[パート1|パート2|パート3]
このシリーズのパート1では、1TBのテーブルを圧縮するいくつかの方法を試しました。最初の試みでまともな結果が得られましたが、パート2でパフォーマンスを改善できるかどうかを確認したいと思いました。そこで、パフォーマンスの問題と思われるいくつかのことを概説し、宛先テーブルをより適切にパーティション化する方法を説明しました。最適な列ストア圧縮のために。私はすでに:
- テーブルを8つのパーティションに分割しました(コアごとに1つ)。
- 各パーティションのデータファイルを独自のファイルグループに配置します。と、
- 「アクティブな」パーティションを除くすべてのパーティションにアーカイブ圧縮を設定します。
各スケジューラーが独自のパーティションに排他的に書き込むようにする必要があります。
まず、作成したバッチテーブルに変更を加える必要があります。バッチごとに追加された行数(自己監査の健全性チェックの一種)と、進行状況を測定するための開始/終了時間を格納するための列が必要です。
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
次に、アフィニティを提供するためにテーブルを作成する必要があります。ロジックを再試行する時間が失われることを意味する場合でも、スケジューラで複数のプロセスを実行する必要はありません。したがって、特定のスケジューラーのセッションを追跡し、スタックを防ぐテーブルが必要です。
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
アイデアは、アプリケーション(SQLQueryStress)の8つのインスタンスをそれぞれ専用のスケジューラーで実行し、特定のパーティション/ファイルグループ/データファイル宛てのデータのみを一度に最大1億行処理するというものです(クリックして拡大) :
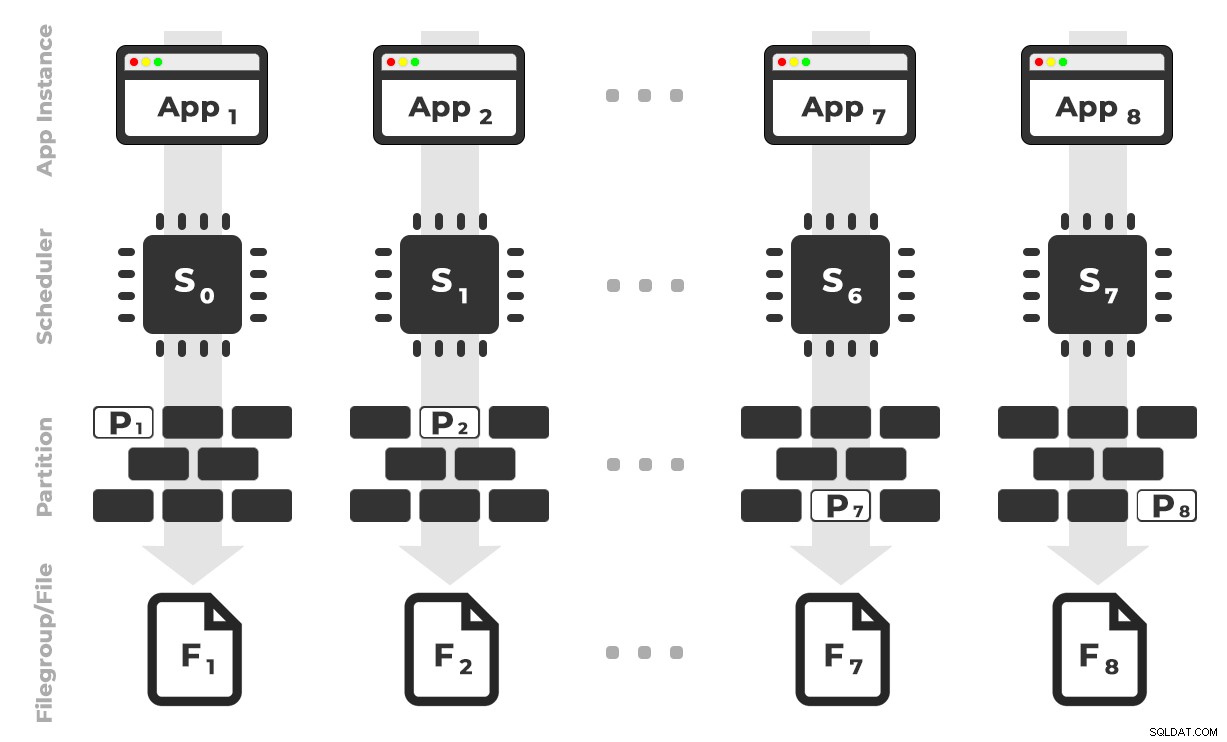 アプリ1はスケジューラー0を取得し、ファイルグループ1のパーティション1に書き込みます。 …
