この記事は、テーブル式に関するシリーズの第6部です。先月のパート5では、非再帰的CTEの論理的な扱いについて説明しました。今月は、再帰CTEの論理的な扱いについて説明します。 T-SQLによる再帰CTEのサポートと、T-SQLでまだサポートされていない標準要素について説明します。サポートされていない要素に対して、論理的に同等のT-SQL回避策を提供します。
サンプルデータ
サンプルデータには、従業員の階層を保持するEmployeesというテーブルを使用します。 empid列は、部下(子ノード)の従業員IDを表し、mgrid列は、マネージャー(親ノード)の従業員IDを表します。次のコードを使用して、tempdbデータベースにEmployeesテーブルを作成してデータを入力します。
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary); 従業員階層のルート(CEO)のmgrid列がNULLであることに注意してください。残りのすべての従業員にはマネージャーがいるため、mgrid列はマネージャーの従業員IDに設定されます。
図1は、従業員の階層をグラフィカルに表したもので、従業員の名前、ID、および階層内でのその位置を示しています。
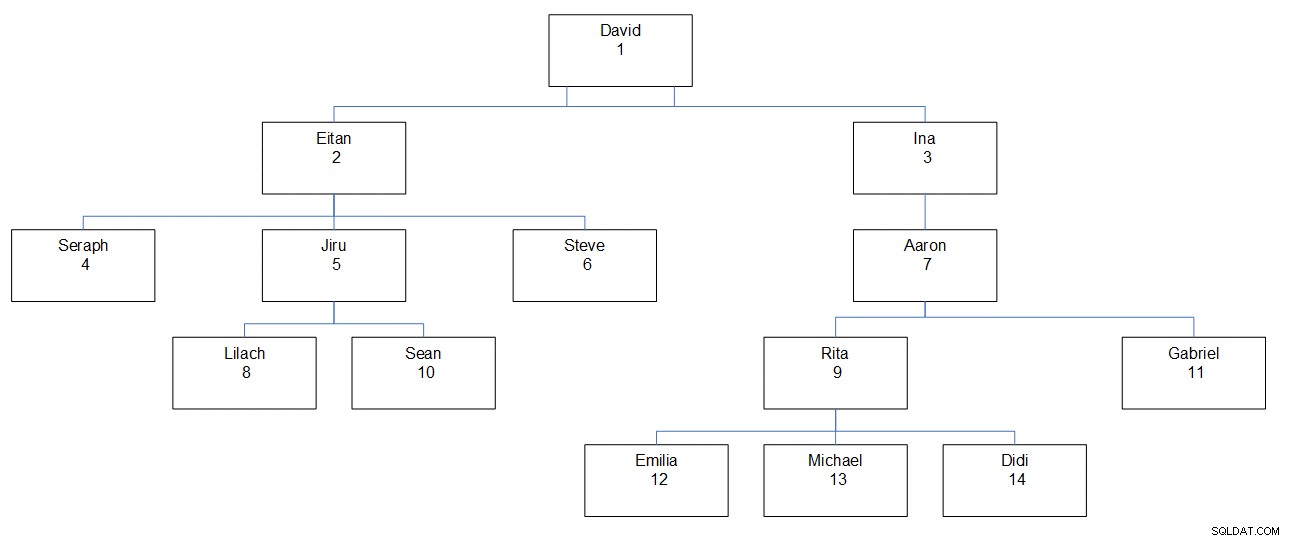 図1:従業員の階層
図1:従業員の階層
再帰的CTE
再帰的CTEには多くのユースケースがあります。使用の典型的なカテゴリは、従業員階層などのグラフ構造の処理に関係しています。グラフを含むタスクでは、多くの場合、任意の長さのパスをトラバースする必要があります。たとえば、あるマネージャーの従業員IDを指定して、入力従業員と、すべてのレベルの入力従業員のすべての部下を返します。つまり、直接および間接の部下。従う必要のあるレベルの数(グラフの次数)に既知の小さな制限がある場合は、部下のレベルごとに結合するクエリを使用できます。ただし、グラフの次数が潜在的に高い場合、ある時点で、多くの結合を持つクエリを作成することは実用的ではなくなります。もう1つのオプションは、命令型の反復コードを使用することですが、そのようなソリューションは時間がかかる傾向があります。これが再帰的CTEが本当に優れているところです。つまり、宣言型で簡潔で直感的なソリューションを使用できます。
検索機能とサイクリング機能について説明する興味深いものに進む前に、再帰CTEの基本から始めます。
CTEに対するクエリの構文は次のとおりです。
WITHAS
(
<テーブル式>
)
<外部クエリ>;
ここでは、WITH句を使用して定義された1つのCTEを示しますが、ご存知のように、コンマで区切って複数のCTEを定義できます。
通常の非再帰的CTEでは、内部テーブル式は1回だけ評価されるクエリに基づいています。再帰CTEでは、内部テーブル式は通常、メンバーと呼ばれる2つのクエリに基づいています。 、ただし、いくつかの特殊なニーズを処理するために2つ以上持つことができます。メンバーは通常、UNION ALL演算子によって区切られ、結果が統一されていることを示します。
メンバーはアンカーメンバーになることができます -一度だけ評価されることを意味します。または、再帰メンバーにすることもできます -空の結果セットが返されるまで、繰り返し評価されることを意味します。 1つのアンカーメンバーと1つの再帰メンバーに基づく再帰CTEに対するクエリの構文は次のとおりです。
WITHAS
(
UNION ALL
)
<外部クエリ>;
メンバーを再帰的にするのは、CTE名への参照があることです。この参照は、最後の実行の結果セットを表します。再帰メンバーの最初の実行では、CTE名への参照は、アンカーメンバーの結果セットを表します。 N> 1のN番目の実行では、CTE名への参照は、再帰メンバーの(N – 1)実行の結果セットを表します。前述のように、再帰メンバーが空のセットを返すと、そのセットは再度実行されません。外部クエリでのCTE名への参照は、アンカーメンバーの単一の実行と再帰メンバーのすべての実行の統合された結果セットを表します。
