SQL Serverがクエリを最適化すると、探索フェーズで候補プランが作成され、その中からコストが最も低いプランが選択されます。選択されたプランは、調査されたプランの中で実行時間が最も短いと想定されています。重要なのは、オプティマイザーはそれにエンコードされた戦略からのみ選択できるということです。たとえば、グループ化と集約を最適化する場合、この記事の執筆時点では、オプティマイザーはStreamAggregate戦略とHashAggregate戦略のどちらかしか選択できません。このシリーズの前半で、利用可能な戦略について説明しました。第1部では、事前に注文されたStream Aggregate戦略、第2部ではSort + Stream Aggregate戦略、第3部ではHash Aggregate戦略、第4部では並列処理の考慮事項について説明しました。
SQL Serverオプティマイザーが現在サポートしていないのは、カスタマイズと人工知能です。つまり、特定の条件下でオプティマイザがサポートする戦略よりも最適である戦略を理解できた場合、オプティマイザを拡張してそれをサポートすることはできず、オプティマイザはそれを使用する方法を学ぶことができません。ただし、実行できることは、念頭に置いている戦略で最適化できる代替クエリ要素を使用してクエリを書き直すことです。シリーズのこの5番目で最後のパートでは、クエリリビジョンを使用したクエリチューニングのこの手法を示します。
この記事で紹介した原価計算の一部を手伝ってくれたPaulWhite(@SQL_Kiwi)に感謝します!
シリーズの前のパートと同様に、PerformanceV3サンプルデータベースを使用します。次のコードを使用して、Ordersテーブルから不要なインデックスを削除します。
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
デフォルトの最適化戦略
次の基本的なグループ化および集約タスクを検討してください。
各荷送人、従業員、および顧客の最大注文日を返します。
最適なパフォーマンスを得るには、次のサポートインデックスを作成します。
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
以下は、これらのタスクを処理するために使用する3つのクエリと、推定サブツリーコスト、およびI / O、CPU、経過時間の統計です。
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
図1は、これらのクエリの計画を示しています。
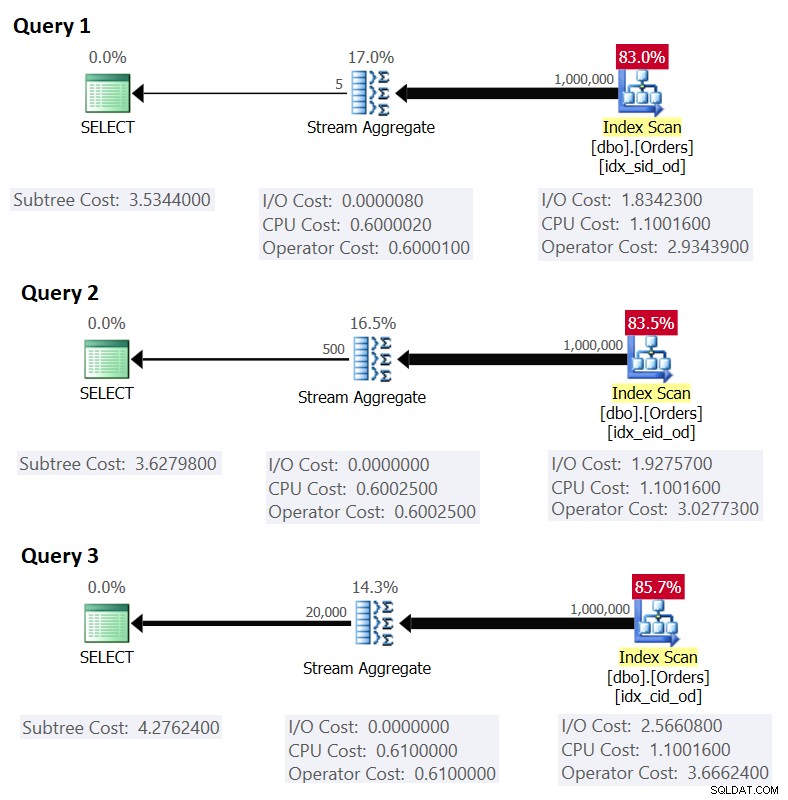 図1:の計画グループ化されたクエリ
図1:の計画グループ化されたクエリ
グループ化セット列を先頭のキー列として、次に集計列を使用してカバーインデックスを設定している場合、SQL Serverは、StreamAggregate戦略をサポートするカバーインデックスの順序付きスキャンを実行するプランを選択する可能性が高いことを思い出してください。 。図1の計画で明らかなように、インデックススキャンオペレーターが計画コストの大部分を負担し、その中でI/O部分が最も顕著です。
代替戦略を提示し、それがデフォルト戦略よりも最適である状況を説明する前に、既存の戦略のコストを評価しましょう。このデフォルト戦略の計画コストを決定する上でI/O部分が最も支配的であるため、最初に、必要な論理ページ読み取りの数を見積もります。後で、プランのコストも見積もります。
