先月、私は特別な島々の挑戦を取り上げました。タスクは、入力秒数(@allowedgap)までのギャップを許容して、各サービスIDのアクティビティの期間を特定することでした。 )。注意点は、ソリューションは2012年より前の互換性が必要であったため、LAGやLEADなどの関数を使用したり、ウィンドウ関数をフレームで集約したりすることはできませんでした。 Toby Ovod-Everett、Peter Larsson、KamilKosnoのコメントに非常に興味深い解決策がいくつか投稿されました。それらはすべて非常に創造的であるため、必ずソリューションを確認してください。
不思議なことに、多くのソリューションは、推奨されるインデックスを使用しない場合よりも使用した場合の方が実行速度が遅くなりました。この記事では、これについての説明を提案します。
すべてのソリューションは興味深いものでしたが、ここでは、ZopaのETL開発者であるKamilKosnoによるソリューションに焦点を当てたいと思いました。彼のソリューションでは、カミルは非常に創造的な手法を使用して、LAGとLEADを使用せずにLAGとLEADをエミュレートしました。 2012年より前の互換性のあるコードを使用してLAG/LEADのような計算を実行する必要がある場合は、この手法が便利です。
推奨されるインデックスがないと、一部のソリューションが高速になるのはなぜですか?
念のため、次のインデックスを使用して、課題の解決策をサポートすることをお勧めします。
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
2012年以前の互換性のあるソリューションは次のとおりです。
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; 図1は、推奨されるインデックスが設定されたソリューションの計画です。
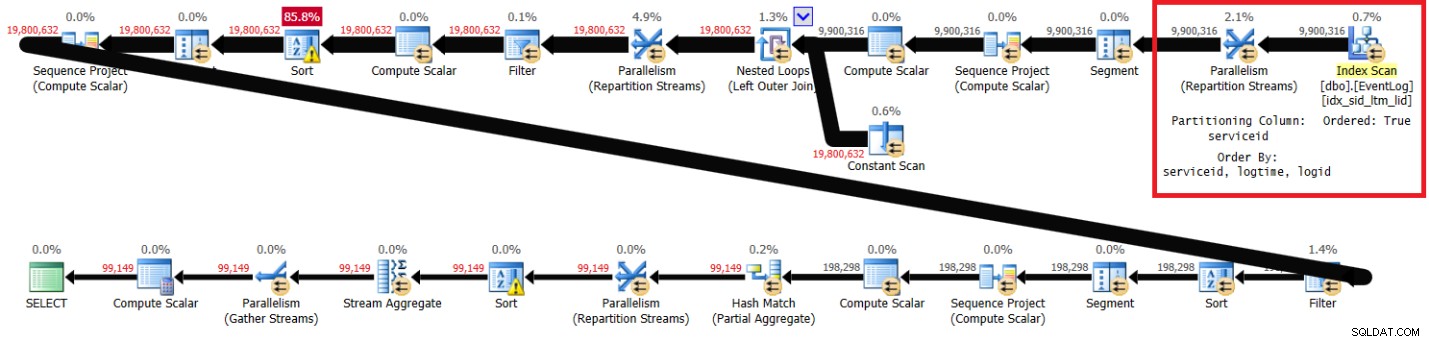 図1:推奨インデックスを使用したItzikのソリューションの計画
図1:推奨インデックスを使用したItzikのソリューションの計画
プランは推奨されるインデックスをキーの順序でスキャンし(OrderedプロパティはTrue)、順序を保持する交換を使用してserviceidでストリームを分割し、並べ替えを必要とせずにインデックスの順序に依存する行番号の初期計算を適用することに注意してください。以下は、ラップトップでのこのクエリ実行で得られたパフォーマンス統計です(経過時間、CPU時間、およびトップ待機時間は秒単位で表されます):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
次に、推奨されるインデックスを削除して、ソリューションを再実行しました:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
図2に示す計画を取得しました。
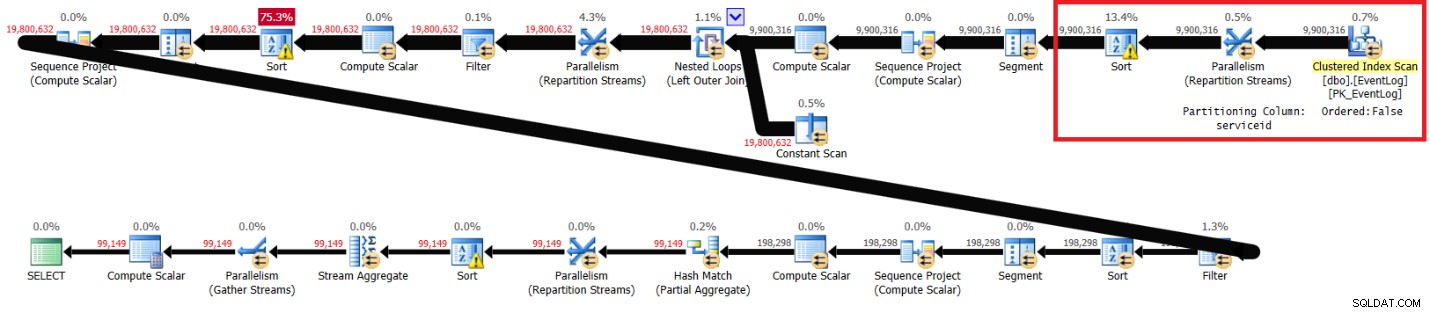 図2:推奨インデックスなしのItzikのソリューションの計画
図2:推奨インデックスなしのItzikのソリューションの計画
