この記事は、NULLの複雑さに関するシリーズの第3回です。パート1では、NULLマーカーの意味と、それが比較でどのように動作するかについて説明しました。パート2では、さまざまな言語要素でのNULL処理の不整合について説明しました。今月は、まだT-SQLに対応していない強力な標準のNULL処理機能と、現在人々が使用している回避策について説明します。
いくつかの例では、先月のようにサンプルデータベースTSQLV5を引き続き使用します。このデータベースを作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
DISTINCT述語
シリーズのパート1では、比較でNULLがどのように動作するか、およびSQLとT-SQLが採用する3値述語論理の複雑さについて説明しました。次の述語を検討してください。
X =Yいずれかの述部がNULLの場合(両方がNULLの場合を含む)、この述部の結果は論理値UNKNOWNになります。 ISNULLおよびISNOTNULL演算子を除いて、同じことが他のすべての演算子にも適用されます。これには、異なるも含まれます。 (<>):
X <> Y多くの場合、実際には、比較のためにNULLを非NULL値と同じように動作させる必要があります。これは特に、欠落しているが適用できないを表すためにそれらを使用する場合に当てはまります。 値。この標準には、次の形式を使用するDISTINCT述語と呼ばれる機能の形式で、このニーズに対するソリューションがあります。
この述語は、等式または不等式のセマンティクスを使用する代わりに、述語を比較するときに識別性ベースのセマンティクスを使用します。等式演算子(=)の代わりに、次の形式を使用して、2つの述語が同じ場合(両方がNULLの場合を含む)にTRUEを取得し、そうでない場合(一方がNULLである場合を含む)にFALSEを取得します。その他はそうではありません:
XはYと区別されません異なるの代わりとして 演算子(<>)を使用すると、次の形式を使用して、2つの述語が異なる場合(一方がNULLで、もう一方がNULLでない場合を含む)にTRUEを取得し、同じ場合(両方がNULLの場合を含む)にFALSEを取得します。
XはYとは異なりますシリーズのパート1で使用した例にDISTINCT述語を適用してみましょう。入力パラメータ@dtを指定すると、入力がNULLでない場合は入力日に出荷された注文を返し、入力がNULLの場合はまったく出荷されなかった注文を返すクエリを作成する必要があったことを思い出してください。標準によれば、このニーズを処理するには、DISTINCT述語とともに次のコードを使用します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
今のところ、パート1から、次のように、EXISTS述語とINTERSECT演算子の組み合わせをT-SQLのSARGable回避策として使用できることを思い出してください。
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
入力日@dtとは異なる(異なる)日に出荷された注文を返すには、次のクエリを使用します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
T-SQLで機能する回避策は、次のようにEXISTS述語とEXCEPT演算子の組み合わせを使用します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
パート1では、テーブルを結合し、結合述語に識別性ベースのセマンティクスを適用する必要があるシナリオについても説明しました。私の例では、T1およびT2と呼ばれるテーブルを使用し、両側にk1、k2、およびk3と呼ばれるNULL可能な結合列があります。標準によれば、このような結合を処理するには、次のコードを使用します。
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
今のところ、前のフィルタリングタスクと同様に、結合のON句でEXISTS述語とINTERSECT演算子の組み合わせを使用して、次のようにT-SQLで個別の述語をエミュレートできます。
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
フィルタで使用する場合、このフォームはSARG可能であり、結合で使用する場合、このフォームはインデックスの順序に依存する可能性があります。
DISTINCT述語がT-SQLに追加されるのを確認したい場合は、ここで投票できます。
このセクションを読んだ後でも、DISTINCT述語について少し不安を感じる場合は、あなただけではありません。おそらく、この述語は、現在T-SQLで行われている既存の回避策よりもはるかに優れていますが、少し冗長で、少し混乱します。それは私たちの心の中で肯定的な比較であるものを適用するために否定的な形式を使用し、逆もまた同様です。まあ、誰もすべての標準的な提案が完璧だとは言いませんでした。チャーリーがパート1へのコメントの1つで述べたように、次の簡略化された形式の方がうまく機能します。
簡潔ではるかに直感的です。 XはYと区別されない代わりに、次を使用します:
X IS YX IS DISTINCT FROM Yの代わりに、次を使用します:
XはYではありませんこの提案された演算子は、実際には既存のISNULLおよびISNOTNULL演算子と一致しています。
クエリタスクに適用して、入力日に発送された(または入力がNULLの場合は発送されなかった)注文を返すには、次のコードを使用します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
入力日とは異なる日に発送された注文を返品するには、次のコードを使用します。
