「Waitstatsは、パフォーマンス関連のカウンターを識別するのに役立ちます。ただし、パフォーマンスの問題を正確に診断するには、情報を待つだけでは十分ではありません。私たちの方法論のキューコンポーネントは、リソースの観点からシステムパフォーマンスのビューを提供するパフォーマンスモニターカウンターから来ています。」Tom Davidson、 Microsoftのパフォーマンス調整ツールボックスを開く
SQLServer Pro Magazine、2003年12月
待機とキューは、TomDavidsonが上記の記事と有名なSQLServer 2005の待機とキューのホワイトペーパーを2006年に公開して以来、SQL Serverのパフォーマンス調整方法として使用されてきました。リソースメトリックと組み合わせて適用すると、待機はワークロードの特定のパフォーマンス特性を評価し、チューニング作業のステアリングを支援します。待機データは、多くのSQL Serverパフォーマンス監視ソリューションによって表面化されます。私は、最初からこの方法を使用して調整することを提唱してきました。このアプローチは、SQL Sentryパフォーマンスダッシュボードの設計に影響を与えました。このダッシュボードは、キュー(主要なリソースメトリック)に隣接する待機を表示して、サーバーパフォーマンスの包括的なビューを提供します。
ただし、リソースの重要性に関するDavidsonの指摘を見逃し、クエリのパフォーマンスとシステムの状態の全体像を示すために待機にほぼ完全に依存している人もいるようです。待機統計はSQLServerエンジンから直接取得され、簡単に使用および分類できます。クエリを待機するということは、アプリケーションとユーザーを待機することを意味し、誰も待つのが好きではありません。クエリとアプリケーションを高速化するための唯一のソリューションとして、待機を伴うチューニングを伝道する方が、より複雑な全体像を伝えるよりも簡単です。
残念ながら、リソース分析を除外するための待機に焦点を当てたアプローチは誤解を招く可能性があり、最悪の場合、あなたは盲目的になります。 SentryOneチームメンバーのKevinKlineとSteveWrightは、以前こことここでこれに触れました。この投稿では、Query Storeによって可能になった最近の調査について詳しく説明します。この調査により、待機時間の不足を明らかにしました。排他的な調整が本当に可能であるということです。
なかった上位のクエリ
