この記事は、T-SQLのバグ、落とし穴、およびベストプラクティスに関するシリーズの第2回です。今回は、サブクエリを含む古典的なバグに焦点を当てます。特に、置換エラーと3値論理の問題について説明します。私がシリーズでカバーするトピックのいくつかは、私たちがこのテーマについて行ったディスカッションで、仲間のMVPによって提案されました。 Erland Sommarskog、Aaron Bertrand、Alejandro Mesa、Umachandar Jayachandran(UC)、Fabiano Neves Amorim、Milos Radivojevic、Simon Sabin、Adam Machanic、Thomas Grohser、Chan Ming Man、PaulWhiteにご提案いただきありがとうございます。
置換エラー
従来の置換エラーを示すために、単純な顧客注文シナリオを使用します。次のコードを実行して、GetNumsというヘルパー関数を作成し、CustomersテーブルとOrdersテーブルを作成してデータを入力します。
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); 現在、Customersテーブルには1から100の範囲の連続した顧客IDを持つ100人の顧客がいます。これらの顧客のうち98人は、Ordersテーブルに対応する注文があります。 ID 17および59の顧客はまだ注文を行っていないため、注文テーブルに存在しません。
あなたは注文した顧客だけを探しており、次のクエリ(クエリ1と呼びます)を使用してこれを達成しようとしています:
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
98人の顧客を取り戻すことになっていますが、代わりにID17と59の顧客を含む100人の顧客すべてを取り戻します。
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
何が悪いのかわかりますか?
混乱を増すために、図1に示すようにクエリ1の計画を調べてください。
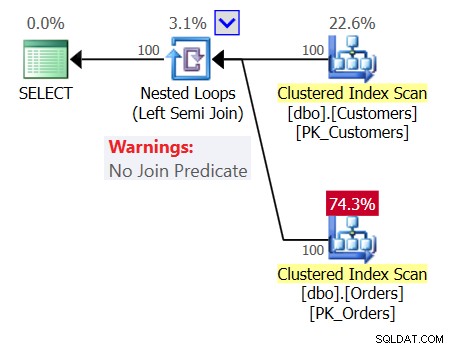 図1:クエリ1の計画
図1:クエリ1の計画
このプランでは、結合述語のないネストされたループ(左半結合)演算子が示されています。つまり、顧客を返すための唯一の条件は、作成したクエリが次のように、空でないOrdersテーブルを持つことです。
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
おそらく、図2に示すような計画を期待していました。
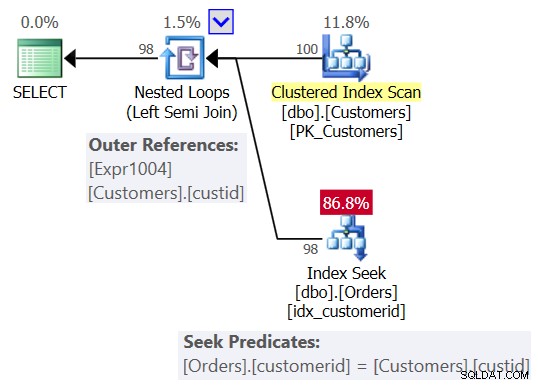 図2:クエリ1の予想される計画
図2:クエリ1の予想される計画
このプランでは、Nested Loops(Left Semi Join)演算子が表示され、Customersのクラスター化インデックスのスキャンが外部入力として、Ordersのcustomerid列のインデックスのシークが内部入力として表示されます。また、Customersのcustid列に基づく外部参照(相関パラメーター)と、シーク述語Orders.customerid=Customers.custidも表示されます。
では、なぜ図2の計画ではなく、図1の計画を取得しているのでしょうか。まだ理解していない場合は、両方のテーブルの定義(具体的には列名)と、クエリで使用されている列名をよく見てください。 Customersテーブルがcustidという列に顧客IDを保持し、Ordersテーブルがcustomeridという列に顧客IDを保持していることがわかります。ただし、コードは外部クエリと内部クエリの両方でcustidを使用します。内部クエリでのcustidへの参照は修飾されていないため、SQLServerは列がどのテーブルからのものであるかを解決する必要があります。 SQL標準によれば、SQL Serverは、最初に同じスコープでクエリされたテーブル内の列を検索することになっていますが、Ordersにはcustidという列がないため、外側のテーブルで検索することになっています。スコープ、そして今回は一致があります。したがって、意図せずに、custidへの参照は、次のクエリを記述したかのように、暗黙的に相関参照になります。
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Ordersが空ではなく、外側のcustid値がNULLでない場合(列がNOT NULLとして定義されているため、この場合はできません)、値をそれ自体と比較するため、常に一致が得られます。 。したがって、クエリ1は次と同等になります。
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
外部テーブルがcustid列でNULLをサポートしている場合、クエリ1は次のようになります。
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
これで、クエリ1が図1の計画で最適化された理由と、100人の顧客すべてを取り戻した理由がわかりました。
少し前に、同様のバグがある顧客を訪問しましたが、残念ながらDELETEステートメントを使用していました。これが何を意味するのか少し考えてみてください。元々削除しようとしていた行だけでなく、すべてのテーブル行が消去されました!
