[パート1|パート2|パート3]
最近、職場の誰かが、急速に成長するテーブルを収容するために、より多くのスペースを要求しました。当時は37億5000万行で、1億4300万ページに表示され、約1.14TBを占めていました。もちろん、テーブルにはいつでもより多くのディスクを投入できますが、これを現在の線形トレンドよりも効率的にスケーリングできるかどうかを確認したいと思いました。圧縮には素晴らしい仕事のようですね。しかし、私はまた、列ストアを含む他のいくつかのソリューションを試してみたかったのですが、人々は驚くほど試してみたがりません。私はニコではありませんが、ここで何ができるかを確認するために努力したいと思いました。
現時点では、ワークロードやその他の読み取りクエリのパフォーマンスの報告に重点を置いていないことに注意してください。このデータのストレージ(およびメモリ)フットプリントにどのような影響があるかを確認したいだけです。
これが元のテーブルです。罪のない人を保護するためにテーブルと列の名前を変更しましたが、それ以外はすべて比較的正確です。
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
numeric(24,12)のように、本来あるべき幅よりも広い、および/または行の圧縮がクリーンアップされる可能性のある他の小さなものがいくつかあります。 およびbigint 列のサイズが早すぎる可能性がありますが、アプリケーションチームに戻って効率がほとんどないかどうかを判断するつもりはありません。この演習では行の圧縮をスキップし、ページと列ストアの圧縮に焦点を当てます。
これは、十分なディスク容量(6TBをはるかに超える)を備えたアイドル状態のサーバー(8コア、64GB RAM)上のデータのコピーです。まず、いくつかのファイルグループを追加しましょう。1つは標準のクラスター化された列ストア用で、もう1つはテーブルのパーティションバージョン用です(最新のパーティションを除くすべてがCOLUMNSTORE_ARCHIVEで圧縮されます。 、古いデータはすべて「読み取り専用でまれにしか使用されない」ため):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
そして、これらのファイルグループのいくつかのファイル(コアごとに1つのファイル、256 GBで均一なサイズ):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
この特定のハードウェア(YMMV!)では、ファイルごとに約10秒かかり、次のようになりました。
パーティションを生成するために、私はデータを「均等に」素朴に分割しました–またはそう思いました。私は37億5000万行を取得し、管理しやすいと思われるものに分割しました。最初の37パーティションに1億行、最後のパーティションに残りの38パーティションがあります。 (これはパート1にすぎないことを忘れないでください!ここには、ソーステーブルの値の均等な分散、および宛先テーブルの行グループの作成に最適なものについての固有の仮定があります。)このためのパーティションスキーマと関数の作成は次のとおりです。次のとおりです:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
RANGE LEFTを使用しています カトリーヌ・ウィルヘルムセンが私に思い出させてくれるように、これは境界値がその左側のパーティションの一部であることを意味するからです。言い換えると、私が指定している値は、各パーティションの最大値です(日付を指定すると、通常はRANGE RIGHTが必要です。 。
次に、各ファイルグループに1つずつ、テーブルの2つのコピーを作成しました。最初のものは標準のクラスター化された列ストアインデックスを持っていましたが、唯一の違いはOIDです。 列はIDENTITYではありません 計算された列は単なるvarbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
2つ目はパーティションスキームに基づいて構築されているため、最初に名前付きPKが必要であり、次にクラスター化列ストアインデックスに置き換える必要がありました(ただし、Brent Ozarはこの短い投稿で、これをより少ない手順で実現する直感的でない構文があることを示しています):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);を作成します。
次に、最後のパーティションを除くすべてのパーティションにアーカイブ圧縮を適用するために、次のコマンドを実行しました。
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); これで、これらのテーブルにデータを入力し、かかった時間と結果のサイズを測定して、比較する準備ができました。 Andy Mallonの便利なバッチ処理スクリプトを変更し、バッチサイズが1,000万行になるように、両方のテーブルに行を順番に挿入しました。実際のスクリプトにはこれ以上のものがあります(進行状況に応じてキューテーブルを更新することを含む)が、基本的には次のとおりです。
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END 元の(圧縮されていない)ソースから両方の列ストアテーブルにデータを入力した後、それらのパーティションを再構築して、行グループと辞書の混乱をクリーンアップしました。最後に、ソーステーブルにページ圧縮を適用しました。各タイプのタイミングと圧縮結果は次のとおりです。
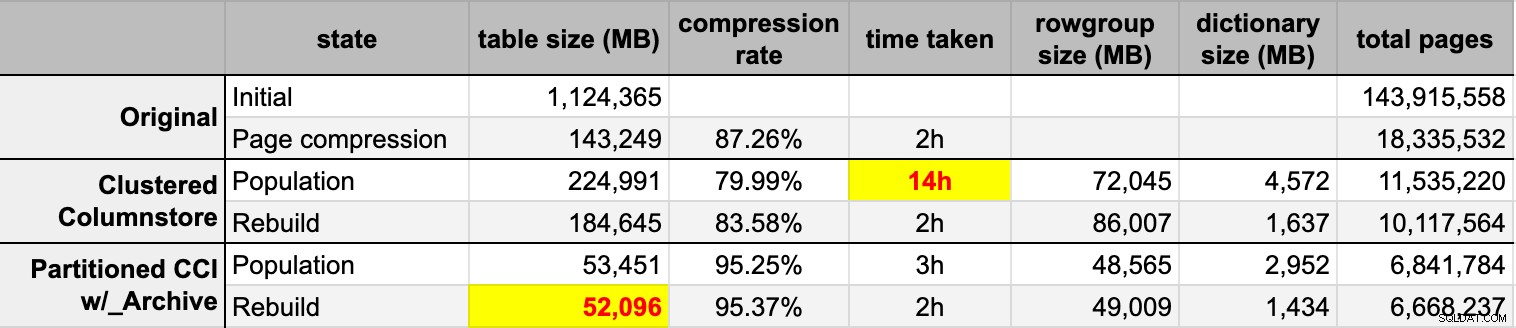
私は感銘を受け、失望しています。このデータは非常によく圧縮されているので感銘を受けました –ストレージのフットプリントを元の1TBの5%に縮小することは、驚くべきことです。がっかりした理由:
- これらのデータファイルを方法で作成しました 大きすぎる。
- 14時間の最初の列ストア圧縮で何が起こったのかわかりません:
- メモリやログのプレッシャーは観察されませんでした。
- ファイルの増加イベントはありませんでした。
- 残念ながら、待機を追跡することは考えていませんでした。いいえ、もう一度試すつもりはありません。 :-)
- ページ圧縮は、おそらくデータが原因で、通常の列ストア圧縮を上回りました。
- 列ストアアーカイブパーティションを再構築すると、多くのCPU時間が消費され、ゲインはほぼゼロになりました。
今後の投稿で、PASSサミットでのJoe Obbishによる素晴らしいコラムストアプレゼンテーションからのメモを確認した後(PASSだけがUIの方法を知っていれば、直接リンクします)、変更点について少し話します。サーバー構成とポピュレーションスクリプトを作成して、列ストアポピュレーションからより良いパフォーマンスを得ることができるかどうかを確認します。
[パート1|パート2|パート3]