インデックススキャン演算子が必要とする論理読み取りの数を見積もるには、テーブルにある行数と、行サイズに基づいてページに収まる行数を知る必要があります。これらの2つのオペランドを取得すると、インデックスのリーフレベルで必要なページ数の式はCEILING(1e0 * @numrows / @rowsperpage)になります。テーブル構造だけがあり、使用する既存のサンプルデータがない場合は、この記事を使用して、サポートインデックスのリーフレベルにあるページ数を見積もることができます。優れた代表的なサンプルデータがある場合は、本番環境と同じスケールでなくても、次のようにカタログや動的管理オブジェクトにクエリを実行することで、ページに収まる平均行数を計算できます。
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); このクエリは、サンプルデータベースに次の出力を生成します。
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
インデックスのリーフページに収まる行数がわかったので、本番テーブルに期待される行数に基づいて、インデックスのリーフページの総数を見積もることができます。これは、インデックススキャンオペレータによって適用される論理読み取りの予想数にもなります。実際には、先読みメカニズムによって生成される追加の読み取りなど、インデックスのリーフレベルのページ数だけでなく、実行される可能性のある読み取りの数も多くなりますが、説明を単純にするためにそれらを無視します。 。
たとえば、予想される行数に対するクエリ1の推定論理読み取り数は、CEILING(1e0 * @numorws / 404)です。 1,000,000行の場合、予想される論理読み取り数は2476です。2476と報告された行ページ数2473の違いは、ページあたりの平均行数を計算したときに行った丸めに起因する可能性があります。
計画コストについては、シリーズのパート1でStreamAggregateオペレーターのコストをリバースエンジニアリングする方法を説明しました。同様の方法で、インデックススキャンオペレーターのコストをリバースエンジニアリングできます。その場合、計画コストは、インデックススキャンおよびストリーム集計オペレーターのコストの合計になります。
インデックススキャンオペレーターのコストを計算するには、重要なコストモデル定数のいくつかをリバースエンジニアリングすることから始めます。
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
上記のコストモデル定数を把握したら、インデックススキャンオペレーターのI / Oコスト、CPUコスト、および総オペレーターコストの式をリバースエンジニアリングすることができます。
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
たとえば、2473ページと1,000,000行のクエリ1のインデックススキャン演算子のコストは次のとおりです。
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
以下は、StreamAggregateオペレーターコストのリバースエンジニアリング式です。
