SQL Server 2012では、グループ化された(ベクトル)集約は並列バッチモード実行を使用できましたが、部分的な(スレッドごとの)集約に対してのみでした。関連するグローバルアグリゲートは、パーティションストリームの後、常に行モードで実行されていました。 交換。
SQL Server 2014では、単一のハッシュ一致集計内で並列バッチモードのグループ化された集計を実行する機能が追加されました。 オペレーター。これにより、不要な行モード処理が排除され、交換の必要がなくなりました。
SQL Server 2016では、シリアルバッチモード処理と集約プッシュダウンが導入されました 。プッシュダウンが成功すると、列ストアスキャン内で集計が実行されます。 オペレーター自体、おそらく圧縮データを直接操作し、SIMDCPU命令を利用します。
集約プッシュダウンで可能なパフォーマンスの向上は、非常に大きくなる可能性があります。ドキュメントには、プッシュダウンを実現するために必要な条件の一部がリストされていますが、「ローカルに集約された行」の欠如は、それらの詳細だけでは完全に説明できない場合があります。
この記事では、GROUP BYの集計プッシュダウンに影響を与える追加の要因について説明します。 クエリのみ 。 スカラー骨材プッシュダウン (GROUP BYのない集計 句)、フィルタープッシュダウン、および式プッシュダウンについては、今後の投稿で取り上げる可能性があります。
最初に言うことは、集約プッシュダウンは圧縮データにのみ適用されるため、デルタストアの行は 対象外です。それを超えて、プッシュダウンは使用される圧縮のタイプに依存する可能性があります。これを理解するには、最初に列ストアストレージがどのように機能するかを高レベルで確認する必要があります。
圧縮された行グループ 列セグメントが含まれています 各列に対して。生の列の値はエンコードされます valueを使用して4バイトまたは8バイトの整数で または辞書 エンコーディング。
値のエンコード ベースオフセットおよびマグニチュード修飾子を使用して生の値を変換することにより、ストレージに必要なビット数を減らすことができます。たとえば、値{1100、1200、1300}は、最初に0.01の係数でスケーリングして{11、12、13}を生成し、次に11でリベースして{0、 1、2}。
辞書エンコーディング 値が重複している場合に使用されます。数値以外のデータで使用できます。それぞれの一意の値はディクショナリに格納され、整数IDが割り当てられます。セグメントデータは、元の値ではなく、ディクショナリ内のID番号を参照します。
エンコード後、セグメントデータはランレングスエンコード(RLE)とビットパッキングを使用してさらに圧縮できます:
RLE 繰り返し要素をデータに置き換え、繰り返し回数を置き換えます。たとえば、{1、1、1、1、1、2、2、2}は{5×1、3×2}に置き換えることができます。 RLEスペースの節約は、繰り返し実行の長さとともに増加します。短期間の実行は逆効果になる可能性があります。
ビットパッキング データのバイナリ形式を可能な限り狭い共通ウィンドウに格納します。たとえば、数値{7、9、15}は、バイナリ(スペースの場合はシングルバイト)整数で{00000111、00001001、00001111}として格納されます。これらのビットを固定の4ビットウィンドウにパックすると、ストリーム{011110011111}が得られます。ウィンドウサイズが固定されていることを知っているということは、区切り文字が必要ないことを意味します。
エンコードと圧縮は別々のステップであるため、RLEとビットパッキングは、生データの値エンコードまたは辞書エンコードの結果に適用されます。さらに、同じ列セグメント内のデータには混合を含めることができます RLEとビットパッキング圧縮の。 RLE圧縮されたデータは純粋と呼ばれます 、ビットパックされた圧縮データは不純と呼ばれます 。列セグメントには、純粋なデータと不純なデータの両方が含まれる場合があります。
エンコードと圧縮によって達成できるスペースの節約は、順序に依存する場合があります。 SQL Serverが列セグメントから完全な行を効率的に再構築できるように、行グループ内のすべての列セグメントは、同じ方法で暗黙的にソートする必要があります。行123が各列セグメントの同じ位置(123)に格納されていることを知っているということは、行番号を格納する必要がないことを意味します。
この配置の欠点の1つは、一般的な並べ替え順序 行グループのすべての列セグメントに対して選択する必要があります。特定の順序は1つの列に非常に適している場合がありますが、他の列の重要な機会を逃します。これは、RLE圧縮の場合に最も明確に当てはまります。 SQL Serverは、Vertipaqテクノロジを使用して、各行グループの列を並べ替える適切な方法を決定し、全体的に適切な圧縮結果を提供します。