次のコードは、特定の入力マネージャーの従業員のサブツリーを返す前述のタスクを実装し、この例では従業員ID3をルート従業員として渡します。
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; アンカークエリは1回だけ実行され、入力ルート従業員(この場合は従業員3)の行を返します。
再帰クエリは、前のレベルの従業員のセット(マネージャーの場合はMとしてエイリアスされたCTE名への参照で表されます)を、部下の場合はSとしてエイリアスされたEmployeesテーブルの直接の部下と結合します。結合述語はS.mgrid=M.empidです。これは、部下のmgrid値がマネージャーのempid値と等しいことを意味します。再帰クエリは、次のように4回実行されます。
- 従業員3の部下を返します。出力:従業員7
- 従業員7の部下を返します。出力:従業員9および11
- 従業員9および11の部下を返します。出力:12、13、14
- 従業員12、13、および14の部下を返します。出力:空のセット;再帰が停止します
外部クエリでのCTE名への参照は、アンカークエリ(従業員3)の単一実行の統一された結果と再帰クエリ(従業員7、9、11、12、13および14)。このコードは次の出力を生成します:
empid mgrid empname ------ ------ -------- 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi
プログラミングソリューションの一般的な問題は、通常バグによって引き起こされる無限ループのような暴走コードです。再帰的CTEの場合、バグが再帰的メンバーの滑走路での実行につながる可能性があります。たとえば、入力従業員の部下を返すためのソリューションで、再帰メンバーの結合述語にバグがあったとします。 ON S.mgrid =M.empidを使用する代わりに、次のようにON S.mgrid=S.mgridを使用しました。
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C; テーブルにnull以外のマネージャーIDを持つ従業員が少なくとも1人いる場合、再帰メンバーを実行すると、空でない結果が返され続けます。再帰メンバーの暗黙的な終了条件は、その実行が空の結果セットを返すときであることに注意してください。空でない結果セットが返された場合、SQLServerはそれを再度実行します。 SQL Serverに再帰的な実行を制限するメカニズムがなかった場合、SQLServerは再帰的なメンバーを永久に繰り返し実行し続けることになります。安全対策として、T-SQLは、再帰メンバーの実行の最大許容数を制限するMAXRECURSIONクエリオプションをサポートしています。デフォルトでは、この制限は100に設定されていますが、負でないSMALLINT値に変更できます。0は制限がないことを表します。最大再帰制限を正の値Nに設定すると、再帰メンバーのN+1回の試行がエラーで中止されます。たとえば、上記のバグのあるコードをそのまま実行すると、デフォルトの最大再帰制限である100に依存するため、再帰メンバーの101実行は失敗します。
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...メッセージ530、レベル16、状態1、行121
ステートメントは終了しました。ステートメントが完了する前に、最大再帰100が使い果たされました。
組織では、従業員の階層が6つの管理レベルを超えないと想定しても安全だとしましょう。次のように、最大再帰制限を100からはるかに小さい数(たとえば、安全のために10など)に減らすことができます。
