NULL処理は、SQLを使用したデータモデリングとデータ操作の難しい側面の1つです。 NULLとは何かを正確に説明しようとするという事実から始めましょう。 それ自体は些細なことではありません。関係理論とSQLをよく理解している人でも、データベースでNULLを使用することに賛成と反対の両方で非常に強い意見を聞くことができます。好むと好まざるとにかかわらず、データベースプラクティショナーとしては、多くの場合、それらに対処する必要があります。NULLは、SQLコードの記述を複雑にするため、それらをよく理解することを優先することをお勧めします。このようにして、不要なバグや落とし穴を回避できます。
この記事は、NULLの複雑さに関するシリーズの最初の記事です。まず、NULLとは何か、およびそれらが比較でどのように動作するかについて説明します。次に、さまざまな言語要素でのNULL処理の不整合について説明します。最後に、T-SQLでのNULL処理に関連する不足している標準機能について説明し、T-SQLで使用できる代替機能を提案します。
カバレッジのほとんどは、SQLの方言を実装するすべてのプラットフォームに関連していますが、場合によっては、T-SQLに固有の側面について言及します。
私の例では、TSQLV5というサンプルデータベースを使用します。このデータベースを作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
欠落値のマーカーとしてのNULL
NULLとは何かを理解することから始めましょう。 SQLでは、NULLは欠落している値のマーカーまたはプレースホルダーです。これは、特定の属性値が存在する場合と欠落している場合がある現実をデータベースで表現しようとするSQLの試みです。たとえば、従業員データをEmployeesテーブルに格納する必要があるとします。名、ミドルネーム、姓の属性があります。 firstname属性とlastname属性は必須であるため、NULLを許可しないものとして定義します。ミドルネーム属性はオプションであるため、NULLを許可するように定義します。
リレーショナルモデルが欠落している値について何を言っているのか疑問に思っている場合は、モデルの作成者であるエドガーF.コッドがそれらを信じていました。実際、彼は2種類の欠落値を区別していました。欠落しているが適用可能(A値マーカー)と欠落しているが適用不可能(I値マーカー)です。ミドルネーム属性を例にとると、従業員がミドルネームを持っているが、プライバシー上の理由から情報を共有しないことを選択した場合は、A値マーカーを使用します。従業員にミドルネームがまったくない場合は、I-Valuesマーカーを使用します。ここでは、まったく同じ属性が関連性があり、存在する場合もあれば、欠落しているが適用可能である場合もあれば、欠落しているが適用できない場合もあります。他のケースはより明確にカットでき、1種類の欠落値のみをサポートします。たとえば、注文の発送日を保持するshippeddateという属性を持つOrdersテーブルがあるとします。発送された注文には、常に現在の関連する発送日があります。出荷日がわからない場合は、まだ出荷されていない注文の場合のみです。したがって、ここでは、関連する出荷日値が存在するか、I値マーカーを使用する必要があります。
SQLの設計者は、適用可能な欠落値と適用不可能な欠落値の区別をしないことを選択し、あらゆる種類の欠落値のマーカーとしてNULLを提供しました。ほとんどの場合、SQLは、NULLが欠落しているが適用可能な種類の欠落値を表すと想定するように設計されています。したがって、特にNULLを適用できない値のプレースホルダーとして使用する場合、デフォルトのSQLNULL処理は正しいと思われるものではない可能性があります。場合によっては、正しいものと見なす処理を取得するために、明示的なNULL処理ロジックを追加する必要があります。
ベストプラクティスとして、属性がNULLを許可しないことがわかっている場合は、列定義の一部としてNOTNULL制約を使用して属性を適用するようにしてください。これにはいくつかの重要な理由があります。理由の1つは、これを強制しないと、ある時点でNULLが発生するためです。これは、アプリケーションのバグまたは不正なデータのインポートの結果である可能性があります。制約を使用すると、NULLがテーブルに到達することは決してないことがわかります。もう1つの理由は、オプティマイザーがNOT NULLなどの制約を評価して最適化を改善し、NULLを探す不要な作業を回避し、特定の変換ルールを有効にすることです。
