SQL Serverでパフォーマンスの低いクエリを確認する方法は複数あります。特に、クエリストア、拡張イベント、動的管理ビュー(DMV)です。各オプションには長所と短所があります。拡張イベントはクエリの個々の実行に関するデータを提供し、クエリストアとDMVはパフォーマンスデータを集約します。クエリストアと拡張イベントを使用するには、事前にそれらを構成する必要があります。データベースでクエリストアを有効にするか、XEセッションを設定して開始します。 DMVデータはいつでも利用できるため、クエリのパフォーマンスを最初に確認するのに最も簡単な方法であることがよくあります。ここで、GlennのDMVクエリが役立ちます。彼のスクリプト内には、CPU、論理I / O、および期間に基づいてインスタンスの上位クエリを見つけるために使用できる複数のクエリがあります。リソースを最も消費するクエリをターゲットにすることは、トラブルシューティングの際に良いスタートとなることがよくありますが、「1000カットによる死」シナリオ、つまり非常に頻繁に実行されるクエリまたはクエリのセットを忘れることはできません。分。グレンのセットには、実行回数に基づいてデータベースの上位クエリを一覧表示するクエリがありますが、私の経験では、ワークロードの全体像を把握することはできません。
クエリパフォーマンスメトリックを確認するために使用される主なDMVは、sys.dm_exec_query_statsです。ストアドプロシージャ(sys.dm_exec_procedure_stats)、関数(sys.dm_exec_function_stats)、およびトリガー(sys.dm_exec_trigger_stats)に固有の追加データも利用できますが、純粋にストアドプロシージャ、関数、およびトリガーではないワークロードを検討してください。アドホッククエリがいくつかある、または完全にアドホックである混合ワークロードを検討してください。
シナリオ例
以前の投稿「アドホックワークロードのパフォーマンスへの影響の調査」からコードを借用して適合させるために、最初に2つのストアドプロシージャを作成します。最初のdbo.RandomSelectsは、アドホックステートメントを生成して実行し、2番目のdbo.SPRandomSelectsは、パラメーター化されたクエリを生成して実行します。
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO 次に、前の投稿で概説したのと同じ方法を使用して、両方のストアドプロシージャを1000回実行します。.cmdファイルは、次のステートメントで.sqlファイルを呼び出します。
Adhoc.sqlファイルの内容:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Parameterized.sqlファイルの内容:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
