高可用性システムとタイトなSLAに対する需要の高まりにより、手動の手順を自動化されたソリューションに置き換える必要があります。しかし、フェイルオーバー操作の複雑さに自分で対処するための時間と必要なリソースはありますか?本番データベースのダウンタイムを犠牲にして、難しい方法を学びますか?
ClusterControlは、障害の検出と処理の高度なサポートを提供します。多くの企業組織で使用されており、最も重要な本番システムを24時間年中無休で稼働させています。
このデータベース管理ソリューションは、さまざまなロードプロキシの展開もサポートします。これらのプロキシはHAスタックで重要な役割を果たすため、アプリケーション接続を新しいマスターノードにリダイレクトするためにアプリケーション接続文字列やDNSエントリを調整する必要はありません。
障害が検出されると、ClusterControlはすべてのバックグラウンド作業を実行して、新しいマスターを選択し、フェールオーバースレーブサーバーを展開し、ロードバランサーを構成します。このブログでは、実稼働システムでTimescaleDBの自動フェイルオーバーを実現する方法を学習します。
レプリケーショントポロジ全体の展開
ClusterControl 1.7.2以降、PostgreSQLをデプロイするのと同じ方法でTimescaleDBレプリケーションセットアップ全体をデプロイできます。「DeployCluster」メニューを使用して、プライマリサーバーと1つ以上のTimescaleDBスタンバイサーバーをデプロイできます。それがどのように見えるか見てみましょう。
まず、ClusterControlを使用して新しいクラスターをデプロイするときに、アクセスの詳細を定義する必要があります。新しいクラスターがデプロイされるすべてのノードへのrootまたはsudoパスワードアクセスが必要です。
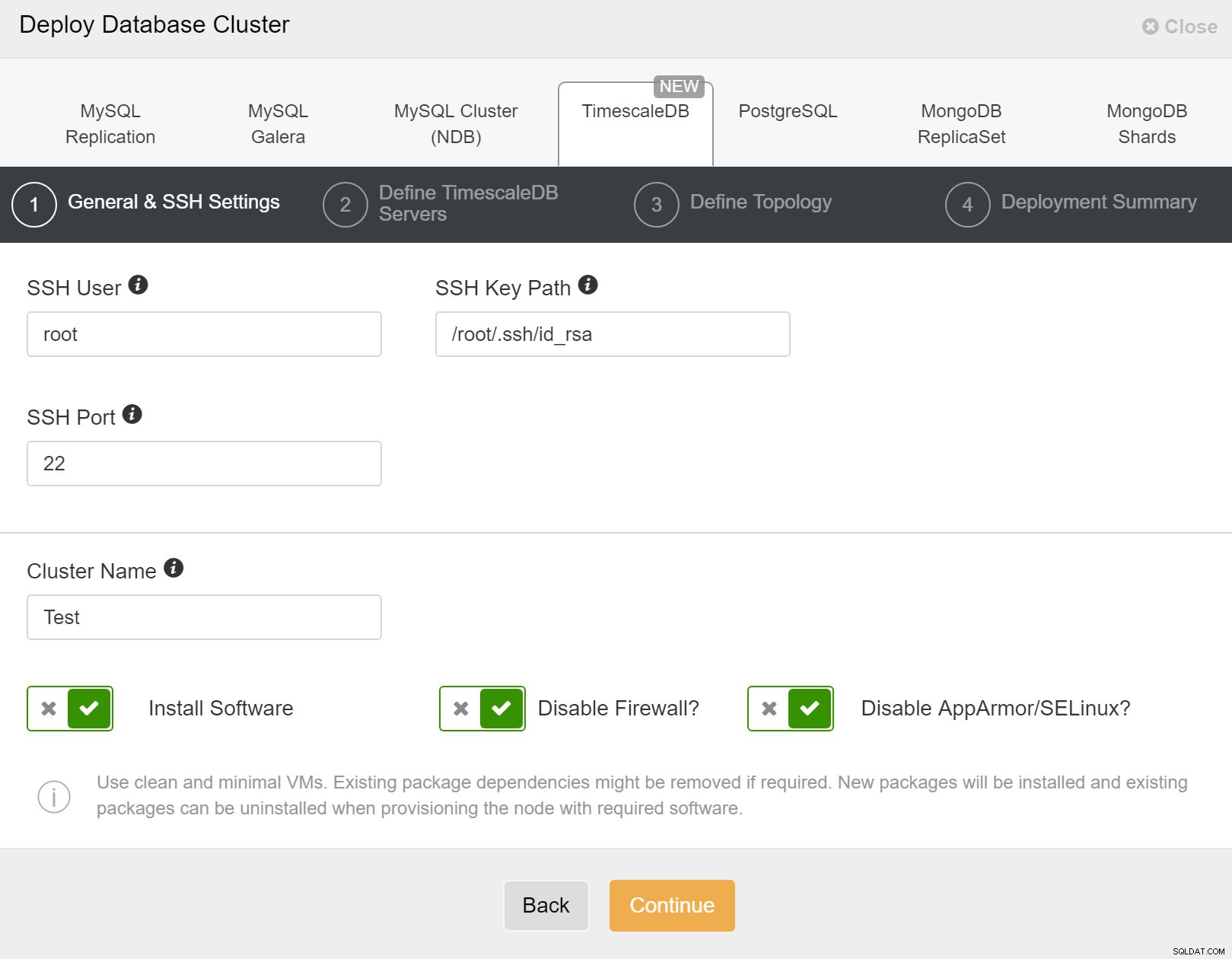 ClusterControl:新しいクラスターをデプロイします
ClusterControl:新しいクラスターをデプロイします 次に、TimescaleDBユーザーのユーザーとパスワードを定義する必要があります。
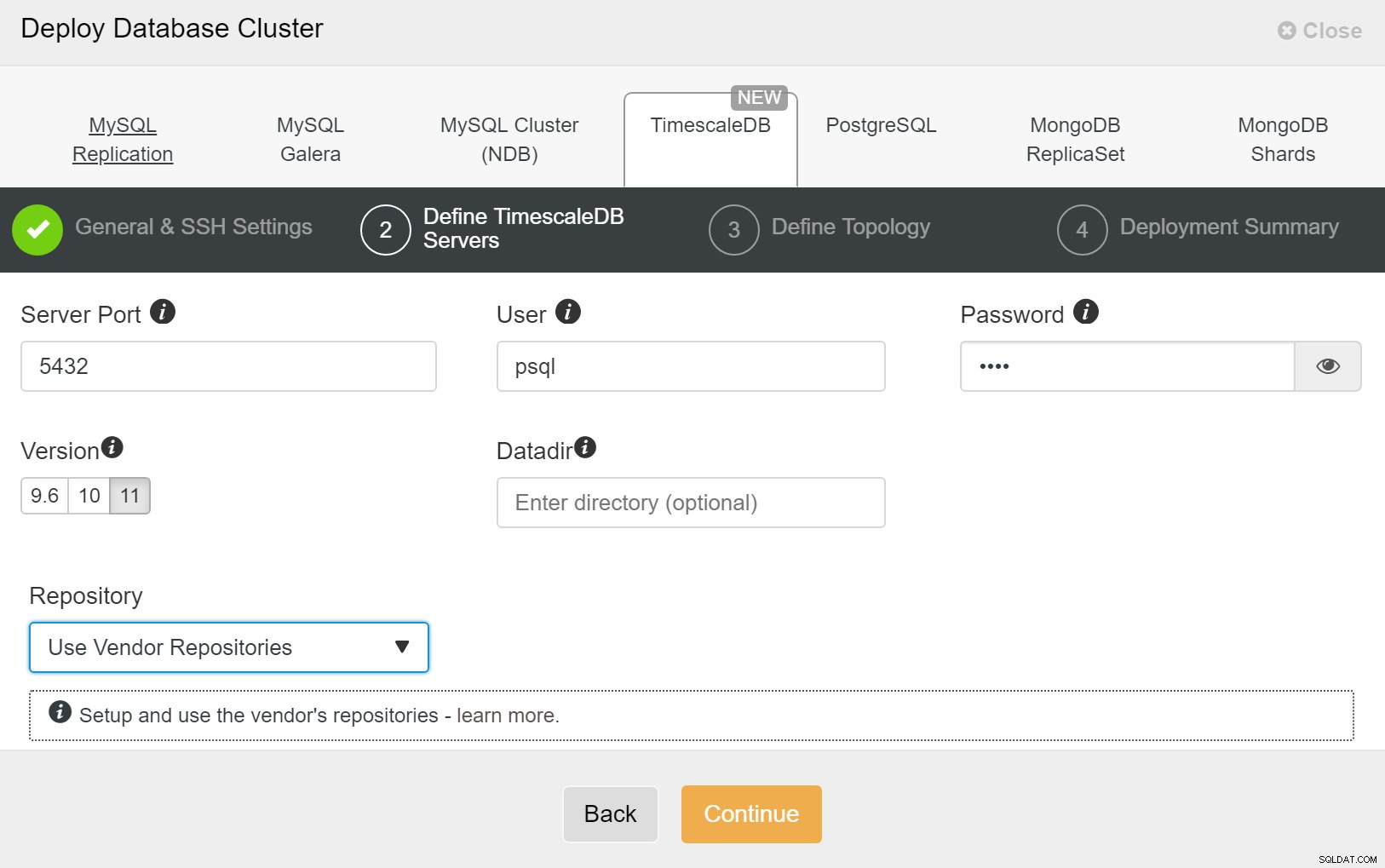 ClusterControl:データベースクラスターをデプロイします
