この記事は、T-SQLのバグ、落とし穴、およびベストプラクティスに関するシリーズの第4回です。以前は、決定論、サブクエリ、および結合について説明しました。今月の記事の焦点は、ウィンドウ関数に関連するバグ、落とし穴、およびベストプラクティスです。 Erland Sommarskog、Aaron Bertrand、Alejandro Mesa、Umachandar Jayachandran(UC)、Fabiano Neves Amorim、Milos Radivojevic、Simon Sabin、Adam Machanic、Thomas Grohser、Chan Ming Man、PaulWhiteにアイデアを提供してくれてありがとう!
私の例では、TSQLV5というサンプルデータベースを使用します。このデータベースを作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
ウィンドウ関数に関連する2つの一般的な落とし穴があります。どちらも、SQL標準によって課される直感に反する暗黙のデフォルトの結果です。 1つの落とし穴は、暗黙のRANGEオプションを使用してウィンドウフレームを取得する現在の合計の計算に関係しています。もう1つの落とし穴は多少関連していますが、FIRST_VALUE関数とLAST_VALUE関数の暗黙的なフレーム定義を含む、より深刻な結果をもたらします。
暗黙のRANGEオプションを使用したウィンドウフレーム
最初の落とし穴は、ウィンドウ順序句を明示的に指定するが、ウィンドウフレーム単位(ROWSまたはRANGE)とそれに関連するウィンドウフレーム範囲(ROWSなど)を明示的に指定しない、集約ウィンドウ関数を使用した累計の計算です。無制限の先行。暗黙のデフォルトは直感に反するものであり、その結果は驚くべきものであり、苦痛を伴う可能性があります。
この落とし穴を示すために、クレジット(正の値)とデビット(負の値)を使用して200万の銀行口座トランザクションを保持するトランザクションと呼ばれるテーブルを使用します。次のコードを実行してトランザクションテーブルを作成し、サンプルデータを入力します。
SET NOCOUNT ON;
USE TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip
DROP TABLE IF EXISTS dbo.Transactions;
CREATE TABLE dbo.Transactions
(
actid INT NOT NULL,
tranid INT NOT NULL,
val MONEY NOT NULL,
CONSTRAINT PK_Transactions PRIMARY KEY(actid, tranid) -- creates POC index
);
DECLARE
@num_partitions AS INT = 100,
@rows_per_partition AS INT = 20000;
INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val)
SELECT NP.n, RPP.n,
(ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM(NEWID())%5))
FROM dbo.GetNums(1, @num_partitions) AS NP
CROSS JOIN dbo.GetNums(1, @rows_per_partition) AS RPP; 私たちの落とし穴には、潜在的な論理的なバグを伴う論理的な側面と、パフォーマンスの低下を伴うパフォーマンスの側面の両方があります。パフォーマンスの低下は、ウィンドウ関数が行モード処理演算子で最適化されている場合にのみ関係します。 SQL Server 2016では、バッチモードのWindow Aggregate演算子が導入されています。これにより、落とし穴のパフォーマンスペナルティ部分が削除されますが、SQL Server 2019より前では、この演算子は、データに列ストアインデックスが存在する場合にのみ使用されます。 SQL Server 2019では、行ストアのサポートにバッチモードが導入されているため、データに列ストアインデックスが存在しない場合でも、バッチモードの処理を実行できます。行モード処理によるパフォーマンスの低下を示すために、この記事のコードサンプルをSQLServer2019以降またはAzureSQLDatabaseで実行している場合は、次のコードを使用してデータベースの互換性レベルを140に設定します。行ストアでバッチモードをまだ有効にしない:
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL = 140;
次のコードを使用して、セッションの時間とI/O統計をオンにします。
SET STATISTICS TIME, IO ON;
SSMSで200万行が出力されるのを待つのを避けるために、このセクションのコードサンプルを実行後に[実行後に結果を破棄する]オプションをオンにして実行することをお勧めします([クエリオプション]、[結果]、[グリッド]に移動し、[実行後に結果を破棄する]をオンにします)。
