マイクロソフトまたはマイクロソフトパートナーに連絡して、クラウドに移行するのにかかる費用について話し合ったことはありますか?もしそうなら、Azure SQL Database DTU計算機について聞いたことがあるかもしれません。また、AndyMallonによってリバースエンジニアリングされた方法についても読んだことがあるかもしれません。 DTU計算機は、サーバーからパフォーマンスメトリックをアップロードし、そのサーバーをAzure SQLデータベース(またはSQLデータベースエラスティックプール)に移行する場合に適切なサービス層を決定するために使用できる無料のツールです。
これを行うには、通常の本番ワークロードの期間中に、スクリプト(コマンドラインまたはPowershell、DTU計算機のWebサイトからダウンロード可能)をスケジュールするか、手動で実行する必要があります。
大規模な環境を分析しようとしている場合、または特定の時点のデータを分析したい場合、これは面倒な作業になる可能性があります。多くの場合、多くのDBAには、パフォーマンスデータをすでにキャプチャしている監視ツールのフレーバーがあります。多くの場合、必要なメトリックをすでにキャプチャしているか、必要なデータをキャプチャするように簡単に構成できます。今日は、SentryOneを利用して、DTU計算機に適切なデータを提供する方法を見ていきます。
まず、DTU計算機のWebサイトで入手できるコマンドラインユーティリティとPowerShellスクリプトによって取得される情報を見てみましょう。キャプチャするパフォーマンスモニターカウンターは4つあります。
- プロセッサ–%プロセッサ時間
- 論理ディスク–ディスク読み取り/秒
- 論理ディスク–ディスク書き込み/秒
- データベース–フラッシュされたログバイト/秒
最初のステップは、これらのメトリックがSQLSentryのデータ収集の一部としてすでにキャプチャされているかどうかを判断することです。発見のために、Jason Hallによるこのブログ投稿を読むことをお勧めします。ここでは、データのレイアウト方法とクエリ方法について説明しています。ここでは、この各ステップについては説明しませんが、ブログシリーズ全体を読んでブックマークすることをお勧めします。