SQL Serverは現在、 RLEのみを使用しています 最小64がある場合の列セグメント内 連続する繰り返し値。セグメントの残りの値はビットパックされています。前述のように、繰り返し値が列セグメントで連続して表示されるかどうかは、行グループに選択された順序によって異なります。
SQL Serverは、特殊な SIMDをサポートしています 1〜10ビット幅、12ビット、および21ビットのビットアンパッキング。 SQL Serverは、標準の整数サイズを使用することもできます。ビットパッキングを使用した16、32、および64ビット。これらの数値は、うまく収まるために選択されています。 64ビット単位で。たとえば、1つのユニットに3つの21ビットサブユニットまたは5つの12ビットサブユニットを保持できます。 SQLServerはしません ビットをパックするときに64ビットの境界を越えます。
SIMDは、プロセッサがAVX2命令をサポートしている場合は256ビットレジスタを使用し、SSE4.2命令が使用可能な場合は128ビットレジスタを使用します。それ以外の場合は、SIMD以外のアンパッキングを使用できます。
ハッシュマッチアグリゲートを使用するほとんどのプラン 列ストアスキャンのすぐ上の演算子 オペレーターは、ドキュメントに記載されている一般的な条件に従って、グループ化された集約プッシュダウンの対象となる可能性があります。
グループ化された集約プッシュダウンを妨げずに、追加のフィルターと式を追加できる場合もあります。一般的な規則として、フィルターまたは式はプッシュダウンも可能である必要があります(ただし、互換性のある式は別の Compute Scalarに表示される場合があります。 )。冒頭で述べたように、これらの側面については別の記事で詳しく説明されている場合があります。
現在、実行計画には、特定の集計が一般的に互換性があると見なされたかどうかを示すものはありません。 グループ化された集約プッシュダウンの有無。それでも、プランが一般的に適格である グループ化された集約プッシュダウンの場合、プッシュダウン(高速)と非プッシュダウン(低速)の両方のコードパスが使用可能になります。
各スキャン出力バッチ(最大900行)は、実行時の決定を行います。 高速コードパスと低速コードパスの間。この柔軟性により、できるだけ多くのバッチがプッシュダウンの恩恵を受けることができます。最悪の場合、「一般的に互換性のある」計画にもかかわらず、実行時に高速パスを使用するバッチはありません。
実行プランには、高速パスプッシュダウン処理の結果が「ローカルに集約された行」として表示されます。 スキャンからの対応する行出力はありません。スローパスバッチは、通常どおり列ストアスキャンからの出力行として表示され、スキャンではなく別のオペレーターによって集計が実行されます。
単一のグループ化された集約とスキャンの組み合わせにより、一部のバッチを高速パスに送信し、一部を低速パスに送信できるため、すべてではありませんが、一部の行がローカルに集約されていることを確認できます。グループ化された集計のプッシュダウンが成功すると、スキャンからの各出力バッチには、グループ化キーと、貢献する行を表す部分的な集計が含まれます。
プッシュダウン処理を使用できるかどうかを判断するためのランタイムチェックがいくつかあります。簡単に文書化されたチェックには、次のものがあります。
- 骨材のオーバーフローの可能性があってはなりません 。
- 不純 (ビットパック)グループ化キー 10ビット以下である必要があります 。純粋な(RLEエンコードされた)グループ化キーは、不純な幅がゼロとして扱われるため、通常、これらにはほとんど障害がありません。
- プッシュダウン処理は、引き続き価値があると見なす必要があります 、各出力バッチの最後に更新される「利益測定」を使用します。
集計オーバーフローの可能性 集計のタイプ、結果データタイプ、現在の部分集計値、および入力データに関する情報に基づいて、バッチごとに控えめに評価されます。たとえば、SQL Serverは、DMV sys.column_store_segmentsで公開されているセグメントメタデータの最小値と最大値を認識しています。 。オーバーフローのリスクがある場合、バッチは低速パス処理を使用します。これは主にSUMのリスクです 集計。
不純なグループ化キーの幅の制限 強調する価値があります。 GROUP BYの列にのみ適用されます グループ化の基礎として実行プランで実際に使用される句。最終的なクエリ結果が元のクエリ仕様と一致することが保証されている限り、オプティマイザには冗長なグループ化列を削除したり、集計を書き換えたりする自由があるため、これらのセットは必ずしも完全に同じではありません。格差がある場合、重要なのは実行計画に示されているグループ化列です。