最近、SentryOneの顧客から、SentryOneデータベースのパフォーマンスに関する懸念について連絡がありました。すべてのSentryOne監視環境の中心には単一のSQLServerデータベースがあり、この顧客は当社のソフトウェアを使用して約600台のサーバーを監視していました。その規模では、クエリのパフォーマンスの問題がときどき発生し、少し調整することも珍しくありません。ワークロード内の新しいクエリが懸念の原因であると思われます。
私は画面共有セッションに参加して見てみましたが、顧客は最初に、SentryOneデータベースも監視している別のシステムからのデータを提示してくれました。システムはクエリレベルの待機アプローチを使用し、SQLSentryデータベースサーバーでの待機の約半分を担当する2つのストアドプロシージャを示しました。これらの2つの手順は常に非常に高速に実行され、データベースの実際のパフォーマンスの問題を示すことはなかったため、これは珍しいことでした。困惑して、SQL Sentryに切り替えて、何が表示されるかを確認しました。同じ間隔で、他のシステムの#1プロシージャが、合計期間、CPUの点で#6、#7、および#8であることに驚きました。それぞれ論理読み取りと論理読み取り:
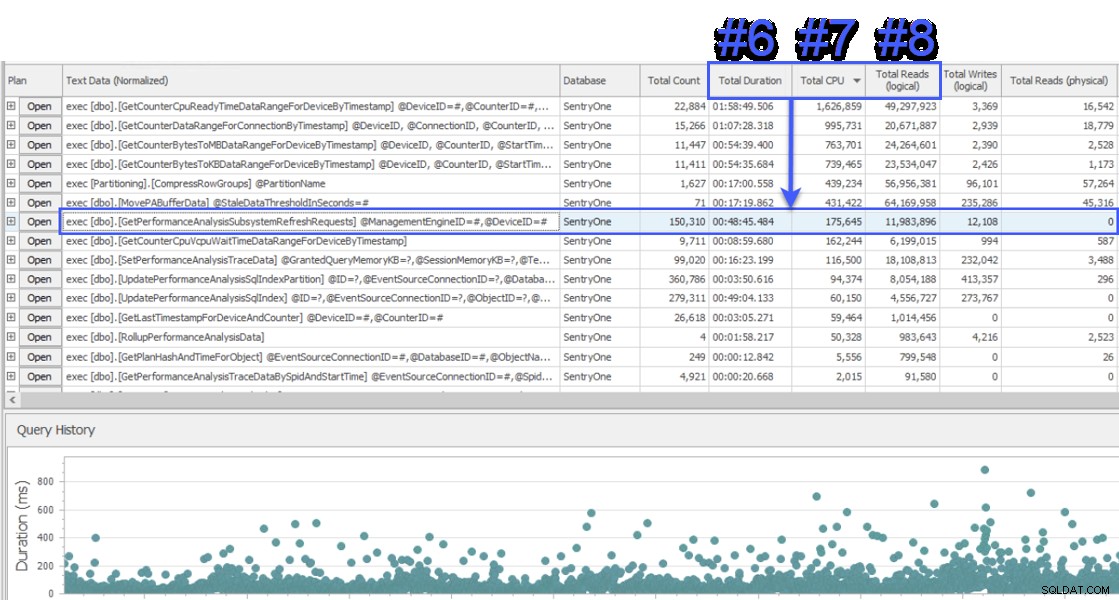 SQLSentryの「トップSQL」ビュー
SQLSentryの「トップSQL」ビュー
リソース消費の観点から、これは、その上のクエリが合計期間の75%、合計CPUの87%、および論理読み取りの88%を表すことを意味しました。さらに、他のシステムの2番目の手順は、SQLSentryのトップ30にも含まれていませんでした。これらの2つのクエリは、上位2つからはほど遠いものであり、実際ののほとんどを占めるクエリです。 システムの消費量は大幅に過小評価されていました。
私は常にトップウェイターとトップリソースコンシューマーの間に強い相関関係があると思っていましたが、このような直接のクエリレベルの比較を実行したことはなかったので、これらの結果は控えめに言っても驚くべきものでした。興味をそそられたので、この状況が典型的なものか異常なものかを調査することにしました。
クエリストア2017から救助へ
SQL Server 2017以降では、クエリストアはクエリリソースの消費に加えてクエリレベルの待機をキャプチャします。 Erin Stellatoは、QueryStoreで素晴らしい投稿をしました。前述のツールを含む他のツールで使用される標準的なアプローチである、実行中のクエリをキャッチすることを期待して、クエリがDMVを毎秒待機するよりもオーバーヘッドが低く正確です。
