[パート1|パート2|パート3]
パート1では、ページ圧縮と列ストア圧縮の両方で1TBテーブルのサイズを80%以上削減する方法を示しました。テーブルを1TBから50GBに縮小できることに感銘を受けましたが、それにかかった時間(2時間から14時間)にはあまり満足していませんでした。 Joe Obbish、Lonny Niederstadt、Niko Neugebauerなどの人々から丁寧に借りたヒントをいくつか使用して、この投稿では、ロードパフォーマンスを向上させるために、元の試みにいくつかの変更を加えます。通常の列ストアインデックスは、このデータセットでのページ圧縮よりも圧縮率が高くなかったため 、そこにたどり着くまでに13時間長くかかったので、 COLUMNSTORE_ARCHIVEを使用したより高度なソリューションにのみ焦点を当てます。 圧縮。
パフォーマンスに影響を与えたと思われる問題には、次のものがあります。
- 不適切なファイルレイアウトの選択 – 1つのファイルグループに8つのファイルを配置しましたが、並列処理はありますが、パーティション化は行われていません(または最適ではありません)。これに対処するために、私は次のことを行います:
- テーブルを8つのパーティションに分割します(コアごとに1つ)
- 各パーティションのデータファイルを独自のファイルグループに配置します
- 8つの個別のプロセスを使用して、各パーティションにアフィニティ化します
- 「アクティブな」パーティションを除くすべてのパーティションでアーカイブ圧縮を使用する
- 小さなバッチが多すぎて行グループの数が最適ではない –一度に1,000万行を処理することで、9つの行グループに1,048,576行を追加すると、残りの562,816行が別の小さな行グループになります。また、残りが102,400行未満の不均一な分布は、効率の低いデルタストア構造に挿入を細流化します。行をより均一に分散し、デルタストアを回避するために、次のようにします。
- 1,048,576行の正確な倍数で可能な限り多くのデータを処理します
- それらを8つのパーティションにできるだけ均等に分散します
- 10倍に近いバッチサイズを使用->1億行
