最近、新しいサポートサイトを立ち上げました。このサイトでは、質問をしたり、製品のフィードバックや機能のリクエストを送信したり、サポートチケットを開いたりできます。目標の一部は、私たちがコミュニティに支援を提供していたすべての場所を一元化することでした。これには、SQLPerformance.comのQ&Aサイトが含まれ、Paul White、Hugo Kornelis、および他の多くの人が、2013年2月までさかのぼって、最も複雑なクエリチューニングと実行プランの質問の解決を支援してきました。 Q&Aサイトは閉鎖されました。
ただし、利点があります。新しいサポートフォーラムで、これらの難しい質問をすることができます。古いコンテンツを探しているなら、それはまだそこにありますが、少し異なって見えます。今日はさまざまな理由で、元のQ&Aサイトを廃止することを決定した後、最終的には、既存のすべてのコンテンツをバックエンドに移行するのではなく、読み取り専用のWordPressサイトでホストすることにしました。新しいサイトの。
この投稿は、その決定の背後にある理由についてではありません。
回答サイトがオフラインになり、DNSが切り替わり、コンテンツが移行されるまでの時間について、私は本当に気分が悪くなりました。警告バナーがサイトに実装されましたが、AnswerHubは実際にはそれを表示しなかったため、これは多くのユーザーにとってショックでした。ですから、できるだけ多くのコンテンツを適切に保持していることを確認したかったので、それを正しくしたかったのです。この投稿は、実際のプロセス、それを実現するためにいくつの異なるテクノロジーが関与しているか、そして結果を披露するのが面白いと思ったので、ここにあります。これは比較的あいまいな移行パスであるため、このエンドツーエンドのメリットを享受できるとは思いませんが、タスクを実行するために多数のテクノロジーを結び付ける例として使用します。また、多くのことは、始める前に聞こえるほど簡単ではないことを私自身に思い出させるのにも役立ちます。
TL; DR これは、アーカイブされたコンテンツの見栄えを良くするために多くの時間と労力を費やしましたが、最後に届いた最後のいくつかの投稿を復元しようとしています。私はこれらのテクノロジーを使用しました:
- Perl
- SQL Server
- PowerShell
- 送信(FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
したがって、タイトル。残酷な詳細の大きな塊が必要な場合は、ここにあります。ご質問やご意見がございましたら、以下にご連絡またはコメントしてください。
AnswerHubは、Q&AコンテンツをホストするMySQLデータベースから665MBのダンプファイルを提供しました。私が試したすべてのエディターはそれに詰まっていたので、最初にJared Cheneyのこの便利なPerlスクリプトを使用して、テーブルごとにファイルに分割する必要がありました。必要なテーブルはnetwork11_nodesと呼ばれていました (質問、回答、コメント)、 network11_authoritables (ユーザー)、および network11_managed_files (プランのアップロードを含むすべての添付ファイル):perlextract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
