これは、数級数ジェネレータの課題に対するソリューションに関するシリーズの第2部です。先月、定数に基づく行を持つテーブル値コンストラクターを使用して、その場で行を生成するソリューションについて説明しました。これらのソリューションに関連するI/O操作はありませんでした。今月は、行を事前入力した物理ベーステーブルをクエリするソリューションに焦点を当てます。このため、先月行ったようにソリューションの時間プロファイルを報告するだけでなく、新しいソリューションのI/Oプロファイルも報告します。アイデアやコメントを共有してくれたAlanBurstein、Joe Obbish、Adam Machanic、Christopher Ford、Jeff Moden、Charlie、NoamGr、Kamil Kosno、Dave Mason、John Nelson#2、EdWagnerに改めて感謝します。
これまでで最速のソリューション
まず、簡単なリマインダーとして、先月の記事から、dbo.GetNumsAlanCharlieItzikBatchと呼ばれるインラインTVFとして実装された最速のソリューションを確認しましょう。
tempdbでテストを行い、IOとTIMEの統計を有効にします:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
先月の最速のソリューションは、バッチ処理を取得するために列ストアインデックスを持つダミーテーブルとの結合を適用します。ダミーテーブルを作成するコードは次のとおりです。
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
そして、これがdbo.GetNumsAlanCharlieItzikBatch関数の定義を含むコードです:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO 先月、次のコードを使用して、SSMSでの実行後に結果を破棄して出力行の戻りを抑制した後、1億行で関数のパフォーマンスをテストしました。
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
この実行で取得した時間統計は次のとおりです。
CPU時間=16031ミリ秒、経過時間=17172ミリ秒。Joe Obbishは、実行時間の大部分が非同期ネットワークI / O待機(ASYNC_NETWORK_IO待機タイプ)によるものであるという意味で、このテストには実際のシナリオの反映が欠けている可能性があることを正しく指摘しました。実際のクエリプランのルートノードのプロパティページを確認することで最大の待機時間を確認するか、待機情報を使用して拡張イベントセッションを実行できます。 SSMSでの実行後に結果の破棄を有効にしても、SQLServerが結果行をSSMSに送信することを妨げることはありません。 SSMSがそれらを印刷できないようにするだけです。