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
例として、クエリ1の場合、1,000,000行と5グループがあるため、推定コストは0.6000105です。
2人のオペレーターのコストを組み合わせると、プラン全体のコストの計算式は次のようになります。
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
クエリ1の場合、2473ページ、1,000,000行、5グループで、次のようになります。
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
これは、図1がクエリ1の推定コストとして示しているものと一致します。
1ページあたりの推定行数に依存している場合、数式は次のようになります。
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
例として、クエリ1の場合、1,000,000行、1ページあたり404行、5つのグループの場合、推定コストは次のようになります。
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
演習として、クエリ2(1,000,000行、ページあたり385行、500グループ)とクエリ3(1,000,000行、ページあたり289行、20,000グループ)の数値を適用して、結果が何に一致するかを確認できます。図1に示します。
クエリの書き換えによるクエリの調整
グループごとにMIN/MAX集約を計算するためのデフォルトの事前順序付けされたストリーム集約戦略は、サポートするカバーリングインデックスの順序付けられたスキャン(または順序付けられた行を発行するその他の予備アクティビティ)に依存します。サポートするカバーリングインデックスが存在する別の戦略は、グループごとにインデックスシークを実行することです。 grpcolでグループ化し、MAX(aggcol)を適用するクエリのこのような戦略に基づく疑似プランの説明は次のとおりです。
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; 考えてみると、グループ化セットの密度が低い場合(グループの数が多く、グループあたりの行数が平均して少ない場合)、デフォルトのスキャンベースの戦略が最適です。シークベースの戦略は、グループ化セットの密度が高い場合に最適です(グループの数が少なく、グループあたりの行数が平均して多い)。図2は、それぞれが最適な場合を示す両方の戦略を示しています。
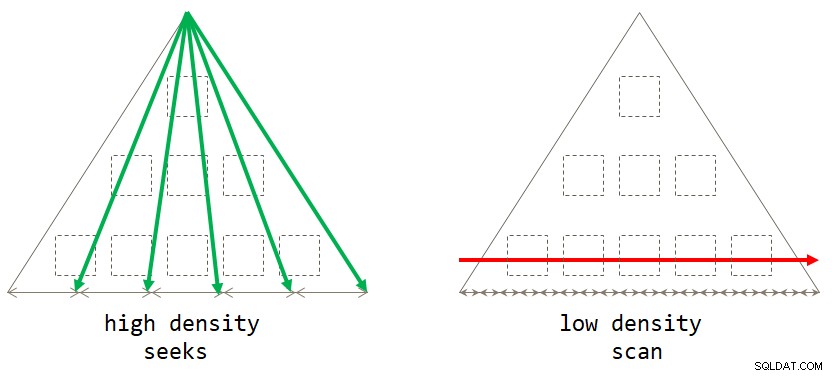 図2:最適な戦略グループ化セット密度に基づく
図2:最適な戦略グループ化セット密度に基づく
グループ化されたクエリの形式でソリューションを記述している限り、現在SQLServerはスキャン戦略のみを考慮します。これは、グループ化セットの密度が低い場合に適しています。密度が高い場合、シーク戦略を取得するには、クエリの書き換えを適用する必要があります。これを実現する1つの方法は、グループを保持するテーブルをクエリし、メインテーブルに対してスカラー集計サブクエリを使用して集計を取得することです。たとえば、各配送業者の最大注文日を計算するには、次のコードを使用します。