SentryOneデータベースを調べたところ、4つのカウンターのうち3つがデフォルトですでにキャプチャされていることがわかりました。欠落していたのは[Database – Log Bytes Flushed/sec]だけでした。 、それで私はそれをオンにできる必要がありました。その方法を説明するJustinRandallによる別のブログ投稿がありました。
つまり、[PerformanceAnalysisCounter]にクエリを実行できます。 テーブル。
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
デフォルトでは、[PerformanceAnalysisSampleIntervalID]に気付くでしょう。 は0に設定されます–これは無効になっていることを意味します。これを有効にするには、次のコマンドを実行する必要があります。実行したSELECTクエリからIDを取得し、このUPDATEで使用するだけです:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
更新を実行した後、新しいカウンターデータを収集できるように、このターゲットに関連するSentryOne監視サービスを再起動する必要があります。
[PerformanceAnalysisSampleIntervalID]を設定したことに注意してください データが10秒ごとにキャプチャされるように、1に設定します。ただし、このデータをキャプチャする頻度を減らして、収集されるデータのサイズを最小限に抑えることができますが、精度は低下します。 [PerformanceAnalysisSampleInterval]を参照してください 使用できる値のリストの表。
データがすぐにテーブルに流れ始めることを期待しないでください。これは、システムを通過するのに時間がかかります。次のクエリで人口を確認できます:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
データが表示されていることを確認したら、DTU計算機に必要な各メトリックのデータを取得する必要がありますが、完全なワークロードまたはビジネスサイクルからの代表的なサンプルが得られるまで、データを抽出するのを待つことをお勧めします。
>Jasonのブログ投稿を読むと、データがさまざまなロールアップテーブルに保存されており、これらの各ロールアップテーブルの保持率が異なることがわかります。これらの多くは、ある期間にわたってワークロードを分析している場合に必要なものよりも低くなっています。これらを変更することは可能かもしれませんが、それは最も賢明ではないかもしれません。私がお見せしているのはサポートされていないため、パフォーマンス、成長、またはその両方に悪影響を与える可能性があるため、SentryOneの設定をいじりすぎないようにすることをお勧めします。
これを補うために、さまざまなロールアップテーブルに必要なデータを抽出し、そのデータを独自の場所に保存できるスクリプトを作成しました。これにより、SentryOneの機能に干渉することなく、独自の保持を制御できます。
表:dbo.AzureDatabaseDTUData
[AzureDatabaseDTUData]というテーブルを作成しました そしてそれをSentryOneデータベースに保存しました。私が作成したプロシージャは、このテーブルが存在しない場合は自動的に生成するため、保存場所をカスタマイズする場合を除いて、手動でこれを行う必要はありません。必要に応じて、これを別のデータベースに保存できます。そのためには、スクリプトを編集する必要があります。表は次のようになります:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
手順:dbo.Custom_CollectDTUDataForDevice