NULLを含む比較
NULLが関係している場合、SQLによる述語の評価にはいくつかの注意が必要です。まず、定数に関する比較について説明します。後で、変数、パラメータ、列に関する比較について説明します。
WHERE、ON、HAVINGなどのクエリ要素でオペランドを比較する述語を使用する場合、比較の結果は、いずれかのオペランドがNULLになる可能性があるかどうかによって異なります。どのオペランドもNULLにできないことが確実にわかっている場合、述語の結果は常にTRUEまたはFALSEになります。これは、2値述語論理、または簡単に言えば、単に2値論理として知られているものです。これは、たとえば、NULLを許可しないと定義されている列を他のNULL以外のオペランドと比較する場合に当てはまります。
比較のオペランドのいずれかがNULLである可能性がある場合、たとえば、等式(=)演算子と不等式(<>、>、<、> =、<=など)演算子の両方を使用してNULLを許可する列の場合、次のようになります。現在、3値述語論理に翻弄されています。特定の比較で、2つのオペランドがたまたまNULL以外の値である場合でも、結果としてTRUEまたはFALSEのいずれかが得られます。ただし、オペランドのいずれかがNULLの場合、UNKNOWNと呼ばれる3番目の論理値を取得します。 2つのNULLを比較する場合でもそうなることに注意してください。 SQLのほとんどの要素によるTRUEとFALSEの扱いは、非常に直感的です。 UNKNOWNの扱いは、必ずしも直感的ではありません。さらに、SQLの要素が異なれば、不明なケースの処理も異なります。これについては、後の記事「NULL処理の不整合」で詳しく説明します。
例として、TSQLV5サンプルデータベースのSales.Ordersテーブルにクエリを実行し、2019年1月2日に出荷された注文を返す必要があるとします。次のクエリを使用します。
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
出荷日が2019年1月2日の行について、フィルター述語がTRUEと評価され、それらの行が返される必要があることは明らかです。また、出荷日は存在するが2019年1月2日ではない行について、述語がFALSEと評価されること、およびそれらの行を破棄する必要があることも明らかです。しかし、出荷日がNULLの行はどうでしょうか。オペランドのいずれかがNULLの場合、等式ベースの述語と不等式ベースの述語の両方がUNKNOWNを返すことに注意してください。 WHEREフィルターは、そのような行を破棄するように設計されています。 WHEREフィルターは、フィルター述語がTRUEと評価される行を返し、述語がFALSEまたはUNKNOWNと評価される行を破棄することを覚えておく必要があります。
このクエリは次の出力を生成します:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
2019年1月2日に出荷されなかった注文を返品する必要があるとします。あなたに関する限り、まだ出荷されていない注文は出力に含まれることになっています。最後と同様のクエリを使用しますが、次のように述語のみを否定します:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
このクエリは次の出力を返します:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
出力は当然、出荷日が2019年1月2日の行を除外しますが、出荷日がNULLの行も除外します。ここで直感に反する可能性があるのは、NOT演算子を使用して、UNKNOWNと評価される述語を否定したときに何が起こるかです。明らかに、NOT TRUEはFALSEであり、NOTFALSEはTRUEです。ただし、NOTUNKNOWNはUNKNOWNのままです。この設計の背後にあるSQLの論理は、命題が真であるかどうかがわからない場合、命題が真であるかどうかもわからないということです。これは、フィルター述語で等式および不等式演算子を使用する場合、述語の正の形式も負の形式もNULLを含む行を返さないことを意味します。