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; メインテーブルのインデックス作成ガイドラインは、デフォルトの戦略をサポートするためのガイドラインと同じです。前述の3つのタスクに対して、これらのインデックスはすでに用意されています。また、グループを保持しているテーブルのグループ化セットの列にサポートインデックスを付けて、そのテーブルに対するI/Oコストを最小限に抑えることもできます。次のコードを使用して、3つのタスクのサポートインデックスを作成します。
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
ただし、小さな問題の1つは、サブクエリに基づくソリューションが、グループ化されたクエリに基づくソリューションと完全に論理的に同等ではないことです。メインテーブルに存在しないグループがある場合、前者は集計としてNULLを含むグループを返しますが、後者はグループをまったく返しません。グループ化されたクエリと真の論理的等価性を実現する簡単な方法は、SELECT句でスカラーサブクエリを使用する代わりに、FROM句でCROSSAPPLY演算子を使用してサブクエリを呼び出すことです。適用されたクエリが空のセットを返した場合、CROSSAPPLYは左の行を返さないことに注意してください。 3つのタスクに対してこの戦略を実装する3つのソリューションクエリと、それらのパフォーマンス統計を次に示します。
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; これらのクエリの計画を図3に示します。
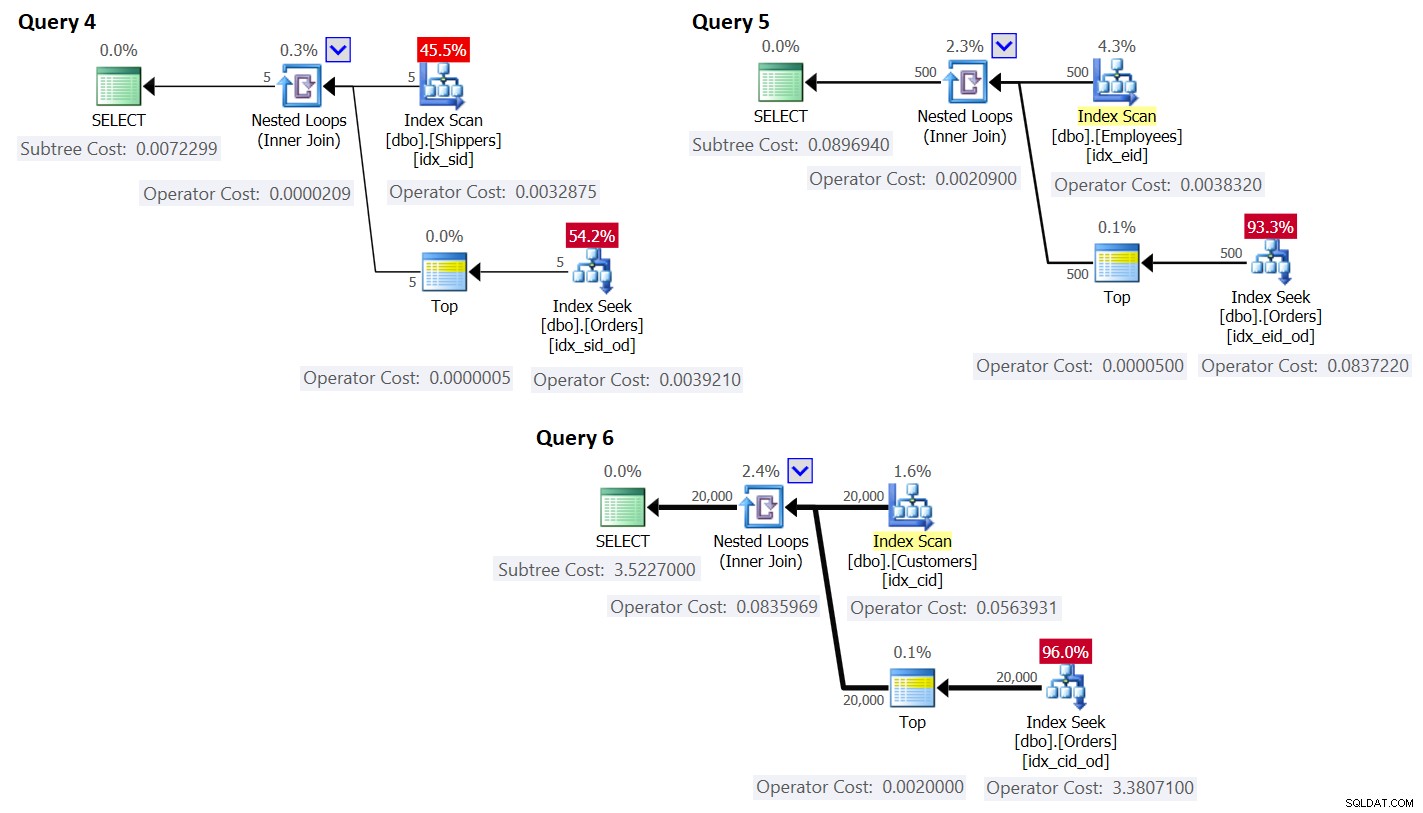 図3:の計画書き換えを伴うクエリ
図3:の計画書き換えを伴うクエリ
ご覧のとおり、グループはグループテーブルのインデックスをスキャンすることで取得され、集計はメインテーブルのインデックスにシークを適用することで取得されます。グループ化セットの密度が高いほど、この計画はグループ化されたクエリのデフォルトの戦略と比較してより最適になります。
以前にデフォルトのスキャン戦略で行ったように、論理読み取りの数を見積もり、シーク戦略のコストを計画しましょう。論理読み取りの推定数は、グループを取得するインデックススキャン演算子の1回の実行の読み取り数と、インデックスシーク演算子のすべての実行の読み取り数です。
インデックススキャン演算子の論理読み取りの推定数は、シークと比較してごくわずかです。それでも、CEILING(1e0 * @numgroups / @rowsperpage)です。例としてクエリ4を取り上げます。インデックスidx_sidがリーフページあたり約600行に収まるとします(データ型がVARCHAR(5)であるため、実際の数は実際のshipperid値によって異なります)。 5つのグループで、すべての行が1つのリーフページに収まります。 5,000のグループがある場合、それらは9ページに収まります。
インデックスシーク演算子のすべての実行の論理読み取りの推定数は、@ numgroups*@indexdepthです。インデックスの深さは次のように計算できます:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