SQL Sentryは常に待機をキャプチャしましたが、オーバーヘッドと精度に関するこれらの懸念のため、SQLServerインスタンスレベルで取得しました。詳細なクエリ待機は、統合されたプランエクスプローラーを介してオンデマンドで利用できます。利用可能な場合は、クエリストアからのクエリレベルのデータを使用してインスタンスレベルの待機を拡張することを評価しています。
この取り組みのために、私はSentryOne Product Advisory Councilの助けを借りました。これは、プライベートSlackチャネルに参加しているSentryOneの顧客、パートナー、および業界の友人のグループです。このスクリプトを共有して、クエリストアから過去8時間のデータをダンプし、金融サービス、ゲームパブリッシング、フィットネストラッキング、保険など、複数の業種にわたる11台の本番サーバーの結果を受け取りました。
クエリストアの待機カテゴリは、ここに記載されています。引用された理由で削除されたこれらを除いて、すべてのカテゴリが分析に含まれていました:
- 並列処理 –複数のスレッドが関連する待機を破棄し、期間やその他のメトリックとの相関関係を混乱させる可能性があるため、クエリの待機時間が実際の期間をはるかに超えて大幅に増加する可能性があります。さらに、CXPACKET / CXCONSUMERの分割は役立ちますが、CXPACKETは並列処理があることを意味するだけであり、必ずしも問題や実用性があるとは限りません。
- CPU –シグナル待機時間は、リソース待機との相関関係を介してCPUボトルネックを確認するのに役立ちますが、Query Storeには現在、このカテゴリにSOS_SCHEDULER_YIELDのみが含まれています。これは、ここで説明する従来の意味での待機ではありません。特にSQLServerがオーバーサブスクライブされたホスト上にあるVM上にある場合は、簡単に比較したり相関させたりすることはできません。たとえば、あるサーバーでは、クエリストアのCPU待機時間は、並列処理なしですべてのクエリの合計CPU時間の227%でしたが、これは不可能なはずです。
- ユーザー待機 およびアイドル –これらのカテゴリは、タイマーとキューの待機のみで構成されており、これらのタイプを常に除外する必要があるのと同じ理由で除外されました。これらは無害であり、ノイズを発生させるだけです。
余談ですが、最近、QueryStoreの父であるConorCunninghamと、Query Storeの待機タイプとカテゴリが将来変更される可能性について話しました。彼は、それは確かに可能であると述べました。
分析結果TL;DR