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C
OPTION (MAXRECURSION 10); これで、再帰メンバーの実行が暴走するバグがある場合、101回の実行ではなく、11回の再帰メンバーの実行の試行で発見されます。
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...メッセージ530、レベル16、状態1、行149
ステートメントは終了しました。ステートメントが完了する前に、最大再帰10が使い果たされました。
最大再帰制限は、バグのある暴走コードの実行を中止するための安全対策として主に使用する必要があることに注意することが重要です。制限を超えると、コードの実行がエラーで中止されることに注意してください。このオプションを使用して、フィルタリングの目的でアクセスするレベルの数を制限しないでください。コードに問題がないときにエラーが生成されないようにする必要があります。
フィルタリングの目的で、プログラムでアクセスするレベルの数を制限できます。入力ルート従業員と比較した現在の従業員のレベル番号を追跡するlvlという列を定義します。アンカークエリでは、lvl列を定数0に設定します。再帰クエリでは、マネージャーのlvl値に1を加えた値に設定します。入力ルートの下の@maxlevelと同じ数のレベルをフィルタリングするには、述語M.lvl <@再帰クエリのON句へのmaxlevel。たとえば、次のコードは、従業員3と従業員3の部下の2つのレベルを返します。
DECLARE @root AS INT = 3, @maxlevel AS INT = 2;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.lvl < @maxlevel
)
SELECT empid, mgrid, empname, lvl
FROM C; このクエリは次の出力を生成します:
empid mgrid empname lvl ------ ------ -------- ---- 3 1 Ina 0 7 3 Aaron 1 9 7 Rita 2 11 7 Gabriel 2
標準のSEARCH句とCYCLE句
ISO / IEC SQL標準は、再帰CTEの2つの非常に強力なオプションを定義しています。 1つは再帰的な検索順序を制御するSEARCHと呼ばれる句で、もう1つはトラバースされたパスのサイクルを識別するCYCLEと呼ばれる句です。 2つの句の標準構文は次のとおりです。
7.18<検索またはサイクル句>機能
再帰クエリ式の結果で順序付けと循環検出情報の生成を指定します。
フォーマット
<リスト要素付き>::=
<クエリ名>[<左パレン><列リスト付き><右パレン>]
AS<テーブルサブクエリ>[<検索またはサイクル句>]
<検索またはサイクル句>::=
<検索句>| <サイクル句>| <検索句><サイクル句>
<検索句>::=
SEARCH<再帰検索順序>SET<シーケンス列>
<再帰検索順序>::=
DEPTH FIRSTBY<列名リスト>| BREADTH FIRSTBY<列名リスト>
<シーケンス列>::=<列名>
<サイクル句>::=
CYCLE<サイクル列リスト>SET<サイクルマーク列> TO<サイクルマーク値>
DEFAULT<非サイクルマーク値>USING<パス列>
<サイクル列リスト>::=<サイクル列>[{<カンマ><サイクル列>}… ]
<サイクル列>::=<列名>
<サイクルマーク列>::=<列名>
<パス列>::=<列名>
<サイクルマーク値>::=<値式>
<非サイクルマーク値>::=<値式>
執筆時点では、T-SQLはこれらのオプションをサポートしていませんが、次のリンクで、将来T-SQLに含めることを求める機能改善リクエストを見つけて、投票することができます。