例としてクエリ4を使用して、インデックスidx_sid_odのリーフページごとに約404行、非リーフページごとに約352行を収めることができるとしましょう。繰り返しになりますが、実際の数値は、データ型がVARCHAR(5)であるため、shipperid列に格納されている実際の値によって異なります。見積もりについては、ここで説明する計算を使用できることを忘れないでください。優れた代表的なサンプルデータが利用できる場合は、次のクエリを使用して、特定のインデックスのリーフページと非リーフページに収まる行数を計算できます。
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; 次の出力が得られました:
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
これらの数値を使用すると、テーブルの行数に対するインデックスの深さは次のようになります。
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
テーブルに1,000,000行ある場合、インデックスの深さは3になります。約5,000万行の場合、インデックスの深さは4レベルに増加し、約176億2000万行の場合は5レベルに増加します。
いずれにせよ、グループ数と行数に関して、上記の1ページあたりの行数を想定すると、次の式はクエリ4の論理読み取りの推定数を計算します。
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
たとえば、5つのグループと1,000,000行の場合、合計で16回の読み取りしか得られません。グループ化されたクエリのデフォルトのスキャンベースの戦略には、CEILING(1e0 * @numrows / @rowsperpage)と同じ数の論理読み取りが含まれることを思い出してください。例としてクエリ1を使用し、インデックスidx_sid_odのリーフページあたり約404行、同じ行数が1,000,000であると仮定すると、約2,476回の読み取りが得られます。テーブルの行数を1,000〜1,000,000,000倍に増やしますが、グループの数は固定したままにします。シーク戦略で必要な読み取り数は21にほとんど変化しませんが、スキャン戦略で必要な読み取り数は2,475,248に直線的に増加します。
シーク戦略の利点は、グループの数が少なく固定されている限り、テーブルの行数に対してほぼ一定のスケーリングを持つことです。これは、シークの数がグループの数によって決定され、インデックスの深さが対数的にテーブルの行数に関連しているためです。ここで、ログベースは非リーフページに収まる行数です。逆に、スキャンベースの戦略では、関係する行数に関して線形スケーリングが行われます。
図4は、5つのグループの固定数と、メインテーブルの行数が異なる場合に、クエリ1とクエリ4によって適用された2つの戦略で推定された読み取り数を示しています。
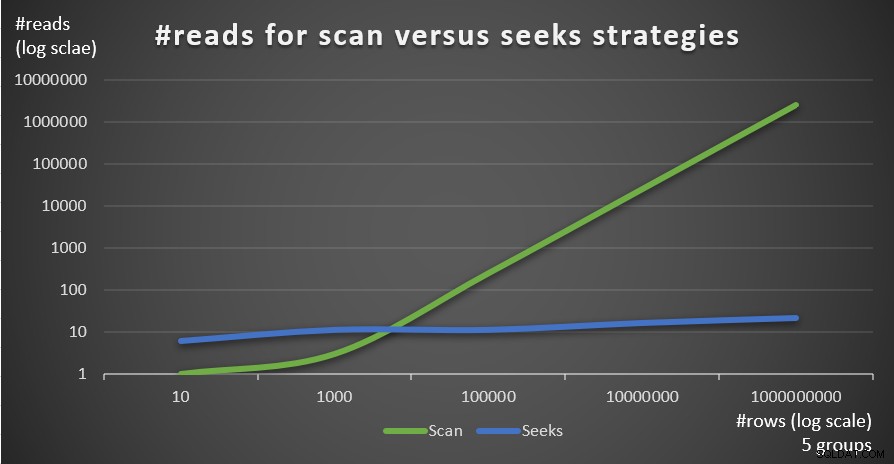 図4:#readsスキャン戦略とシーク戦略(5グループ)
図4:#readsスキャン戦略とシーク戦略(5グループ)
図5は、メインテーブルの行数が1,000,000に固定され、グループの数が異なる場合に、2つの戦略で推定された読み取り数を示しています。
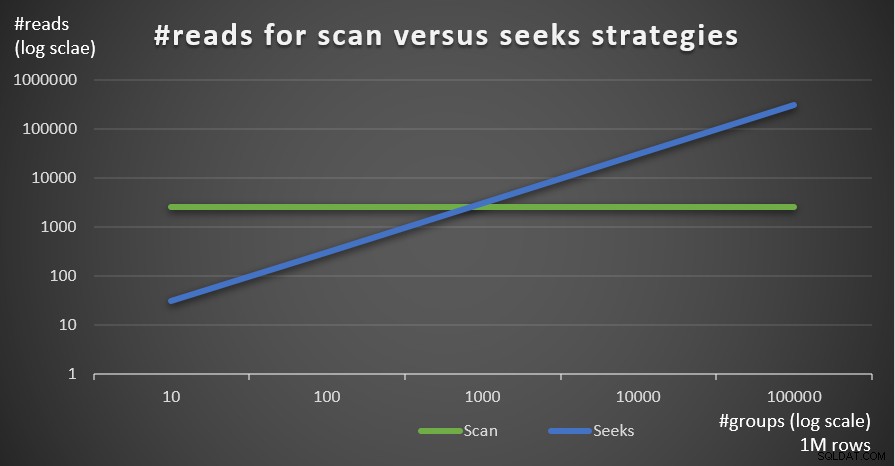 図5:#readsスキャン戦略とシーク戦略(100万行)
図5:#readsスキャン戦略とシーク戦略(100万行)