このようなバグを回避するのに役立つベストプラクティスについては、主に2つあります。まず、制御できる限り、同じものを表す属性に対して、テーブル全体で一貫した列名を使用するようにしてください。次に、これが一般的な方法ではない自己完結型のものを含め、サブクエリで列参照をテーブル修飾するようにしてください。もちろん、完全なテーブル名を使用したくない場合は、テーブルエイリアスを使用できます。この方法をクエリに適用して、最初の試行で次のコードを使用したとします。
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
ここでは、暗黙的な列名解決を許可していないため、SQLServerは次のエラーを生成します。
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Ordersテーブルのメタデータを確認し、間違った列名を使用していることに気づき、次のようにクエリを修正します(このクエリ2と呼びます)。
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
今回は、ID 17と59の顧客を除いて、98人の顧客で適切な出力が得られます。
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
また、図2で前述した予想される計画も得られます。
余談ですが、Customers.custidが図2のネストされたループ(左半結合)演算子の外部参照(相関パラメーター)である理由は明らかです。それほど明白ではないのは、Expr1004が外部参照としてプランに表示される理由です。 SQLServerのフェローMVPであるPaulWhiteは、先読みメカニズムによる重複した作業を回避するために、外部入力のリーフからの情報を使用してストレージエンジンにヒントを与えることに関連している可能性があると理論付けています。詳細はこちらでご覧いただけます。
3値論理の問題
サブクエリに関連する一般的なバグは、外部クエリがNOT IN述語を使用し、サブクエリがその値の中でNULLを返す可能性がある場合に関係しています。たとえば、顧客IDとしてNULLを使用してOrdersテーブルに注文を保存できる必要があるとします。このような場合は、どの顧客にも関連付けられていない注文を表します。たとえば、実際の製品数とデータベースに記録された数の間の不一致を補正する注文。
次のコードを使用して、NULLを許可するcustid列を使用してOrdersテーブルを再作成し、今のところ、以前と同じサンプルデータを入力します(17と59を除く顧客ID 1から100による注文):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); その間、前のセクションで説明したベストプラクティスに従って、同じ属性のテーブル間で一貫した列名を使用し、Customersテーブルと同じようにOrdersテーブルの列にcustidという名前を付けたことに注意してください。
注文しなかった顧客を返すクエリを作成する必要があるとします。 NOT IN述語(クエリ3、最初の実行と呼びます)を使用して、次の単純なソリューションを考え出します。
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
このクエリは、顧客17と59で期待される出力を返します。
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
会社の倉庫で在庫が作成され、一部の製品の実際の数量とデータベースに記録されている数量の間に不一致が見つかりました。したがって、不整合を説明するためにダミーの補正順序を追加します。注文に関連付けられている実際の顧客はいないため、顧客IDとしてNULLを使用します。次のコードを実行して、このような注文ヘッダーを追加します。
INSERT INTO dbo.Orders(custid) VALUES(NULL);
クエリ3を2回実行します:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
今回は、空の結果が得られます:
custid companyname ------- ------------ (0 rows affected)
明らかに、何かがおかしい。顧客17と59は注文をしていません。実際、顧客テーブルには表示されますが、注文テーブルには表示されません。それでも、クエリ結果には、注文をしなかった顧客はいないと記載されています。バグの場所と修正方法を理解できますか?