この例は非常に単純です。サブクエリを含むトリッキーなケースがあります。サブクエリでNOTIN述語を使用すると、サブクエリが戻り値の中でNULLを返す場合によくあるバグがあります。クエリは常に空の結果を返します。その理由は、述語の正の形式(IN部分)は、外部値が見つかった場合はTRUEを返し、NULLとの比較のために見つからなかった場合はUNKNOWNを返すためです。次に、NOT演算子を使用して述語を否定すると、常にそれぞれFALSEまたはUNKNOWNが返されますが、TRUEにはなりません。このバグについては、T-SQLのバグ、落とし穴、およびベストプラクティス(提案されたソリューション、最適化の考慮事項、ベストプラクティスを含むサブクエリ)で詳しく説明します。この古典的なバグにまだ精通していない場合は、この記事を確認してください。バグは非常に一般的であり、回避するための簡単な対策があります。
必要に応じて、異なる(<>)演算子を使用して、2019年1月2日とは異なる出荷日で注文を返品しようとするとどうでしょうか。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
残念ながら、オペランドのいずれかがNULLの場合、等式演算子と不等式演算子の両方でUNKNOWNが生成されるため、このクエリは、NULLを除いて、前のクエリと同様に次の出力を生成します。
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
2種類の演算子の等式、不等式、および否定を使用してUNKNOWNを生成するNULLとの比較の問題を分離するために、次のすべてのクエリは空の結果セットを返します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
SQLによると、何かがNULLに等しいか、NULLと異なるかどうかを確認するのではなく、特別な演算子ISNULLとISNOT NULLをそれぞれ使用して、何かがNULLであるかNULLでないかを確認する必要があります。これらの演算子は2値論理を使用し、常にTRUEまたはFALSEを返します。たとえば、IS NULL演算子を使用して、次のように未発送の注文を返します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
このクエリは次の出力を生成します:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
次のように、IS NOT NULL演算子を使用して、出荷された注文を返します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
このクエリは次の出力を生成します:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
次のコードを使用して、2019年1月2日とは異なる日付に発送された注文と、未発送の注文を返品します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
このクエリは次の出力を生成します:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
シリーズの後半では、DISTINCT述語など、現在T-SQLにないNULL処理の標準機能について説明します。 、NULL処理を大幅に簡素化する可能性があります。
変数、パラメーター、列との比較
前のセクションでは、列を定数と比較する述語に焦点を当てました。ただし、実際には、ほとんどの場合、列を変数/パラメーターまたは他の列と比較します。このような比較には、さらに複雑さが伴います。
NULL処理の観点からは、変数とパラメーターは同じように扱われます。例では変数を使用しますが、変数の処理について私が指摘する点は、パラメーターにも同様に関連しています。
次の基本的なクエリ(クエリ1と呼びます)について考えてみます。これは、特定の日に出荷された注文をフィルタリングします。
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
この例では変数を使用し、サンプルの日付で初期化しますが、これもストアドプロシージャまたはユーザー定義関数のパラメーター化されたクエリである可能性があります。
このクエリを実行すると、次の出力が生成されます。
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
クエリ1の計画を図1に示します。
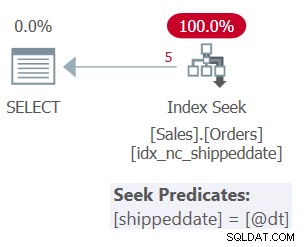 図1:クエリ1の計画
図1:クエリ1の計画