アプリ1はスケジューラー0を取得し、ファイルグループ1のパーティション1に書き込みます。 …
次に、アプリケーションの各インスタンスが単一のスケジューラーで時間を予約できるようにするストアドプロシージャが必要です。以前の投稿で述べたように、これは私の最初のアイデアではありません(そして、Joe Obbishがいなければ、そのガイドでそれを見つけることはできなかったでしょう)。これがUtilityで作成した手順です :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END 簡単ですよね? SQLQueryStressの8つのインスタンスを起動し、このバッチをそれぞれに配置します:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
スケジューラーの割り当てはチョコレートの箱のようなものなので、それほど単純ではないことを除けば。予想されるスケジューラーでアプリの各インスタンスを取得するのに多くの試行が必要でした。アプリの特定のインスタンスの例外を調べて、PartitionIDを変更します 合わせる。これが、私が複数の反復を使用した理由です(ただし、インスタンスごとに1つのスレッドのみが必要でした)。例として、アプリのこのインスタンスはスケジューラー3にあることを期待していましたが、スケジューラー4を取得しました:
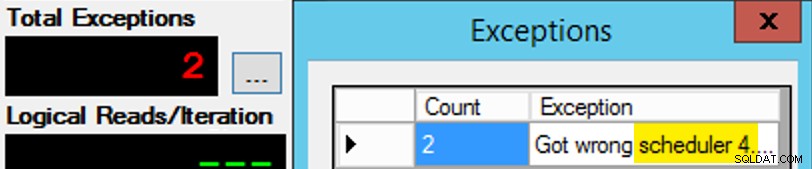 最初は成功しなかった場合…
最初は成功しなかった場合…
クエリウィンドウの3を4に変更して、再試行しました。私が速かったとしたら、スケジューラーの割り当ては「スティッキー」だったので、すぐにそれを拾い上げて、離れていきました。しかし、私はいつも十分な速さではなかったので、それはちょっとしたモグラのようでした。ここでの作業を手作業で減らすために、より良い再試行/ループルーチンを考案し、遅延を短縮して、それが機能するかどうかをすぐに知ることができたかもしれませんが、これは私のニーズには十分でした。また、各プロセスの開始時間を意図せずにずらすこともできました。これは、Obbish氏からのもう1つのアドバイスです。