.sqlファイルを呼び出す.cmdファイルの構文例:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
グレンのトップワーカー時間クエリのバリエーションを使用して、ワーカー時間(CPU)に基づいてトップクエリを確認する場合:
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
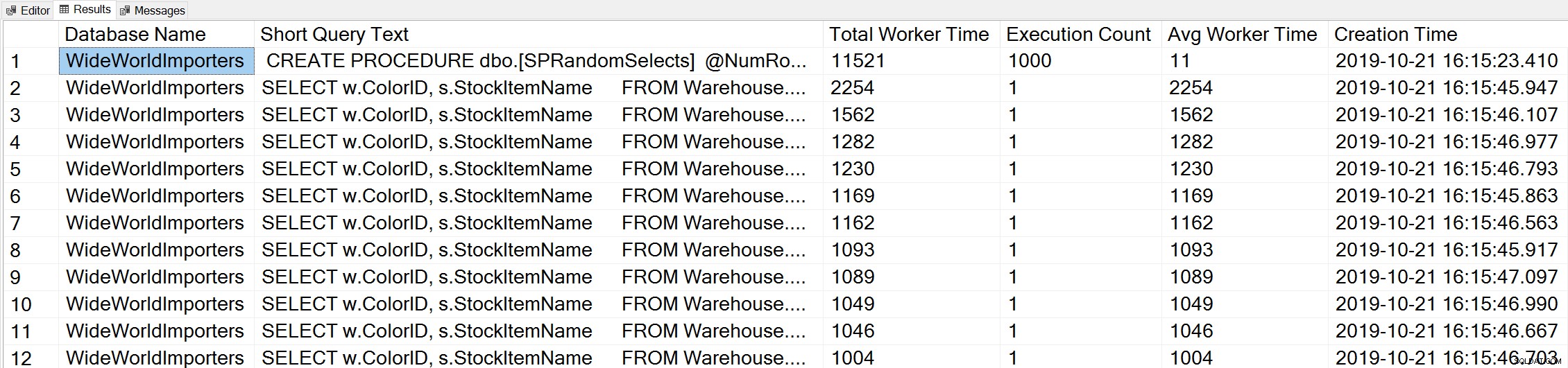
ストアドプロシージャからのステートメントは、累積CPUの最大量で実行されるクエリと見なされます。
WideWorldImportersデータベースに対してGlennのQueryExecutionCountsクエリのバリエーションを実行する場合:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
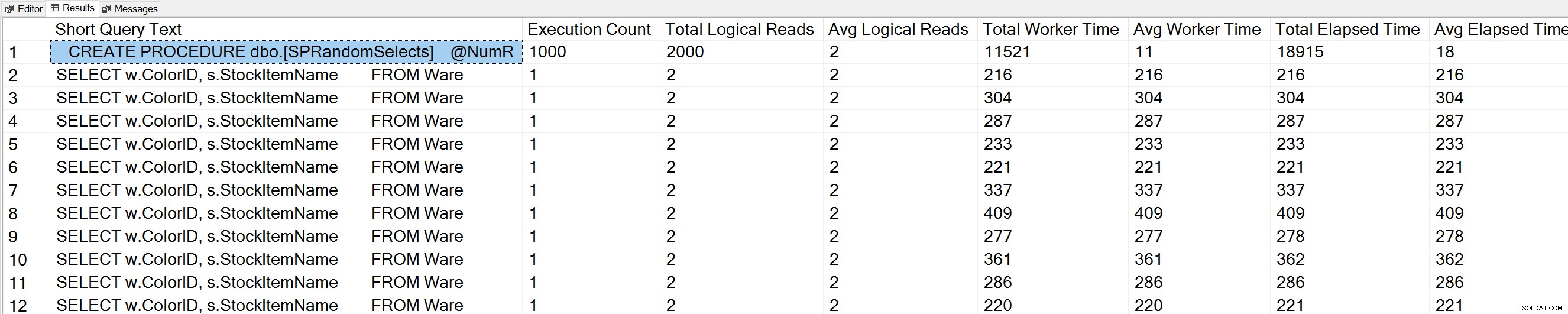
リストの一番上にストアドプロシージャステートメントも表示されます。
ただし、実行したアドホッククエリは、リテラル値が異なっていても、基本的に同じでした。 query_hashを見るとわかるように、ステートメントは繰り返し実行されました:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
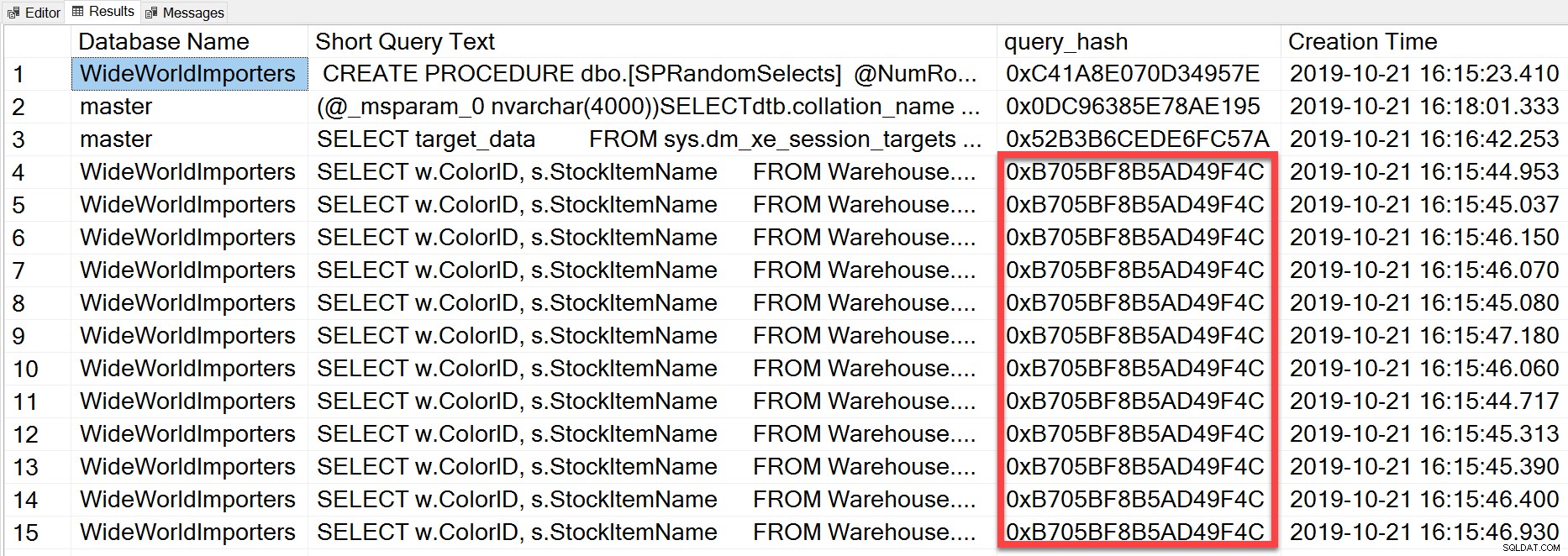
query_hashはSQLServer2008で追加され、ステートメントテキスト用にクエリオプティマイザーによって生成された論理演算子のツリーに基づいています。論理演算子の同じツリーを生成する同様のステートメントテキストを持つクエリは、クエリ述語のリテラル値が異なっていても、同じquery_hashを持ちます。リテラル値は異なる場合がありますが、オブジェクトとそのエイリアスは同じである必要があり、クエリのヒントと、場合によってはSETオプションも同じである必要があります。 RandomSelectsストアドプロシージャは、さまざまなリテラル値を持つクエリを生成します。
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; ただし、すべての実行には、query_hashの値がまったく同じ0xB705BF8B5AD49F4Cがあります。アドホッククエリ(およびquery_hashに関して同じもの)が実行される頻度を理解するには、sys.dm_exec_query_stats(多くの場合、値1)。