グループ化セットの密度が高く(グループの数が少ない)、メインテーブルが大きいほど、読み取り数の観点からシーク戦略が優先されることが非常に明確にわかります。各戦略で使用されるI/Oパターンについて疑問がある場合。確かに、インデックスシーク操作はランダムI / Oを実行しますが、インデックススキャン操作はシーケンシャルI/Oを実行します。それでも、より極端なケースでは、どちらの戦略がより最適であるかはかなり明確です。
クエリプランのコストについても、図3のクエリ4のプランを例として使用して、プラン内の個々のオペレーターに分類してみましょう。
インデックススキャンオペレーターのコストのリバースエンジニアリング式は次のとおりです。
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
この場合、5つのグループがあり、すべてが1ページに収まるため、コストは次のようになります。
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
プランに示されているコストは同じです。
以前と同様に、式CEILING(1e0 * @numrows / @rowsperpage)(この場合はCEILING(1e0 * @))を使用して、ページあたりの推定行数に基づいて、インデックスのリーフレベルのページ数を推定できます。 numgroups / @groupsperpage)。インデックスidx_sidがリーフページあたり約600行に収まり、5つのグループで1ページを読み取る必要があるとします。いずれにせよ、インデックススキャン演算子の原価計算式は次のようになります。
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
ネストされたループ演算子のリバースエンジニアリングされた原価計算式は次のとおりです。
@executions * 0.00000418
私たちの場合、これは次のように解釈されます:
@numgroups * 0.00000418
クエリ4の場合、5つのグループで、次のようになります。
5 * 0.00000418 = 0.0000209
プランに示されているコストは同じです。
トップオペレーターのリバースエンジニアリングされた原価計算式は次のとおりです。
@executions * @toprows * 0.00000001
私たちの場合、これは次のように解釈されます:
@numgroups * 1 * 0.00000001
5つのグループを使用すると、次のようになります。
5 * 0.0000001 = 0.0000005
プランに示されているコストは同じです。
Index Seekオペレーターに関しては、ここでPaulWhiteから大きな助けを得ました。友達、ありがとう!計算は、最初の実行と再バインド(前の実行の結果を再利用しない最初以外の実行)では異なります。インデックススキャン演算子で行ったように、コストモデルの定数を特定することから始めましょう:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
行の目標が適用されていない1回の実行では、I/OとCPUのコストは次のようになります。
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
TOP(1)を使用しているため、1ページと1行しか含まれていないため、コストは次のようになります。