監視
アフィニティ化されたコピーの実行中に、次の2つのクエリで現在のステータスに関するヒントを得ることができます。
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
私がすべてを正しく行った場合、両方のクエリは8行を返し、論理読み取りと期間の増分を示します。待機タイプはPAGEIOLATCH_SH間で切り替わります 、SOS_SCHEDULER_YIELD 、場合によってはRESERVED_MEMORY_ALLOCATION_EXT。バッチが終了したとき(-- AND EndTime IS NULLのコメントを外すことでこれらを確認できます 、RowsAdded = RowsInRangeであることを確認します 。
SQLQueryStressの8つのインスタンスがすべて完了すると、SELECT INTO <newtable> FROM dbo.BatchQueueを実行できます。 後で分析するために最終結果をログに記録します。
その他のテスト
アフィニティを使用して、既存のパーティション化されたクラスター化列ストアインデックスにデータをコピーすることに加えて、他にもいくつか試してみたかったのです。
- アフィニティを制御しようとせずに、データを新しいテーブルにコピーします。私はアフィニティロジックを手順から外し、「適切なスケジューラを取得することを望んでいる」こと全体を偶然に任せました。確かに、スケジューラスタッキングがしたため、これには時間がかかりました。 起こる。たとえば、この特定の時点で、スケジューラー3は2つのプロセスを実行していましたが、スケジューラー0は昼休みを取っています。
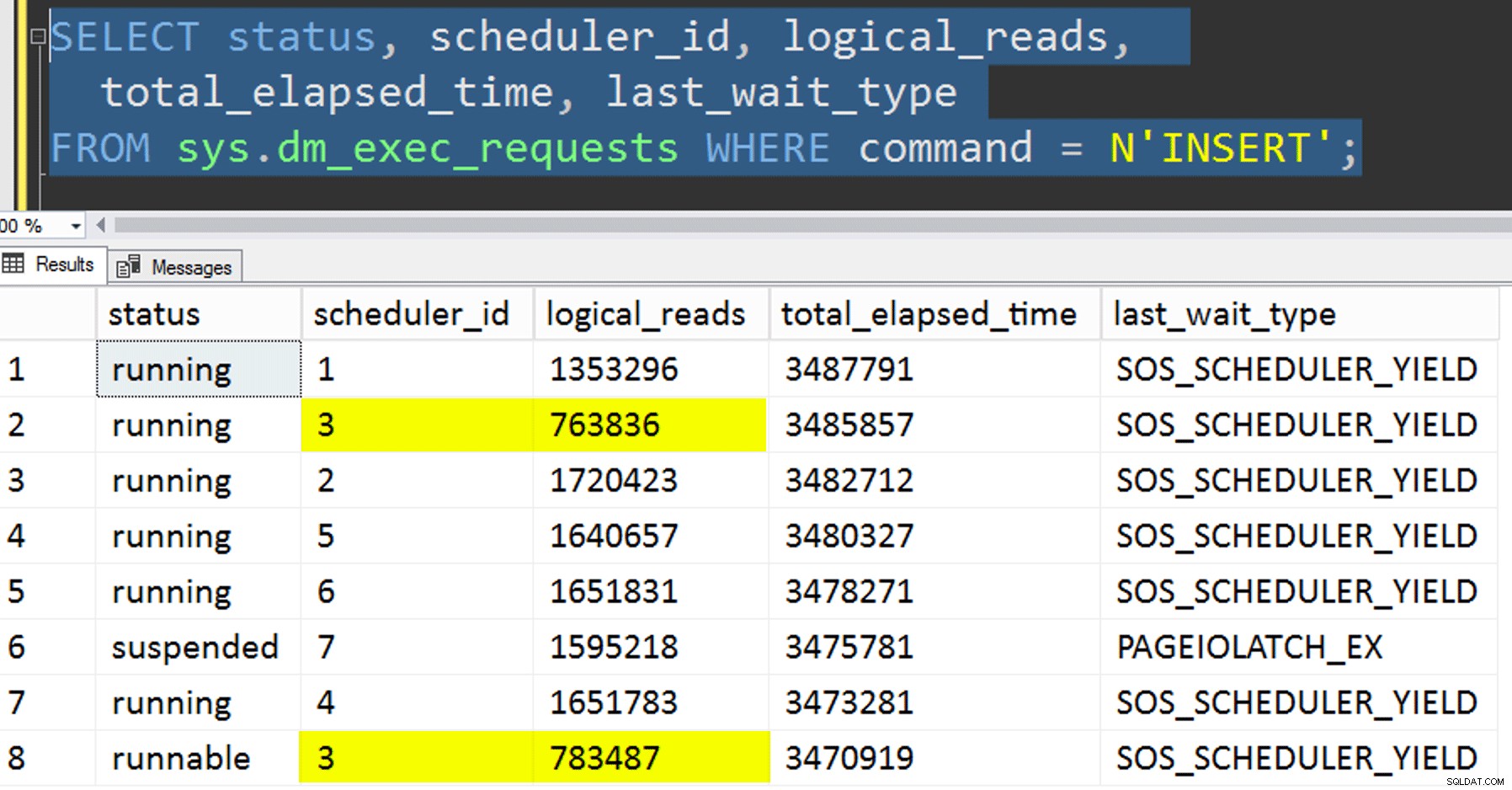 あなたはどこにいますか、スケジューラー番号0?