- スケジューラのスタッキング –これを確認していませんが、スケジューラーのラウンドロビンが原因で、1つのスケジューラーが多くの作業を引き受け、別のスケジューラーが不十分であることが原因で速度低下が発生した可能性があります。これで、1つのmaxdop8プロセスではなく8つのmaxdop1プロセスを使用してデータを意図的にロードし、すべてのスケジューラーを均等にビジー状態に保つために、次のようにします。
- スケジューラ間で均等にバランスをとろうとするストアドプロシージャを使用します(このアイデアの背後にあるインスピレーションについては、SQLCATガイド:リレーショナルエンジンの189〜191ページを参照してください)。
- ドキュメントで警告されているように、グローバルトレースフラグ2467および2469を有効にします
- バックグラウンド列ストア圧縮タスク –とにかく最後に再構築することを計画していたので、これを人口の間に実行させるのは無駄でした。今回は:
- グローバルトレースフラグ634を使用してこのタスクを無効にします
初期のパーティション関数とスキームを廃止し、データのより均等な分散に基づいて新しいパーティションを構築しました。使用する予定の「貧乏人の並列処理」を最大化するために、8つのパーティションをコアの数とデータファイルの数に一致させたいと思います。
まず、それぞれが独自のファイルを持つ新しいファイルグループのセットを作成する必要があります。
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
次に、テーブルの行数3,754,965,954を確認しました。それらを正確に配布するには 8つのパーティションに均等に分散すると、パーティションあたり469,370,744.25行になります。うまく機能させるために、パーティションの境界を nextに対応させるようにしましょう。 1,048,576行の倍数。これは1,048,576x 448 =469,762,048です –これは、最初の7つのパーティションで取得する行数であり、最後のパーティションに466,631,618行が残ります。実際のOIDを確認するには 各パーティションに最適な行数を含めるための境界として機能する値を使用して、元のテーブルに対してこのクエリを実行しました(実行に25分かかったため、これらの結果を別のテーブルにダンプすることをすぐに学びました):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