- T-SQLの再帰CTEにISO/IECSQLSEARCH句のサポートを追加する
- T-SQLの再帰CTEにISO/IECSQLCYCLE句のサポートを追加
次のセクションでは、2つの標準オプションについて説明し、現在T-SQLで利用できる論理的に同等の代替ソリューションも提供します。
SEARCH句
標準のSEARCH句は、再帰的な検索順序を、指定された順序列によってBREADTHFIRSTまたはDEPTHFIRSTとして定義し、訪問したノードの順序位置を使用して新しいシーケンス列を作成します。 BREADTH FIRSTを指定して、最初に各レベル(幅)を検索し、次にレベル(深さ)を検索します。 DEPTH FIRSTを指定して、最初に下(深さ)を検索し、次に横(幅)を検索します。
外部クエリの直前にSEARCH句を指定します。
幅優先探索の順序の例から始めます。この機能はT-SQLでは使用できないため、SQLServerまたはAzureSQLDatabaseで標準句を使用する例を実際に実行することはできません。次のコードは、従業員1のサブツリーを返し、empidによる幅優先探索順序を要求し、訪問したノードの序数位置を使用してseqbreadthというシーケンス列を作成します。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH BREADTH FIRST BY empid SET seqbreadth
--------------------------------------------
SELECT empid, mgrid, empname, seqbreadth
FROM C
ORDER BY seqbreadth; このコードの望ましい出力は次のとおりです。
empid mgrid empname seqbreadth ------ ------ -------- ----------- 1 NULL David 1 2 1 Eitan 2 3 1 Ina 3 4 2 Seraph 4 5 2 Jiru 5 6 2 Steve 6 7 3 Aaron 7 8 5 Lilach 8 9 7 Rita 9 10 5 Sean 10 11 7 Gabriel 11 12 9 Emilia 12 13 9 Michael 13 14 9 Didi 14
seqbreadth値がempid値と同じであるように見えるという事実に混乱しないでください。これは、作成したサンプルデータでempid値を手動で割り当てた結果として偶然に発生したものです。
図2は、従業員階層をグラフで表したもので、点線はノードが検索された幅優先探索を示しています。 empid値は従業員名のすぐ下に表示され、割り当てられたseqbreadth値は各ボックスの左下隅に表示されます。
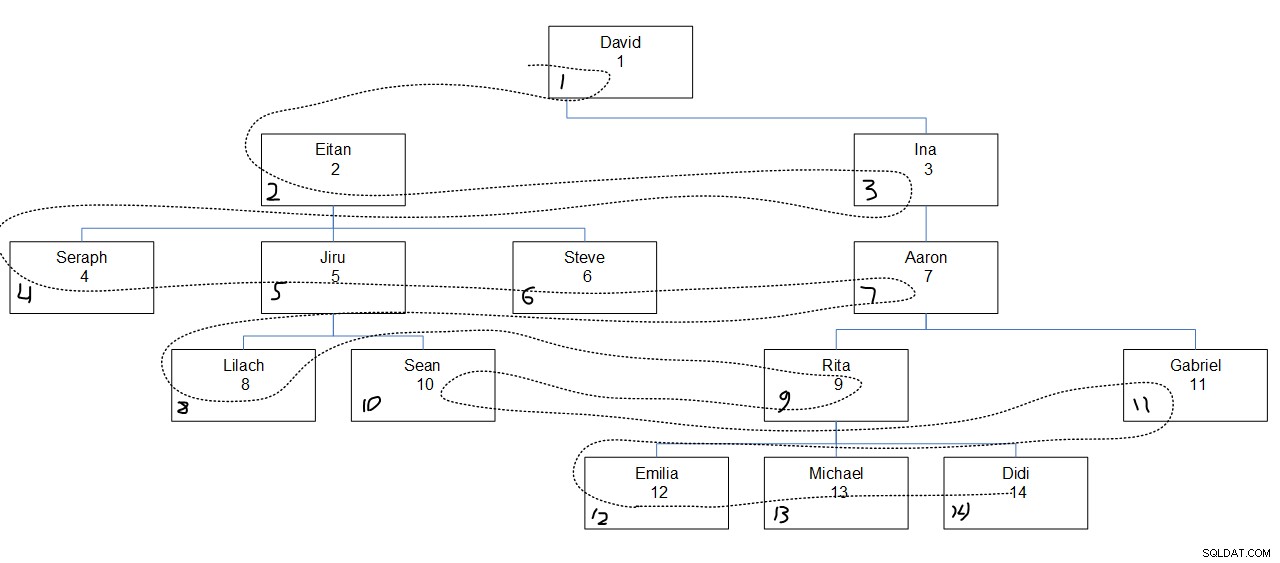 図2:幅優先探索
図2:幅優先探索
ここで興味深いのは、各レベル内で、ノードの親の関連付けに関係なく、指定された列の順序(この場合はempid)に基づいてノードが検索されることです。たとえば、第4レベルでは、リラックが最初にアクセスされ、リタが2番目、ショーンが3番目、ガブリエルが最後にアクセスされることに注意してください。これは、第4レベルのすべての従業員の中で、それが彼らの気の利いた価値観に基づく順序だからです。リラックとショーンは同じマネージャーのジルの直属の部下であるため、連続して検索されることになっているわけではありません。
標準のSAERCHDEPTHFIRSTオプションと論理的に同等のT-SQLソリューションを思いつくのはかなり簡単です。ルートに対するノードのレベルを追跡するために、前に示したようにlvlという列を作成します(最初のレベルの場合は0、2番目のレベルの場合は1など)。次に、ROW_NUMBER関数を使用して、外部クエリで目的の結果シーケンス列を計算します。ウィンドウの順序として、最初にlvlを指定し、次に目的の順序列(この場合はempid)を指定します。完全なソリューションのコードは次のとおりです。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadth
FROM C
ORDER BY seqbreadth; 次に、深さ優先探索の順序を調べてみましょう。標準によれば、次のコードは従業員1のサブツリーを返し、empidによる深さ優先探索順序を要求し、検索されたノードの順序位置を使用してseqdepthというシーケンス列を作成します。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH DEPTH FIRST BY empid SET seqdepth
----------------------------------------
SELECT empid, mgrid, empname, seqdepth
FROM C
ORDER BY seqdepth; このコードの望ましい出力は次のとおりです。
empid mgrid empname seqdepth ------ ------ -------- --------- 1 NULL David 1 2 1 Eitan 2 4 2 Seraph 3 5 2 Jiru 4 8 5 Lilach 5 10 5 Sean 6 6 2 Steve 7 3 1 Ina 8 7 3 Aaron 9 9 7 Rita 10 12 9 Emilia 11 13 9 Michael 12 14 9 Didi 13 11 7 Gabriel 14
目的のクエリ出力を見ると、シーケンス値が以前のように割り当てられた理由を理解するのはおそらく難しいでしょう。図3が役立つはずです。従業員階層をグラフィカルに表現し、深さ優先探索の順序を反映した点線と、各ボックスの左下隅に割り当てられたシーケンス値を示します。
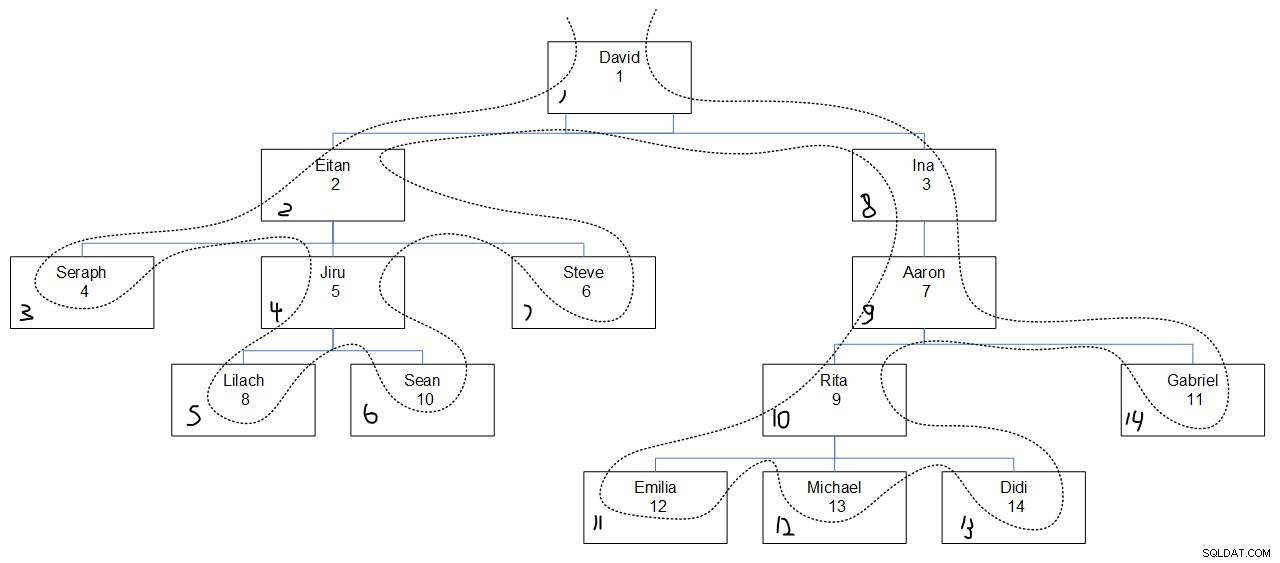 図3:最初に深さを検索
図3:最初に深さを検索
標準のSEARCHDEPTHFIRSTオプションと論理的に同等のT-SQLソリューションを考え出すのは少し注意が必要ですが、実行可能です。ソリューションを2つのステップで説明します。
ステップ1では、ノードごとに、ノードの祖先ごとのセグメントで構成されるバイナリソートパスを計算します。各セグメントは、その兄弟間の祖先のソート位置を反映します。このパスは、lvl列を計算する方法と同様に作成します。つまり、アンカークエリのルートノードの空のバイナリ文字列から始めます。次に、再帰クエリで、親のパスを、バイナリセグメントに変換した後、兄弟間のノードの並べ替え位置と連結します。 ROW_NUMBER関数を使用して、親(この場合はmgrid)で分割され、関連する順序付け列(この場合はempid)で順序付けられた位置を計算します。親がグラフに含めることができる直接の子の最大数に応じて、行番号を十分なサイズのバイナリ値に変換します。 BINARY(1)は親ごとに最大255の子をサポートし、BINARY(2)は65,535をサポートし、BINARY(3):16,777,215、BINARY(4):4,294,967,295をサポートします。再帰CTEでは、アンカークエリと再帰クエリの対応する列は同じタイプである必要があります 、したがって、ソートパスを両方で同じサイズのバイナリ値に変換するようにしてください。
ソリューションのステップ1を実装するコードは次のとおりです(セグメントごとにBINARY(1)で十分であり、マネージャーごとに直属の部下が255人以下であると想定しています):
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, sortpath
FROM C; このコードは次の出力を生成します:
empid mgrid empname sortpath ------ ------ -------- ----------- 1 NULL David 0x 2 1 Eitan 0x01 3 1 Ina 0x02 7 3 Aaron 0x0201 9 7 Rita 0x020101 11 7 Gabriel 0x020102 12 9 Emilia 0x02010101 13 9 Michael 0x02010102 14 9 Didi 0x02010103 4 2 Seraph 0x0101 5 2 Jiru 0x0102 6 2 Steve 0x0103 8 5 Lilach 0x010201 10 5 Sean 0x010202
ここでクエリしている単一のサブツリーのルートノードのソートパスとして、空のバイナリ文字列を使用したことに注意してください。アンカーメンバーが複数のサブツリールートを返す可能性がある場合は、再帰クエリで計算するのと同じように、アンカークエリでROW_NUMBERの計算に基づくセグメントから開始するだけです。このような場合、並べ替えパスは1セグメント長くなります。
手順2で行う必要があるのは、外部クエリでsortpath順に並べられた行番号を計算することで、目的の結果のseqdepth列を作成することです。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth
FROM C
ORDER BY seqdepth; このソリューションは、前に示した標準のSEARCHDEPTHFIRSTオプションを目的の出力とともに使用するのと論理的に同等です。
深さ優先探索順序(この場合はseqdepth)を反映するシーケンス列ができたら、もう少し努力するだけで、階層の非常に優れた視覚的描写を生成できます。前述のlvl列も必要になります。シーケンス列で外部クエリを並べ替えます。ノードを表すために使用する属性(この場合はempnameなど)を返し、その前に文字列('|'など)を付けてlvl回複製します。このような視覚的描写を実現するための完全なコードは次のとおりです。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, empname, 0 AS lvl,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.empname, M.lvl + 1 AS lvl,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth,
REPLICATE(' | ', lvl) + empname AS emp
FROM C
ORDER BY seqdepth; このコードは次の出力を生成します:
empid seqdepth emp ------ --------- -------------------- 1 1 David 2 2 | Eitan 4 3 | | Seraph 5 4 | | Jiru 8 5 | | | Lilach 10 6 | | | Sean 6 7 | | Steve 3 8 | Ina 7 9 | | Aaron 9 10 | | | Rita 12 11 | | | | Emilia 13 12 | | | | Michael 14 13 | | | | Didi 11 14 | | | Gabriel
かっこいいです!
CYCLE句
グラフ構造にはサイクルがある場合があります。これらのサイクルは有効または無効である可能性があります。有効なサイクルの例は、都市と町を結ぶ高速道路と道路を表すグラフです。これが閉路グラフと呼ばれるものです。 。逆に、この場合のような従業員階層を表すグラフには、サイクルがあるとは想定されていません。これが非周期的と呼ばれるものです。 グラフ。ただし、誤った更新が原因で、意図せずにサイクルが発生したとします。たとえば、次のコードを実行して、誤ってCEO(従業員1)のマネージャーIDを従業員14に更新したとします。