もちろん、このバグはOrdersテーブルのNULLに関係しています。 SQLにとって、NULLは、該当する顧客を表す可能性のある欠落値のマーカーです。 SQLは、NULLが欠落していて適用できない(無関係な)顧客を表していることを認識していません。 Ordersテーブルに存在するCustomersテーブル内のすべての顧客について、IN述語はTRUEを生成する一致を検出し、NOT IN部分はそれをFALSEにするため、顧客行は破棄されます。ここまでは順調ですね。ただし、顧客17および59の場合、NULL以外の値とのすべての比較ではFALSEが生成され、NULLとの比較ではUNKNOWNが生成されるため、IN述部はUNKNOWNを生成します。 SQLは、NULLが該当する顧客を表す可能性があると想定しているため、論理値UNKNOWNは、外部の顧客IDが内部のNULL顧客IDと等しいかどうかが不明であることを示します。 FALSEまたはFALSE…またはUNKNOWNはUNKNOWNです。その後、UNKNOWNに適用されたNOT IN部分は、引き続きUNKNOWNになります。
簡単に言うと、注文しなかった顧客を返品するように依頼しました。したがって、当然のことながら、注文を行ったことが確実にわかっているため、クエリはOrdersテーブルに存在するCustomersテーブルからすべての顧客を破棄します。残りの部分(この場合は17と59)については、SQLに対してクエリがそれらを破棄します。これは、注文したかどうかが不明であるのと同じように、注文しなかったかどうかも不明であり、フィルターには確実性(TRUE)が必要です。行を返すため。なんてピクルス!
したがって、最初のNULLがOrdersテーブルに入るとすぐに、その瞬間から、NOTINクエリから常に空の結果が返されます。データに実際にはNULLが含まれていないが、列でNULLが許可されている場合はどうでしょうか。クエリ3の最初の実行で見たように、このような場合、正しい結果が得られます。おそらく、アプリケーションがデータにNULLを導入することは決してないと考えているので、心配する必要はありません。これは、いくつかの理由で悪い習慣です。 1つは、列がNULLを許可するように定義されている場合、NULLが許可されていなくても、最終的にそこに到達することはほぼ確実です。それは時間の問題です。これは、不正なデータのインポート、アプリケーションのバグ、およびその他の理由の結果である可能性があります。もう1つは、データにNULLが含まれていない場合でも、列でNULLが許可されている場合、オプティマイザーはクエリプランの作成時にNULLが存在する可能性を考慮する必要があり、NOTINクエリではパフォーマンスが低下します。 。これを実証するために、図3に示すように、行にNULLを追加する前に、クエリ3を最初に実行する計画を検討してください。