2つの計画で強調表示されているセクションは、違いを示しています。推奨インデックスのないプランは、クラスター化インデックスの順序付けされていないスキャンを実行し、順序を保持しない交換を使用してサービスIDでストリームを分割し、ウィンドウ関数が必要とするように(serviceid、logtime、logidで)行を並べ替えます。残りの作業は両方の計画で同じようです。推奨インデックスのないプランは、他のプランにはない余分な種類があるため、遅くなるはずです。ただし、このプランでラップトップで取得したパフォーマンス統計は次のとおりです。
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
CPU時間が長くなりますが、これは一部、余分な並べ替えが原因です。おそらく追加のソートスピルが原因で、より多くのI/Oが関係しています。ただし、経過時間は約30%速くなります。これを説明できるのは何ですか?これを理解するための1つの方法は、LiveQueryStatisticsオプションを有効にしてSSMSでクエリを実行することです。これを行ったとき、右端のParallelism(Repartition Streams)オペレーターは、推奨インデックスなしで6秒、推奨インデックスありで35秒で終了しました。主な違いは、前者はインデックスから事前に順序付けられたデータを取得し、順序を保持する交換であるということです。後者はデータを順序付けせずに取得し、順序を保持する交換ではありません。注文を保持する交換は、順序を保持しない交換よりも高価になる傾向があります。また、少なくとも最初の並べ替えまでの計画の右端では、前者は交換パーティション列と同じ順序で行を配信するため、すべてのスレッドで実際に行を並列処理することはできません。後者は行を順序付けずに配信するため、すべてのスレッドが行を真に並列に処理できるようになります。両方のプランの上位の待機はCXPACKETであることがわかりますが、前者の場合、待機時間は後者の2倍であり、後者の場合の並列処理がより最適であることがわかります。私が考えていない他の要因が働いている可能性があります。驚くべきパフォーマンスの違いを説明できる追加のアイデアがある場合は、共有してください。
私のラップトップでは、これにより、推奨インデックスがない場合の実行が、推奨インデックスがある場合よりも速くなりました。それでも、別のテストマシンでは、その逆でした。結局のところ、こぼれる可能性のある余分な種類があります。
好奇心から、推奨されるインデックスを使用して(MAXDOP 1オプションを使用して)シリアル実行をテストし、ラップトップで次のパフォーマンス統計を取得しました。
elapsed: 42, CPU: 40, logical reads: 143,519
ご覧のとおり、実行時間は、推奨されるインデックスが設定された並列実行の実行時間と同様です。ラップトップには4つの論理CPUしかありません。もちろん、マイレージはハードウェアによって異なる場合があります。重要なのは、インデックスを作成する場合と使用しない場合を含め、さまざまな代替案をテストする価値があるということです。結果は驚くべきものであり、直感に反する場合があります。
カミルのソリューション
私はカミルのソリューションに本当に興味をそそられ、特に彼が2012年以前の互換性のある手法でLAGとLEADをエミュレートする方法が好きでした。