UPDATE Employees SET mgrid = 14 WHERE empid = 1;
これで、従業員階層に無効なサイクルがあります。
サイクルが有効か無効かにかかわらず、グラフ構造をトラバースするときは、循環パスを繰り返し追跡し続けたくないことは確かです。どちらの場合も、同じノードの最初以外のオカレンスが見つかったらパスの追跡を停止し、そのようなパスを循環としてマークします。
では、再帰クエリを使用してサイクルがあるグラフをクエリすると、それらを検出するメカニズムがない場合はどうなりますか?これは実装によって異なります。 SQL Serverでは、ある時点で最大再帰制限に達し、クエリが中止されます。たとえば、サイクルを導入した上記の更新を実行したと仮定して、次の再帰クエリを実行して、従業員1のサブツリーを特定してみてください:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; このコードは明示的な最大再帰制限を設定していないため、デフォルトの制限である100が想定されています。 SQL Serverは、完了する前にこのコードの実行を中止し、エラーを生成します:
empid mgrid empname ------ ------ -------- 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron ...メッセージ530、レベル16、状態1、行432
ステートメントは終了しました。ステートメントが完了する前に、最大再帰100が使い果たされました。
SQL標準では、再帰CTE用にCYCLEと呼ばれる句が定義されており、グラフ内のサイクルを処理できます。この句は、外部クエリの直前に指定します。 SEARCH句も存在する場合は、最初にそれを指定し、次にCYCLE句を指定します。 CYCLE句の構文は次のとおりです。
CYCLE<サイクル列リスト>SET<サイクルマーク列>TO<サイクルマーク値>DEFAULT<非サイクルマーク値>
USING<パス列>
サイクルの検出は、指定されたサイクル列リストに基づいています。 。たとえば、従業員階層では、この目的でempid列を使用することをお勧めします。同じempid値が2回目に表示されると、サイクルが検出され、クエリはそのようなパスをそれ以上追跡しません。新しいサイクルマーク列を指定します これは、サイクルが見つかったかどうか、およびサイクルマークとしての独自の値を示します。 および非サイクルマーク 値。たとえば、1と0、「はい」と「いいえ」、またはその他の任意の値を選択できます。 USING句で、これまでに見つかったノードのパスを保持する新しい配列列名を指定します。
入力ルート従業員の部下へのリクエストを処理する方法は次のとおりです。empid列に基づいてサイクルを検出し、サイクルが検出された場合はサイクルマーク列に1を示し、それ以外の場合は0を示します。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
CYCLE empid SET cycle TO 1 DEFAULT 0
------------------------------------
SELECT empid, mgrid, empname
FROM C; このコードの望ましい出力は次のとおりです。
empid mgrid empname cycle ------ ------ -------- ------ 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
