MERGEについての私の意見は誰もがすでに知っていると思います そしてなぜ私はそれから離れているのですか。しかし、これは、人々がアップサートを実行したいときに私がいたるところに見られる別の(アンチ)パターンです(行が存在する場合は更新し、存在しない場合は挿入します):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
これは、実際の生活でこれについてどのように考えているかを反映した、かなり論理的なフローのように見えます。
- このキーの行はすでに存在しますか?
- はい :OK、その行を更新します。
- いいえ :OK、それから追加します。
しかし、これは無駄です。
行を見つけてそれが存在することを確認し、それを更新するためにもう一度見つける必要があるだけで、2回の作業を実行します。 何もしません。キーにインデックスが付けられている場合でも(常にそうなることを願っています)。このロジックをフローチャートに入れて、各ステップで、データベース内で発生する必要のある操作のタイプを関連付けると、次のようになります。
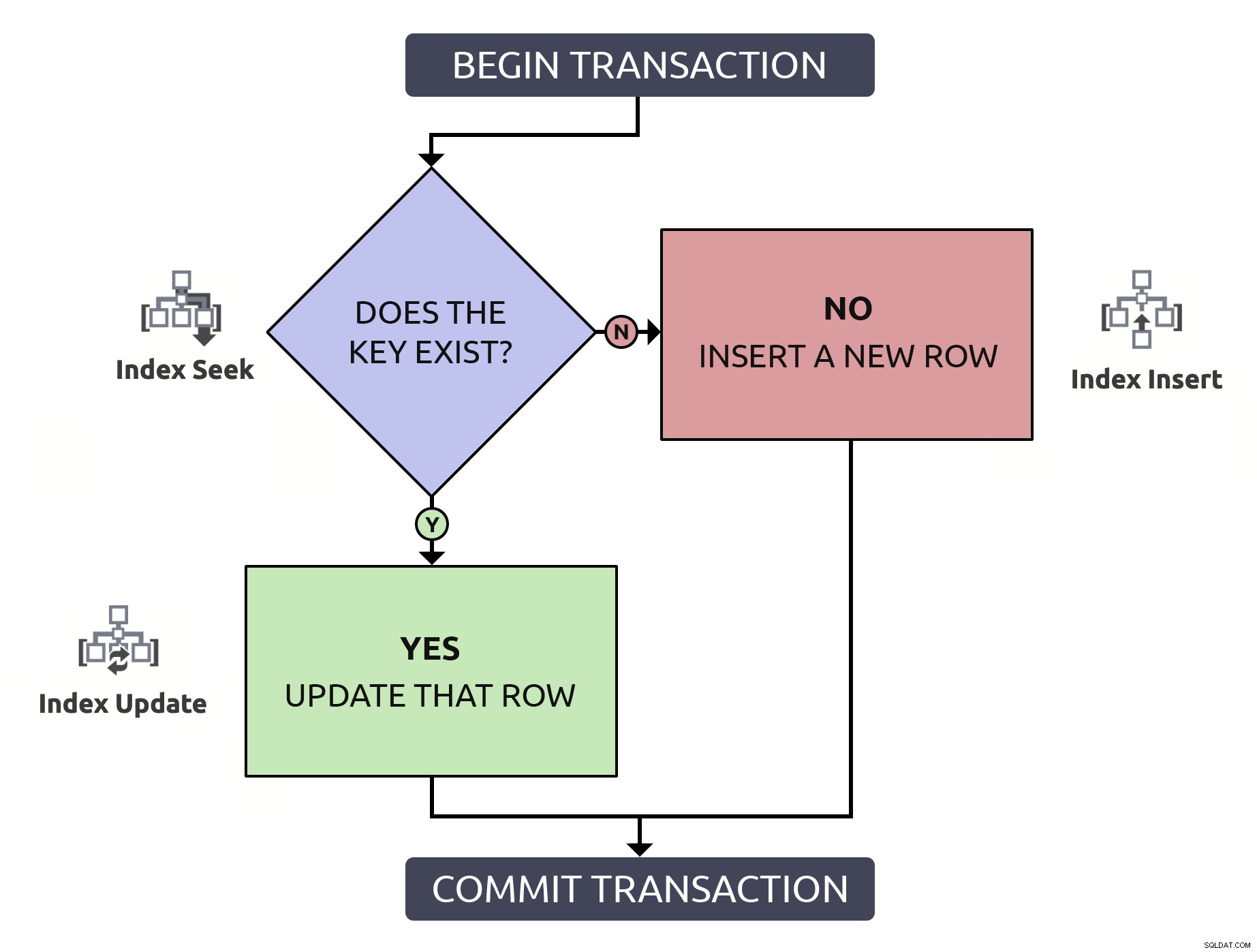
さらに重要なのは、パフォーマンスはさておき、明示的なトランザクションを使用して分離レベルを上げない限り、行がまだ存在しない場合に複数の問題が発生する可能性があります。
- キーが存在し、2つのセッションが同時に更新しようとすると、両方とも正常に更新されます (1つは「勝ち」、「敗者」はそれに続く変更に続き、「失われた更新」につながります)。これ自体は問題ではなく、すべき方法です。 並行性を備えたシステムが機能することを期待します。ポールホワイトはここで内部力学についてより詳細に話し、マーティンスミスはここで他のいくつかのニュアンスについて話します。
- キーが存在しないが、両方のセッションが同じ方法で存在チェックに合格した場合、両方が挿入しようとすると何かが発生する可能性があります。
- デッドロック 互換性のないロックのため;
- キー違反エラーを発生させる それは起こるべきではありませんでした。または、
- 重複するキー値を挿入 その列が適切に制約されていない場合。
最後の1つは、最悪のIMHOです。これは、データを破損する可能性があるためです。 。デッドロックと例外は、エラー処理、XACT_ABORTなどで簡単に処理できます。 、および衝突が予想される頻度に応じて、ロジックを再試行します。しかし、あなたが安心感に落ち着いたら、IF EXISTS チェックは重複(またはキー違反)からあなたを保護します、それは起こるのを待っている驚きです。列がキーのように機能することを期待する場合は、列を公式にして制約を追加します。
「多くの人が言っている…」