問題は、関数を使用して多数の系列を生成する場合でも、実際のシナリオで大きな結果セットをクライアントに返す可能性はどのくらいあるかということです。おそらく、クエリ結果をテーブルに書き込んだり、関数の結果をクエリの一部として使用して、最終的に小さな結果セットを生成したりすることがよくあります。これを理解する必要があります。 SELECT INTOステートメントを使用して結果セットを一時テーブルに書き込むか、結果列の値を変数に割り当てる割り当てSELECTステートメントでAlanBursteinのトリックを使用することができます。
変数割り当てオプションを使用するように最後のテストを変更する方法は次のとおりです。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
このテストで得た時間統計は次のとおりです。
CPU時間=8641ミリ秒、経過時間=8645ミリ秒。今回は、待機情報に非同期ネットワークI / O待機がなく、実行時間が大幅に短縮されていることがわかります。
関数をもう一度テストします。今回は順序を追加します:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
この実行で次のパフォーマンス統計を取得しました:
CPU時間=9360ミリ秒、経過時間=9551ミリ秒。列nは、列rownumに関して順序を保持する式に基づいているため、このクエリのプランには並べ替え演算子は必要ないことを思い出してください。これは、先月取り上げたCharliの定数畳み込みのトリックのおかげです。両方のクエリの計画(順序付けなしのクエリと順序付けありのプランは同じであるため、パフォーマンスは同じになる傾向があります。
図1は、先月のソリューションで得られたパフォーマンスの数値をまとめたものです。今回は、実行後に結果を破棄するのではなく、テストで変数の割り当てを使用しています。
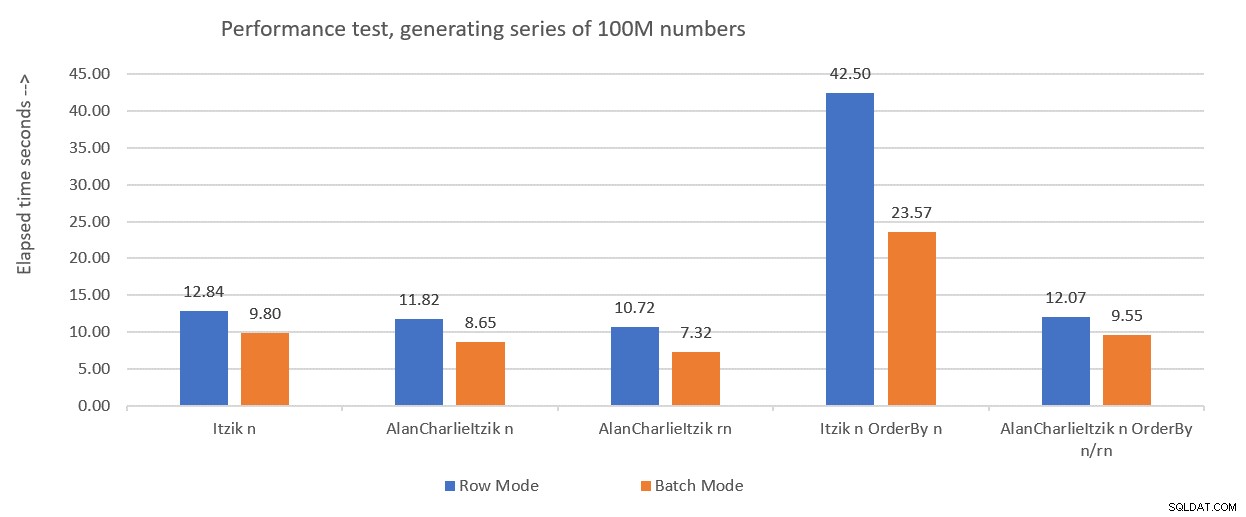 図1:変数割り当てを使用したこれまでのパフォーマンスの概要
図1:変数割り当てを使用したこれまでのパフォーマンスの概要
変数割り当て手法を使用して、この記事で紹介する残りのソリューションをテストします。変数の割り当て、SELECT INTO、実行後の結果の破棄、またはその他の手法を使用して、実際の状況を最もよく反映するようにテストを調整してください。
MAXDOP1を使用せずにシリアルプランを強制するためのヒント
新しいソリューションを紹介する前に、ちょっとしたヒントを取り上げたかっただけです。一部のソリューションは、シリアルプランを使用する場合に最適に機能することを思い出してください。これを強制する明白な方法は、MAXDOP1クエリヒントを使用することです。並列処理を有効にしたい場合と無効にしたい場合は、これが正しい方法です。ただし、シナリオの可能性は低くなりますが、関数を使用するときに常にシリアルプランを強制したい場合はどうなりますか?