テーブルには、このクエリをサポートするためのカバーインデックスがあります。インデックスはidx_nc_shippeddateと呼ばれ、キーリスト(shippeddate、orderid)で定義されます。クエリのフィルタ述語は、検索引数(SARG)として表されます。 、これは、オプティマイザがサポートインデックスにシーク操作を適用することを検討し、修飾行の範囲に直接進むことを可能にすることを意味します。フィルタ述語をSARGableにするのは、インデックス内の修飾行の連続範囲を表す演算子を使用し、フィルタリングされた列に操作を適用しないことです。取得したプランは、このクエリに最適なプランです。
しかし、ユーザーが未発送の注文を要求できるようにするにはどうすればよいでしょうか。このような注文の出荷日はNULLです。入力日としてNULLを渡す試みは次のとおりです。
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
すでにご存知のように、等式演算子を使用する述語は、オペランドのいずれかがNULLの場合にUNKNOWNを生成します。したがって、このクエリは空の結果を返します:
orderid shippeddate ----------- ----------- (0 rows affected)
T-SQLはISNULL演算子をサポートしていますが、明示的なIS
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
このクエリは正しい出力を生成します:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
ただし、図2に示すように、このクエリの計画は最適ではありません。
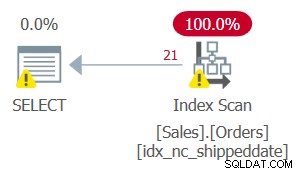 図2:クエリ2の計画
図2:クエリ2の計画
フィルターされた列に操作を適用したため、フィルター述部はSARGとは見なされなくなりました。インデックスはまだカバーされているので、使用できます。ただし、インデックスにシークを適用して、対象となる行の範囲に直接移動する代わりに、インデックスリーフ全体がスキャンされます。テーブルに50,000,000の注文があり、未出荷の注文は1,000のみであるとします。このプランでは、対象となる1,000行に直接移動するシークを実行する代わりに、50,000,000行すべてをスキャンします。
フィルタ述語の1つの形式は、どちらも後の正しい意味を持ち、検索引数と見なされます(shippeddate =@dt OR(shippeddate IS NULL AND @dt IS NULL))。このSARGable述語を使用したクエリは次のとおりです(これをクエリ3と呼びます):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
このクエリの計画を図3に示します。
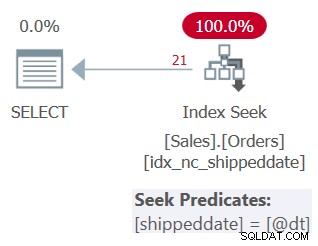 図3:クエリ3の計画
図3:クエリ3の計画
ご覧のとおり、この計画では、サポートインデックスにシークが適用されます。シーク述語はshippeddate=@dtと言いますが、比較のためにNULL以外の値と同じようにNULLを処理するように内部的に設計されています。
このソリューションは、一般的に妥当なソリューションと見なされます。それは標準的で、最適で、正しいものです。その主な欠点は、冗長であるということです。 NULL可能列に基づく複数のフィルター述部がある場合はどうなりますか?すぐに長くて面倒なWHERE句になってしまいます。また、列が入力パラメーターと異なる行を検索するNULL可能列を含むフィルター述語を作成する必要がある場合は、さらに悪化します。述語は次のようになります:(shippeddate <> @dt AND((shippeddate IS NULL AND @dt IS NOT NULL)OR(shippeddate IS NOT NULL and @dt IS NULL)))。
簡潔で最適な、よりエレガントなソリューションの必要性を明確に理解できます。残念ながら、ANSI_NULLSセッションオプションをオフにする非標準のソリューションに頼る人もいます。このオプションにより、SQL Serverは、3値論理ではなく2値論理で等式(=)および異なる(<>)演算子の非標準処理を使用し、比較のためにNULLを非NULL値と同じように扱います。少なくとも、オペランドの1つがパラメーター/変数またはリテラルである限り、そうです。
次のコードを実行して、セッションでANSI_NULLSオプションをオフにします。
SET ANSI_NULLS OFF;
単純な等式ベースの述語を使用して、次のクエリを実行します。