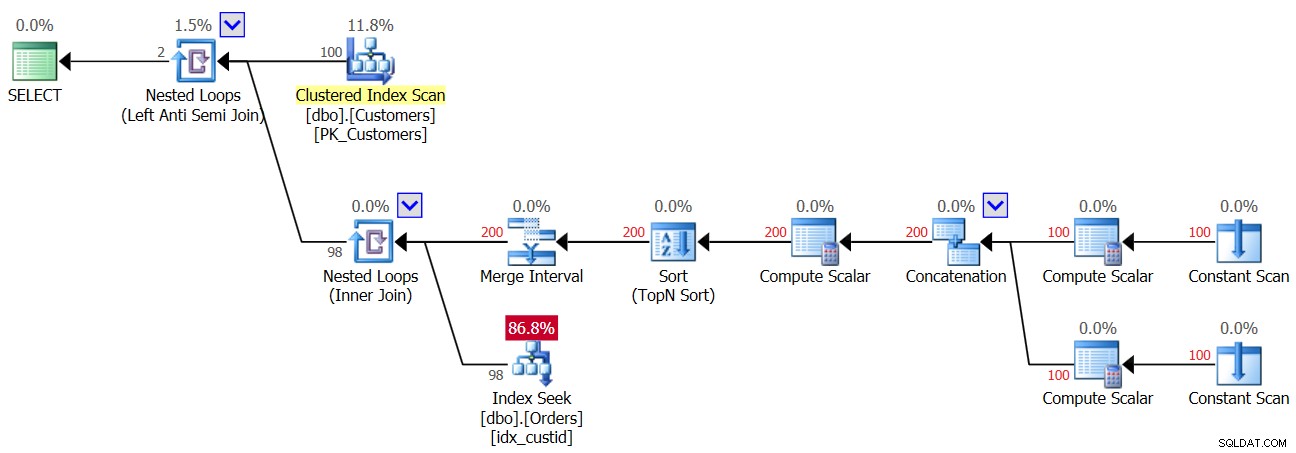 図3:クエリ3の最初の実行の計画
図3:クエリ3の最初の実行の計画
最上位のネストされたループ演算子は、左アンチセミジョインロジックを処理します。これは基本的に、不一致を特定し、一致が見つかるとすぐに内部アクティビティを短絡することです。ループの外側の部分は、Customersテーブルから100人の顧客すべてをプルするため、ループの内側の部分は100回実行されます。
一番上のループの内側の部分は、ネストされたループ(内側の結合)演算子を実行します。下のループの外側の部分は、顧客ごとに2つの行を作成します。1つはNULLの場合、もう1つは現在の顧客ID用です。マージ間隔演算子で混乱させないでください。これは通常、重複する間隔をマージするために使用されます。たとえば、col1 BETWEEN 20AND30またはcol1BETWEEN25AND35などの述語はcol1BETWEEN20 AND 35に変換されます。このアイデアは、IN述語の重複を削除するために一般化できます。私たちの場合、実際には重複することはできません。簡単に言うと、前述のように、ループの外側の部分は、顧客ごとに2つの行を作成するものと考えてください。1つ目はNULLの場合、2つ目は現在の顧客IDです。次に、ループの内部は、最初にOrdersのインデックスidx_custidでシークを実行して、NULLを探します。 NULLが見つかった場合、現在の顧客IDの2回目のシークはアクティブになりません(上部のアンチセミジョインループによって処理される短絡を思い出してください)。このような場合、外部の顧客は破棄されます。ただし、NULLが見つからない場合、下部のループは、注文で現在の顧客IDを探すための2回目のシークをアクティブにします。見つかった場合、外部の顧客は破棄されます。見つからない場合は、外部のお客様に返品します。これが意味するのは、注文にNULLが存在しない場合、このプランは顧客ごとに2つのシークを実行するということです。これは、下部ループの外部入力の行数200として計画で確認できます。結果として、最初の実行で報告されるI/O統計は次のとおりです。
Table 'Orders'. Scan count 200, logical reads 603
NULLの行がOrdersテーブルに追加された後の、クエリ3の2回目の実行の計画を図4に示します。
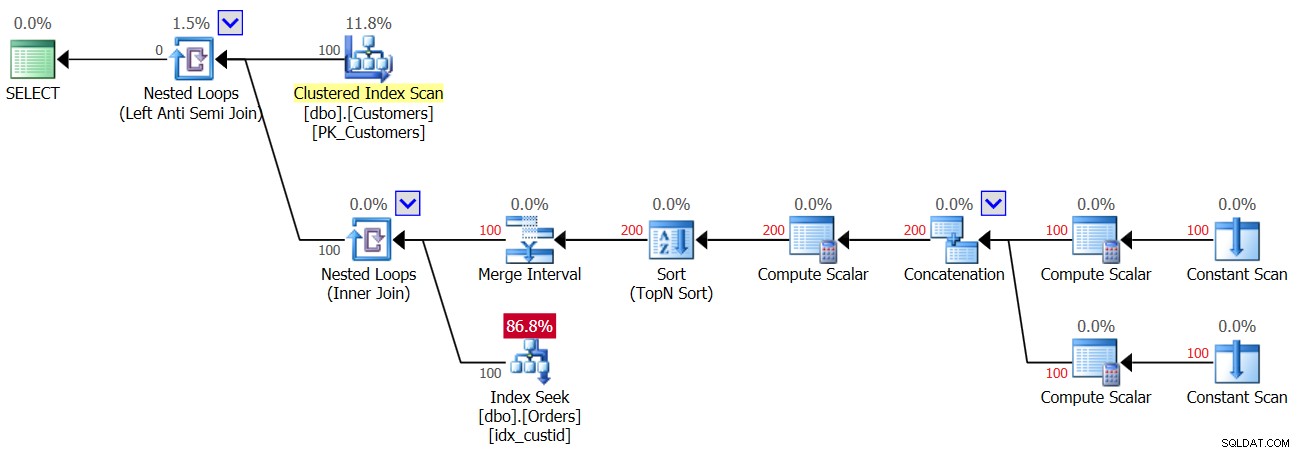 図4:クエリ3の2回目の実行の計画
図4:クエリ3の2回目の実行の計画
テーブルにはNULLが存在するため、すべての顧客について、Index Seek演算子を最初に実行すると一致するものが見つかり、すべての顧客が破棄されます。つまり、顧客ごとに1回だけシークを実行し、2回ではないので、今回は200回ではなく100回のシークを取得します。ただし、同時に、これは空の結果が返されることを意味します!