これを達成するための秘訣があります。クエリでのインライン化不可能なスカラーUDFの使用は、並列処理の阻害要因です。スカラーUDFインライン化阻害剤の1つは、SYSDATETIMEなどの時間依存の組み込み関数を呼び出すことです。したがって、インライン化できないスカラーUDFの例を次に示します。
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
もう1つのオプションは、戻り値として定数のみを使用してUDFを定義し、そのヘッダーでINLINE=OFFオプションを使用することです。ただし、このオプションは、スカラーUDFインライン化を導入したSQLServer2019以降でのみ使用できます。上記の推奨機能を使用すると、古いバージョンのSQLServerでそのまま作成できます。
次に、dbo.GetNumsAlanCharlieItzikBatch関数の定義を変更して、dbo.MySYSDATETIMEへのダミー呼び出しを行います(それに基づいて列を定義しますが、返されたクエリの列を参照しないでください)。
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO これで、MAXDOP 1を指定せずにパフォーマンステストを再実行しても、シリアルプランを取得できます。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
ただし、この関数を使用するクエリはすべてシリアルプランを取得するようになることを強調することが重要です。並列プランの恩恵を受けるクエリで関数が使用される可能性がある場合は、このトリックを使用しない方がよいでしょう。シリアルプランが必要な場合は、MAXDOP1を使用してください。
JoeObbishによる解決策
ジョーのソリューションはかなり創造的です。ソリューションについての彼自身の説明は次のとおりです。
「私は、134,217,728行の連続した整数を使用してクラスター化列ストアインデックス(CCI)を作成することを選択しました。この関数は、テーブルを最大32回参照して、結果セットに必要なすべての行を取得します。データが適切に圧縮され(1行あたり3バイト未満)、バッチモードが「無料」で利用できるため、CCIを選択しました。以前の経験では、CCIからの連続番号の読み取りは、他の方法で生成するよりも高速であることが示されています。 」前述のように、Joeは、行をSSMSに送信することによって生成される非同期ネットワークI / O待機のために、元のパフォーマンステストが大幅に歪んでいることにも言及しました。したがって、ここで実行するすべてのテストでは、変数の割り当てでAlanのアイデアを使用します。実際の状況を最もよく反映しているものに基づいて、テストを調整してください。
ジョーがテーブルdbo.GetNumsObbishTableを作成し、134,217,728行を入力するために使用したコードは次のとおりです。
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
このコードが私のマシンで完了するのに1:04分かかりました。
次のコードを実行すると、このテーブルのスペース使用量を確認できます。
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
約350MBのスペースを使用しました。この記事で紹介する他のソリューションと比較すると、このソリューションはかなり多くのスペースを使用します。
SQL Serverの列ストアアーキテクチャでは、行グループは2 ^ 20=1,048,576行に制限されています。次のコードを使用して、このテーブルに対して作成された行グループの数を確認できます。
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); 128の行グループを取得しました。
dbo.GetNumsObbish関数を定義したコードは次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
32個の個別のクエリは、互いに素な134,217,728整数のサブ範囲を生成します。これらのサブ範囲は、統合されると、完全な中断のない範囲1〜4,294,967,296を生成します。このソリューションで本当に賢いのは、個々のクエリが使用するWHEREフィルター述語です。 SQL ServerがインラインTVFを処理するとき、最初にパラメーターの埋め込みを適用し、パラメーターを入力定数に置き換えていることを思い出してください。 SQL Serverは、入力範囲と交差しないサブ範囲を生成するクエリを最適化できます。たとえば、入力範囲1〜100,000,000を要求すると、最初のクエリのみが関連し、残りはすべて最適化されます。この場合の計画には、テーブルの1つのインスタンスのみへの参照が含まれます。それはかなり素晴らしいです!
1から1億の範囲で関数のパフォーマンスをテストしてみましょう:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
このクエリの計画を図2に示します。
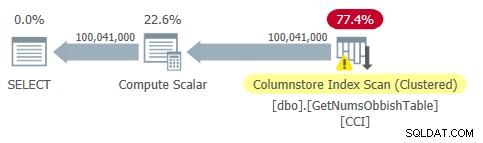 図2:dbo.GetNumsObbishの計画、1億行、順序なし