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
したがって、この場合のIndexSeek演算子の最初の実行のコストは次のとおりです。
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
再バインドのコストについては、通常どおり、CPUとI/Oのコストで構成されています。それぞれ@rebindcpuと@rebindioと呼びましょう。クエリ4では、5つのグループがあり、4つの再バインドがあります(@rebindsと呼びます)。 @rebindcpuのコストは簡単な部分です。式は次のとおりです。
@rebindcpu = @rebinds * (@cpubase + @cpurow)
私たちの場合、これは次のように解釈されます:
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
@rebindioの部分は少し複雑です。ここで、原価計算式は、統計的に、置換を伴うサンプリングを使用して再バインドが読み取ると予想される個別のページの予想数を計算します。この要素を@pswrと呼びます(置換でサンプリングされた個別のページの場合)。つまり、インデックスには@indexdatapagesのページ数(この場合は2,473)があり、@ rebindsの再バインド数(この場合は4)があります。再バインドするたびに特定のページを読み取る確率が同じであると仮定すると、合計でいくつの異なるページを読み取ることが期待されますか?これは、2,473個のボールが入ったバッグを持ち、4回盲目的にバッグからボールを引き出してから、バッグに戻すのと似ています。統計的に、合計でいくつの異なるボールを引くと予想されますか?オペランドを使用したこの式は次のとおりです。
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
私たちの番号であなたは得る:
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
次に、グループごとの平均の行数とページ数を計算します。
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
クエリ4では、カーディナリティは1,000,000で、密度は1/5=0.2です。だからあなたは得る:
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
次に、フィルタリングせずにI / Oコストを計算します(@ioと呼びます)。
@io = @randomio + (@seqio * (@grouppages - 1e0))
私たちの場合、次のようになります:
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
最後に、シークは各再バインドで1行のみを抽出するため、次の式を使用して@rebindioを計算します。
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
私たちの場合、次のようになります:
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
最後に、オペレーターのコストは次のとおりです。
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