2回目の実行で報告されるI/O統計は次のとおりです。
Table 'Orders'. Scan count 100, logical reads 300
サブクエリの戻り値にNULLが含まれる可能性がある場合の、このタスクの1つの解決策は、次のように単純にそれらを除外することです(ソリューション1 /クエリ4と呼びます):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
このコードは期待される出力を生成します:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
このソリューションの欠点は、フィルターを追加することを忘れないようにする必要があることです。 NOT EXISTS述語を使用するソリューションが好きです。この場合、サブクエリには、注文の顧客IDと顧客の顧客IDを比較する明示的な相関関係があります(ソリューション2 /クエリ5と呼びます):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
NULLと何かの間の等式ベースの比較は、UNKNOWNを生成し、UNKNOWNはWHEREフィルターによって破棄されることに注意してください。したがって、NULLがOrdersに存在する場合、明示的なNULL処理を追加しなくても、内部クエリのフィルタによって削除されるため、データにNULLが存在するかどうかを心配する必要はありません。
このクエリは期待される出力を生成します:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
両方のソリューションの計画を図5に示します。
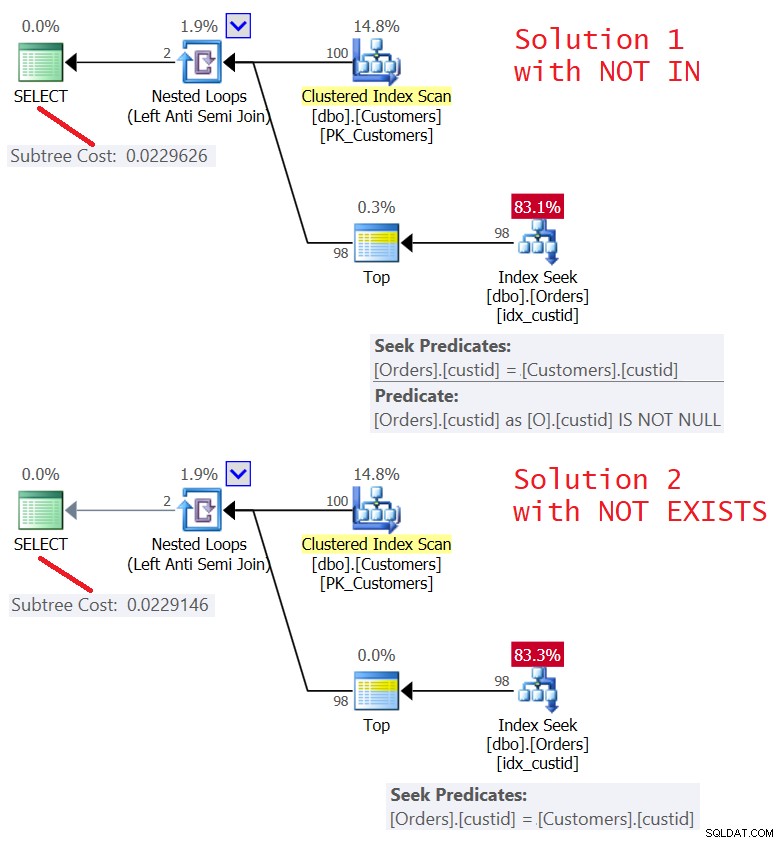 図5:クエリ4(ソリューション1)とクエリ5(ソリューション2)の計画)
図5:クエリ4(ソリューション1)とクエリ5(ソリューション2)の計画)
ご覧のとおり、計画はほぼ同じです。また、短絡を伴う左セミジョイン最適化を使用して、非常に効率的です。どちらも、注文のインデックスidx_custidで100回のシークのみを実行し、Top演算子を使用して、リーフの1つの行がタッチされた後に短絡を適用します。
両方のクエリのI/O統計は同じです:
Table 'Orders'. Scan count 100, logical reads 348
ただし、考慮すべきことの1つは、外部テーブルの相関列にNULLが含まれる可能性があるかどうかです(この場合はcustid)。顧客注文のようなシナリオでは関連性がない可能性が非常に高いですが、他のシナリオでは関連性がある可能性があります。実際にそうであれば、どちらのソリューションも外部NULLを誤って処理します。
これを示すために、次のコードを実行して、顧客IDの1つとしてNULLを使用してCustomersテーブルを削除して再作成します。
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); 解決策1は、内部NULLが存在するかどうかに関係なく、外部NULLを返しません。