Dan Guzmanは、10年以上前に、Conditional INSERT / UPDATE Race Conditionで、その後の「UPSERT」Race ConditionWithMERGEで競合状態について話しました。
マイケル・スワートもこの主題を何度も扱ってきました:
- ミスバスティング:同時更新/挿入ソリューション–初期ロジックをそのままにして、分離レベルを上げるだけで、キー違反がデッドロックに変わったことを認めました。
- マージステートメントに注意してください–彼は
MERGEについての熱意をチェックしました;そして、 - MERGEを使用する場合の回避策–
MERGEを回避し続ける正当な理由がまだたくさんあることをもう一度確認しました。 。
3つの投稿すべてのコメントもすべて読んでください。
ソリューション
次のパターンに調整するだけで、キャリアの多くのデッドロックを修正しました(冗長チェックを破棄し、シーケンスをトランザクションでラップし、適切なロックで最初のテーブルアクセスを保護します):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
なぜ2つのヒントが必要なのですか? UPDLOCKではありません 十分ですか?
-
UPDLOCKステートメントでの変換のデッドロックから保護するために使用されます レベル(被害者に再試行を促すのではなく、別のセッションを待機させます)。 SERIALIZABLEトランザクション全体を通じて、基になるデータへの変更から保護するために使用されます (存在しない行が引き続き存在しないことを確認してください)。
これはもう少しコードですが、1000%安全であり、最悪でも ケース(行がまだ存在しない)の場合、アンチパターンと同じように機能します。最良の場合、既存の行を更新する場合は、その行を1回だけ検索する方が効率的です。このロジックをデータベースで実行する必要のある高レベルの操作と組み合わせると、少し簡単になります。
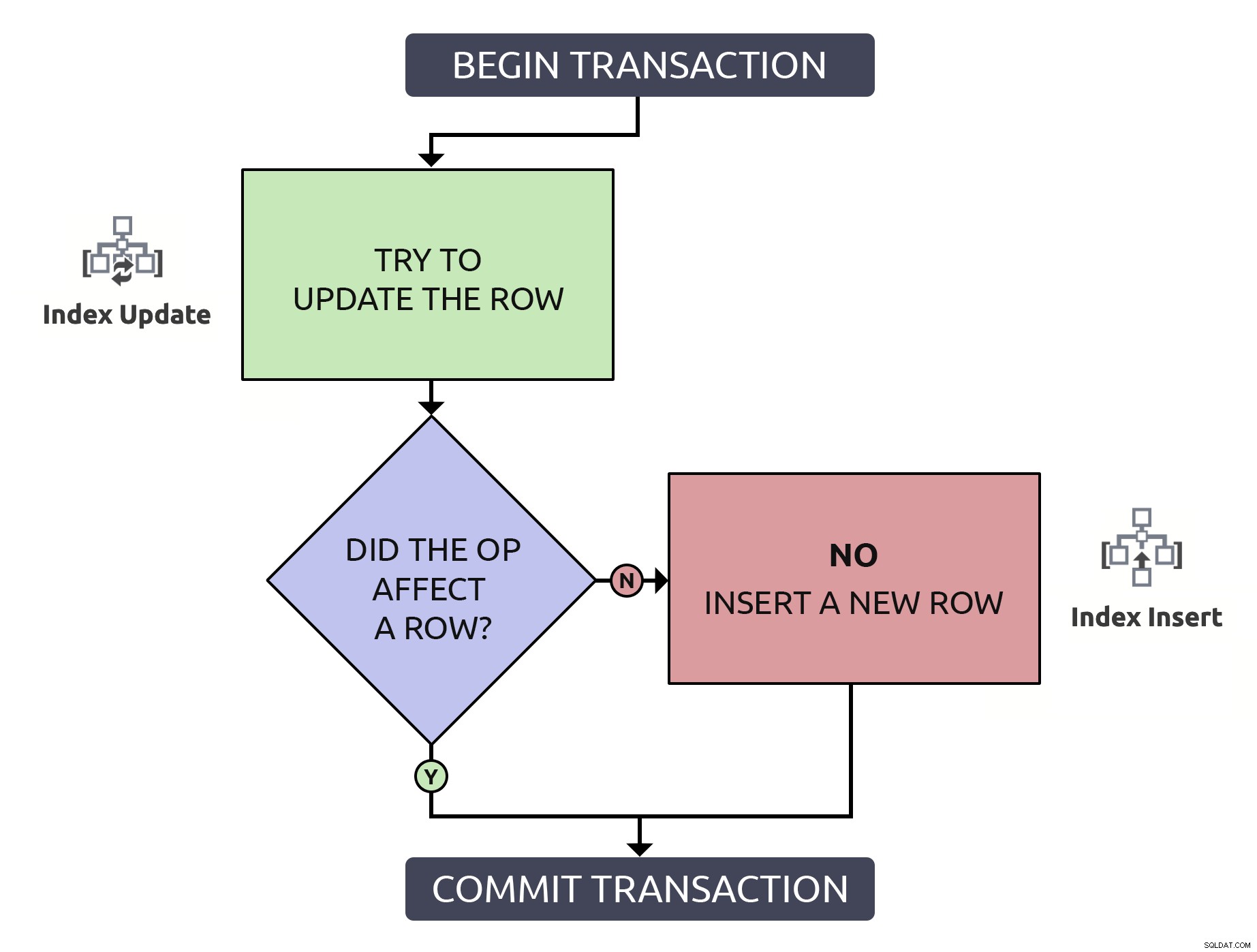 この場合、1つのパスで発生するインデックス操作は1つだけです。
この場合、1つのパスで発生するインデックス操作は1つだけです。
しかし、繰り返しになりますが、パフォーマンスはさておき:
- キーが存在し、2つのセッションが同時にキーを更新しようとすると、両方が交代で行を正常に更新します。 、以前のように。
- キーが存在しない場合、1つのセッションが「勝ち」て行を挿入します 。もう一方は待たなければなりません ロックが解除されて存在を確認し、強制的に更新されるまで。
どちらの場合も、レースに勝った作家は、その後に更新された「敗者」にデータを失います。