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
このクエリは、21個の未出荷の注文を返します。図3で前に示したのと同じ計画が得られ、インデックスのシークが示されます。
次のコードを実行して、ANSI_NULLSがオンになっている標準の動作に戻します。
SET ANSI_NULLS ON;
このような非標準的な動作に依存することは強くお勧めしません。ドキュメントには、このオプションのサポートがSQLServerの将来のバージョンで削除されることも記載されています。さらに、多くの人は、ドキュメントが非常に明確であっても、このオプションがオペランドの少なくとも1つがパラメータ/変数または定数である場合にのみ適用可能であることを認識していません。結合など、2つの列を比較する場合は適用されません。
では、両側がNULLの場合に一致を取得したい場合、NULL可能な結合列を含む結合をどのように処理しますか?例として、次のコードを使用して、テーブルT1およびT2を作成してデータを入力します。
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
このコードは、両側の結合キー(k1、k2、k3)に基づく結合をサポートするために、両方のテーブルにカバーインデックスを作成します。
次のコードを使用してカーディナリティ統計を更新し、数値を膨らませて、オプティマイザーがより大きなテーブルを処理していると見なすようにします。
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
単純な等式ベースの述語を使用して2つのテーブルを結合するには、次のコードを使用してください。
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; 以前のフィルタリングの例と同様に、ここでも、等式演算子を使用したNULL間の比較では、UNKNOWNが生成され、不一致が発生します。このクエリは空の出力を生成します:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
前のフィルタリングの例のようにISNULLまたはCOALESCEを使用して、NULLを両側のデータに通常は表示できない値に置き換えると、正しいクエリが生成されます(このクエリをクエリ4と呼びます):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); このクエリは次の出力を生成します:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
ただし、フィルター処理された列を操作するとフィルター述部のSARGabilityが壊れるのと同じように、結合列を操作すると、インデックスの順序に依存できなくなります。これは、図4に示すように、このクエリの計画で確認できます。
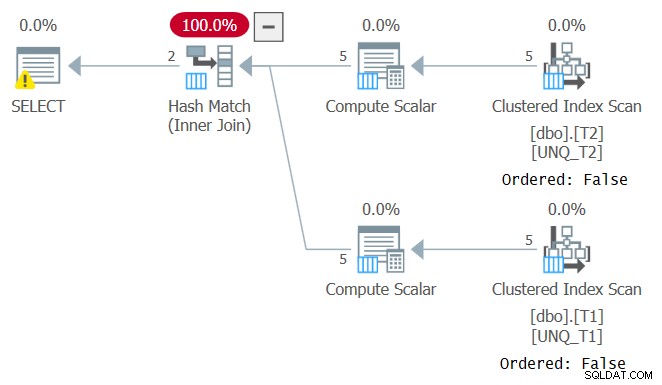 図4:クエリ4の計画
図4:クエリ4の計画
このクエリの最適な計画は、明示的な並べ替えを行わずに、2つのカバーするインデックスの順序付きスキャンとそれに続くマージ結合アルゴリズムを適用する計画です。オプティマイザーは、インデックスの順序に依存できないため、別のプランを選択しました。 INNER MERGEJOINを使用してMergeJoinアルゴリズムを強制しようとした場合でも、プランはインデックスの順序付けされていないスキャンに依存し、その後に明示的な並べ替えが続きます。試してみてください!
もちろん、フィルタリングタスクには、前に示したSARGable述語と同様の長い述語を使用できます。
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); このクエリは目的の結果を生成し、オプティマイザがインデックスの順序に依存できるようにします。ただし、私たちの希望は、最適で簡潔なソリューションを見つけることです。
一致を識別する目的と不一致を識別する目的の両方で、結合とフィルターの両方で使用できる、あまり知られていないエレガントで簡潔な手法があります。この手法は、Paul Whiteの優れた記事「UndocumentedQueryPlans:Equality Comparisons from 2011」などですでに発見され、文書化されています。しかし、何らかの理由で、まだ多くの人がこの手法に気付いていないようで、残念ながら、最適ではなく、長く、非標準ソリューション。それは確かにより多くの露出と愛に値する。