図2:dbo.GetNumsObbishの計画、1億行、順序なし
この計画では、実際にテーブルのCCIへの参照が1つだけ必要であることに注意してください。
この実行について、次の時間統計を取得しました。
これは非常に印象的で、私がテストした他のどの製品よりもはるかに高速です。
この実行で取得したI/O統計は次のとおりです。
テーブル'GetNumsObbishTable'。スキャンカウント1、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り32928 、lob物理読み取り0、lobページサーバー読み取り0、lob先読み読み取り0、lobページサーバー先読み読み取り0。テーブル'GetNumsObbishTable'。 セグメントは96を読み取ります 、セグメントは32をスキップしました。
このソリューションのI/Oプロファイルは、他のソリューションと比較した場合の欠点の1つであり、この実行で30Kを超えるLOB論理読み取りが発生します。
複数の134,217,728整数のサブ範囲を越える場合、プランにテーブルへの複数の参照が含まれることを確認するには、たとえば、1〜400,000,000の範囲の関数をクエリします。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
この実行の計画を図3に示します。
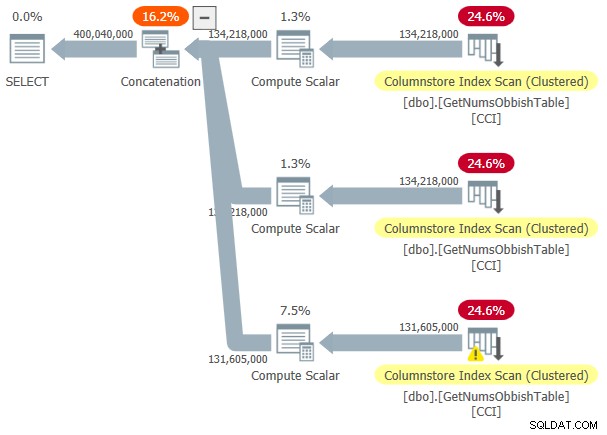 図3:dbo.GetNumsObbishの計画、4億行、順序なし
図3:dbo.GetNumsObbishの計画、4億行、順序なし
要求された範囲は3つの134,217,728整数のサブ範囲を超えたため、計画にはテーブルのCCIへの3つの参照が示されています。
この実行で取得した時間統計は次のとおりです。
CPU時間=20610ミリ秒、経過時間=20628ミリ秒。そして、これがそのI /O統計です:
テーブル'GetNumsObbishTable'。スキャンカウント3、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り131026 、lob物理読み取り0、lobページサーバー読み取り0、lob先読み読み取り0、lobページサーバー先読み読み取り0。テーブル'GetNumsObbishTable'。 セグメントは382を読み取ります 、セグメントスキップ2。
今回のクエリ実行では、13万を超えるLOB論理読み取りが発生しました。
I / Oコストを抑えることができ、番号シリーズを順番に処理する必要がない場合、これは優れたソリューションです。ただし、シリーズを順番に処理する必要がある場合、このソリューションでは、プランに並べ替え演算子が含まれます。注文した結果をリクエストするテストは次のとおりです。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
この実行の計画を図4に示します。
 図4:dbo.GetNumsObbishの計画、1億行、注文済み
図4:dbo.GetNumsObbishの計画、1億行、注文済み
この実行で取得した時間統計は次のとおりです。
CPU時間=44516ミリ秒、経過時間=34836ミリ秒。ご覧のとおり、明示的な並べ替えにより、実行時間が1桁増加すると、パフォーマンスが大幅に低下しました。
この実行で取得したI/O統計は次のとおりです。
テーブル'GetNumsObbishTable'。スキャンカウント4、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り32928 、lob物理読み取り0、lobページサーバー読み取り0、lob先読み読み取り0、lobページサーバー先読み読み取り0。テーブル'GetNumsObbishTable'。 セグメントは96を読み取ります 、セグメントは32をスキップしました。
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。
WorktableがSTATISTICSIOの出力に表示されたことを確認します。これは、ソートがtempdbに流出する可能性があるためです。その場合、ワークテーブルが使用されます。この実行はこぼれなかったため、このエントリの数値はすべてゼロです。
John Nelson#2、Dave、Joe、Alan、Charlie、Itzikによるソリューション
John Nelson#2は、そのシンプルさが美しいソリューションを投稿しました。さらに、デイブ、ジョー、アラン、チャーリー、そして私自身による他のソリューションからのアイデアや提案が含まれています。
Joeのソリューションと同様に、JohnはCCIを使用して、高レベルの圧縮と「無料の」バッチ処理を実現することにしました。 Johnだけが、ビット列にダミーのNULLマーカーを含む4B行でテーブルを埋め、ROW_NUMBER関数に数値を生成させることにしました。保存された値はすべて同じであるため、繰り返し値を圧縮すると、必要なスペースが大幅に少なくなり、Joeのソリューションと比較してI/Oが大幅に少なくなります。列ストア圧縮は、行グループの列セグメント内のそのような連続する各セクションを、連続して繰り返される発生の数とともに1回だけ表すことができるため、繰り返し値を非常にうまく処理します。すべての行の値(NULLマーカー)が同じであるため、理論的には、行グループごとに1回だけ出現する必要があります。 4B行の場合、4,096行グループになるはずです。それぞれに単一の列セグメントがあり、スペース使用量の要件はほとんどありません。