並行性の高いシステムでの全体的なスループットは可能性があることに注意してください。 苦しみますが、それはあなたが喜んで行うべきトレードオフです。デッドロックの犠牲者やキー違反エラーがたくさん発生しているが、それらはすぐに発生しているということは、優れたパフォーマンス指標ではありません。すべてのシナリオからすべてのブロックが削除されることを望んでいる人もいますが、データの整合性のために絶対に必要なブロックを行っている人もいます。
しかし、更新の可能性が低い場合はどうなりますか?
上記のソリューションが更新を最適化することは明らかであり、書き込もうとしているキーは、少なくとも同じ頻度でテーブルにすでに存在していると想定しています。挿入を最適化したい場合は、挿入が更新よりも可能性が高いことを知っているか推測している場合は、ロジックを反転させても安全なアップサート操作を行うことができます。
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; 「ただやる」アプローチもあります。このアプローチでは、盲目的に挿入し、衝突によって呼び出し元に例外が発生します。
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;>
これらの例外のコストは、多くの場合、最初にチェックするコストを上回ります。ヒット/ミス率を大まかに正確に推測して試してみる必要があります。これについてこことここに書きました。
複数の行をアップサートするのはどうですか?
上記はシングルトンの挿入/更新の決定を扱っていますが、Justin Pealingは、複数の行を処理しているときに、それらのどれがすでに存在するかを知らずに何をすべきかを尋ねました。
テーブル値パラメーターのようなものを使用して一連の行を送信すると仮定すると、結合を使用して更新し、NOT EXISTSを使用して挿入しますが、パターンは上記の最初のアプローチと同等です。
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END TVP(XML、コンマ区切りリスト、ブードゥー)以外の方法で複数の行をまとめる場合は、最初にそれらをテーブル形式に入れて、それが何であれ結合します。このシナリオでは、最初に挿入を最適化しないように注意してください。最適化しないと、一部の行が2回更新される可能性があります。
結論
これらのアップサートパターンは、私がよく目にするものよりも優れているので、ぜひ使い始めてください。 IF EXISTSを見つけるたびに、この投稿をポイントします 野生のパターン。そして、ちょっと、ポールホワイト(sql.kiwi | @SQK_Kiwi)への別の叫び声。彼は難しい概念を理解しやすくし、次に説明するのに非常に優れているからです。
そして、あなたがしなければならないと感じたら MERGEを使用する 、@私にしないでください。正当な理由があります(おそらく、あいまいなMERGEが必要です -機能のみ)、または上記のリンクを真剣に受け止めていませんでした。