この手法は、INTERSECTやEXCEPTなどの集合演算子が、値を比較するときに、等式または不等式ベースの比較アプローチではなく、識別性ベースの比較アプローチを使用するという事実に依存しています。
例として、参加タスクを考えてみましょう。結合キー以外の列を返す必要がない場合は、次のように、INTERSECT演算子を使用した単純なクエリ(クエリ5と呼びます)を使用します。
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
このクエリは次の出力を生成します:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
このクエリの計画を図5に示します。これは、オプティマイザがインデックスの順序に依存し、マージ結合アルゴリズムを使用できることを確認しています。
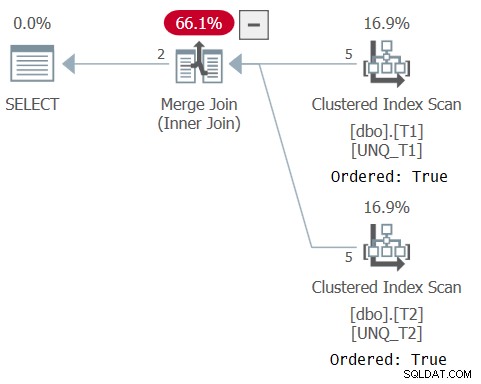 図5:クエリ5の計画
図5:クエリ5の計画
Paulが彼の記事で述べているように、set演算子のXMLプランは、暗黙のIS比較演算子( CompareOp ="IS" )を使用します。 )通常の結合で使用されるEQ比較演算子とは対照的に( CompareOp ="EQ" )。集合演算子のみに依存するソリューションの問題は、比較している列のみを返すように制限されることです。本当に必要なのは、結合と集合演算子のハイブリッドのようなものです。これにより、要素のサブセットを比較しながら、結合のように追加の要素を返し、集合演算子のように識別性ベースの比較(IS)を使用できます。これは、外部構造として結合を使用することで実現できます。また、INTERSECT演算子を使用したクエリに基づいて、結合のON句にEXISTS述語を使用し、両側から結合キーを比較します(このソリューションをクエリと呼びます)。 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
INTERSECT演算子は、2つのクエリを操作し、それぞれがいずれかの側からの結合キーに基づいて1つの行のセットを形成します。 2つの行が同じ場合、INTERSECTクエリは1つの行を返します。 EXISTS述部はTRUEを返し、一致します。 2つの行が同じでない場合、INTERSECTクエリは空のセットを返します。 EXISTS述語はFALSEを返し、不一致になります。
このソリューションは、目的の出力を生成します:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
このクエリの計画を図6に示します。これは、オプティマイザがインデックスの順序に依存できたことを確認するものです。
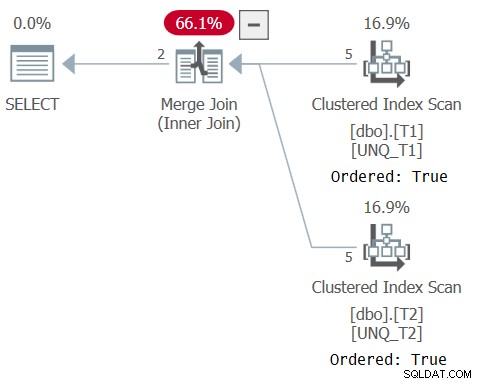 図6:クエリ6の計画
図6:クエリ6の計画
次のように、列とパラメーター/変数を含むフィルター述語と同様の構造を使用して、区別に基づいて一致を検索できます。
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
計画は、前に図3に示したものと同じです。
次のように、述語を否定して不一致を探すこともできます。
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
このクエリは次の出力を生成します:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
または、正の述語を使用することもできますが、次のようにINTERSECTをEXCEPTに置き換えます。
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
2つのケースの計画は異なる可能性があることに注意してください。そのため、大量のデータを使用して両方の方法を試してください。
結論
NULLは、SQLコードの記述に複雑さの共有を追加します。データにNULLが存在する可能性について常に考え、正しいクエリ構造を使用していることを確認し、NULLを正しく処理するために関連するロジックをソリューションに追加する必要があります。それらを無視することは、コードにバグが発生する確実な方法です。今月は、定数、変数、パラメーター、および列を含む比較で、NULLとは何か、およびNULLがどのように処理されるかに焦点を当てました。来月は、さまざまな言語要素でのNULL処理の不整合、およびNULL処理の標準機能の欠落について説明することで、引き続き取り上げます。