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Microsoftが明確な述語を追加することを決定した場合、標準の冗長形式と、この非標準でありながらより簡潔で直感的な形式の両方をサポートしていればよいでしょう。不思議なことに、SQL Serverのクエリプロセッサは、内部比較演算子ISをすでにサポートしています。これは、ここで説明した目的のIS演算子と同じセマンティクスを使用します。この演算子の詳細については、Paul Whiteの記事「ドキュメント化されていないクエリプラン:同等性の比較」(「EQではなくIS」を検索)を参照してください。不足しているのは、T-SQLの一部として外部に公開することです。
NULL処理句(IGNORE NULLS | RESPECT NULLS)
オフセットウィンドウ関数LAG、LEAD、FIRST_VALUE、およびLAST_VALUEを使用する場合、NULL処理の動作を制御する必要がある場合があります。デフォルトでは、これらの関数は、式の結果が実際の値であるかNULLであるかに関係なく、要求された位置で要求された式の結果を返します。ただし、関連する方向に移動し続け(LAGとLAST_VALUEの場合は後方、LEADとFIRST_VALUEの場合は前方)、存在する場合は最初の非NULL値を返し、それ以外の場合はNULLを返したい場合があります。この標準では、NULL処理句を使用してこの動作を制御できます。 次の構文で:
offset_function(NULL処理句が指定されていない場合のデフォルトは、RESPECT NULLSオプションです。これは、NULLであっても、要求された位置に存在するものをすべて返すことを意味します。残念ながら、この句はT-SQLではまだ使用できません。 LAG関数とFIRST_VALUE関数を使用した標準構文の例と、T-SQLで機能する回避策を提供します。 LEADおよびLAST_VALUEでこのような機能が必要な場合は、同様の手法を使用できます。
サンプルデータとして、次のコードを使用して作成および入力するT4というテーブルを使用します。
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
最後の関連を返すことを含む一般的なタスクがあります 価値。 col1のNULLは値に変更がないことを示し、NULL以外の値は新しい関連する値を示します。 IDの順序に基づいて、最後のNULL以外のcol1値を返す必要があります。標準のNULL処理句を使用すると、次のようにタスクを処理できます。
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
このクエリから期待される出力は次のとおりです。
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
T-SQLには回避策がありますが、これには2層のウィンドウ関数と1つのテーブル式が含まれます。
最初のステップでは、MAXウィンドウ関数を使用して、col1がNULLでない場合に、これまでの最大ID値を保持するgrpという列を計算します。
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; このコードは次の出力を生成します:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
ご覧のとおり、col1値が変更されるたびに、一意のgrp値が作成されます。
2番目のステップでは、最初のステップのクエリに基づいてCTEを定義します。次に、外部クエリで、grpによって定義された各パーティション内で、これまでの最大col1値を返します。これが最後のNULL以外のcol1値です。完全なソリューションコードは次のとおりです。
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; 明らかに、これは単にIGNORE_NULLSと言うよりもはるかに多くのコードと作業です。
もう1つの一般的なニーズは、最初の関連する値を返すことです。この場合、IDの順序に基づいて、これまでのところNULL以外の最初のcol1値を返す必要があるとします。標準のNULL処理句を使用すると、次のようにFIRST_VALUE関数とIGNORENULLSオプションを使用してタスクを処理します。
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; このクエリから期待される出力は次のとおりです。
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
T-SQLの回避策は、最後のNULL以外の値に使用されたものと同様の手法を使用しますが、double-MAXアプローチの代わりに、MIN関数の上にFIRST_VALUE関数を使用します。
最初のステップでは、MINウィンドウ関数を使用して、col1がNULLでない場合に、これまでの最小ID値を保持するgrpという列を計算します。
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; このコードは次の出力を生成します:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
最初の関連する値の前にNULLが存在する場合、2つのグループになります。1つ目はgrp値としてNULLを持ち、2つ目はgrp値として最初の非NULLIDを持ちます。
2番目のステップでは、最初のステップのコードをテーブル式に配置します。次に、外部クエリで、grpでパーティション化されたFIRST_VALUE関数を使用して、最初の関連する(NULL以外の)値が存在する場合はそれを収集し、そうでない場合は次のようにNULLを収集します。
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; 繰り返しになりますが、これは単にIGNORE_NULLSオプションを使用する場合と比較して、多くのコードと作業です。
この機能が役立つと思われる場合は、ここでT-SQLに含めることに投票できます。
最初にNULLで注文| NULLS LAST