徹底的な分析の結果、お客様のシステムで観察された結果は異常ではなく、一般的なものであることが確認されました。つまり、ワークロードの監視と調整を待機に重点を置いたツールに依存している場合、間違ったクエリに集中していて、ほとんどの責任者を見逃している可能性が高くなります。 システムでのクエリ期間とリソース消費量の計算。 CPUとIOの消費は、サーバーのハードウェアとクラウドの消費に直接変換されるため、これは重要です。
ほとんどのクエリは待たない
最初に取り上げる興味深い重要な発見は、ほとんどのクエリが待機をまったく生成しないということです。すべてのサーバーにわたる56,438の合計クエリのうち、待機時間があったのは9,781(17%)のみであり、重要なタイプからの待機時間があったのは8,092(14%)のみでした。最適化するクエリを決定するために待機のみを使用している場合、ワークロード内のほとんどのクエリを見逃すことになります。
待機とリソースの相関
各システムのすべてのクエリを待機とリソースでランク付けし、ランクを使用してスピアマンの相関を計算することにより、待機がリソース消費にどのように関連しているかを分析しました。私たちが最終的に決定しようとしているのは、トップウェイターがトップ消費者になる傾向があるかどうかです。結局のところ、そうではありません。
表1 は、平均クエリ待機のカラースケールの相関係数を示しています。 時間 他の測定値へ–値1.00(紺色)は完全に相関しているデータを表します。ご覧のとおり、ほとんどのサーバーで待機やその他の測定値との相関は強くなく、1つのサーバーではほとんどの測定値と負の相関関係があります。
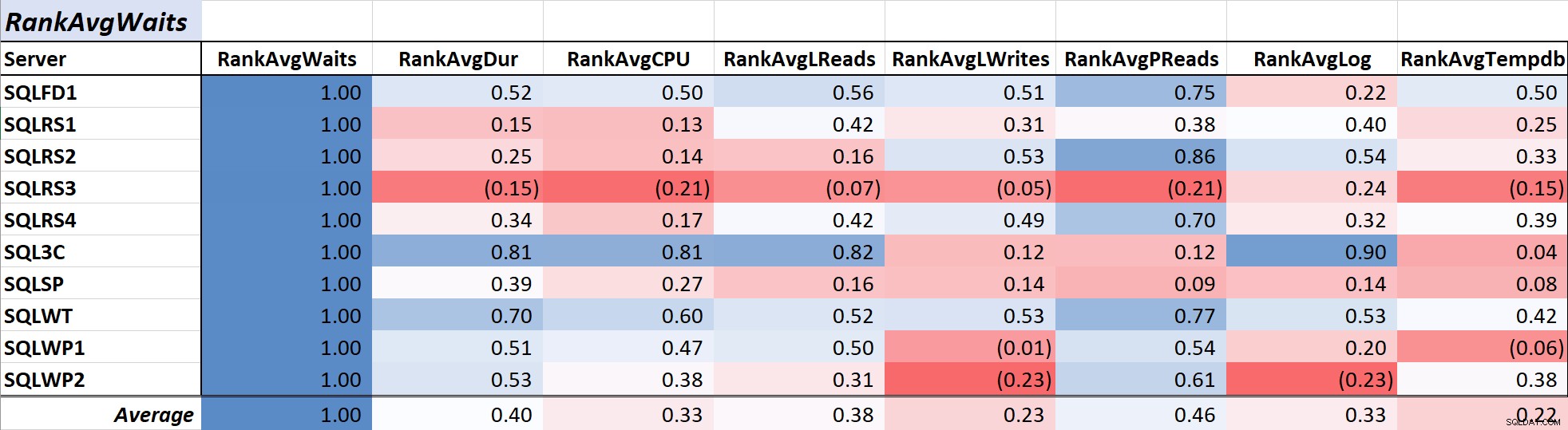 表1:平均クエリ待機時間(ms)との相関>
表1:平均クエリ待機時間(ms)との相関>
クエリの継続時間は、ユーザーエクスペリエンスに直接変換されるため、DBAや開発者にとって主な関心事であることが多く、表2 平均クエリ期間間の相関関係を示します およびその他の対策。期間と2つの主要なリソース測定値、CPUと論理読み取りとの相関は、それぞれ.97と.75で非常に強力です。
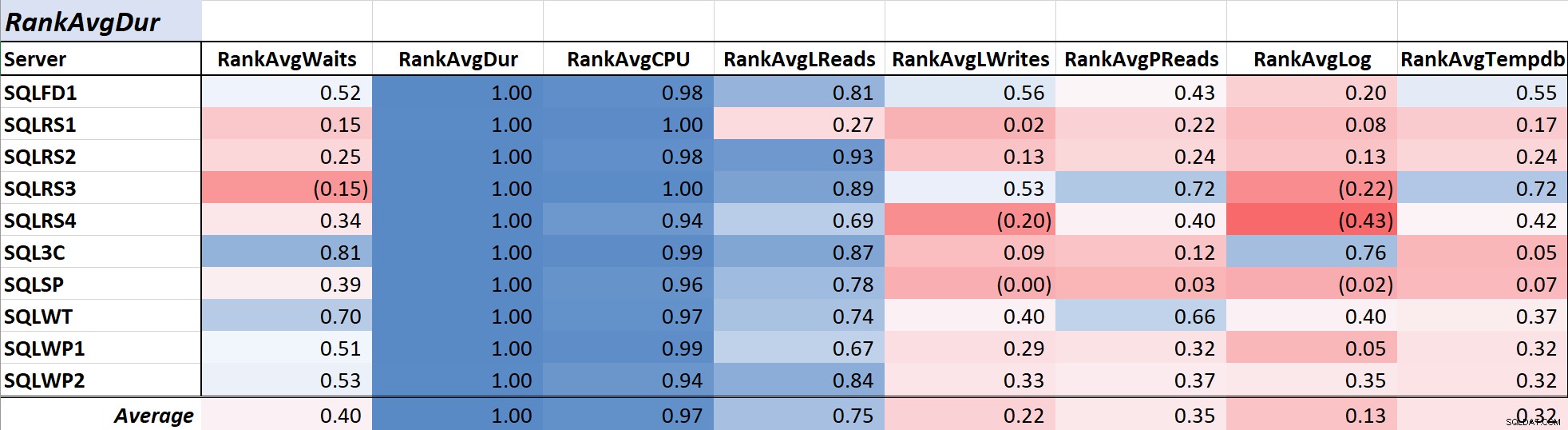 表2:平均クエリ期間(ミリ秒)との相関
表2:平均クエリ期間(ミリ秒)との相関
論理読み取りは常にCPUを使用し、期間と同様に、CPUはミリ秒単位で測定されるため、この関係は驚くべきことではありません。結果は、データベースアプリケーションをできるだけ高速に実行する場合は、待機のみを使用するよりも、クエリCPUと論理読み取りの削減に重点を置く方が期間の短縮に効果的であるという考えと一致しています。幸いなことに、クエリの設計やインデックス作成などを改善することは、通常、クエリの待機時間を直接短縮するよりも簡単な提案です。同僚のAaronBertrandは、ここで待機してチューニングするときに、いくつかの警告を効果的に提示します。