これは、すべてのDTU固有のデータを一度にプルするために使用できるストアドプロシージャです(十分な時間ログバイトカウンターを収集している場合)。または、収集されたデータに定期的に追加するようにスケジュールします。これで、出力をDTU計算機に送信する準備が整いました。上記の表のように、プロシージャはSentryOneデータベースで作成されますが、オブジェクト参照に3つまたは4つの部分からなる名前を追加するだけで、他の場所で簡単に作成できます。手順へのインターフェースは次のとおりです。
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
注 :手順全体が少し長いため、この投稿(dbo.Custom_CollectDTUDataForDevice.sql_.zip)に添付されています。
使用できるパラメーターがいくつかあります。それぞれにデフォルト値があるため、デフォルト値で問題がない場合は、それらを指定する必要はありません。
- @DeviceID –これにより、特定のSQLServerまたはすべてのデータを収集するかどうかを指定できます。デフォルトは-1です。これは、監視対象のすべてのSQLServerをコピーすることを意味します。特定のインスタンスの情報のみをエクスポートする場合は、
DeviceIDを見つけます。[dbo].[Device]のホストに対応します テーブル、およびその値を渡します。渡すことができる@DeviceIDは1つだけです 一度に、一連のサーバーを通過する場合は、プロシージャを複数回呼び出すか、一連のデバイスをサポートするようにプロシージャを変更できます。 - @DaysToPurge –これは、データを削除する年齢を表します。デフォルトは14日です。つまり、14日までのデータのみをプルし、カスタムテーブル内の14日より古いデータはすべて削除されます。
他の4つのパラメーターは、SentryOneがカウンターIDの列挙を変更した場合に備えて、将来を保証するためにあります。
スクリプトに関するいくつかの注意事項:
- データがプルされると、切り捨てられた分から最大値を取得し、それをエクスポートします。これは、1分あたりのメトリックごとに1つの値があることを意味しますが、それはキャプチャされた最大値です。データをDTU計算機に提示する必要があるため、これは重要です。
- 初めてエクスポートを実行するときは、もう少し時間がかかる場合があります。これは、パラメータ値に基づいて可能なすべてのデータを取得するためです。追加の実行ごとに、抽出されるデータは前回の実行以降の新しいデータのみであるため、はるかに高速になるはずです。
- SentryOneのパージプロセスよりも進んだタイムスケジュールで実行するには、この手順をスケジュールする必要があります。私が行ったことは、毎晩実行するSQLエージェントジョブを作成したところです。このジョブは、前夜以降のすべての新しいデータを収集します。
- SentryOneのパージプロセスはメトリックに基づいて変化する可能性があるため、ある期間に4つのカウンターすべてを含まない行がコピーに含まれる可能性があります。抽出プロセスを開始したときからのみデータの分析を開始することをお勧めします。
- 既存のSentryOneプロシージャのコードブロックを使用して、各カウンタのロールアップテーブルを決定しました。テーブルの現在の名前をハードコーディングすることもできますが、SentryOneメソッドを使用することで、組み込みのロールアッププロセスへの変更と前方互換性があるはずです。
データをスタンドアロンテーブルに移動したら、PIVOTクエリを使用して、データをDTU計算機が期待する形式に変換できます。
手順:dbo.Custom_ExportDataForDTUCalculator
データをCSV形式に抽出する別の手順を作成しました。このプロシージャのコードも添付されています(dbo.Custom_ExportDataForDTUCalculator.sql_.zip)。
3つのパラメータがあります:
- @DeviceID –収集していて、電卓に送信するデバイスの1つに対応するSmallint。
- @BeginTime –開始時刻を現地時間で表す日時。例:
'2018-12-04 05:47:00.000'。手順はUTCに変換されます。省略した場合は、表の最も早い値から収集されます。 - @EndTime –終了時刻を表す日時。これも現地時間です。例:
'2018-12-06 12:54:00.000'。省略した場合は、テーブル内の最新の値まで収集されます。
SQLInstanceA用に収集されたすべてのデータを取得するための実行例 12月4日午前5時47分から12月6日午後12時54分まで。
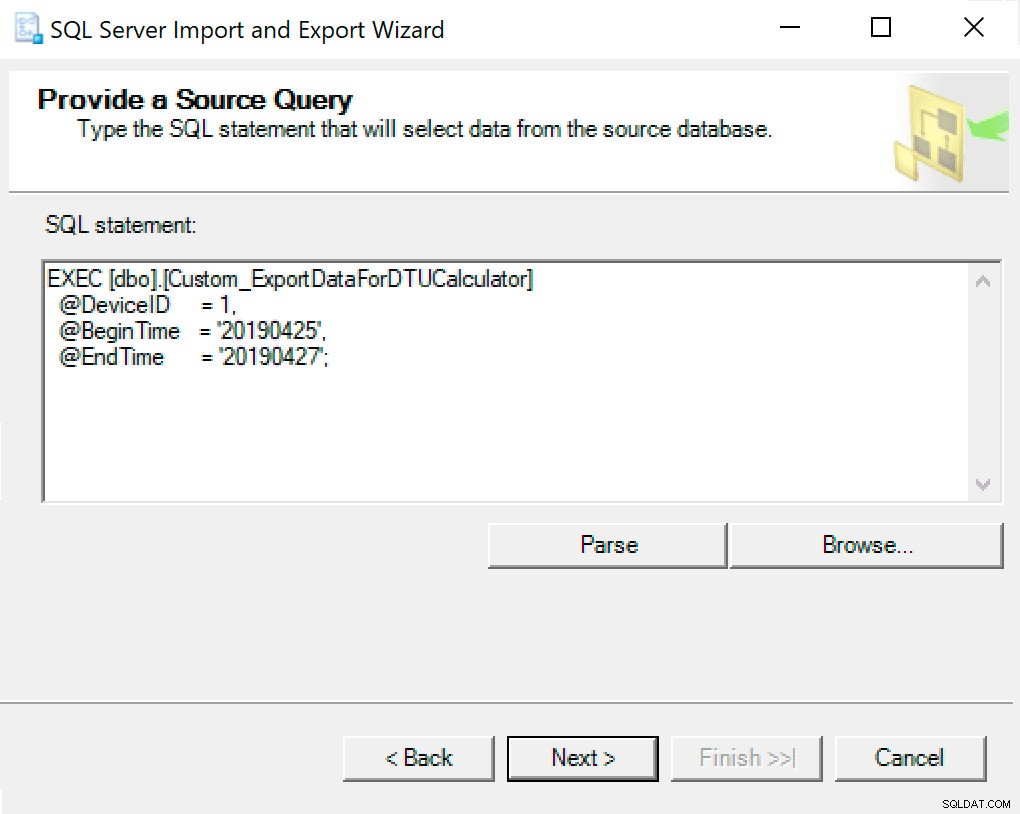
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
データはCSVファイルにエクスポートする必要があります。データ自体について心配する必要はありません。 csvファイルにサーバーに関する識別情報がなく、日付とメトリックのみが含まれるように、結果を出力するようにしました。
SSMSでクエリを実行する場合は、右クリックして結果をエクスポートできます。ただし、ここではオプションが限られているため、DTU計算機で期待される形式を取得するには、出力を操作する必要があります。 (これを行う方法を見つけたら、遠慮なく試して、私に知らせてください。)
SSMSに組み込まれたエクスポートウィザードを使用することをお勧めします。データベースを右クリックして、[タスク]->[データのエクスポート]に移動します。データソースには「SQLServerNativeClient」を使用し、SentryOneデータベース(またはデータのコピーが保存されている場所)をポイントします。宛先には、「フラットファイル宛先」を選択する必要があります。場所を参照し、ファイルに名前を付けて、ファイルをCSVとして保存します。
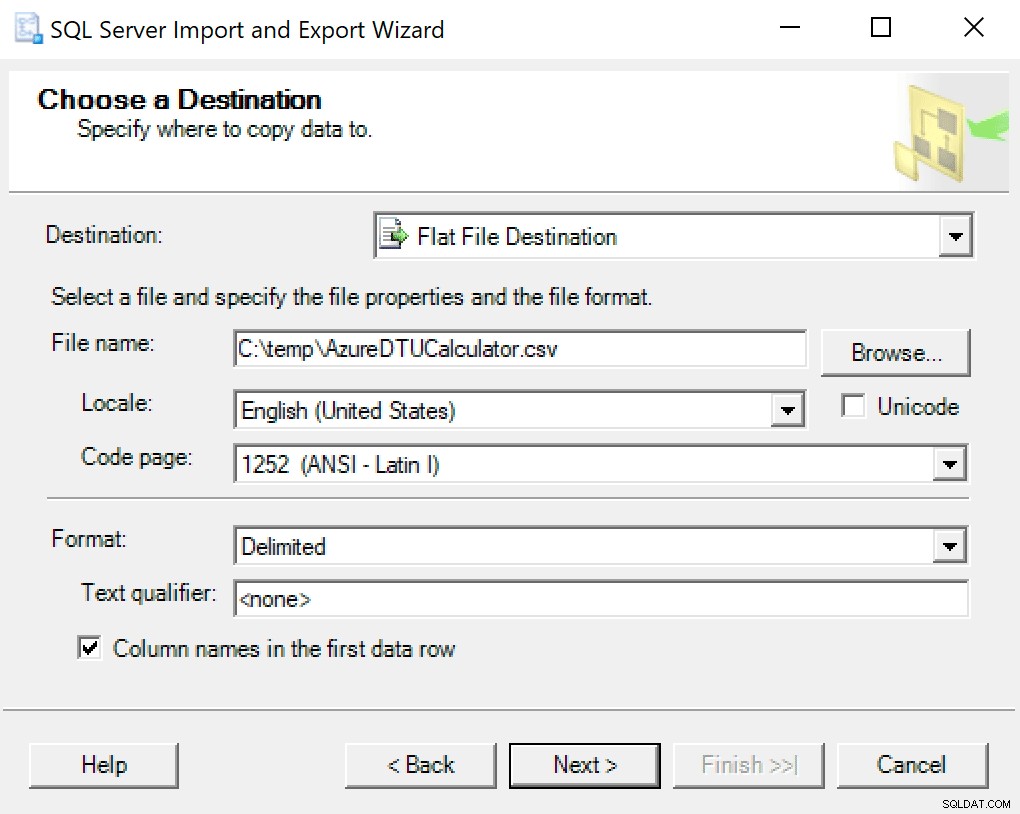
コードページはそのままにしておくように注意してください。エラーを返すものもあります。私は1252がうまく機能することを知っています。残りの値はデフォルトのままです。