落とし穴に入る前に、明示的なフレーム指定を備えたウィンドウ集計関数を使用して現在の合計を適用することにより、各トランザクション後の銀行口座残高を計算する次のクエリ(クエリ1と呼びます)を検討してください。
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
ROWS UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; 行モード処理を使用したこのクエリの計画を図1に示します。
 図1:クエリ1の計画、行モード処理
図1:クエリ1の計画、行モード処理
プランは、テーブルのクラスター化されたインデックスから事前に注文されたデータをプルします。次に、SegmentおよびSequence Projectオペレーターを使用して行番号を計算し、現在の行のフレームに属する行を特定します。次に、Segment、Window Spool、およびStream Aggregate演算子を使用して、ウィンドウ集約関数を計算します。ウィンドウスプール演算子は、集約する必要のあるフレーム行をスプールするために使用されます。特別な最適化がなければ、プランは行ごとに該当するすべてのフレーム行をスプールに書き込み、それらを集約する必要がありました。これにより、2次またはNの複雑さが生じます。幸いなことに、フレームがUNBOUNDED PRECEDINGで始まる場合、SQLServerはケースをファストトラックとして識別します。 この場合、前の行の現在の合計を取得し、現在の行の値を加算して現在の行の現在の合計を計算し、線形スケーリングを行います。このファストトラックモードでは、プランは入力行ごとに2つの行のみをスプールに書き込みます。1つは集計、もう1つは詳細です。
ウィンドウスプールは、2つの方法のいずれかで物理的に実装できます。ウィンドウ関数用に特別に設計された高速のメモリ内スプールとして、または本質的にtempdbの一時テーブルである低速のオンディスクスプールとして。スプールに書き込む必要のある行数が基になる行ごとにある場合 10,000を超える可能性があります。または、SQL Serverがその数を予測できない場合は、低速のディスク上のスプールを使用します。クエリプランでは、基になる行ごとに正確に2つの行がスプールに書き込まれるため、SQLServerはメモリ内のスプールを使用します。残念ながら、どのような種類のスプールを取得しているかを計画から判断する方法はありません。これを理解する方法は2つあります。 1つは、window_spool_ondisk_warningと呼ばれる拡張イベントを使用することです。もう1つのオプションは、STATISTICS IOを有効にし、Worktableと呼ばれるテーブルについて報告された論理読み取りの数を確認することです。ゼロより大きい数値は、ディスク上のスプールを取得したことを意味します。ゼロは、メモリ内スプールを取得したことを意味します。クエリのI/O統計は次のとおりです。
テーブル'Worktable'論理読み取り:0。テーブル'Transactions'論理読み取り:6208。ご覧のとおり、メモリ内スプールを使用しました。これは通常、最初の区切り文字としてUNBOUNDEDPRECEDINGを使用してROWSウィンドウフレームユニットを使用する場合に当てはまります。
クエリの時間統計は次のとおりです。
CPU時間:4297ミリ秒、経過時間:4441ミリ秒。このクエリが私のマシンで完了し、結果が破棄されるまでに約4.5秒かかりました。
さて、キャッチのために。 ROWSの代わりにRANGEオプションを使用し、同じ区切り文字を使用すると、意味に微妙な違いが生じる可能性がありますが、行モードでのパフォーマンスには大きな違いがあります。意味の違いは、完全な注文がない場合、つまり、一意ではないもので注文している場合にのみ関係します。 ROWS UNBOUNDED PRECEDINGオプションは現在の行で停止するため、同点の場合、計算は非決定的です。逆に、RANGE UNBOUNDED PRECEDINGオプションは、現在の行より先に表示され、存在する場合はタイが含まれます。 TOPWITHTIESオプションと同様のロジックを使用します。完全な注文がある場合、つまり、独自の注文をしている場合、含める関係はありません。したがって、このような場合、ROWSとRANGEは論理的に同等になります。問題は、RANGEを使用する場合、SQL Serverは常に行モード処理でディスク上のスプールを使用することです。これは、特定の行を処理するときに、含まれる行の数を予測できないためです。これにより、パフォーマンスが大幅に低下する可能性があります。
次のクエリ(クエリ2と呼びます)を考えてみましょう。これはクエリ1と同じで、ROWSの代わりにRANGEオプションを使用するだけです。
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
RANGE UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; このクエリの計画を図2に示します。
 図2:クエリ2の計画、行モード処理
図2:クエリ2の計画、行モード処理