T-SQLは現在CYCLE句をサポートしていませんが、論理的に同等の回避策があります。これには3つのステップが含まれます。以前に、再帰的な検索順序を処理するためのバイナリソートパスを作成したことを思い出してください。同様に、ソリューションの最初のステップとして、現在のノード(現在のノードを含む)につながる祖先のノードID(この場合は従業員ID)で構成される文字列ベースの祖先パスを作成します。ノードIDの間に、最初と最後に1つずつ、区切り文字が必要です。
このような祖先のパスを作成するためのコードは次のとおりです。
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath
FROM C; このコードは次の出力を生成しますが、引き続き循環パスを追跡しているため、最大再帰制限を超えると、完了する前に中止されます。
empid mgrid empname ancpath ------ ------ -------- ------------------- 1 14 David .1. 2 1 Eitan .1.2. 3 1 Ina .1.3. 7 3 Aaron .1.3.7. 9 7 Rita .1.3.7.9. 11 7 Gabriel .1.3.7.11. 12 9 Emilia .1.3.7.9.12. 13 9 Michael .1.3.7.9.13. 14 9 Didi .1.3.7.9.14. 1 14 David .1.3.7.9.14.1. 2 1 Eitan .1.3.7.9.14.1.2. 3 1 Ina .1.3.7.9.14.1.3. 7 3 Aaron .1.3.7.9.14.1.3.7. ...メッセージ530、レベル16、状態1、行492
ステートメントは終了しました。ステートメントが完了する前に、最大再帰100が使い果たされました。
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' 。
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath, cycle
FROM C; This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle ------ ------ -------- ------------------- ------ 1 14 David .1. 0 2 1 Eitan .1.2. 0 3 1 Ina .1.3. 0 7 3 Aaron .1.3.7. 0 9 7 Rita .1.3.7.9. 0 11 7 Gabriel .1.3.7.11. 0 12 9 Emilia .1.3.7.9.12. 0 13 9 Michael .1.3.7.9.13. 0 14 9 Didi .1.3.7.9.14. 0 1 14 David .1.3.7.9.14.1. 1 2 1 Eitan .1.3.7.9.14.1.2. 0 3 1 Ina .1.3.7.9.14.1.3. 1 7 3 Aaron .1.3.7.9.14.1.3.7. 1 ...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.cycle = 0
)
SELECT empid, mgrid, empname, cycle
FROM C; This code runs to completion, and generates the following output:
empid mgrid empname cycle ------ ------ -------- ----------- 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid = NULL WHERE empid = 1;
Run the recursive query and you will find that there are no cycles present.
結論
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.