より大きな困難は、グループ化列のいずれかがビットパッキングを使用して格納されているかどうか、および格納されている場合はどの幅が使用されたかを知ることです。 RLEを使用してエンコードされた値の数を知ることも役立ちます。この情報は、column_store_segmentsにある可能性があります DMVですが、今日はそうではありません。私の知る限り、メタデータからビットパッキングとRLE情報を取得するための文書化された方法は今のところありません。そのため、文書化されていない代替案を探す必要があります。
RLEとビットパッキング情報の検索
文書化されていないDBCC CSINDEX 必要な情報を提供してくれます。このコマンドでSSMSメッセージタブに出力を生成するには、トレースフラグ3604をオンにする必要があります。関心のある列セグメントに関する情報が与えられると、このコマンドは次を返します。
- セグメント属性(
column_store_segmentsと同様) ) - RLE情報
- RLEデータへのブックマーク
- ビットパック情報
文書化されていないため、いくつかの癖(クラスター化された列ストアの列IDに1つ追加する必要があるが、クラスター化されていない列ストアには追加しないなど)があり、いくつかの小さなエラーさえあります。個人用テストシステム以外には使用しないでください。うまくいけば、いつの日か、このデータにアクセスするためのサポートされた方法が代わりに提供されるでしょう。
DBCC CSINDEXを表示するための最良の方法 そして、このテキストでこれまでに述べられたポイントがいくつかの例を通して働くことであることを示します。次のスクリプトは、dbo.Numbersというテーブルがあることを前提としています。 1から少なくとも16,384までの整数を含む現在のデータベース内。これは、1000万の整数を使用してこのテーブルの標準バージョンを作成するためのスクリプトです。
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
例はすべて同じ基本的なテストテーブルを使用しています。最初の列c1 各行に一意の番号が含まれています。 2番目の列c2 少数の個別の値ごとに多数の重複が入力されます。
クラスター化された列ストアインデックスは、データの入力後に作成されるため、すべてのテストデータは単一の圧縮された行グループ(デルタストアなし)になります。これは、列c2のbツリークラスター化インデックスを置き換えて構築されます。 VertiPaqアルゴリズムに、その列での並べ替えの有用性を早い段階で検討するように促します。これが基本的なテスト設定です:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
2つの変数は、列c2に挿入する個別の値の数です。 、およびそれらの各値の重複の数。
テストクエリは、非常に単純なグループ化されたCOUNT_BIGです。 列c2を使用した集計 キーとして:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
列ストアのインデックス情報は、DBCC CSINDEXを使用して表示されます 各テストクエリの実行後:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); テストは、執筆時点で入手可能な最新リリースバージョンのSQLServerで実行されました:Microsoft SQL Server 2017 RTM-CU13-ODビルド14.0.3049 Windows 10Pro上のDeveloperEdition(64ビット)。 SQLServer2016の最新ビルドでも問題なく動作するはずです。
テスト1:プッシュダウン、9ビットの不純なキー
このテストでは、上記のテストデータ入力スクリプトを正確に使用して、32,256行のテーブルを作成します。列c1 1から32,256までの数字が含まれています。
列c2 512の異なる値が含まれています 0から511まで。 c2の各値 63回複製 、ただし、c1で表示すると、連続したブロックとして表示されません。 注文;値0から511まで63回循環します。
前述の説明を踏まえると、SQLServerはc2を格納することを期待しています。 使用する列データ:
- 辞書エンコーディング 重複する値がかなりの数あるためです。
- RLEなし 。値ごとの重複の数(63)は、RLEに必要な64のしきい値に達していません。
- ビットパッキングサイズ9 。 512個の異なる辞書エントリは9ビットに正確に収まります(2 ^ 9 =512)。各64ビットユニットには、最大7つの9ビットサブユニットが含まれます。
これはすべて、DBCC CSINDEXを使用して正しいことが確認されます。 クエリ:
セグメント属性 出力のセクションには、辞書エンコーディングが表示されます。 (タイプ2; encodingTypeの値 sys.column_store_segmentsに記載されているとおりです 。
バージョン=1encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 RowCount =32256
