熱心なインデックススプール 親演算子に行を返し始める前に、子演算子からインデックス付きワークテーブルにすべての行を読み取ります。いくつかの点で、熱心なインデックススプールは究極の欠落しているインデックスの提案 、ただし、そのようには報告されません。
インデックス付きの作業テーブルに行を挿入するのは比較的低コストですが、無料ではありません。オプティマイザは、関連する作業によってコスト以上の節約ができることを考慮する必要があります。それがスプールに有利に働くためには、計画はスプールからの行を複数回消費するように見積もられる必要があります。それ以外の場合は、スプールをスキップして、基礎となる操作を1回だけ実行することもできます。
- 複数回アクセスするには、ネストされたループ結合演算子の内側にスプールが表示されている必要があります。
- ループを繰り返すたびに、ループの外側から提供される特定のインデックススプールキー値を探す必要があります。
つまり、結合は適用である必要があります 、ネストされたループの結合ではありません 。 2つの違いについては、私の記事「適用とネストされたループの結合」を参照してください。
熱心なインデックススプールは、ネストされたループの内側にのみ表示される場合がありますが、適用 、「パフォーマンススプール」ではありません。熱心なインデックススプールは、トレースフラグ8690またはNO_PERFORMANCE_SPOOLでは無効にできません。 クエリのヒント。
インデックススプールに挿入された行は、通常、インデックスキーの順序で事前に並べ替えられないため、インデックスページが分割される可能性があります。文書化されていないトレースフラグ9260を使用して、並べ替えを生成できます。 これを回避するために、インデックススプールの前に演算子を配置します。欠点は、余分な並べ替えコストにより、オプティマイザがスプールオプションを選択できなくなる可能性があることです。
SQL Serverは、bツリーインデックスへの並列挿入をサポートしていません。これは、並列の熱心なインデックススプールの下にあるすべてのものが単一のスレッドで実行されることを意味します。スプールの下のオペレーターは、まだ(誤解を招くように)並列処理アイコンでマークされています。 書き込みするために1つのスレッドが選択されます スプールに。他のスレッドはEXECSYNCを待機します それが完了する間。スプールにデータが入力されると、読み取りが可能になります。 並列スレッドによる。
インデックススプールは、スプールのインデックスキーによって順序付けられた出力をサポートすることをオプティマイザに通知しません。スプールからの並べ替えられた出力が必要な場合は、不要な並べ替えが表示されることがあります。 オペレーター。熱心なインデックススプールは、とにかく永続的なインデックスに置き換える必要があることが多いため、これは多くの場合、小さな問題です。
熱心なインデックススプールを生成できる5つのオプティマイザルールがあります オプション(内部ではインデックスオンザフライとして知られています) )。熱心なインデックススプールがどこから来ているのかを理解するために、これらのうち3つを詳しく見ていきます。
SelToIndexOnTheFly
これは最も一般的なものです。これは、データアクセス演算子のすぐ上にある1つ以上のリレーショナル選択(別名フィルターまたは述語)と一致します。 SelToIndexOnTheFly ルールは、述語を熱心なインデックススプールのシーク述語に置き換えます。
AdventureWorks サンプルデータベースの例を以下に示します。
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
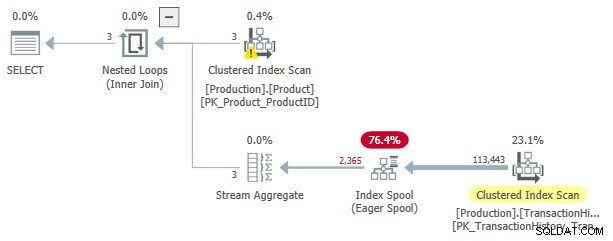
この実行プランの推定コストは3.0881です。 ユニット。いくつかの興味深い点:
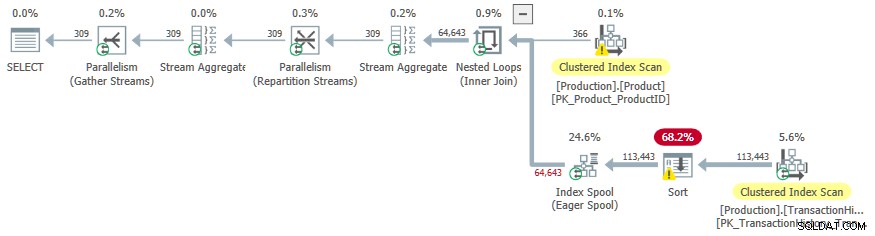
- ネストされたループの内部結合 演算子は適用です 、