あなたはどこにいますか、スケジューラー番号0? - ページを適用する または行 前のソースへの圧縮(オンライン/オフラインの両方) アフィニティ化されたコピー(オフライン)。最初にデータを圧縮することで宛先を高速化できるかどうかを確認します。コピーはオンラインでも行うことができますが、AndyMallonの
intのように注意してください。bigintへ 変換、それはいくつかの体操が必要です。この場合、CPUアフィニティを利用できないことに注意してください(ただし、ソーステーブルがすでにパーティション化されている場合は利用できます)。私は頭が良く、元のソースのバックアップを取り、データベースを初期状態に戻す手順を作成しました。手動で特定の状態に戻そうとするよりもはるかに高速で簡単です。-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- 最後に、最初にクラスター化インデックスをパーティションスキームに再構築し、次にその上にクラスター化列ストアインデックスを構築します。後者の欠点は、SQL Server 2017では、これをオンラインで実行できないことです…しかし、2019年には実行できるようになります。
ここでは、最初にPK制約を削除する必要があります。
メッセージ1907、レベル16、状態1DROP_EXISTINGは使用できません 、元の一意性制約はクラスター化列ストアインデックスによって適用できず、一意性クラスター化インデックスを非一意性クラスター化インデックスに置き換えることはできないためです。
インデックス「pk_tblOriginal」を再作成できません。新しいインデックス定義は、既存のインデックスによって適用されている制約と一致しません。これらすべての詳細により、これは3つのステップのプロセスになり、オンラインの2番目のステップになります。最初のステップは、