クエリ2は、全順序があるため、論理的にクエリ1と同等です。ただし、RANGEを使用しているため、ディスク上のスプールで最適化されます。クエリ2の計画では、ウィンドウスプールがクエリ1の計画と同じように見え、推定コストが同じであることに注意してください。
クエリ2を実行するための時間とI/O統計は次のとおりです。
CPU時間:19515ミリ秒、経過時間:20201ミリ秒。テーブル「ワークテーブル」の論理読み取り:12044701。テーブル「トランザクション」の論理読み取り:6208。
Worktableに対する多数の論理読み取りに注意してください。これは、ディスク上のスプールを取得したことを示しています。実行時間は、クエリ1の場合の4倍以上です。
その場合は、本当にネクタイを含める必要がない限り、RANGEオプションの使用を避けるだけでよいと考えている場合は、それは良い考えです。問題は、明示的なウィンドウ順序句でフレーム(aggregates、FIRST_VALUE、LAST_VALUE)をサポートするウィンドウ関数を使用しているが、ウィンドウフレームユニットとそれに関連するエクステントについて言及していない場合、デフォルトでRANGEUNBOUNDEDPRECEDINGを取得することです。 。このデフォルトはSQL標準によって規定されており、標準は一般的にデフォルトとしてより決定論的なオプションを好むため、これを選択しました。次のクエリ(クエリ3と呼びます)は、このトラップに該当する例です。
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid ) AS balance
FROM dbo.Transactions; 多くの場合、人々は、デフォルトでROWS UNBOUNDED PRECEDINGを取得していると想定してこのように記述しますが、実際にはRANGEUNBOUNDEDPRECEDINGを取得していることに気づいていません。この関数は全順序を使用しているため、ROWSと同じ結果が得られ、結果から問題があるとは言えません。しかし、得られるパフォーマンスの数値は、クエリ2の場合と同じです。私は、人々が常にこの罠に陥っているのを目にします。
この問題を回避するためのベストプラクティスは、フレームでウィンドウ関数を使用し、ウィンドウフレームの単位とその範囲を明示し、通常はROWSを使用する場合です。 RANGEの使用は、注文が一意ではなく、同点を含める必要がある場合にのみ予約してください。
ROWSとRANGEの間に概念的な違いがある場合を示す次のクエリについて考えてみます。
SELECT orderdate, orderid, val,
SUM(val) OVER( ORDER BY orderdate ROWS UNBOUNDED PRECEDING ) AS sumrows,
SUM(val) OVER( ORDER BY orderdate RANGE UNBOUNDED PRECEDING ) AS sumrange
FROM Sales.OrderValues
ORDER BY orderdate; このクエリは次の出力を生成します:
orderdate orderid val sumrows sumrange ---------- -------- -------- -------- --------- 2017-07-04 10248 440.00 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2303.40 2017-07-08 10250 1552.60 3856.00 4510.06 2017-07-08 10251 654.06 4510.06 4510.06 2017-07-09 10252 3597.90 8107.96 8107.96 ...
2017年7月8日の場合のように、同じ注文日が複数回表示される行の結果の違いを観察します。ROWSオプションにタイが含まれていないため、非決定的である方法と、RANGEオプションがどのように機能するかに注意してください。同点を含むため、常に決定論的です。
ただし、実際には、一意ではないもので注文する場合があり、計算を決定論的にするためにタイを含める必要がある場合は疑問があります。実際にはおそらくはるかに一般的なのは、2つのことのいずれかを行うことです。 1つは、ウィンドウの順序に何かを追加して一意にすることで関係を解消することです。これにより、次のように決定論的な計算が行われます。
SELECT orderdate, orderid, val,
SUM(val) OVER( ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING ) AS runningsum
FROM Sales.OrderValues
ORDER BY orderdate; このクエリは次の出力を生成します:
orderdate orderid val runningsum ---------- -------- --------- ----------- 2017-07-04 10248 440.00 440.00 2017-07-05 10249 1863.40 2303.40 2017-07-08 10250 1552.60 3856.00 2017-07-08 10251 654.06 4510.06 2017-07-09 10252 3597.90 8107.96 ...