RLEセクションにはRLEデータなしが表示されます 、ビットパック領域へのポインタ、および値ゼロの空のエントリのみ:
RLEヘッダー:
ロブタイプ=3RLEアレイカウント(ネイティブユニットの観点から)=2
RLEアレイエントリサイズ=8
RLEデータ:
インデックス=0ビットパック配列インデックス=0カウント=32256
インデックス=1値=0カウント=0
ビットパックデータヘッダー セクションには、ビットパックサイズ9が表示されます 使用された4,608ビットパックユニット:
ビットパックデータヘッダー:
ビットパックエントリサイズ=9ビットパックユニット数=4608ビットパック最小ID=3
ビットパックデータサイズ=36864
ビットパックデータ セクションには、DBCC CSINDEXへの最後の2つのパラメータによって要求された最初の2つのビットパックユニットに格納された値が表示されます。 指図。各64ビットユニットは、それぞれ9ビット(7 x 9 =63ビット)の7つのサブユニット(0〜6の番号)を保持できることを思い出してください。 4,608ユニットは全体で4,608*7 =32,256行を保持します:
ユニット0サブユニット0=383
ユニット0サブユニット1=255
ユニット0サブユニット2=127
ユニット0サブユニット3=510
ユニット0サブユニット4=381
ユニット0サブユニット5=253
ユニット0サブユニット6=125
ユニット1サブユニット0=508
ユニット1サブユニット1=379
ユニット1サブユニット2=251
ユニット1サブユニット3=123
ユニット1サブユニット4=506
ユニット1サブユニット5=377
ユニット1サブユニット6=249
グループ化キーはビットパッキングを使用するため サイズが10以下の場合 、グループ化された集約プッシュダウン ここで働くために。実際、実行プランは、すべての行が Columnstore Index Scanでローカルに集約されたことを示しています。 演算子:

プランxmlにはActualLocallyAggregatedRows="32256"が含まれています インデックススキャンの実行時情報。
テスト2:プッシュダウンなし、12ビットの不純なキー
このテストは@valuesを変更します パラメータを1025に設定し、@dupesを維持します at 63.これにより、64,575行のテーブルが作成され、1,025個の個別の値が含まれます。 列c2 0から1024までの範囲で実行されます。 c2の各値 63回複製 。
SQLServerはc2を格納します 使用する列データ:
- 辞書エンコーディング 重複する値がかなりの数あるためです。
- RLEなし 。値ごとの重複の数(63)は、RLEに必要な64のしきい値に達していません。
- サイズ12のビットパック 。 1,025個の個別の辞書エントリは10ビットに完全には収まりません(2 ^ 10 =1,024)。それらは11ビットに収まりますが、SQLServerは前述のようにそのビットパッキングサイズをサポートしていません。次に小さいサイズは12ビットです。ビットパッキングにハードボーダーのある64ビットユニットを使用すると、12ビットサブユニットよりも11ビットサブユニットが64ビットに収まります。いずれにせよ、5つのサブユニットが64ビットユニットに収まります。
DBCC CSINDEX 出力は上記の分析を確認します:
バージョン=1encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 RowCount =64575
RLEヘッダー:
ロブタイプ=3RLEアレイカウント(ネイティブユニットの観点から)=2
RLEアレイエントリサイズ=8
RLEデータ:
インデックス=0ビットパック配列インデックス=0カウント=64575
インデックス=1値=0カウント=0
ビットパックデータヘッダー:
ビットパックエントリサイズ=12ビットパックユニット数=129915ビットパック最小ID=3
ビットパックデータサイズ=103320
ビットパックデータ:
ユニット0サブユニット0=767
ユニット0サブユニット1=510
ユニット0サブユニット2=254
ユニット0サブユニット3=1021
ユニット0サブユニット4=765
ユニット1サブユニット0=507
ユニット1サブユニット1=250
ユニット1サブユニット2=1019
ユニット1サブユニット3=761
ユニット1サブユニット4=505
不純以来 グループ化キーのサイズは10を超える 、グループ化された集約プッシュダウン 機能しない ここ。これは、ローカルに集約されたゼロ行を示す実行プランによって確認されます。 Columnstore Index Scanで 演算子:
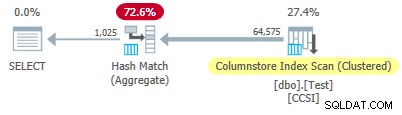