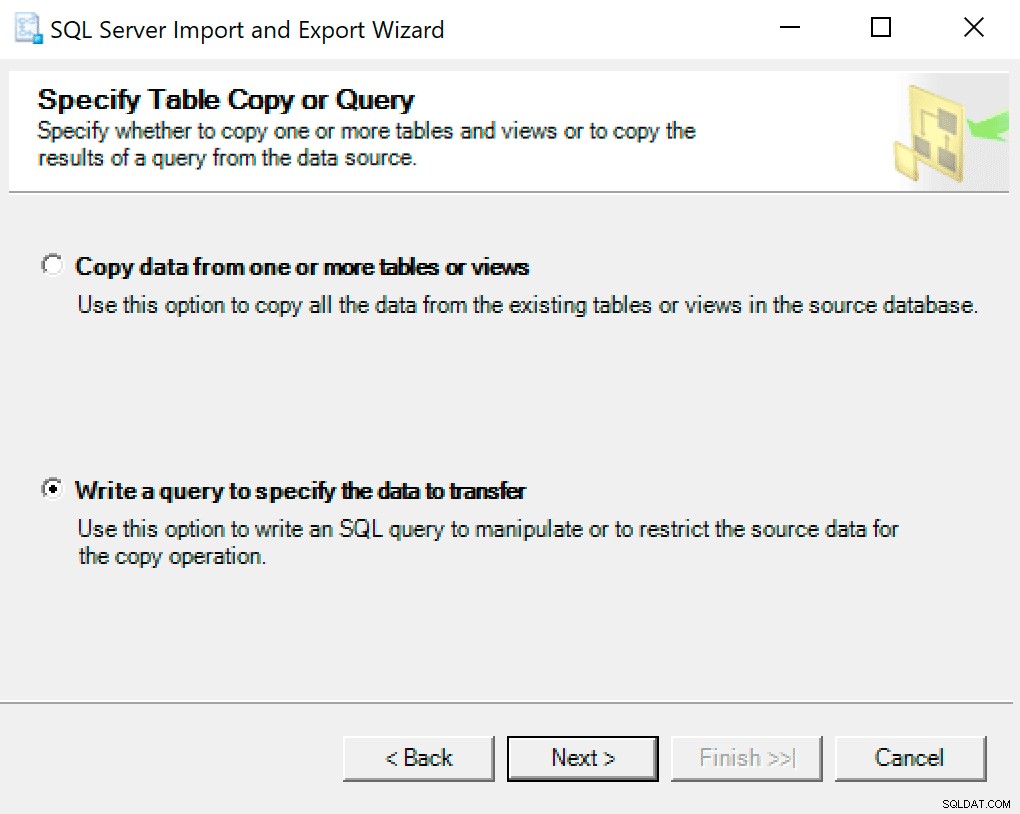
次の画面で、オプション転送するデータを指定するクエリを作成を選択します 。
次のウィンドウで、パラメータを設定したプロシージャ呼び出しをコピーします。次を押してください。
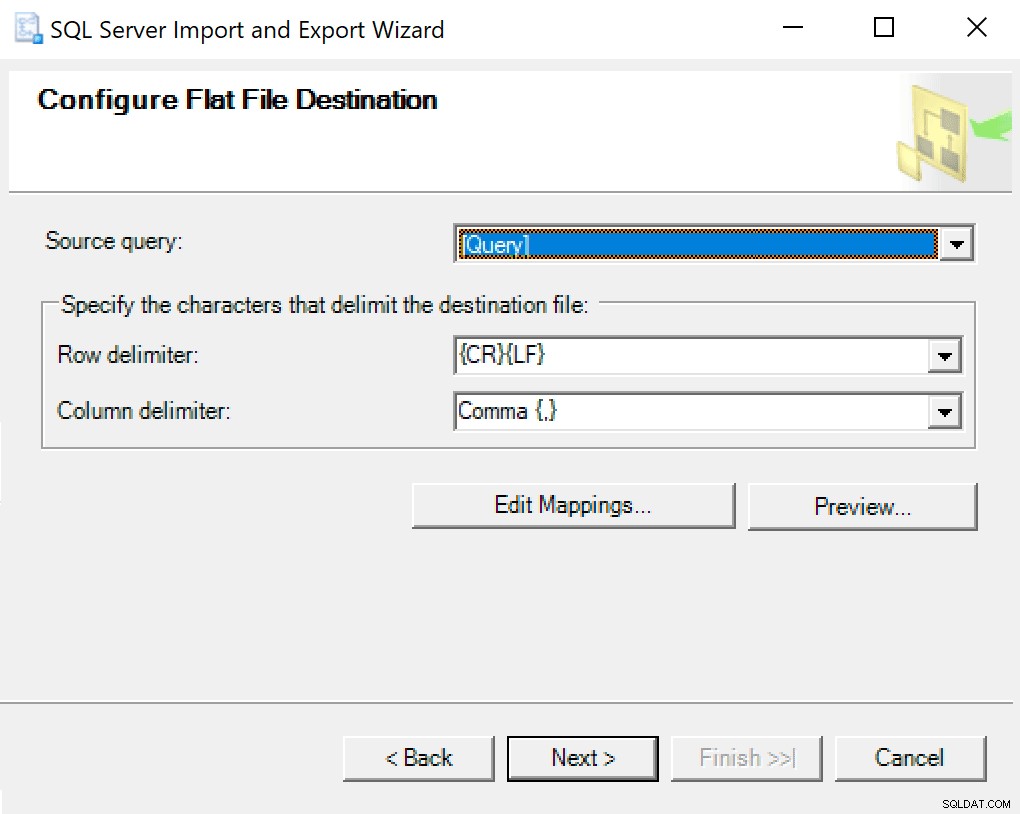
Flat File Destinationの構成に到達したら、オプションをデフォルトのままにします。これがあなたのものが異なる場合のスクリーンショットです:
次にヒットしてすぐに実行します。最後のステップで使用するファイルが作成されます。
注 :これに使用するSSISパッケージを作成し、これを頻繁に行う場合は、パラメーター値をSSISパッケージに渡すことができます。これにより、毎回ウィザードを実行する必要がなくなります。
ファイルを保存した場所に移動し、そこにあることを確認します。開くと、次のようになります。
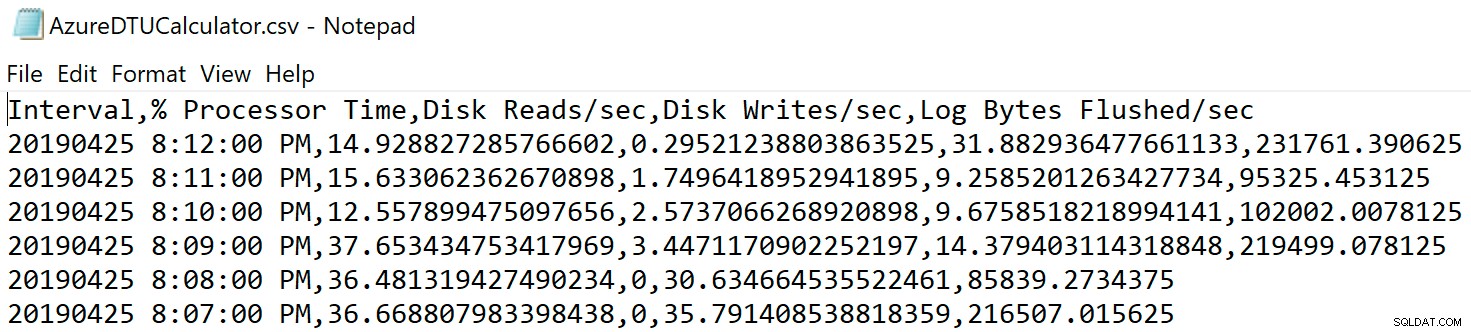
DTU計算機のWebサイトを開き、「CSVファイルをアップロードして計算する」という部分まで下にスクロールします。サーバーにあるコアの数を入力し、CSVファイルをアップロードして、[計算]をクリックします。次のような一連の結果が表示されます(画像をクリックしてズームします):
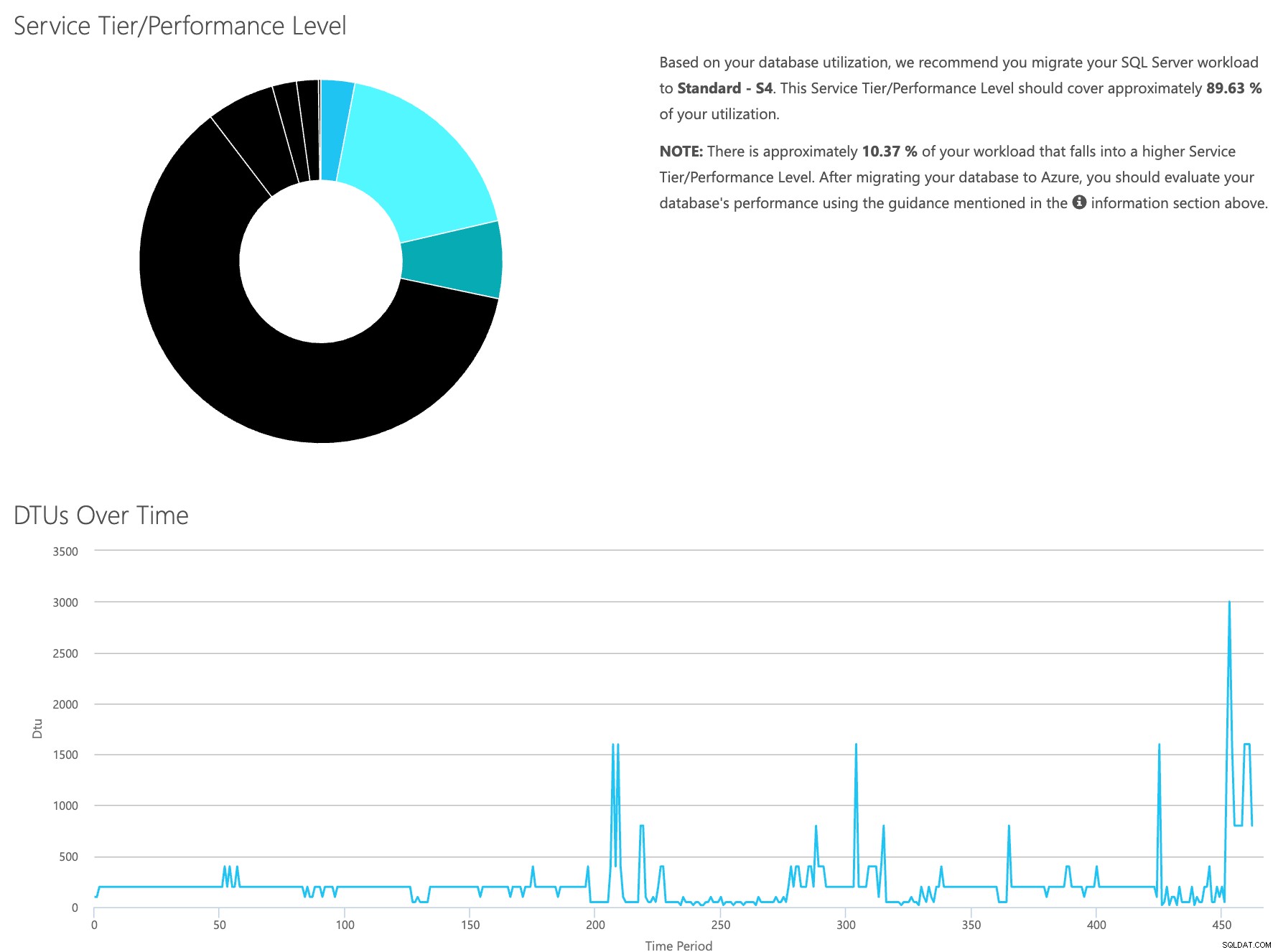
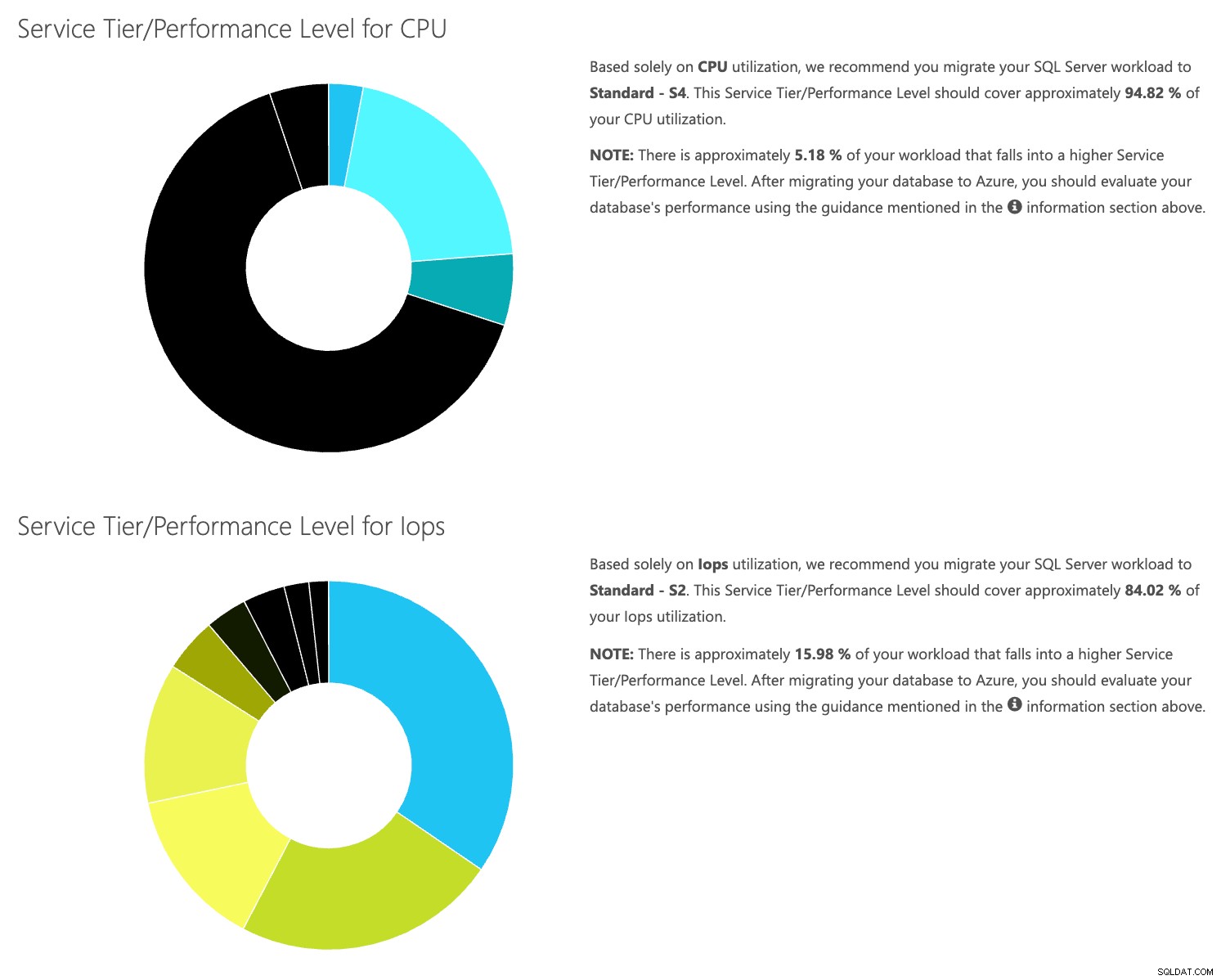
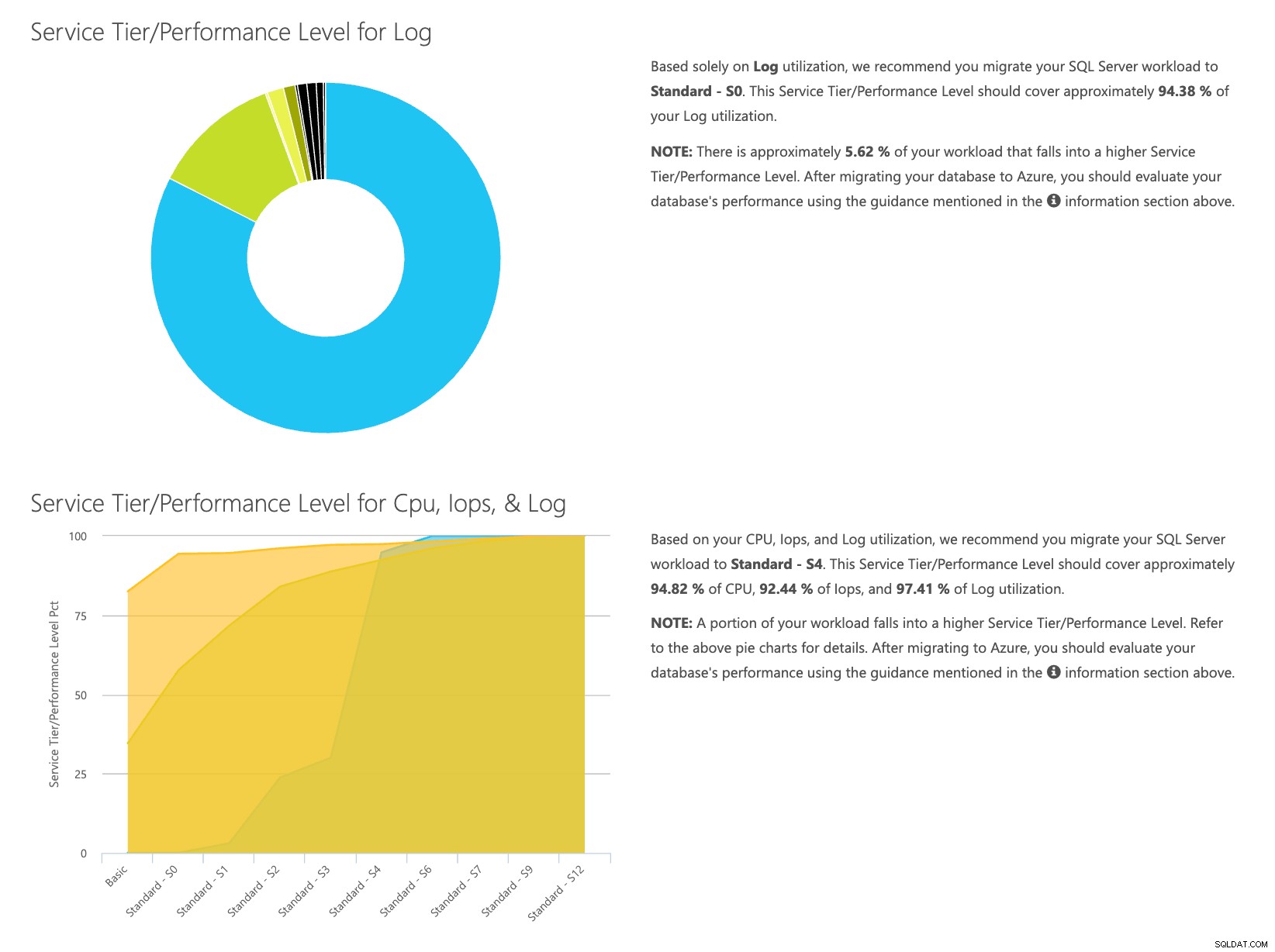
データは個別に保存されているため、さまざまな時点のワークロードを分析できます。これは、SentryOneを使用して監視しているサーバーに対してコマンドutility\powershellスクリプトを手動で実行/スケジュールする必要がありません。
手順を簡単に要約すると、次の手順を実行する必要があります。