これは、クエリ4の計画に示されているインデックスシークオペレーターのコストと同じです。
これで、すべてのオペレーターのコストを集計して、完全なクエリプランのコストを取得できます。取得:
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) 簡略化すると、Seeks戦略の次の完全な原価計算式が得られます。
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) 例として、T-SQLを使用して、クエリ4のシーク戦略を使用したクエリプランのコストの計算を次に示します。
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; この計算では、クエリ4のコスト0.0072295が計算されます。図3に示されている推定コストは0.0072299です。かなり近いです!演習として、この式を使用してクエリ5とクエリ6のコストを計算し、図3に示す数値に近い数値が得られることを確認します。
デフォルトのスキャンベースの戦略のコスト計算式は(スキャンと呼びます)であることを思い出してください。 戦略):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
例としてクエリ1を使用し、テーブルに1,000,000行、ページあたり404行、5つのグループを想定すると、スキャン戦略の推定クエリプランコストは3.5366です。
図6は、5のグループの固定数と、メインテーブルの行数が異なる場合に、クエリ1(スキャン)とクエリ4(シーク)によって適用される2つの戦略の推定クエリプランコストを示しています。
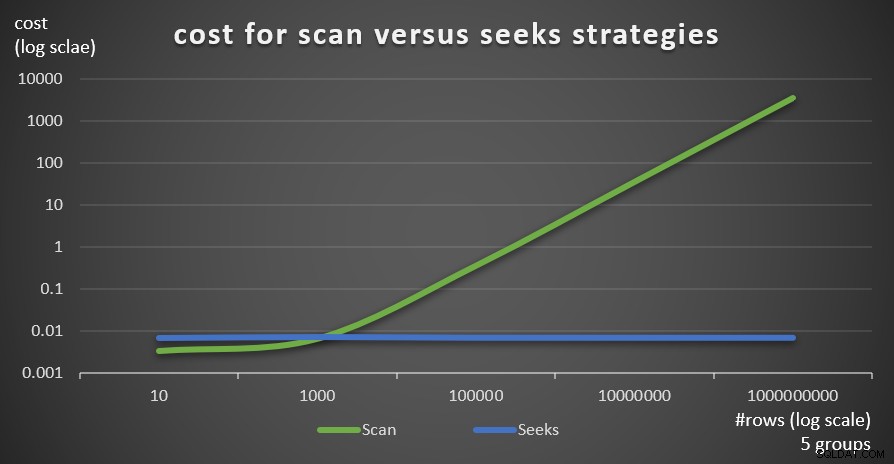 図6:コストスキャン戦略とシーク戦略(5グループ)
図6:コストスキャン戦略とシーク戦略(5グループ)
図7は、メインテーブルの行数が1,000,000に固定され、グループの数が異なる場合の2つの戦略の推定クエリプランコストを示しています。
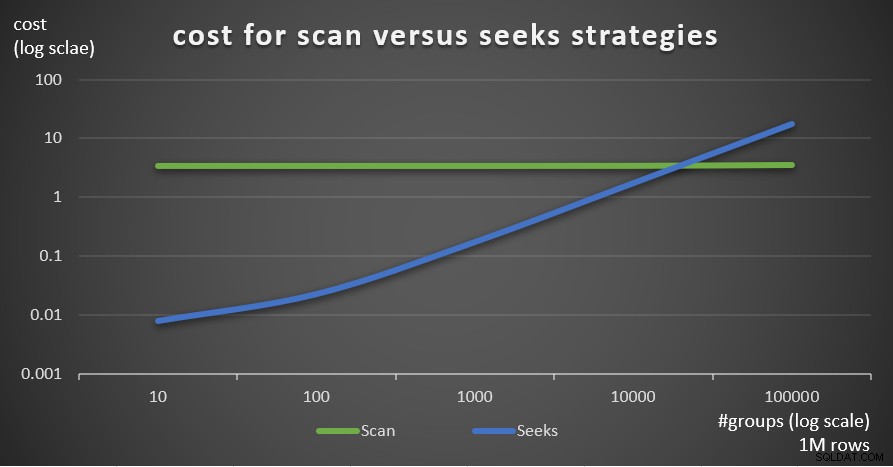 図7:コストスキャン戦略とシーク戦略(100万行)
図7:コストスキャン戦略とシーク戦略(100万行)
これらの調査結果から明らかなように、グループ化セットの密度が高く、メインテーブルの行が多いほど、スキャン戦略と比較してシーク戦略が最適になります。したがって、高密度のシナリオでは、必ずAPPLYベースのソリューションを試してください。それまでの間、Microsoftがこの戦略をグループ化されたクエリの組み込みオプションとして追加することを期待できます。
結論
この記事では、データをグループ化して集約するクエリのクエリ最適化しきい値に関する5部構成のシリーズを締めくくっています。このシリーズの目標の1つは、オプティマイザーが使用できるさまざまなアルゴリズムの詳細、各アルゴリズムが優先される条件、および独自のクエリの書き換えにいつ介入する必要があるかについて説明することでした。もう1つの目標は、さまざまなオプションを見つけて比較するプロセスを説明することでした。明らかに、同じ分析プロセスを、フィルタリング、結合、ウィンドウ処理、およびクエリ最適化の他の多くの側面に適用できます。うまくいけば、クエリの調整に以前よりも対処できるようになりました。