Columnstore Index Scan によって、64,575行すべてが(バッチで)出力されます。 Hash Match Aggregateによってバッチモードで集計されます オペレーター。 ActualLocallyAggregatedRows インデックススキャンのxmlプランランタイム情報に属性がありません。
テスト3:プッシュダウン、純粋なキー
このテストは@dupesを変更します RLEを許可するための63から64までのパラメーター。 @values パラメータが16,384に変更されました(単一の行グループに収まる行の総数の最大値)。 @valuesに選択された正確な数 重要ではありません。重要なのは、RLEを使用できるように、一意の値ごとに64の複製を生成することです。
SQLServerはc2を格納します 使用する列データ:
- 辞書エンコーディング 値が重複しているため。
- RLE。 それぞれが64のしきい値を満たすため、すべての個別の値に使用されます。
- ビットパックされたデータはありません 。サイズ16があれば、サイズ16を使用します。サイズ12は十分な大きさではなく(2 ^ 12 =4,096の個別の値)、サイズ21は無駄になります。 16,384個の異なる値は14ビットに収まりますが、以前と同様に、これらの値は16ビットサブユニットよりも64ビット単位に収まりません。
DBCC CSINDEX 出力は上記を確認します(スペース上の理由から、いくつかのRLEエントリとブックマークのみが表示されます):
バージョン=1encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 RowCount =1048576
RLEヘッダー:
ロブタイプ=3RLEアレイカウント(ネイティブユニットの観点から)=16385
RLEアレイエントリサイズ=8
RLEデータ:
インデックス=0値=3カウント=64
インデックス=1値=1538カウント=64
インデックス=2値=3072カウント=64
インデックス=3値=4608カウント=64
インデックス=4値=6142カウント=64
…
インデックス=16381値=8954カウント=64
インデックス=16382値=10489カウント=64
インデックス=16383値=12025カウント=64
インデックス=16384値=0カウント=0
ブックマークヘッダー:
ブックマーク数=65ブックマーク距離=16384ブックマークサイズ=520
ブックマークデータ:
位置=0インデックス=64
位置=512インデックス=16448
位置=1024インデックス=32832
…
位置=31744インデックス=1015872
位置=32256インデックス=1032256
位置=32768インデックス=1048577
ビットパックデータヘッダー:
ビットパックエントリサイズ=16ビットパックユニット数=0ビットパック最小ID=3
ビットパックデータサイズ=0
グループ化キーは純粋なので (RLEが使用されます)、グループ化された集約プッシュダウン ここで期待されています。実行プランは、ローカルに集約されたすべての行を表示することでこれを確認します Columnstore Index Scanで 演算子:
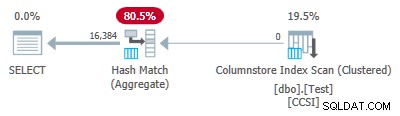
プランxmlにはActualLocallyAggregatedRows="1048576"が含まれています インデックススキャンの実行時情報。
テスト4:10ビットの不純なキー
このテストは@valuesを設定します 1024および@dupes から63まで、64,512行のテーブルを提供し、1,024個の個別の値 列c2 0から1,023までの値。 c2の各値 63回複製 。
最も重要なこと 、bツリークラスター化インデックスが列c1に作成されるようになりました 列c2の代わりに 。クラスタ化された列ストアは、bツリーのクラスタ化インデックスを引き続き置き換えます。これはスクリプトの変更された部分です:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQLServerはc2を格納します 使用する列データ:
- 辞書エンコーディング 重複しているため。
- RLEなし 。値ごとの重複の数(63)は、RLEに必要な64のしきい値に達していません。
- サイズ10のビットパッキング 。 1,024個の個別の辞書エントリは10ビットに正確に収まります(2 ^ 10 =1,024)。それぞれ10ビットの6つのサブユニットを各64ビットユニットに格納できます。
DBCC CSINDEX 出力は次のとおりです:
バージョン=1encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 RowCount =64512
RLEヘッダー:
ロブタイプ=3RLEアレイカウント(ネイティブユニットの観点から)=2
RLEアレイエントリサイズ=8
RLEデータ:
インデックス=0ビットパック配列インデックス=0カウント=64512
インデックス=1値=0カウント=0
ビットパックデータヘッダー:
ビットパックエントリサイズ=10ビットパックユニット数=10752ビットパック最小ID=3
ビットパックデータサイズ=86016
ビットパックデータ:
ユニット0サブユニット0=766
ユニット0サブユニット1=509
ユニット0サブユニット2=254
ユニット0サブユニット3=1020
ユニット0サブユニット4=764
ユニット0サブユニット5=506
ユニット1サブユニット0=250
ユニット1サブユニット1=1018
ユニット1サブユニット2=760
ユニット1サブユニット3=504
ユニット1サブユニット4=247
ユニット1サブユニット5=1014
不純以来 グループ化キーは10以下のサイズを使用し、グループ化された集約プッシュダウンが期待されます。 ここで働くために。しかし、それは何が起こるかではありません 。実行プランは、64,512行のうち54,612行が Hash Match Aggregateで集計されたことを示しています。 演算子:
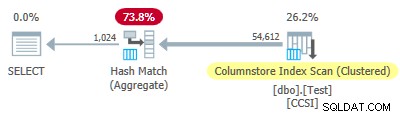
プランxmlにはActualLocallyAggregatedRows="9900"が含まれています インデックススキャンの実行時情報。これは、グループ化された集約プッシュダウンを意味します 9,900行に使用されましたが、他の54,612行には使用されませんでした!
SQL Serverは、グループ化された集約プッシュダウンを使用して開始しました 不純なグループ化キーが10ビット以下の基準を満たしているため、この実行の場合。これは合計11バッチ(それぞれ900行=合計9,900行)続きました。その時点で、グループ化された集約プッシュダウンの有効性を測定するフィードバックメカニズム うまくいかないと判断し、オフにしました 。残りのバッチはすべて、プッシュダウンを無効にして処理されました。
フィードバックは基本的に、集約された行の数と生成されたグループの数を比較します。 100の値で始まり、各プッシュダウン出力バッチの最後に調整されます。値が10以下に下がると、現在のグループ化操作でプッシュダウンが無効になります。
「プッシュダウンのメリットの測定値」は、プッシュダウンされた集計作業がどれほどひどく進んでいるかに応じて、多かれ少なかれ減少します。出力バッチでグループ化キーごとに平均8行未満の場合、現在の利益値は22%減少します。 8を超え16未満の場合、メトリックは11%減少します。
一方、状況が改善し、グループ化キーごとに16行以上が出力バッチで検出された場合、メトリックは100にリセットされ、部分的な集計バッチがスキャンによって生成されるため、引き続き調整されます。
>
このテストのデータは、列c1の元のbツリークラスター化インデックスが原因で、プッシュダウンに対して特に役に立たない順序で表示されました。 。このように表示すると、列c2の値 0から開始し、1,023に達するまで1ずつ増分してから、サイクルを再開します。 1,023の個別の値は、900行の各出力バッチにキーごとに部分的に集約された行が1つだけ含まれるようにするのに十分です。これは幸せな状態ではありません。
値ごとに63ではなく64の重複があった場合、SQLServerはc2による並べ替えを検討していました。 列ストアインデックスを構築している間、RLE圧縮を生成しました。現状では、22%のペナルティがすべてのバッチの後に開始されます。 100から開始し、同じ切り上げ整数演算を使用すると、メトリック値のシーケンスは次のようになります。
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
11番目のバッチは、メトリックを10以下に減らし、プッシュダウンは無効になります。 900行の11バッチは、実行プランに示されている9,900のローカルに集約された行を占めています。
900個の異なる値を持つバリエーション
テスト4でも、行が同じ役に立たない順序で表示されていると仮定すると、901個の異なる値で同じ動作が見られます。
@valuesの変更 他のすべてを同じに保ちながら、パラメータを900に設定すると、実行プランに劇的な影響があります。
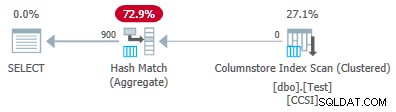
これで、900のグループすべてがスキャン時に集約されます。 xmlプランのプロパティにはActualLocallyAggregatedRows="56700"が表示されます 。これは、グループ化された集約プッシュダウンが1つのバッチで900のグループ化キーと部分的な集約を維持するためです。 It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
注: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.