ProductIDおよびSafetyStockLevelProductから 外部参照としてのテーブル 。 - 適用の最初の反復で、熱心なインデックススプール Clustered Index Scanから完全に入力されます
TransactionHistoryの テーブル。 - スプールのワークテーブルには、
(ProductID, Quantity)にキー設定されたクラスター化されたインデックスがあります 。 - 述語に一致する行
TH.ProductID = P.ProductIDおよびTH.Quantity < P.SafetyStockLevelスプールはそのインデックスを使用して応答します。これは、最初の反復を含む、適用のすべての反復に当てはまります。 -
TransactionHistoryテーブルは1回だけスキャンされます。
熱心なインデックススプールにソートされた入力を強制することは可能ですが、これは、冒頭で述べたように、推定コストに影響します。上記の例では、文書化されていないトレースフラグを有効にすると、スプールのないプランが生成されます。
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
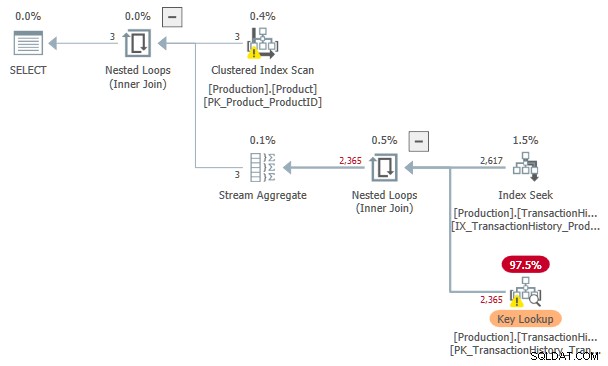
このインデックスシークの推定コスト およびキールックアップ 計画は3.11631 ユニット。これは、インデックススプールのみを使用したプランのコストよりも高くなりますが、インデックススプールとソートされた入力を使用したプランよりも低くなります。
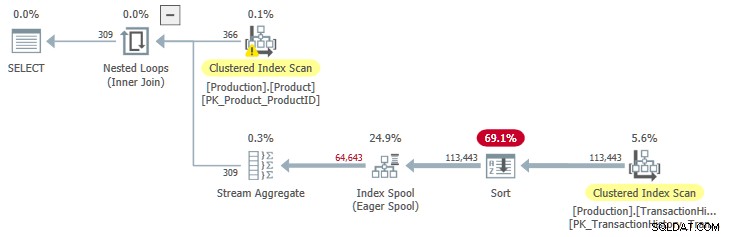
スプールへの入力がソートされたプランを表示するには、ループの反復の予想回数を増やす必要があります。これにより、スプールは並べ替えの追加費用を返済する機会が与えられます。 。 Productから期待される行数を拡張する1つの方法 テーブルはNameを作成するためのものです 制限の少ない述語:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); これにより、スプールへの入力が並べ替えられた実行プランが得られます。
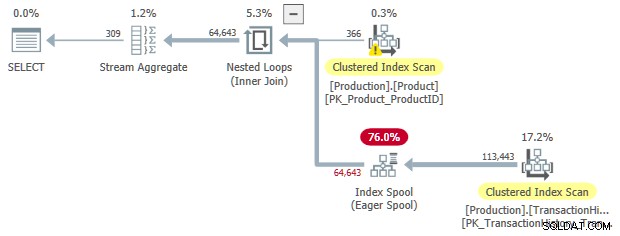
JoinToIndexOnTheFly
このルールは、内部結合を変換します 適用に 、内側に熱心なインデックススプールが付いています。このルールを一致させるには、結合述語の少なくとも1つが不等式である必要があります。
これは、SelToIndexOnTheFlyよりもはるかに特殊なルールです。 、しかし考え方はほとんど同じです。この場合、インデックススプールシークに変換される選択(述部)は結合に関連付けられます。参加から適用への変換 結合述語を結合自体から適用の内側に移動できるようにします。
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
以前と同様に、スプールへの並べ替えられた入力を要求できます:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
今回は、並べ替えの追加コストにより、オプティマイザーは並列プランを選択するようになりました。
望ましくない副作用は、並べ替えです。 オペレーターがtempdbに流出 。ソートに使用できる合計メモリ許可は十分ですが、(通常どおり)並列スレッド間で均等に分割されます。はじめに述べたように、SQL Serverはbツリーインデックスへの並列挿入をサポートしていないため、熱心なインデックススプールの下のオペレーターは単一のスレッドで実行されます。この単一のスレッドはメモリ許可の一部しか取得しないため、並べ替え tempdbに流出 。
この副作用は、トレースフラグが文書化されておらず、サポートされていない理由の1つである可能性があります。
SelSTVFToIdxOnFly