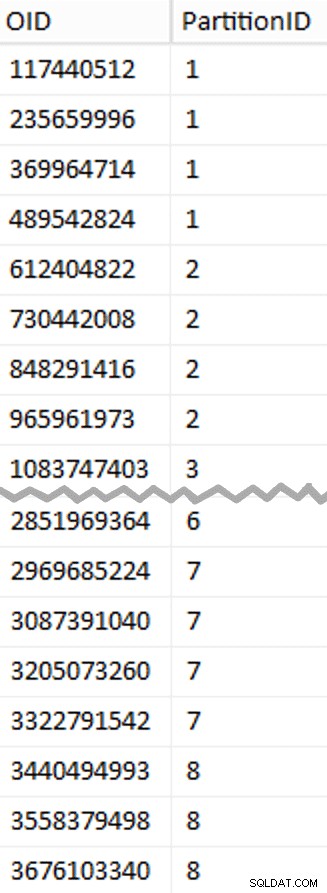 ここで予想以上に開梱します。 CTEは、1.14 TBのテーブル全体をスキャンし、すべての行に行番号を割り当てる必要があるため、すべての面倒な作業を行います。 。
ここで予想以上に開梱します。 CTEは、1.14 TBのテーブル全体をスキャンし、すべての行に行番号を割り当てる必要があるため、すべての面倒な作業を行います。 。 (1048576 * 112)番目ごとにのみ返したい ただし、これらは私のバッチ境界行であるため、これが WHEREです。 節はありません。一度に1億行に近いバッチに作業を分割したいのですが、1回のショットで4億6900万行を処理したくないことも覚えておいてください。したがって、データを8つのパーティションに分割することに加えて、これらの各パーティションを117,440,512 (1,048,576 * 112)の4つのバッチに分割したいと思います。 行。 4つのバッチの隣接する各セットは1つのパーティションに属しているため、 PartitionID 現在の行番号integerの結果に1を加算するだけです。 (1,048,576 * 448)で割った値 、これにより、境界が常に「左」セットにあることが保証されます。次に、結果に1を追加します。そうしないと、0ベースのパーティションのコレクションを参照することになり、誰もそれを望まないからです。
わかりました、それはたくさんの言葉でした。右側は、 stage の(省略された)コンテンツを示す写真です。 表(クリックして完全な結果を表示し、パーティション境界値を強調表示します)。
次に、そのステージングテーブルから別のクエリを導出して、各パーティション内の各バッチの最小値と最大値、および考慮されていない追加のバッチ( OID > 上限値よりも大きい):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); これらの値は次のようになります:
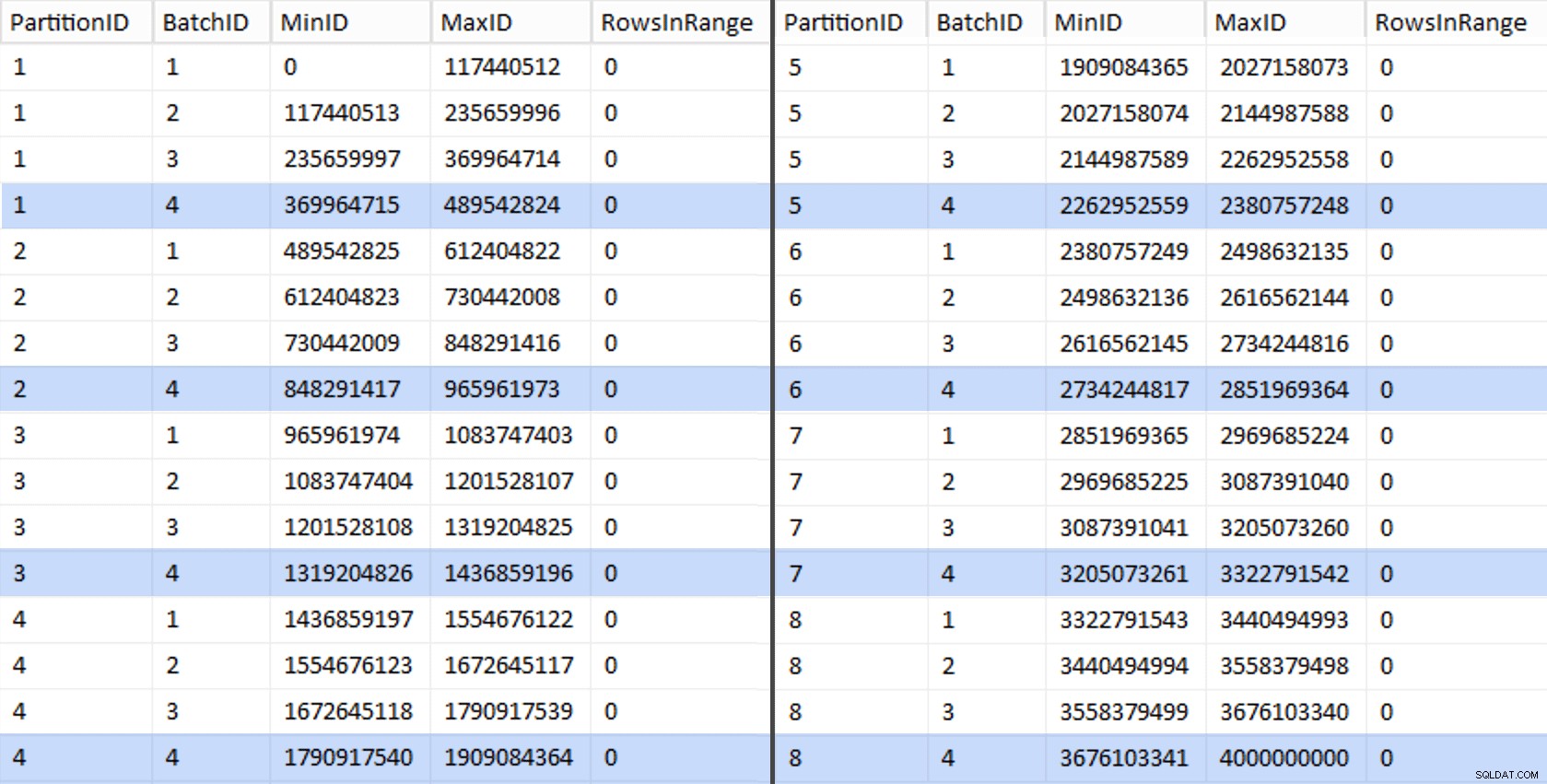
作業をテストするために、そこから<コードを更新する一連のクエリを導出できます。> BatchQueue テーブルからの実際の行数を使用します。