- [Database – Log Bytes Flushed / sec]カウンターを有効にして、データが収集されていることを確認します
- SentryOneテーブルから独自のテーブルにデータをコピーします(必要に応じてスケジュールします)。
- DTU計算機に適した形式で新しいテーブルからデータをエクスポートします
- CSVをDTU計算機にアップロードする
クラウドへの移行を検討していて、現在SQL Sentryで監視しているサーバー/インスタンスの場合、これは、必要なサービス層のタイプとコストの両方を見積もる比較的簡単な方法です。ただし、そこに到達したら、監視する必要があります。そのためには、SentryOneDBSentryをチェックしてください。
作者について
 ダスティンドーシーは現在、LifePoint Healthのマネージングデータベースエンジニアであり、ソリューションの管理とエンジニアリングを担当するチームを率いています。 90の病院のデータベース技術で。彼は、2008年以来、管理、アーキテクチャ、開発、およびBIの機能において、主にヘルスケアでSQL Serverを使用し、サポートしてきました。彼は日常のDBAを悩ませている問題を解決する方法を見つけることに情熱を注いでおり、これを他の人と共有するのが大好きです。彼はSQLコミュニティイベントで講演しているほか、DustinDorsey.comでブログを書いています。
ダスティンドーシーは現在、LifePoint Healthのマネージングデータベースエンジニアであり、ソリューションの管理とエンジニアリングを担当するチームを率いています。 90の病院のデータベース技術で。彼は、2008年以来、管理、アーキテクチャ、開発、およびBIの機能において、主にヘルスケアでSQL Serverを使用し、サポートしてきました。彼は日常のDBAを悩ませている問題を解決する方法を見つけることに情熱を注いでおり、これを他の人と共有するのが大好きです。彼はSQLコミュニティイベントで講演しているほか、DustinDorsey.comでブログを書いています。