ClusterControl:データベースクラスターをデプロイします 最後に、トポロジを定義する必要があります。どのホストをプライマリにし、どのホストをスタンバイとして構成する必要があります。トポロジでホストを定義している間、ClusterControlはsshアクセスが期待どおりに機能するかどうかを確認します。これにより、接続の問題を早期に発見できます。最後の画面で、同期または非同期のレプリケーションのタイプについて尋ねられます。
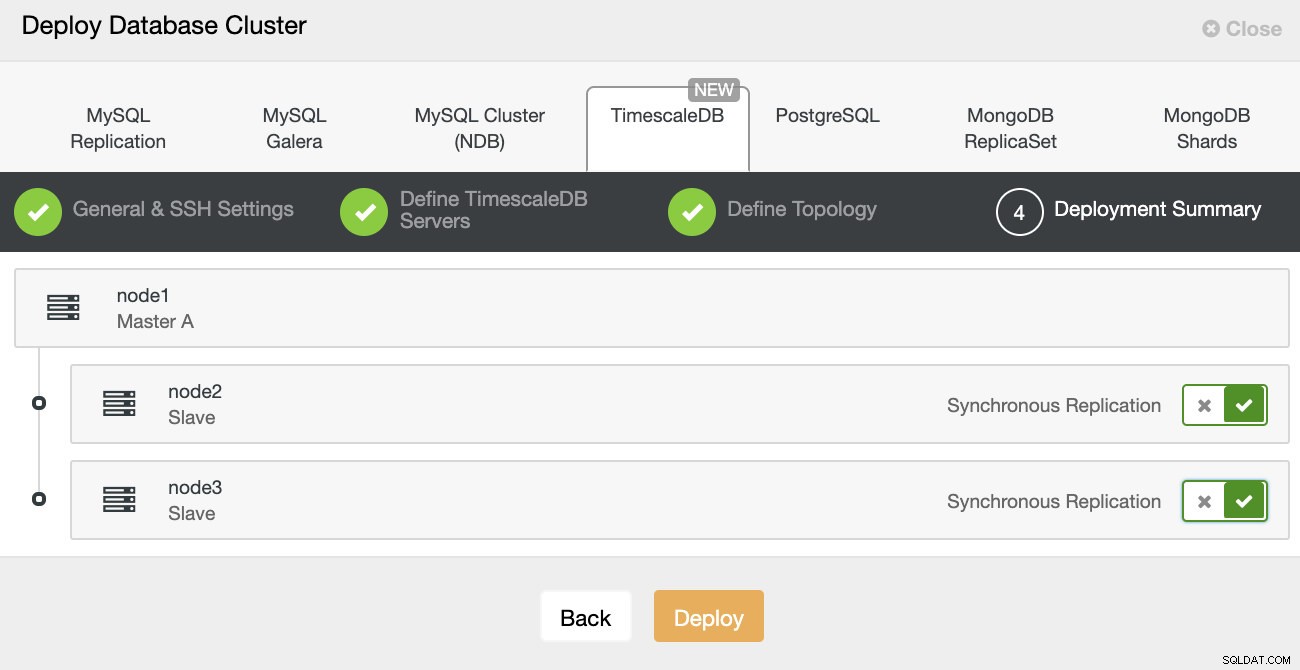 ClusterControlの展開
ClusterControlの展開 それだけです。それでは、展開を開始する必要があります。 ClusterControlでジョブが作成され、進行状況を追跡できるようになります。
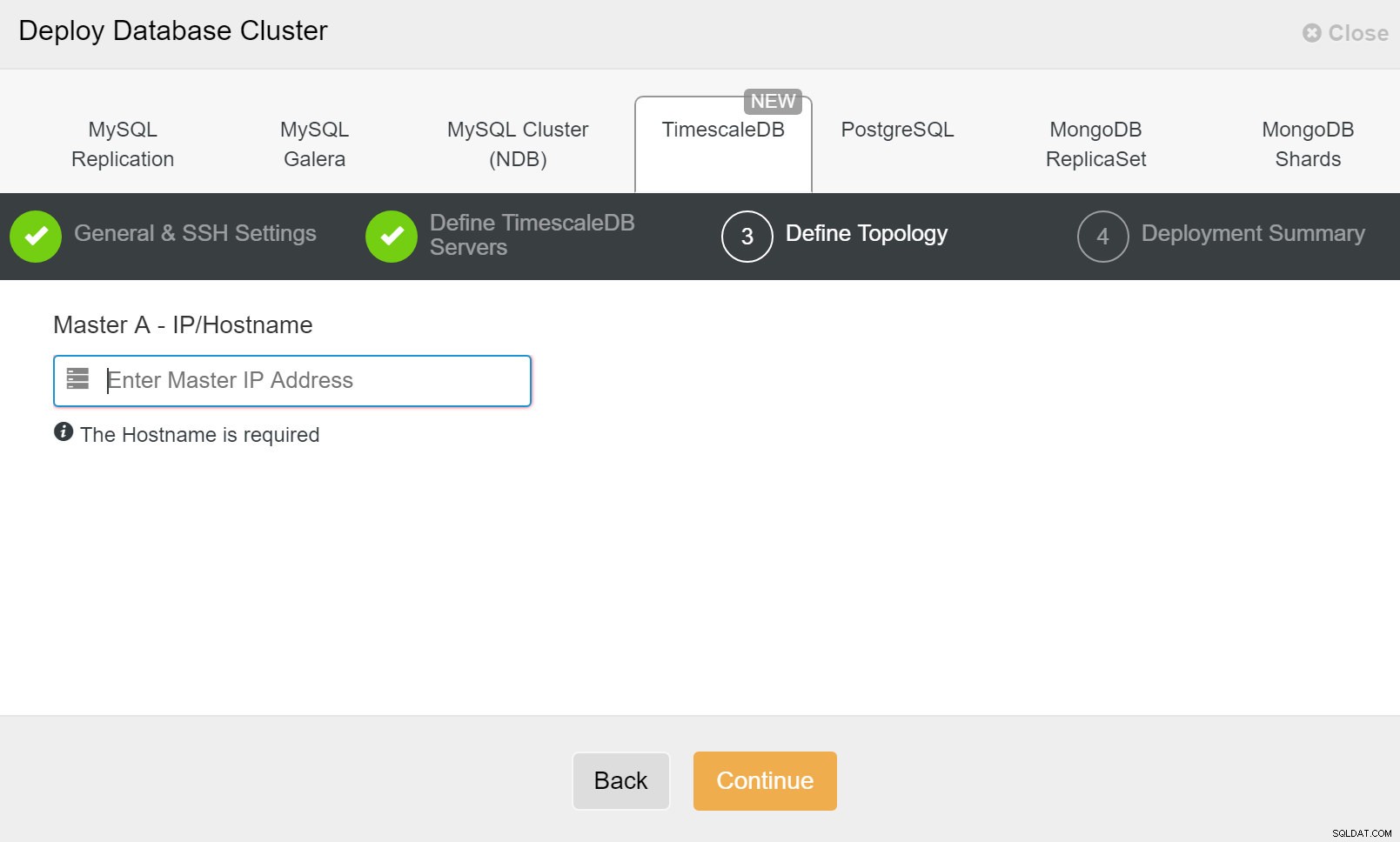 ClusterControl:TimescleDbクラスターのトポロジを定義します