合計待機時間の%
次に、待機時間が最も長いクエリが最も多くのリソース消費を占める傾向があるかどうかを調べました。顧客のシステムで見たものが非定型であるかどうかを判断したいと思います。ここで、上位2つの待機中のクエリは、総リソース消費量の比較的小さな割合を表しています。
チャート1 以下は、合計待機時間の75%を表すクエリによって占められる、各サーバーの合計CPUおよび論理読み取りの割合を示しています。 1台のサーバーのみが75%を超えるリソースを持っていました–SQLRS3での読み取り。残りの部分では、待機時間の75%を占めるクエリは、リソースの75%未満を消費し、多くの場合、はるかに少なくなります。これは、お客様のシステムで見たものを反映しており、相関分析と一致しています。
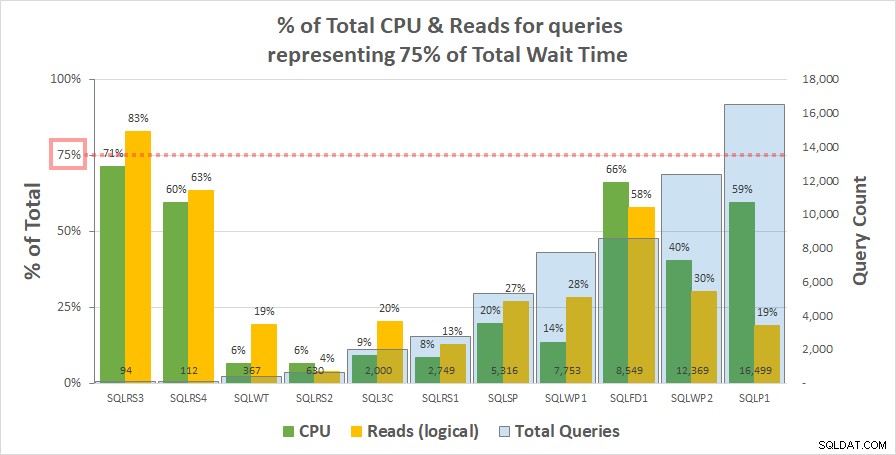
ワークロード内のクエリの総数と関係があるように見えることに注意してください。これは、2番目のy軸の水色の列シリーズで表され、グラフはこのシリーズの昇順で並べ替えられます。待機の75%でリソース測定値が最も高い2つのサーバーでも、クエリが最も少なくなりました(SQLRS3およびSQLRS4)。ワークロードセットが小さいほど、少数のクエリの潜在的な影響が大きくなります。確かに、両方のサーバーで、待機とリソースの大部分を占めるのは2つのクエリだけです。これを確認する1つの方法は、待機は、最も必要のないときに最も重いクエリを特定するのに最も役立つということです。
待機時間とクエリ期間
最後に、各システムの合計待機時間と合計クエリ時間の割合を評価しました。 表3 次の列があります:
- 合計クエリ時間(ミリ秒)
- 合計待機時間ms– raw
- 合計待機時間ms–並列処理、アイドル、およびユーザー待機なし(Rev1)
- 合計待機時間ms–並列処理、アイドル、ユーザー待機、CPU(Rev2)なし
- データバーを含む3つの待機時間列の期間の割合
- データバーを含む一意のクエリの総数
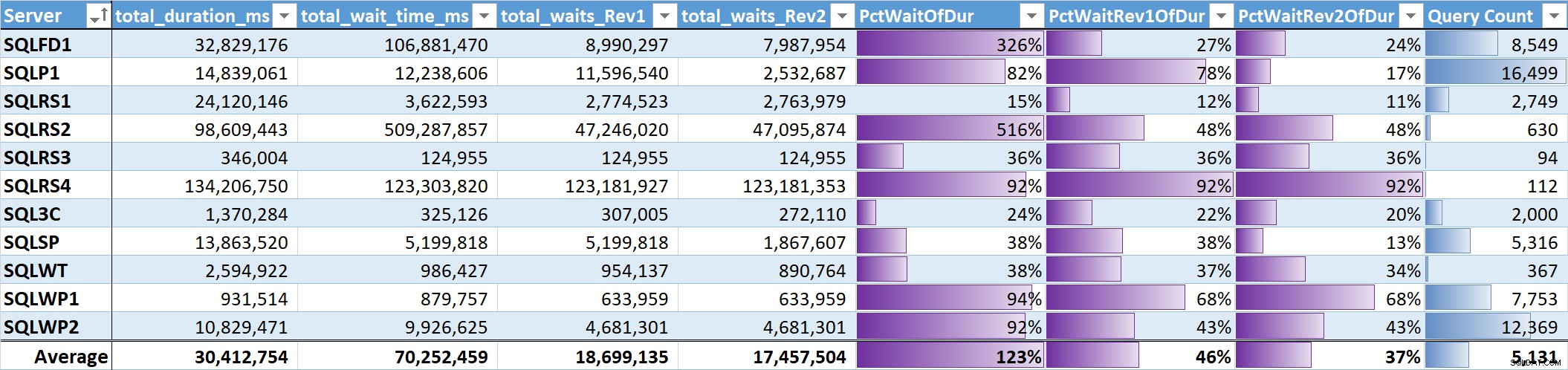
意味のある待機の重み付けされていない平均 (Rev2)すべてのシステムで、合計クエリ期間の37%です。 5つのシステムでは25%未満であり、2つのシステムでのみ50%を超えていました。待機時間が92%(SQLRS4)のシステムでは、1つはクエリが最も少なく、2つのクエリが待機の99%、期間の97%、CPUの84%、読み取りの86%を占めています。