プレゼンテーション、ウィンドウ処理、TOP / OFFSET-FETCHフィルタリング、またはその他の目的でデータを注文する場合、このコンテキストでNULLがどのように動作するかという問題がありますか? SQL標準では、NULLは非NULLの前または後に一緒にソートする必要があり、いずれかの方法を決定するのは実装に任されています。ただし、ベンダーが何を選択する場合でも、一貫性を保つ必要があります。 T-SQLでは、昇順を使用する場合、NULLが最初に(NULL以外の前に)順序付けられます。例として次のクエリを考えてみましょう。
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
このクエリは次の出力を生成します:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
出力には、出荷日がNULLである未出荷の注文が、既存の該当する出荷日がある出荷済み注文の前に注文されていることが示されます。
しかし、昇順を使用するときに最後に順序付けするためにNULLが必要な場合はどうなりますか? ISO / IEC SQL標準は、NULLが最初に順序付けされるか最後に順序付けられるかを制御する順序付け式に適用する句をサポートしています。この句の構文は次のとおりです。
<順序式>NULLSFIRST | NULLS LAST私たちのニーズに対応するには、注文を出荷日で並べ替えて昇順で返しますが、未出荷の注文は最後に返され、タイブレーカーとしての注文IDで返すには、次のコードを使用します。
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
残念ながら、このNULLS順序句はT-SQLでは使用できません。
T-SQLでよく使用される回避策は、順序式の前にCASE式を付けることです。これにより、NULL以外の値の順序値がNULLよりも低い定数が返されます(このソリューションをクエリ1と呼びます)。
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
このクエリは、NULLが最後に表示される目的の出力を生成します:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
出荷日列をキーとして、Sales.Ordersテーブルにカバーインデックスが定義されています。ただし、操作されたフィルタリング列がフィルターのSARGabilityとインデックスのシークを適用する機能を妨げるのと同様に、操作された順序列は、クエリのORDERBY句をサポートするためにインデックスの順序に依存する機能を防ぎます。したがって、SQL Serverは、図1に示すように、明示的な並べ替え演算子を使用してクエリ1の計画を生成します。
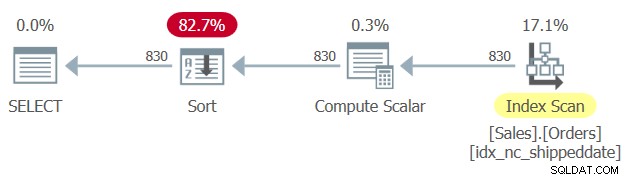 図1:クエリ1の計画
図1:クエリ1の計画
明示的な並べ替えが問題になるほど、データのサイズが大きくない場合があります。しかし時々そうです。明示的な並べ替えを使用すると、クエリのスケーラビリティが非常に直線的になり(1行あたりの支払い額が増えるほど)、応答時間(最初の行が返されるまでの時間)が遅れます。
順序を保持するマージ結合連結演算子を使用して最適化されるソリューションを使用して、このような場合に明示的な並べ替えを回避するために使用できるトリックがあります。 SQLServerのさまざまなシナリオで採用されているこの手法の詳細な説明を見つけることができます。マージ結合連結による並べ替えの回避。ソリューションの最初のステップでは、2つのクエリの結果を統合します。1つのクエリは、順序列がNULLでない行を返し、順序値(0など)を持つ定数に基づく結果列(sortcolと呼びます)を返します。 NULLを含む行を返す別のクエリで、sortcolは最初のクエリよりも高い順序値を持つ定数に設定されています(例:1)。2番目のステップでは、最初のステップのコードに基づいてテーブル式を定義し、次に外側のクエリでは、最初にsortcolで行を並べ替え、次に残りの順序付け要素で行を並べ替えます。この手法を実装する完全なソリューションのコードは次のとおりです(このソリューションをクエリ2と呼びます):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
このクエリの計画を図2に示します。
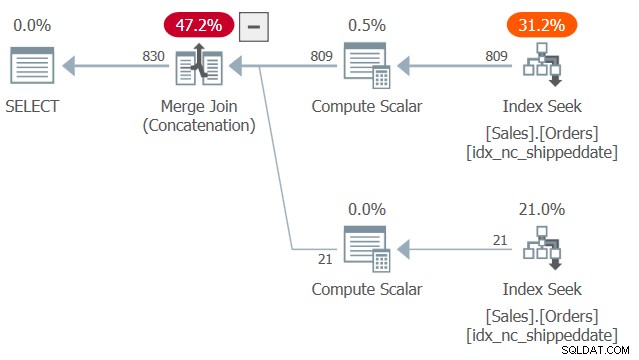 図2:クエリ2の計画
図2:クエリ2の計画
カバーするインデックスidx_nc_shippeddateの2つのシークと順序付き範囲スキャンに注意してください。1つはshippeddateisがNULLでない行をプルし、もう1つはshippeddateがNULLの行をプルします。次に、マージ結合アルゴリズムが結合で機能するのと同様に、マージ結合(連結)アルゴリズムは、2つの順序付けられた側からの行をジッパーのように統合し、取り込んだ順序を保持して、クエリの表示順序のニーズをサポートします。この手法が、明示的な並べ替えを使用するCASE式を使用したより一般的なソリューションよりも常に高速であると言っているわけではありません。ただし、前者には線形スケーリングがあり、後者にはnlognスケーリングがあります。したがって、前者は行数が多い場合に、後者は行数が少ない場合にうまくいく傾向があります。
明らかに、この一般的なニーズに対するソリューションがあることは良いことですが、T-SQLが将来的に標準のNULL順序句のサポートを追加した場合ははるかに優れています。
結論
ISO / IEC SQL標準には、まだT-SQLに到達していない非常に多くのNULL処理機能があります。この記事では、それらのいくつかについて説明しました。DISTINCT述語、NULL処理節、およびNULLの順序を最初にするか最後にするかを制御することです。 T-SQLでサポートされているこれらの機能の回避策も提供しましたが、明らかに面倒です。来月は、標準の一意性制約、T-SQL実装との違い、T-SQLで実装できる回避策について説明します。