ClusterControl:TimescleDbクラスターのトポロジを定義します 完了すると、クラスター内の役割を使用したトポロジーのセットアップが表示されます。また、データベースインスタンスの前にロードバランサー(HAProxy)を追加したため、自動フェイルオーバーでデータベース接続設定を変更する必要がないことに注意してください。
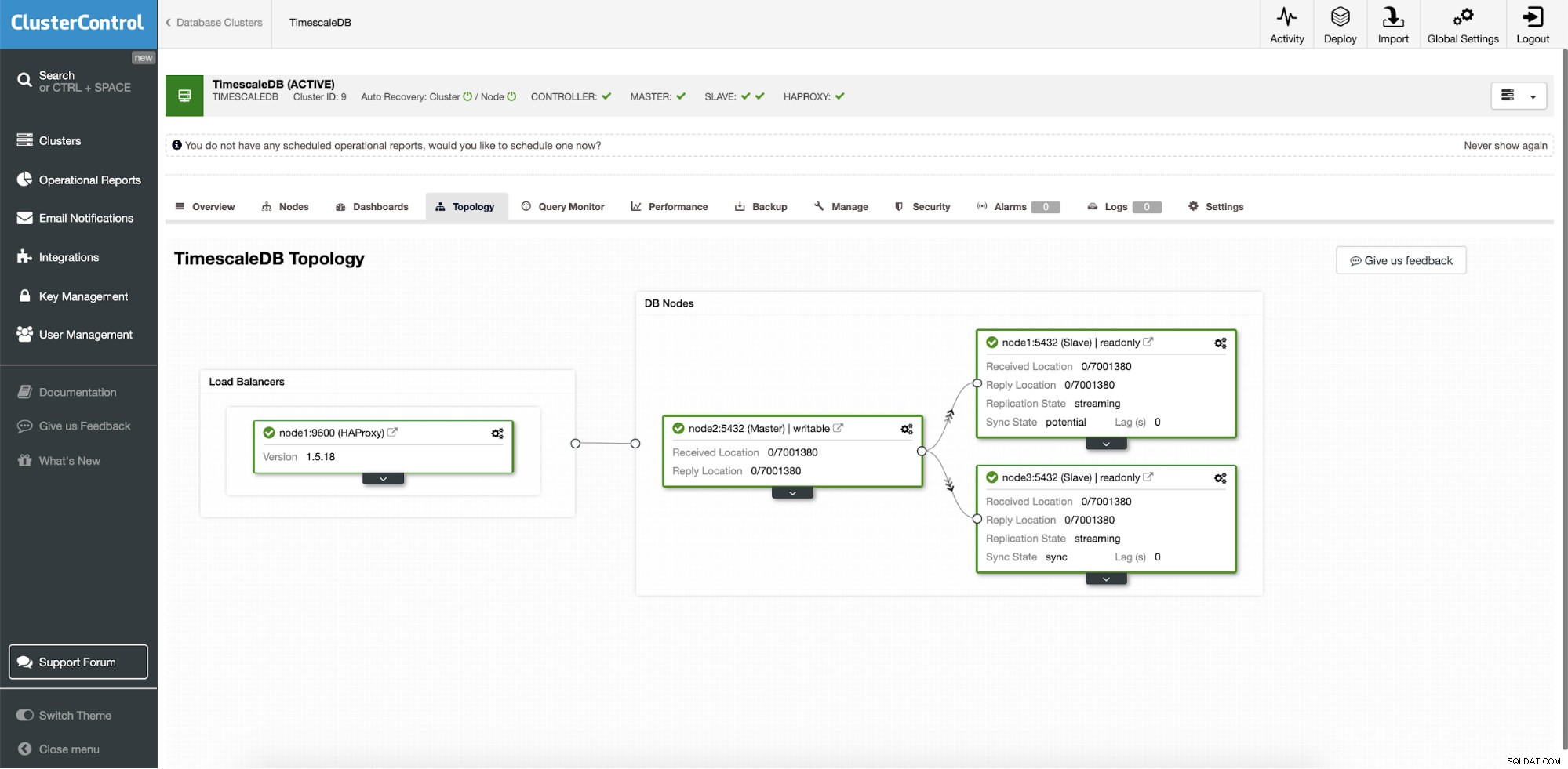 ClusterControl:トポロジ
ClusterControl:トポロジ ClusterControlによってTimescaleがデプロイされると、自動リカバリがデフォルトで有効になります。状態はクラスターバーで確認できます。
 ClusterControl:自動回復クラスターとノードの状態
ClusterControl:自動回復クラスターとノードの状態 フェイルオーバー構成
レプリケーションセットアップがデプロイされると、ClusterControlはセットアップを監視し、障害が発生したサーバーを自動的に回復できます。また、トポロジの変更を調整することもできます。
ClusterControlの自動フェイルオーバーは、次の原則に基づいて設計されました。
- フェイルオーバーする前に、マスターが本当に死んでいることを確認してください
- フェイルオーバーは1回のみ