コンテキストをWideWorldImportersデータベースに変更し、実行数に基づいて上位のクエリを探すと、query_hashでグループ化すると、ストアドプロシージャとの両方が表示されるようになります。 アドホッククエリ:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

注:sys.dm_exec_function_statsDMVはSQLServer2016で追加されました。SQLServer2014以前でこのクエリを実行するには、このDMVへの参照を削除する必要があります。
この出力は、異なるリテラル値が使用済み。クエリ出力にはquery_plan_hashも含まれます。これは、同じquery_hashを持つクエリでは異なる場合があります。この追加情報は、クエリのプランのパフォーマンスを評価するときに役立ちます。上記の例では、すべてのクエリに同じquery_plan_hash、0x299275DD475C4B17があり、入力値が異なっていても、クエリオプティマイザーが同じプランを生成することを示しています。これは安定しています。同じquery_hashに複数のquery_plan_hash値が存在する場合、プランの変動性が存在します。 query_hashに基づく同じクエリが数千回実行されるシナリオでは、一般的な推奨事項はクエリをパラメータ化することです。計画の変動が存在しないことを確認できる場合は、クエリをパラメータ化すると、各実行の最適化とコンパイル時間が削除され、CPU全体が削減される可能性があります。一部のシナリオでは、5〜10個のアドホッククエリをパラメータ化すると、システム全体のパフォーマンスを向上させることができます。
概要
どのような環境でも、リソースの使用に関して最もコストがかかるクエリと、最も頻繁に実行されるクエリを理解することが重要です。グレンのDMVスクリプトを使用すると、両方のタイプの分析で同じクエリセットが表示される可能性があり、誤解を招く可能性があります。そのため、ワークロードが主に手続き型であるか、主にアドホックであるか、または混合であるかを確認することが重要です。ストアドプロシージャの利点については多くの文書がありますが、特にEntity Framework、NHibernate、LINQ to SQLなどのオブジェクトリレーショナルマッパー(ORM)を使用するソリューションでは、混合または高度にアドホックなワークロードが非常に一般的であることがわかりました。サーバーのワークロードの種類がわからない場合は、上記のクエリを実行して、query_hashに基づいて最も実行されたクエリを確認することをお勧めします。ワークロードと、ヘビーヒッターと1000カットクエリによる死の両方に存在するものを理解し始めると、リソースの使用とこれらのクエリがシステムパフォーマンスに与える影響を真に理解し、チューニングの努力をターゲットにすることができます。