このルールは、SelToIndexOnTheFlyと同じことを行います 、ただし、ストリーミングテーブル値関数の場合 (sTVF)行ソース。これらのsTVFは、とりわけDMVおよびDMFを実装するために内部で広く使用されています。これらは、最新の実行計画ではテーブル値関数として表示されます。 演算子(元々はリモートテーブルスキャンとして) 。
これまで、これらのsTVFの多くは、apply。から相関パラメータを受け入れることができませんでした。 適用ではなく、リテラル、変数、モジュールパラメータを受け入れることができます。 外部参照。ドキュメントにはまだこれに関する警告がありますが、現在はやや古くなっています。
とにかく、重要なのは、SQLServerがapplyを渡すことができない場合があるということです。 sTVFへのパラメータとしての外部参照。そのような状況では、sTVFの結果の一部を熱心なインデックススプールに具体化することは理にかなっています。現在のルールはその能力を提供します。
次のコード例は、結合から適用に正常に変換されたDMVクエリを示しています。 。 外部参照 パラメータとして2番目のDMVに渡されます:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
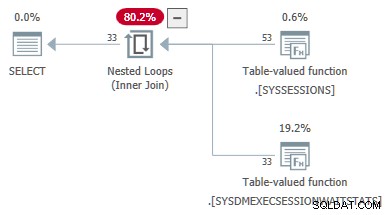
待機統計TVFの計画プロパティは、入力パラメーターを示します。 2番目のパラメータ値は外部参照として提供されます セッションから DMV:
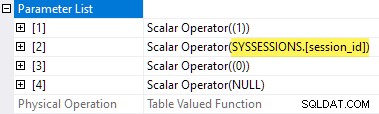
sys.dm_exec_session_wait_statsが残念です はビューであり、関数ではありません。これは、 applyを記述できないためです。 直接。
以下の書き直しは、内部転換を打ち負かすのに十分です:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
session_idを使用 述語はパラメーターとして使用されなくなりました。SelSTVFToIdxOnFly ルールはそれらを熱心なインデックススプールに自由に変換できます:
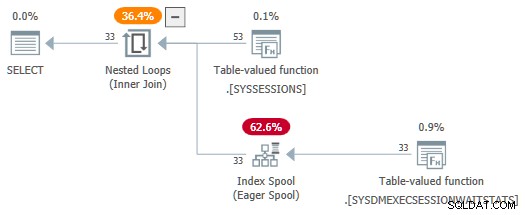
DMVソース上で熱心なインデックススプールを取得するには、トリッキーな書き直しが必要であるという印象を残したくありません。これにより、デモが簡単になります。熱心なスプールを備えたプランを生成するDMV結合を使用したクエリに遭遇した場合でも、少なくともそれがどのようにしてそこに到達したかはわかっています。
DMVにインデックスを作成することはできないため、実行プランのパフォーマンスが十分でない場合は、ハッシュまたはマージ結合を使用する必要があります。
残りの2つのルールはSelIterToIdxOnFlyです。 およびJoinIterToIdxOnFly 。これらは、SelToIndexOnTheFlyに直接対応しています。 およびJoinToIndexOnTheFly 再帰CTEデータソースの場合。これらは私の経験では非常にまれなので、デモを提供するつもりはありません。 (ちょうどそのようにIter ルール名の一部は理にかなっています。これは、SQLServerが末尾再帰をネストされた反復として実装しているという事実に由来しています。)
アプライの内部で再帰CTEが複数回参照される場合、別のルール(SpoolOnIterator )CTEの結果をキャッシュできます:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; 実行プランには、まれな Eager Row Count Spoolが含まれています。 :
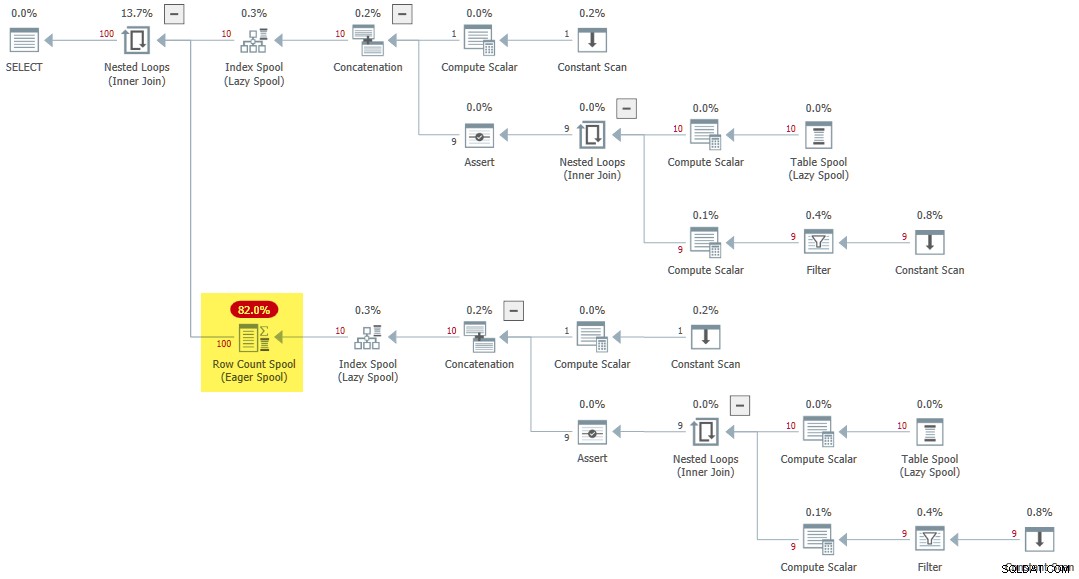
熱心なインデックススプールは、多くの場合、データベーススキーマに有用な永続インデックスがないことを示しています。ストリーミングテーブル値関数の例が示すように、これは常に当てはまるわけではありません。