解決策2は、内部NULLが存在するかどうかに関係なく、外部NULLを返します。
NULL以外の値を処理するようにNULLを処理する場合、つまり、顧客に存在するが注文には存在しない場合はNULLを返し、両方に存在する場合はNULLを返さない場合は、区別を使用するようにソリューションのロジックを変更する必要があります。等式ベースの比較ではなく、ベースの比較。これは、EXISTS述語とEXCEPT集合演算子を組み合わせることで実現できます(このソリューション3 /クエリ6と呼びます):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
現在、CustomersとOrdersの両方にNULLがあるため、このクエリはNULLを正しく返しません。クエリの出力は次のとおりです。
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
次のコードを実行して、OrdersテーブルからNULLの行を削除し、ソリューション3を再実行します。
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
今回は、顧客にはNULLが存在しますが、注文には存在しないため、結果にはNULLが含まれます:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
このソリューションの計画を図6に示します。
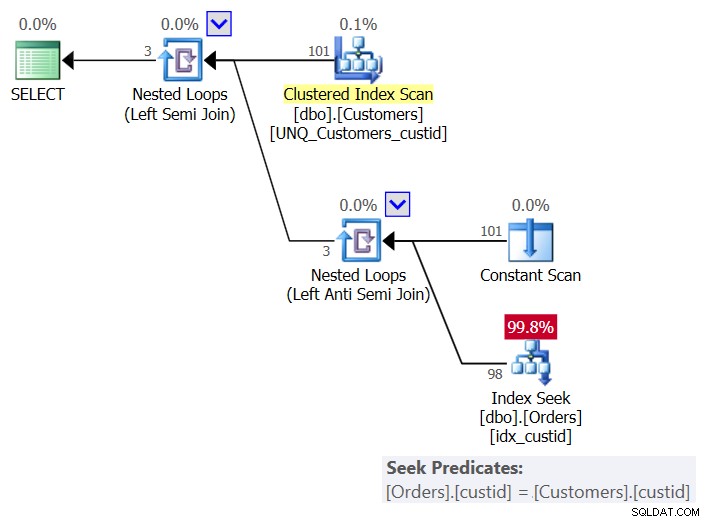 図6:クエリ6の計画(ソリューション3)
図6:クエリ6の計画(ソリューション3)
顧客ごとに、プランはコンスタントスキャン演算子を使用して現在の顧客との行を作成し、注文のインデックスidx_custidに単一のシークを適用して、顧客が注文に存在するかどうかを確認します。最終的に、顧客ごとに1つのシークが発生します。現在、テーブルには101人の顧客がいるため、101人のシークがあります。
このクエリのI/O統計は次のとおりです。
Table 'Orders'. Scan count 101, logical reads 415
結論
今月は、サブクエリ関連のバグ、落とし穴、ベストプラクティスについて説明しました。置換エラーと3値論理の問題について説明しました。テーブル全体で一貫した列名を使用することを忘れないでください。また、サブクエリでは、自己完結型の列であっても、常にテーブル修飾列を使用してください。また、列でNULLを許可することが想定されていない場合は、NOT NULL制約を適用し、データで可能な場合は常にNULLを考慮に入れることを忘れないでください。許可されている場合は、サンプルデータにNULLを含めるようにしてください。これにより、コードのテスト時にコードのバグをより簡単に見つけることができます。サブクエリと組み合わせる場合は、NOTIN述部に注意してください。内部クエリの結果でNULLが可能である場合は、通常、NOTEXISTS述語が推奨される代替手段です。