- 一貫性のないスレーブにフェイルオーバーしないでください
- マスターにのみ書き込む
- 障害が発生したマスターを自動的に回復しないでください
組み込みのアルゴリズムを使用すると、多くの場合、フェイルオーバーを非常に迅速に実行できるため、データベース環境で最高のSLAを保証できます。
プロセスは構成可能です。環境の詳細にリカバリを採用するために使用できる複数のパラメータが付属しています。
| max_replication_lag | 最大許容レプリケーションラグ(秒単位) |
| replication_stop_on_error | データ損失を引き起こす可能性のあるエラーが発生した場合、フェイルオーバー/スイッチオーバー手順は失敗します。デフォルトで有効になっています。 0は無効を意味します |
| replication_auto_rebuild_slave | SQL THREADが停止し、エラーコードがゼロ以外の場合、スレーブは自動的に再構築されます。 1は有効、0は無効(デフォルト)を意味します。 |
| Replication_failover_blacklist | ホスト名:ポートのペアのコンマ区切りリスト。ブラックリストに登録されたサーバーは、フェイルオーバー中の候補とは見なされません。 Replication_failover_whitelistが設定されている場合、replication_failover_blacklistは無視されます。 |
| Replication_failover_whitelist | ホスト名:ポートのペアのコンマ区切りリスト。ホワイトリストに登録されたサーバーのみがフェイルオーバー中の候補と見なされます。ホワイトリストにあるサーバーが利用できない(稼働中/接続されていない)場合、フェイルオーバーは失敗します。 Replication_failover_whitelistが設定されている場合、replication_failover_blacklistは無視されます。 |
フェイルオーバー処理
マスターの障害が検出されると、マスター候補のリストが作成され、そのうちの1つが新しいマスターとして選択されます。プライマリに昇格するサーバーのホワイトリストと、プライマリに昇格できないサーバーのブラックリストを作成することができます。残りのスレーブは新しいプライマリからスレーブ化され、古いプライマリは再起動されません。