これらはSSMSでの読み込みがそれほど速くはありませんでしたが、少なくともそこでは Ctrlを使用できました。 + H これを(たとえば)変更するには:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
これに:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
次に、データをSQL Serverにロードして、操作できるようにしました。そして私を信じて、私はそれを操作しました。
次に、すべての添付ファイルを取得する必要がありました。ベンダーから入手したMySQLダンプファイルには、膨大な数の INSERTが含まれていました。 ステートメントがありますが、ユーザーがアップロードした実際の計画ファイルはありません—データベースにはファイルへの相対パスしかありませんでした。 T-SQLを使用して、 Invoke-WebRequestを呼び出す一連のPowerShellコマンドを作成しました すべてのファイルを取得してローカルに保存します(この猫の皮を剥ぐ方法はたくさんありますが、これは簡単にできました)。これから:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
これにより、この一連のコマンドが生成されました(このTLSの問題を解決するための事前コマンドとともに)。全体が非常に高速に実行されましたが、{大量のファイルセット}や{低帯域幅}の組み合わせにはこのアプローチはお勧めしません:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
これにより、ほとんどすべての添付ファイルがダウンロードされましたが、確かに、最初にアップロードされたときの古いサイトのエラーのために、一部が見落とされていました。そのため、新しいサイトでは、存在しない添付ファイルへの参照が表示される場合があります。
次に、PanicTransmit5を使用してtempをアップロードしました 新しいサイトへのフォルダ。コンテンツがアップロードされると、 /s/temp/1-proc.pesessionにリンクします。 引き続き機能します。
次に、SSLに移りました。新しいWordPressサイトで証明書をリクエストするには、answers.sqlperformance.comのDNSを更新して、WordPressホストであるWPEngineのCNAMEを指すようにする必要がありました。ここでは一種の鶏肉と卵でした。httpsURLのダウンタイムが発生し、新しいサイトに証明書がないと失敗しました。古いサイトの証明書の有効期限が切れていたので、これは問題ありませんでした。また、古いサイトからすべてのファイルをダウンロードするまで、これを行うのを待たなければなりませんでした。DNSが反転すると、バックドアを経由する以外にそれらにアクセスする方法がないためです。
DNSが伝播するのを待っている間に、すべての質問、回答、コメントをWordPressで使用できるものに取り込むロジックの作業を開始しました。テーブルスキーマがWordPressと異なるだけでなく、エンティティのタイプもかなり異なります。私のビジョンは、各質問(および回答やコメント)を1つの投稿にまとめることでした。