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; これは私のシステムでは約6分かかりました。次に、次のクエリを実行して、最後のバッチを除くすべてのバッチが行グループに完全に入力でき、潜在的なデルタストアの使用のために余りを残さないことを示すことができます。
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
これで、テーブルは次のようになります。
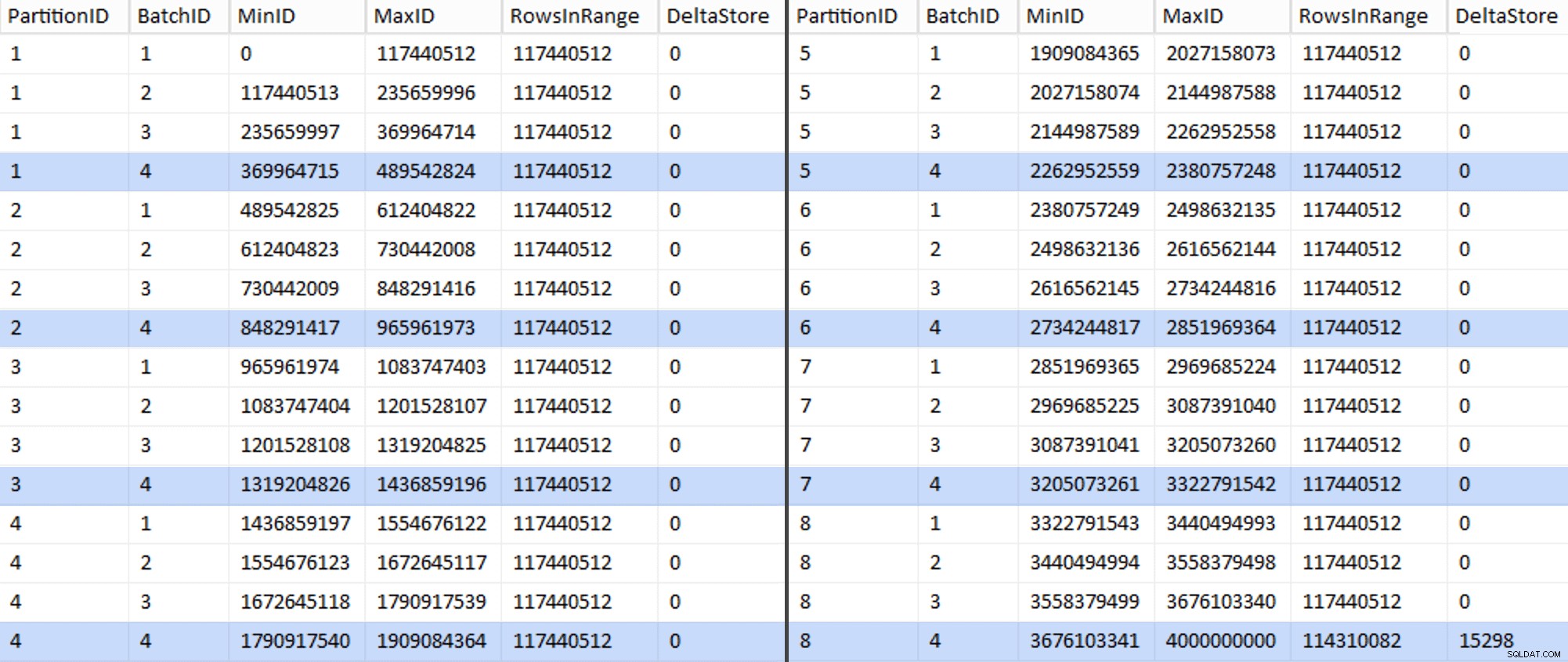
案の定、すべてのバッチには、計算された117,440,512百万行があります。ただし、最後の行には、少なくとも理想的には、非圧縮のデルタストアのみが含まれます。 このパーティションのバッチサイズをわずかに変更することで、これも防ぐことができます 4つのバッチすべてが同じサイズで実行されるようにするか、バッチ数を変更して、102,400または1,048,576の他の倍数に対応します。新しいOIDを取得する必要があるため ベーステーブルの値に加えて、移行作業にさらに25分を追加して、この1つの不完全なパーティションをスライドさせます。特に、アーカイブ圧縮のメリットを十分に享受できないためです。
BatchQueue テーブルは、バッチを処理してデータを新しいパーティション化されたクラスター化された列ストアテーブルに移行するのに役立つ兆候を示し始めています。境界がわかったので、これを作成する必要があります。境界は7つしかないので、これは手動で行うこともできますが、動的SQLに作業を任せるのが好きです:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; 結果:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
それが作成されたら、パーティションスキームを作成し、連続する各パーティションを専用ファイルに割り当てることができます。
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
これで、テーブルを作成して移行の準備をすることができます:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
パート3では、 BatchQueueをさらに構成します。 テーブルを作成し、データを新しい構造にプッシュするプロセスの手順を作成し、結果を分析します。
[パート1|パート2|パート3]