以下に、ノード障害のシミュレーションを示します。
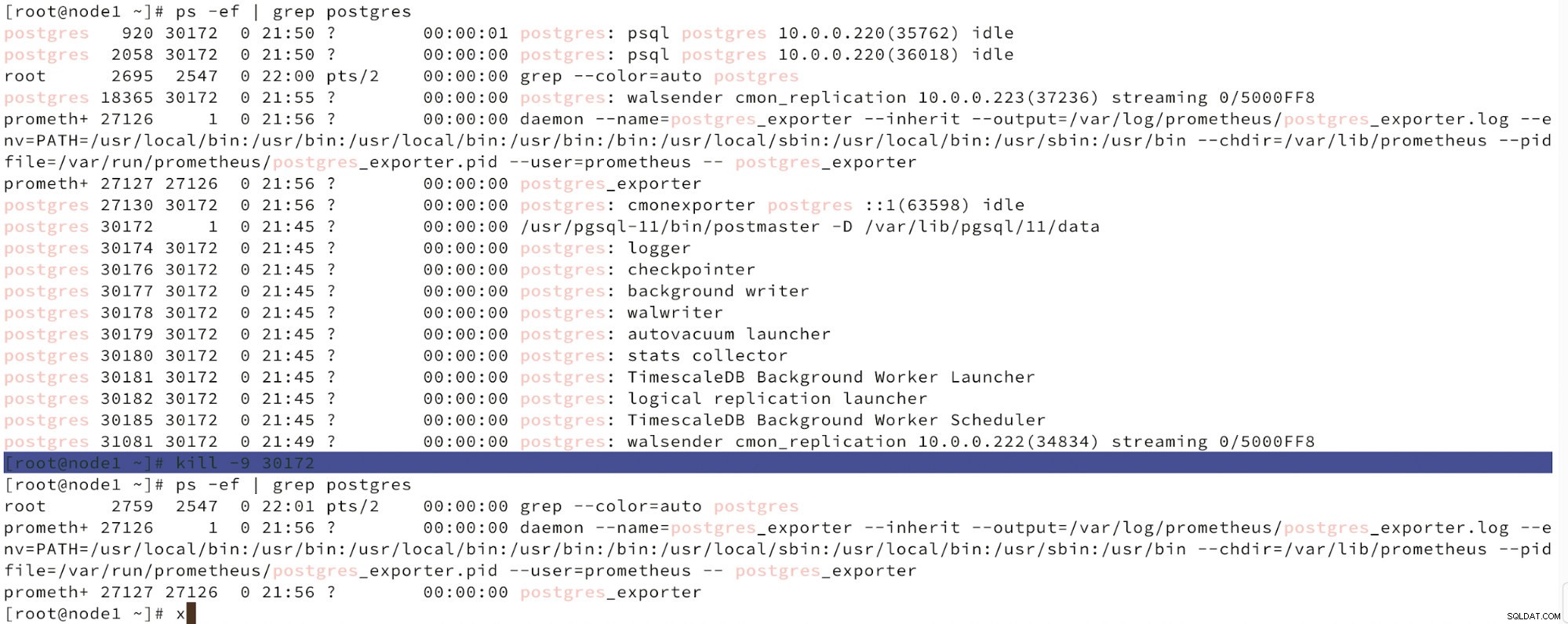 killを使用してマスターノードの障害をシミュレートする
killを使用してマスターノードの障害をシミュレートする ノードの誤動作が検出され、自動回復が検出されると、ClusterControlはフェイルオーバーを実行するジョブをトリガーします。以下に、クラスターを回復するために実行されたアクションを示します。
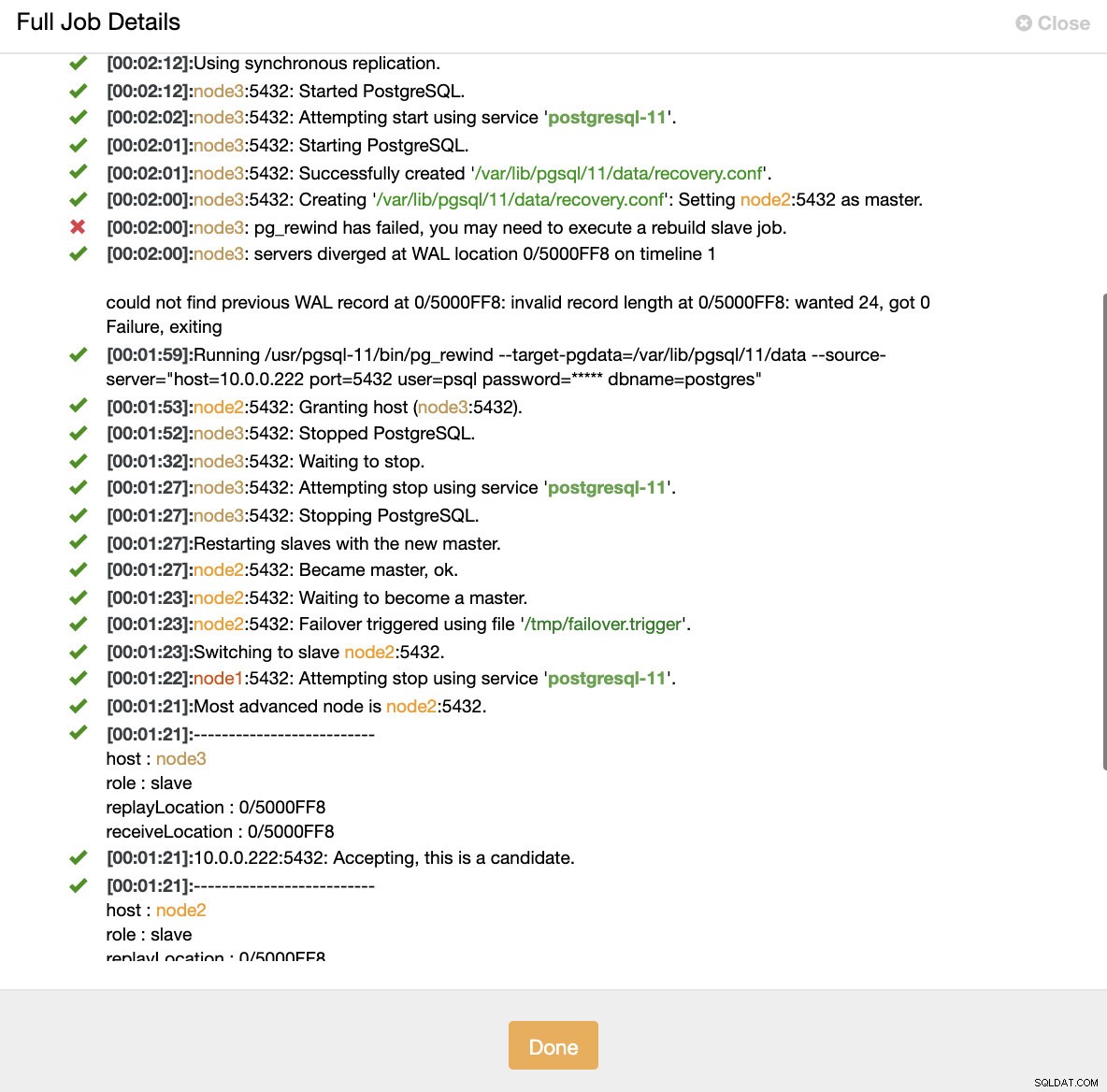 ClusterControl:クラスターを再構築するためにトリガーされたジョブ
ClusterControl:クラスターを再構築するためにトリガーされたジョブ 一部のデータがスタンバイ・サーバーに転送されていない可能性があるため、ClusterControlは意図的に古いプライマリーをオフラインに保ちます。このような場合、プライマリがこのデータを含む唯一のホストであり、不足しているデータを手動で回復することをお勧めします。