トリッキーな部分は、nodesテーブルに、親と元の(「マスター」)親参照を含む、同じテーブル内の3つのコンテンツタイプすべてが含まれていることです。彼らのフロントエンドコードは、ある種のカーソルを使用して、コンテンツを階層的かつ時系列でステップスルーして表示する可能性があります。 WordPressにはそれほど贅沢はないので、HTMLを1回のショットでつなぎ合わせる必要がありました。例として、データは次のようになります。
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
ID、タイプ、または親で並べ替えることはできませんでした。以前の回答に対してコメントが後で来ることがあり、最初の回答が必ずしも受け入れられた回答であるとは限らないためです。この出力が欲しかった( ++ インデントの1つのレベルを表します):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
再帰CTEを書き始め、<取り消し線>部分的に その夜のRekorderligが多すぎたため、私は仲間のプロダクトマネージャーであるAndy Mallon(@AMtwo)の助けを借りました。彼は私がこのクエリを作成するのを手伝ってくれました。これにより、投稿が適切な表示順序で返されます(このスニペットを試して、親や承認された回答を変更して、正しい順序が引き続き返されることを確認できます):
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; 結果:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
天才。私は十数人をスポットチェックし、次のステップに進んでうれしかった。アンディに何度も感謝しましたが、もう一度やり直させてください。アンディに感謝します!
セット全体を好きな順序で返すことができたので、出力を操作してHTML要素とクラス名を適用し、質問、回答、コメント、インデントを意味のある方法でマークできるようにする必要がありました。最終目標は次のように出力されました(これはより単純なケースの1つであることに注意してください):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
5,000以上のアイテムすべてについて、その出力の信頼できる形式に到達するために実行しなければならなかったばかげた数の反復をステップスルーしません(すべてが接着されると、ほぼ1,000の投稿に変換されます)。その上、 INSERTの形式でこれらを生成する必要がありました 次に、WordPressサイトのphpMyAdminに貼り付けることができるステートメント。これは、奇妙な構文図に準拠することを意味します。これらのステートメントには、WordPressに必要なその他の追加情報を含める必要がありましたが、ソースデータ( post_type など)に存在または正確ではありませんでした。 )。また、その管理コンソールは、データが多すぎるとタイムアウトになるため、一度に最大750の挿入にチャンクする必要がありました。これが私が最終的に得た手順です(これは実際には特定のことを学ぶためのものではなく、インポートされたデータの操作がどれだけ必要だったかのデモンストレーションにすぎません):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO それからの出力は完全ではなく、WordPressに詰め込む準備がまだできていません:
 サンプル出力(クリックして拡大)
サンプル出力(クリックして拡大)
実際のコンテンツ(マークダウンを含む)をより適切に制御できるHTMLとCSSに変換し、出力( INSERT の束)を書き込むには、C#からの追加のヘルプが必要になります。 たまたま大量のHTMLコードが含まれていたステートメント)をディスク上のファイルに開いて、phpMyAdminに貼り付けることができました。 HTMLの場合、次のように開始されたプレーンテキスト+マークダウン:
dbo.sometableから何かを選択します;
[1]:https:// elsewhere
これになる必要があります:
それについて説明している
dbo.sometableから何かを選択します; これを実現するために、私はMarkdownSharpの助けを借りました。これは、MarkdownからHTMLへの変換の多くを処理するStackOverflowで作成されたオープンソースライブラリです。それは私のニーズにはぴったりでしたが、完璧ではありませんでした。それでもさらに操作を実行する必要があります:
- MarkdownSharpでは、
target =_blankなどは使用できません。 、したがって、処理後に自分でそれらを注入する必要があります。 - コード(4つのスペースが前に付いているもの)は
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }はい、それは醜いコードの束ですが、最終的にはphpMyAdminを吐き出さない出力のセットに到達し、WordPressは(十分に)うまく表示されます。異なるパラメータ範囲でC#プログラムを複数回呼び出しただけです:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
次に、各ファイルを開いてphpMyAdminに貼り付け、GO:
を押します。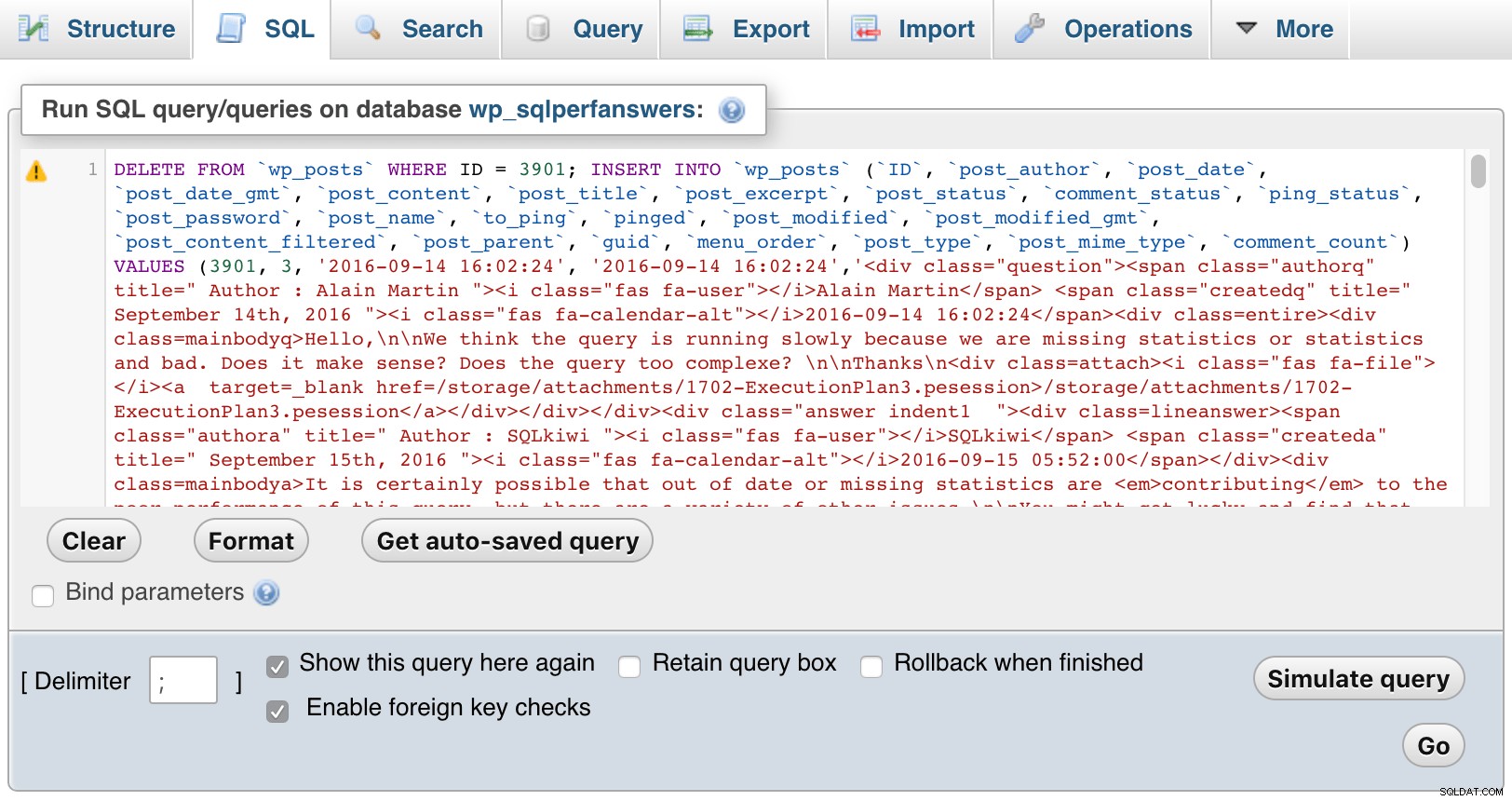 phpMyAdmin(クリックして拡大)
phpMyAdmin(クリックして拡大) もちろん、WordPress内にCSSを追加して、質問、コメント、回答を区別したり、コメントをインデントして質問と回答の両方への返信を表示したり、コメントにコメントをネストしたりする必要がありました。 1か月の質問にドリルスルーすると、抜粋は次のようになります。
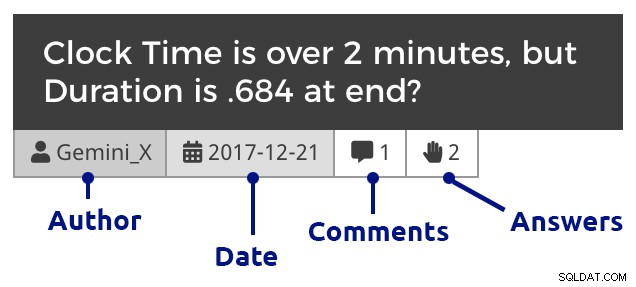 質問タイル(クリックして拡大)
質問タイル(クリックして拡大) 次に、埋め込み画像、複数の添付ファイル、ネストされたコメント、および回答を示す投稿例:
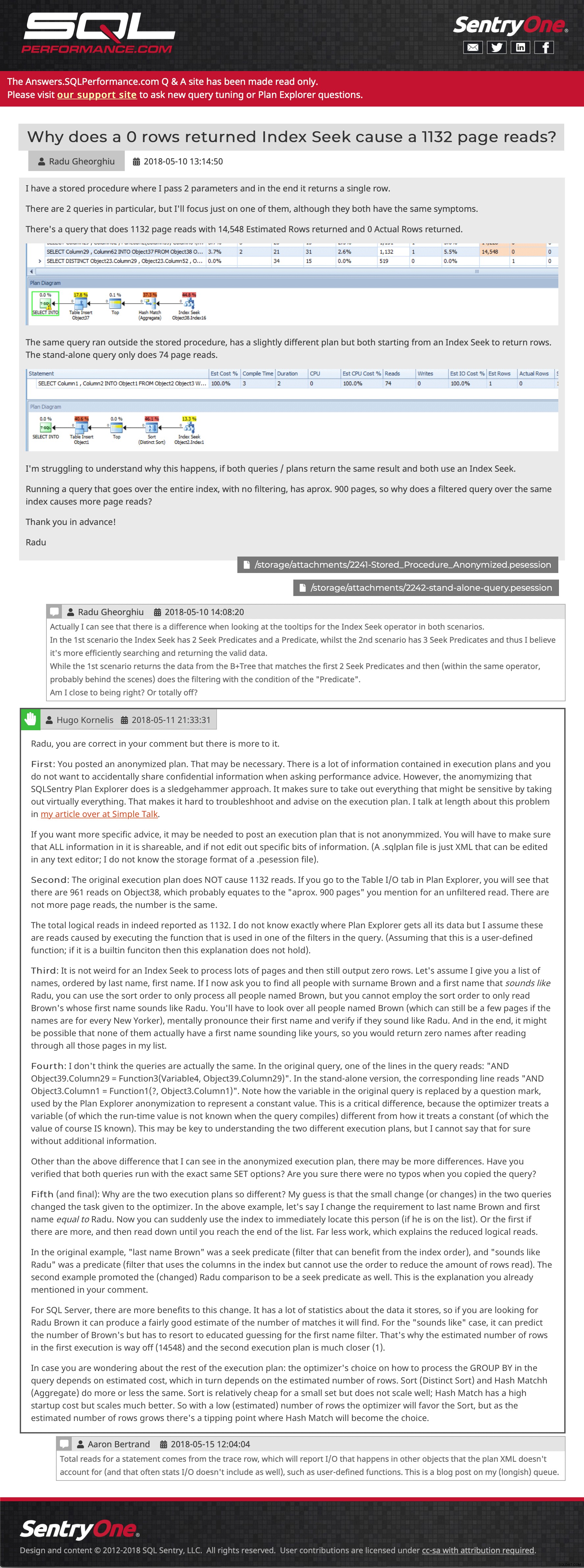 サンプルの質問と回答(クリックしてそこに移動)
サンプルの質問と回答(クリックしてそこに移動) 最後のバックアップが取られた後にサイトに送信されたいくつかの投稿をまだ回復しようとしていますが、閲覧することを歓迎します。足りないものや場違いなものを見つけた場合はお知らせください。また、コンテンツが引き続き役立つことをお知らせください。プランエクスプローラー内からプランアップロード機能を再導入したいと考えていますが、新しいサポートサイトでAPIの作業が必要になるため、今日はETAを用意していません。
- Answers.SQLPerformance.com