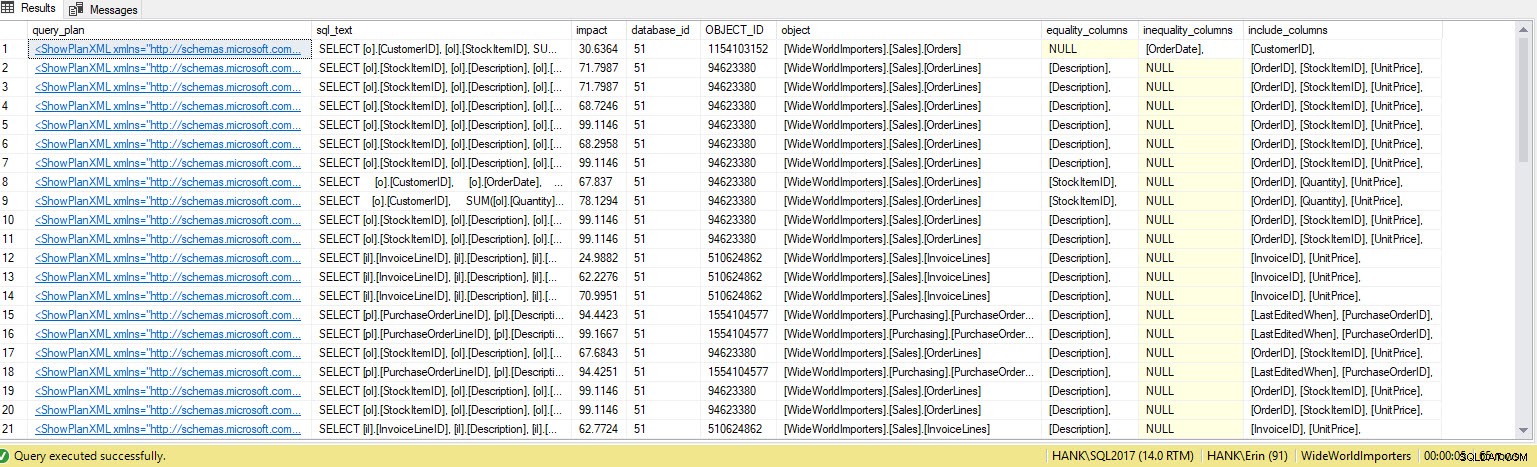
出力にはさらに多くの行が含まれます。繰り返しになりますが、クエリストアデータは、システムに対して実行されたクエリのより大きなビューを表します。このデータを使用すると、欠落しているインデックスだけでなく、それらのインデックスがサポートするクエリを特定するための包括的な方法が得られます。ここから、クエリストアを詳しく調べ、パフォーマンスメトリックと実行頻度を調べて、インデックスの作成の影響を理解し、クエリがインデックスを保証するのに十分な頻度で実行されるかどうかを判断できます。
クエリストアを使用していないが、SentryOneを使用している場合は、SentryOneデータベースからこれと同じ情報をマイニングできます。クエリプランは圧縮形式でdbo.PerformanceAnalysisPlanテーブルに格納されるため、使用するクエリは上記のクエリと同様のバリエーションですが、DECOMPRESS関数も使用されていることがわかります。
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; 1つのSentryOneシステムで、次の出力がありました(もちろん、query_plan値のいずれかをクリックすると、グラフィカルプランが開きます):

SentryOneがクエリストアに対して提供するいくつかの利点は、データベースごとにこのタイプのコレクションを有効にする必要がないことです。また、すべてのデータがリポジトリに保存されるため、監視対象データベースがストレージ要件をサポートする必要がありません。クエリストアをサポートするバージョンだけでなく、サポートされているすべてのバージョンのSQLServerでこの情報を取得することもできます。ただし、SentryOneは、期間や読み取りなどのしきい値を超えるクエリのみを収集することに注意してください。これらのデフォルトのしきい値を微調整することはできますが、SentryOneデータベースをマイニングするときに注意する必要があるのは1つの項目です。すべてのクエリが収集されるわけではありません。さらに、DECOMPRESS関数はSQLServer2016まで使用できません。古いバージョンのSQLServerの場合は、次のいずれかを実行する必要があります。
- SentryOneデータベースをバックアップし、SQL Server 2016以降で復元して、クエリを実行します。
- dbo.PerformanceAnalysisPlanテーブルからデータをbcpして、SQLServer2016インスタンスの新しいテーブルにインポートします。
- SQLServer2016インスタンスからリンクサーバーを介してSentryOneデータベースにクエリを実行します。または、
- 解凍後に特定のものを解析できるアプリケーションコードからデータベースをクエリします。
SentryOneを使用すると、プランキャッシュだけでなく、SentryOneリポジトリ内に保持されているデータもマイニングできます。 SQL Server 2016以降を実行していて、クエリストアが有効になっている場合は、この情報もsys.query_store_planにあります。 。欠落しているインデックスを見つけるこの例だけに限定されません。 Jonathanの他のプランキャッシュポストからのすべてのクエリは、SentryOneまたはQueryStoreからのデータをマイニングするために使用するように変更できます。さらに、XQueryに精通している(または学習する意思がある)場合は、Showplan Schemaを使用して、必要な情報を見つけるためにプランを解析する方法を理解できます。これにより、クエリプランでパターンやアンチパターンを見つけて、問題が発生する前にチームで修正できるようになります。