ソリューションの最初のステップを実装するコードは次のとおりです。
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
このコードは、次の出力を生成します(serviceid 1のデータのみを表示します):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
このステップでは、行ごとに1つずつ離れ、serviceidでパーティション化され、logtimeで並べ替えられた2つの行番号を計算します。現在の行番号は終了時刻(end_timeと呼びます)を表し、現在の行番号から1を引いたものは開始時刻(start_timeと呼びます)を表します。
次のコードは、ソリューションの2番目のステップを実装します。
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; この手順により、次の出力が生成されます。
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
この手順では、各行を2つの行にピボット解除し、各ログエントリを複製します。1つは時間タイプstart_time用で、もう1つはend_time用です。ご覧のとおり、最小行番号と最大行番号を除いて、各行番号は2回表示されます。1回目は現在のイベントのログ時間(start_time)で、もう1回は前のイベントのログ時間(end_time)です。
次のコードは、ソリューションの3番目のステップを実装します。
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; このコードは次の出力を生成します:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
このステップでは、データをピボットし、同じ行番号の行のペアをグループ化し、現在のイベントログ時間(start_time)用に1つの列を返し、前のイベントログ時間(end_time)用に別の列を返します。この部分は、LAG関数を効果的にエミュレートします。
次のコードは、ソリューションの4番目のステップを実装します。
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; このコードは次の出力を生成します:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
このステップでは、前の終了時刻と現在の開始時刻の差が許容ギャップよりも大きいペアと、イベントが1つしかない行をフィルタリングします。次に、現在の各行の開始時刻を次の行の終了時刻に接続する必要があります。これには、LEADのような計算が必要です。これを実現するために、コードは再び1つ離れた行番号を作成します。今回は、現在の行番号が開始時刻(start_time_grp)を表し、現在の行番号から1を引いたものが終了時刻(end_time_grp)を表します。
前と同じように、次のステップ(番号5)は行のピボットを解除することです。この手順を実装するコードは次のとおりです。