失敗したプライマリを自動的に再構築したい場合は、cmon構成ファイルにreplication_auto_rebuild_slaveというオプションがあります。デフォルトでは無効になっていますが、ユーザーが有効にすると、障害が発生したプライマリが新しいプライマリのスレーブとして再構築されます。もちろん、障害が発生したプライマリにのみ存在する不足しているデータがある場合、そのデータは失われます。
スタンバイサーバーの再構築
別の機能は、レプリケーションセットアップのすべてのスレーブ(またはスタンバイサーバー)で使用できる「レプリケーションスレーブの再構築」ジョブです。これは、たとえば、スタンバイ上のデータをクリアして、プライマリのデータの新しいコピーを使用して再構築する場合に使用されます。スタンバイサーバーが何らかの理由でプライマリから接続および複製できない場合に役立ちます。
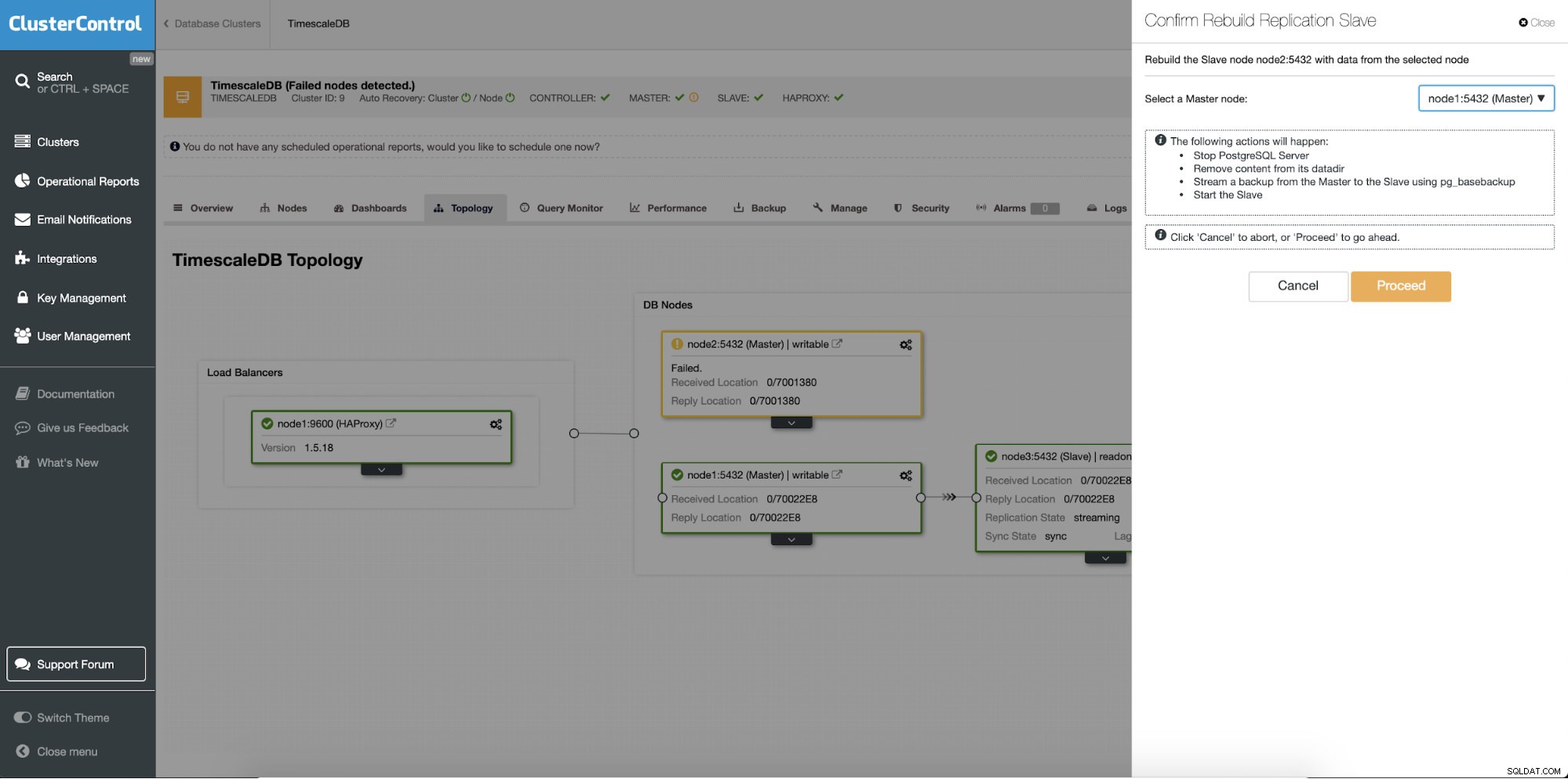 ClusterControl:レプリケーションスレーブを再構築します
ClusterControl:レプリケーションスレーブを再構築します  ClusterControl:スレーブを再構築します
ClusterControl:スレーブを再構築します