もう1つのオプションは、次のように、注文日ごとに予備的なグループ化を適用することです。
SELECT orderdate, SUM(val) AS daytotal,
SUM(SUM(val)) OVER( ORDER BY orderdate ROWS UNBOUNDED PRECEDING ) AS runningsum
FROM Sales.OrderValues
GROUP BY orderdate
ORDER BY orderdate; このクエリは、各注文日が1回だけ表示される次の出力を生成します。
orderdate daytotal runningsum ---------- --------- ----------- 2017-07-04 440.00 440.00 2017-07-05 1863.40 2303.40 2017-07-08 2206.66 4510.06 2017-07-09 3597.90 8107.96 ...
とにかく、ここでのベストプラクティスを忘れないでください!
幸いなことに、SQL Server 2016以降で実行していて、データに列ストアインデックスが存在する場合(偽のフィルター処理された列ストアインデックスであっても)、SQL Server 2019以降で実行している場合、またはAzure SQL Databaseでは、列ストアインデックスの存在に関係なく、前述の3つのクエリすべてがバッチモードのWindowAggregate演算子で最適化されます。この演算子を使用すると、行モードの処理の非効率性の多くが解消されます。このオペレーターはスプールをまったく使用しないため、メモリ内とディスク上のスプールの問題はありません。より高度な処理を使用して、ROWSとRANGEの両方のメモリ内の行のウィンドウに複数の並列パスを適用できます。
バッチモード最適化の使用方法を示すために、データベースの互換性レベルが150以上に設定されていることを確認してください。
ALTER DATABASE TSQLV5 SET COMPATIBILITY_LEVEL = 150;
クエリ1を再度実行します:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
ROWS UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; このクエリの計画を図3に示します。
 図3:クエリ1の計画、バッチモード処理
図3:クエリ1の計画、バッチモード処理
このクエリで取得したパフォーマンス統計は次のとおりです。
CPU時間:937ミリ秒、経過時間:983ミリ秒。表「トランザクション」の論理読み取り:6208。
実行時間は1秒に短縮されました!
明示的なRANGEオプションを指定してクエリ2を再度実行します:
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid
RANGE UNBOUNDED PRECEDING ) AS balance
FROM dbo.Transactions; このクエリの計画を図4に示します。
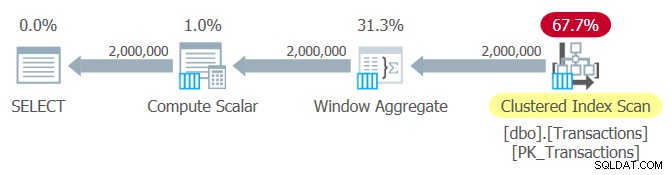 図2:クエリ2の計画、バッチモード処理
図2:クエリ2の計画、バッチモード処理
このクエリで取得したパフォーマンス統計は次のとおりです。
CPU時間:969ミリ秒、経過時間:1048ミリ秒。表「トランザクション」の論理読み取り:6208。
パフォーマンスはクエリ1の場合と同じです。
暗黙のRANGEオプションを使用して、クエリ3を再度実行します。
SELECT actid, tranid, val,
SUM(val) OVER( PARTITION BY actid
ORDER BY tranid ) AS balance
FROM dbo.Transactions; もちろん、計画とパフォーマンスの数値はクエリ2の場合と同じです。
完了したら、次のコードを実行してパフォーマンス統計をオフにします。
SET STATISTICS TIME, IO OFF;
また、SSMSの[実行後に結果を破棄する]オプションをオフにすることを忘れないでください。
FIRST_VALUEとLAST_VALUEの暗黙のフレーム
FIRST_VALUE関数とLAST_VALUE関数は、それぞれウィンドウフレームの最初の行または最後の行から式を返すオフセットウィンドウ関数です。それらのトリッキーな部分は、人々が初めてそれらを使用するときに、フレームをサポートしていることに気付かず、むしろパーティション全体に適用されると考えることです。
注文情報に加えて、顧客の最初と最後の注文の値を返す次の試みを検討してください。
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid ) AS firstval,
LAST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid ) AS lastval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; これらの関数がウィンドウパーティション全体で機能すると誤って信じている場合、これはこれらの関数を初めて使用する多くの人々の信念であり、当然、FIRST_VALUEは顧客の最初の注文の注文値を返し、LAST_VALUEは顧客の最初の注文の注文値を返すことを期待します。顧客の最後の注文の注文値。ただし、実際には、これらの関数はフレームをサポートします。念のため、フレームをサポートする関数では、ウィンドウ順序句を指定し、ウィンドウフレーム単位とそれに関連するエクステントを指定しない場合、デフォルトでRANGEUNBOUNDEDPRECEDINGが取得されます。 FIRST_VALUE関数を使用すると、期待どおりの結果が得られますが、クエリが行モード演算子で最適化されると、ディスク上のスプールを使用する場合のペナルティが発生します。 LAST_VALUE関数を使用すると、さらに悪化します。ディスク上のスプールのペナルティを支払うだけでなく、パーティションの最後の行から値を取得する代わりに、現在の行から値を取得します!