OFFLINEのみを明示的にテストしました;ONLINEの間、3分で実行されました 15分後に止まりました。どちらの場合もデータサイズの操作であってはならないものの1つですが、それは別の日に残しておきます。ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
結果
タイミングと圧縮率:
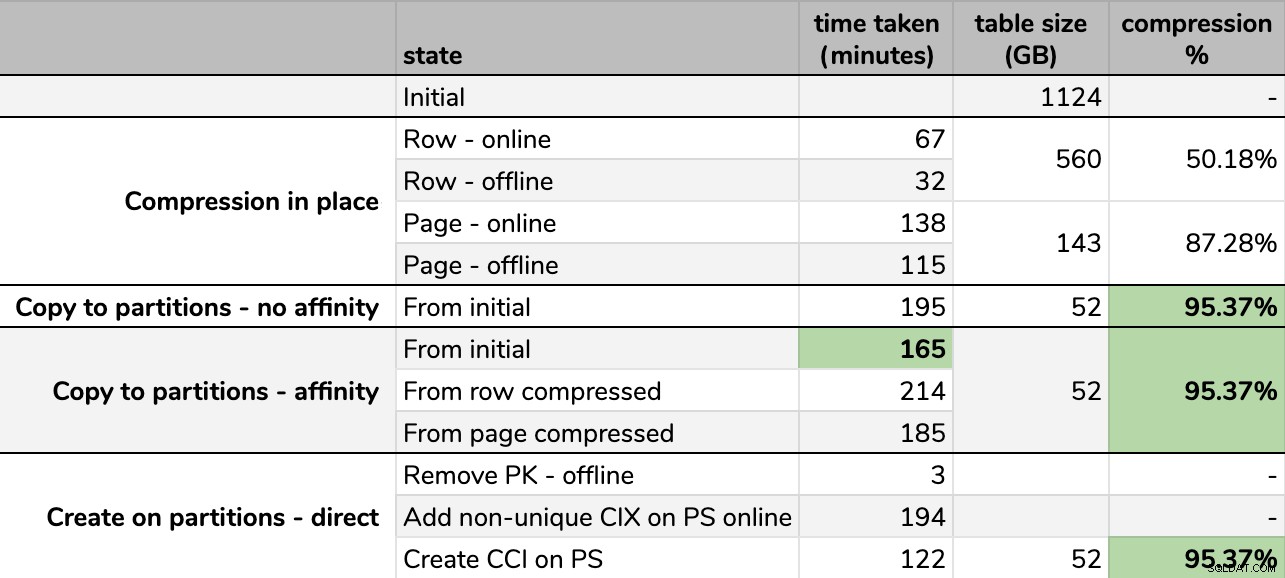 一部のオプションは他のオプションよりも優れています
一部のオプションは他のオプションよりも優れています
同じ手法を使用しても、実行するたびに最終的なサイズにわずかな違いがあるため、GBに丸めたことに注意してください。また、アフィニティメソッドのタイミングは平均に基づいています。 一部のスケジューラーは他のスケジューラーよりも速く終了したため、個々のスケジューラー/バッチランタイム。
一部のタスクには依存関係があるため、スプレッドシートから正確な画像を想像するのは困難です。そのため、情報をタイムラインとして表示し、費やした時間と比較してどの程度の圧縮が得られるかを示します。
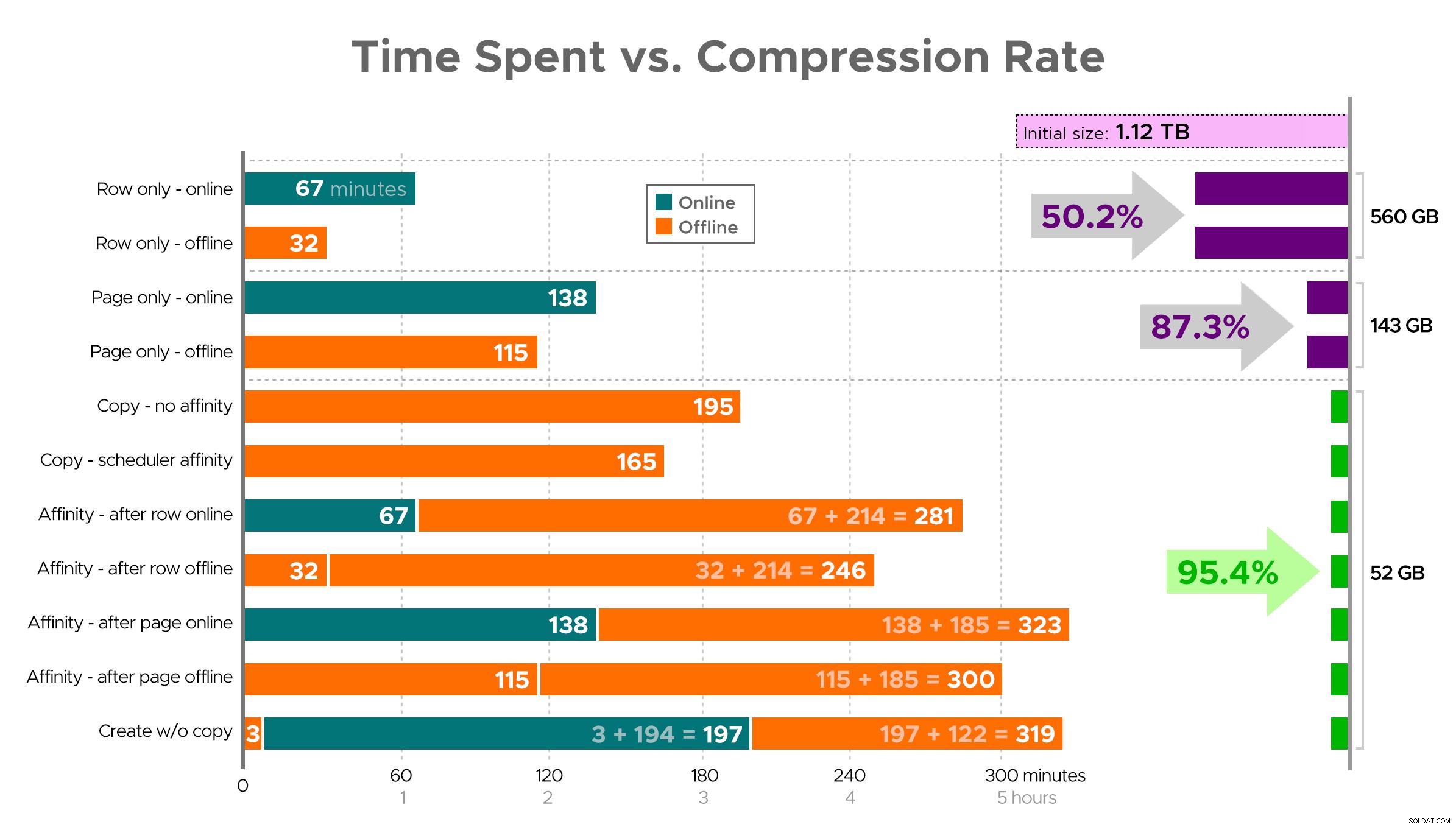 費やした時間(分)と圧縮率
費やした時間(分)と圧縮率
結果からのいくつかの観察結果。ただし、データの圧縮方法が異なる可能性があることに注意してください(また、オンライン操作はEnterprise Editionを使用している場合にのみ適用されます):
- 優先度ができるだけ早くスペースを節約する場合 、最善の策は、行の圧縮を適切に適用することです。混乱を最小限に抑えたい場合は、オンラインで使用してください。速度を最適化したい場合は、オフラインを使用してください。