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; 出力:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
ご覧のとおり、grp列はサービスID内の島ごとに一意です。
ステップ6は、ソリューションの最後のステップです。このステップを実装するコードは次のとおりです。これは完全なソリューションコードでもあります。
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); この手順により、次の出力が生成されます。
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
このステップでは、行をserviceidとgrpでグループ化し、関連するグループのみをフィルタリングし、最小のstart_timeを島の始まりとして返し、最大の終了時間を島の終わりとして返します。
図3は、推奨されるインデックスを設定したこのソリューションで得た計画です。
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
図3の推奨インデックスを使用して計画します。
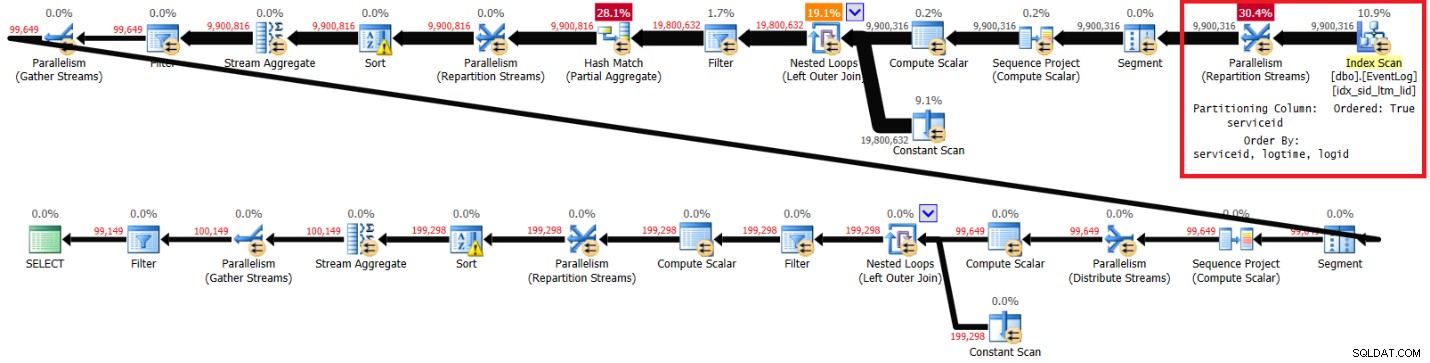 図3:推奨インデックスを使用したKamilのソリューションの計画
図3:推奨インデックスを使用したKamilのソリューションの計画
ラップトップでのこの実行で得られたパフォーマンス統計は次のとおりです。
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
次に、推奨されるインデックスを削除して、ソリューションを再実行しました:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
推奨インデックスなしで実行するための図4に示す計画を取得しました。
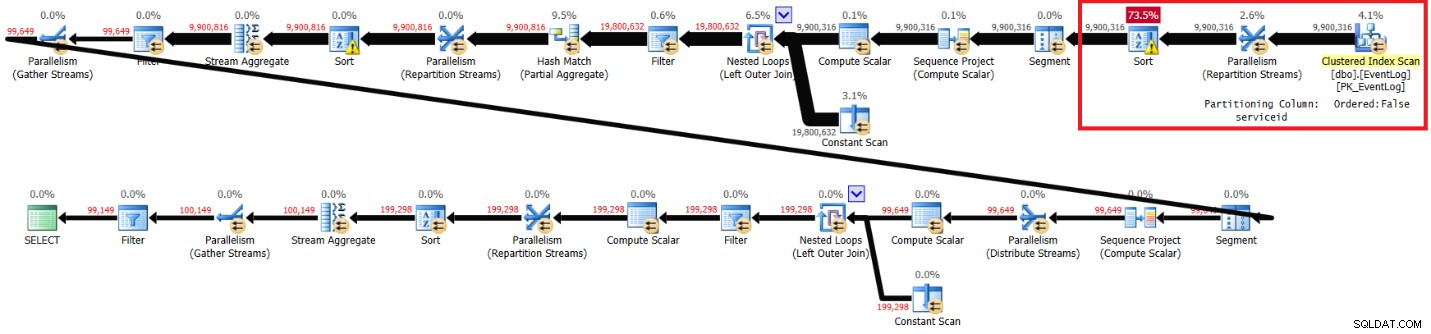 図4:推奨インデックスなしのKamilのソリューションの計画
図4:推奨インデックスなしのKamilのソリューションの計画
この実行で得られたパフォーマンス統計は次のとおりです。
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
実行時間、CPU時間、CXPACKET待機時間は私のソリューションと非常に似ていますが、論理的な読み取りは少なくなります。カミルのソリューションは、推奨されるインデックスがなくても私のラップトップでより高速に実行されます。これは同様の理由によるものと思われます。
結論
異常は良いことです。彼らはあなたを好奇心をそそり、問題の根本的な原因を調査し、その結果、新しいことを学ぶようにさせます。特定のマシンで、推奨されるインデックス付けなしで一部のクエリがより高速に実行されるのを見るのは興味深いことです。
ソリューションを提供してくれたToby、Peter、Kamilに改めて感謝します。この記事では、カミルのソリューションについて、LAGとLEADを行番号でエミュレートし、ピボットを解除してピボットするという彼の創造的な手法について説明しました。この手法は、2012年より前の環境でサポートする必要があるLAGおよびLEADのような計算が必要な場合に役立ちます。