上記のクエリの出力は次のとおりです。
custid orderdate orderid val firstval lastval ------- ---------- -------- ---------- ---------- ---------- 1 2018-08-25 10643 814.50 814.50 814.50 1 2018-10-03 10692 878.00 814.50 878.00 1 2018-10-13 10702 330.00 814.50 330.00 1 2019-01-15 10835 845.80 814.50 845.80 1 2019-03-16 10952 471.20 814.50 471.20 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 88.80 2 2018-08-08 10625 479.75 88.80 479.75 2 2018-11-28 10759 320.00 88.80 320.00 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 403.20 3 2018-04-15 10507 749.06 403.20 749.06 3 2018-05-13 10535 1940.85 403.20 1940.85 3 2018-06-19 10573 2082.00 403.20 2082.00 3 2018-09-22 10677 813.37 403.20 813.37 3 2018-09-25 10682 375.50 403.20 375.50 3 2019-01-28 10856 660.00 403.20 660.00 ...
多くの場合、このような出力を初めて見ると、SQLServerにバグがあると思います。しかしもちろん、そうではありません。これは単にSQL標準のデフォルトです。クエリにバグがあります。フレームが含まれていることに気付いた場合は、フレームの仕様を明示し、後の行をキャプチャする最小のフレームを使用する必要があります。また、必ずROWSユニットを使用してください。したがって、パーティションの最初の行を取得するには、フレームROWS BETWEEN UNBOUNDED PRECEDING ANDCURRENTROWでFIRST_VALUE関数を使用します。パーティションの最後の行を取得するには、フレームROWS BETWEEN CURRENT ROW ANDUNBOUNDEDFOLLOWINGでLAST_VALUE関数を使用します。
バグが修正された修正済みのクエリは次のとおりです。
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS firstval,
LAST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS lastval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; 今回は正しい結果が得られます:
custid orderdate orderid val firstval lastval ------- ---------- -------- ---------- ---------- ---------- 1 2018-08-25 10643 814.50 814.50 933.50 1 2018-10-03 10692 878.00 814.50 933.50 1 2018-10-13 10702 330.00 814.50 933.50 1 2019-01-15 10835 845.80 814.50 933.50 1 2019-03-16 10952 471.20 814.50 933.50 1 2019-04-09 11011 933.50 814.50 933.50 2 2017-09-18 10308 88.80 88.80 514.40 2 2018-08-08 10625 479.75 88.80 514.40 2 2018-11-28 10759 320.00 88.80 514.40 2 2019-03-04 10926 514.40 88.80 514.40 3 2017-11-27 10365 403.20 403.20 660.00 3 2018-04-15 10507 749.06 403.20 660.00 3 2018-05-13 10535 1940.85 403.20 660.00 3 2018-06-19 10573 2082.00 403.20 660.00 3 2018-09-22 10677 813.37 403.20 660.00 3 2018-09-25 10682 375.50 403.20 660.00 3 2019-01-28 10856 660.00 403.20 660.00 ...