- 中断なしで圧縮を最大化する場合 、オンラインでページ圧縮を使用すると、中断することなく90%のストレージ削減に近づくことができます。
- 圧縮と中断を最大化する場合は問題ありません 、クラスター化列ストアインデックスを使用して、データを新しいパーティション化されたバージョンのテーブルにコピーし、上記のアフィニティプロセスを使用してデータを移行します。 (繰り返しになりますが、あなたが私よりも優れたプランナーであれば、この混乱をなくすことができます。)
最後のオプションは私のシナリオに最適でしたが、それでもワークロードでタイヤを蹴る必要があります(はい、複数形)。また、SQL Server 2019では、この手法はあまりうまく機能しない可能性がありますが、クラスター化された列ストアインデックスをオンラインで構築できるため、それほど重要ではない可能性があります。
これらのアプローチのいくつかは、「可能な限り迅速に終了する」よりも「利用可能な状態を維持する」、「利用可能な状態を維持する」よりも「ディスク使用量を最小限に抑える」、または読み取りパフォーマンスと書き込みのオーバーヘッドのバランスをとる方がよいため、多かれ少なかれ受け入れられる可能性があります。 。
これのいずれかの側面についての詳細が必要な場合は、質問してください。私は脂肪の一部をトリミングして、細部と消化率のバランスを取りましたが、以前はそのバランスについて間違っていました。別れの考えとして、これがどれほど直線的であるかが気になります。25TBを超える同様の構造を持つ別のテーブルがあり、そこで同様の影響を与えることができるかどうかが気になります。それまでは、圧縮してください!
[パート1|パート2|パート3]