待機時間は特定のシステムでクエリ実行時間のかなりの部分を占める可能性があり、待機時間を短縮するとクエリ期間も短縮されることは直感的に思えますが、待機時間と期間の相関は弱いことがわかりました。それほど単純なことではないでしょうし、私自身の経験がこれを裏付けています。ここではさらに調査が必要です。
PlanExplorerとSQLSentryを使用した包括的なチューニング
この優れたSQLskillsホワイトペーパーが頻繁に示唆しているように、高い待機時間の原因は、多くの場合、最適化されていないクエリとインデックスです。無料のSentryOneプランエクスプローラーは、インデックス分析モジュールや他の多くの革新的な機能を使用した効率的なクエリチューニングにより、リソース消費を削減することを目的としています。 SQL Sentryは、PlanExplorerをTopSQL、Blocking、およびDeadlocksモジュールに直接統合するため、問題のあるクエリを1か所で自動的にキャプチャして調整できます。 SQL Sentryダッシュボードの履歴待機、CPU、またはIOチャートで関心のある範囲を簡単に選択し、[トップSQL]ビューにジャンプして、その時間中にリソースを消費している上位のクエリを見つけることができます。次に、シングルクリックでプランエクスプローラーでクエリを開き、詳細なクエリレベルの待機を取得できますおよび 必要に応じてオンデマンドのリソース。これよりも、完全な待機とキューの調整方法の優れた実施形態はないと思います。
 SQLSentryダッシュボードの「待機」チャート
SQLSentryダッシュボードの「待機」チャート
 無料のSentryOneプランエクスプローラーは、操作レベルとともに、時間の経過とともに待機を表示しますコストとリソース
無料のSentryOneプランエクスプローラーは、操作レベルとともに、時間の経過とともに待機を表示しますコストとリソース
結論
待機とキューを使用した調整は、2006年に戻ったときと同じように今日のSQL Serverのパフォーマンスに適用できます。ただし、リソースを除外するために待機に焦点を当てることは、データから一般的に最適化されていないことにつながることが明らかであるため、危険なビジネスです。コスト効率の悪いシステム。ハードウェアリソースとクラウドの支出に関しては、最終的には待機時間ではなくコンピューティングリソースとIOリソースにお金を払うことになります。そのため、消費のために直接最適化するのが便利です。私の経験では、リソースの消費と関連する競合が減少すると、当然、待機時間の短縮が続きます。
謝辞
SentryOneのリードデータサイエンティストであるFredFrostの貴重な情報と、この分析の批評的なレビューに感謝します。