これらの機能を備えたフレームをサポートするための標準の動機は何だったのだろうか。あなたがそれについて考えるならば、あなたは主にそれらを使ってパーティションの最初または最後の行から何かを取得します。たとえば、現在の2行前の値が必要な場合は、2 PRECEDINGで始まるフレームでFIRST_VALUEを使用する代わりに、明示的なオフセットが2のLAGを使用する方がはるかに簡単ではありません。>>
SELECT custid, orderdate, orderid, val,
LAG(val, 2) OVER( PARTITION BY custid
ORDER BY orderdate, orderid ) AS prevtwoval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; このクエリは次の出力を生成します:
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ----------- 1 2018-08-25 10643 814.50 NULL 1 2018-10-03 10692 878.00 NULL 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 NULL 2 2018-08-08 10625 479.75 NULL 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10365 403.20 NULL 3 2018-04-15 10507 749.06 NULL 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 1940.85 3 2018-09-25 10682 375.50 2082.00 3 2019-01-28 10856 660.00 813.37 ...
明らかに、上記のLAG関数の使用と、2PRECEDINGで始まるフレームでのFIRST_VALUEの使用には意味上の違いがあります。前者では、行が目的のオフセットに存在しない場合、デフォルトでNULLを取得します。後者の場合でも、存在する最初の行から値を取得します。つまり、パーティションの最初の行から値を取得します。次のクエリについて考えてみます。
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER( PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS prevtwoval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid; このクエリは次の出力を生成します:
custid orderdate orderid val prevtwoval ------- ---------- -------- ---------- ----------- 1 2018-08-25 10643 814.50 814.50 1 2018-10-03 10692 878.00 814.50 1 2018-10-13 10702 330.00 814.50 1 2019-01-15 10835 845.80 878.00 1 2019-03-16 10952 471.20 330.00 1 2019-04-09 11011 933.50 845.80 2 2017-09-18 10308 88.80 88.80 2 2018-08-08 10625 479.75 88.80 2 2018-11-28 10759 320.00 88.80 2 2019-03-04 10926 514.40 479.75 3 2017-11-27 10365 403.20 403.20 3 2018-04-15 10507 749.06 403.20 3 2018-05-13 10535 1940.85 403.20 3 2018-06-19 10573 2082.00 749.06 3 2018-09-22 10677 813.37 1940.85 3 2018-09-25 10682 375.50 2082.00 3 2019-01-28 10856 660.00 813.37 ...
今回は、出力にNULLがないことを確認してください。したがって、FIRST_VALUEとLAST_VALUEでフレームをサポートすることにはある程度の価値があります。これらの関数を使用してフレームの仕様を常に明示し、必要な行を含む最小のフレームでROWSオプションを使用するという、ベストプラクティスを覚えておいてください。
結論
この記事では、ウィンドウ関数に関連するバグ、落とし穴、およびベストプラクティスに焦点を当てました。ウィンドウ集計関数とFIRST_VALUEおよびLAST_VALUEウィンドウオフセット関数の両方がフレームをサポートしていること、およびウィンドウ順序句を指定しているがウィンドウフレーム単位とそれに関連する範囲を指定していない場合は、RANGEUNBOUNDEDPRECEDINGを取得することに注意してください。デフォルト。これにより、クエリが行モード演算子で最適化されると、パフォーマンスが低下します。 LAST_VALUE関数を使用すると、パーティションの最後の行ではなく、現在の行から値を取得できます。フレームについて明確にし、一般的にRANGEよりROWSオプションを優先することを忘れないでください。バッチモードのWindowAggregateオペレーターでパフォーマンスが向上するのを見るのは素晴らしいことです。該当する場合、少なくともパフォーマンスの落とし穴は解消されます。