アーカイブ圧縮を使用してCCIとして実装された、テーブルを作成してデータを設定するコードは次のとおりです。
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO このソリューションの主な欠点は、このテーブルにデータを入力するのにかかる時間です。このコードは、並列処理を許可する場合は私のマシンで12:32分かかり、シリアルプランを強制する場合は15:17分かかりました。
データ負荷の最適化に取り組むことができることに注意してください。たとえば、Johnは、OSTRESS.EXEとの32の同時接続を使用して行をロードするソリューションをテストしました。各接続は、2 ^ 20行(最大行グループサイズ)の128ラウンドの挿入を実行します。このソリューションにより、ジョンの読み込み時間が3分の1に短縮されました。ジョンが使用したコードは次のとおりです。
ostress -S(local)\ YourSQLInstance -E -dtempdb -n32 -r128 -Q "WITH L0 AS(SELECT CAST(NULL AS BIT)AS b FROM(VALUES(1)、(1)、(1)、(1) 、(1)、(1)、(1)、(1)、(1)、(1)、(1)、(1)、(1)、(1)、(1)、(1))AS D(b))、L1 AS(SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B)、L2 AS(SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B)、nulls(b)AS(SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)INSERT INTO dbo.NullBits4B(b)SELECT TOP(1048576)b FROM nulls OPTION(MAXDOP 1); "それでも、ロード時間は分単位です。幸いなことに、このデータの読み込みは1回だけ実行する必要があります。
すばらしいニュースは、テーブルに必要なスペースが少ないことです。次のコードを使用して、スペースの使用状況を確認します。
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
1.64MBを取得しました。テーブルに4B行があることを考えると、これは驚くべきことです。
次のコードを使用して、作成された行グループの数を確認してください。
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); 予想どおり、行グループの数は4,096です。
dbo.GetNumsJohn2DaveObbishAlanCharlieItzik関数の定義は、非常に単純になります。
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
ご覧のとおり、テーブルに対する単純なクエリでは、ROW_NUMBER関数を使用して基本行番号(rownum列)を計算し、外部クエリでは、dbo.GetNumsAlanCharlieItzikBatchと同じ式を使用してrn、op、およびnを計算します。ここでも、rnとnの両方がrownumに関して順序を保持しています。
関数のパフォーマンスをテストしてみましょう:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
この実行について、図5に示す計画を取得しました。
 図5:dbo.GetNumsJohn2DaveObbishAlanCharlieItzikの計画
図5:dbo.GetNumsJohn2DaveObbishAlanCharlieItzikの計画
このテストで得た時間統計は次のとおりです。
CPU時間=7593ミリ秒、経過時間=7590ミリ秒。
ご覧のとおり、実行時間はJoeのソリューションほど高速ではありませんが、テストした他のすべてのソリューションよりも高速です。
このテストで取得したI/O統計は次のとおりです。
テーブル'NullBits4B'。 セグメントは96を読み取ります 、セグメントスキップ0
I / O要件がJoeのソリューションよりも大幅に低いことに注意してください。
このソリューションのもう1つの優れた点は、注文した一連の番号を処理する必要がある場合でも、追加料金を支払わないことです。これは、結果をrnまたはnのどちらで並べ替えたかに関係なく、プランで明示的な並べ替え操作が行われないためです。
これを実証するためのテストは、次のとおりです。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
図5で前に示したのと同じプランが得られます。
このテストで得た時間統計は次のとおりです。
CPU時間=7578ミリ秒、経過時間=7582ミリ秒。そして、ここにI /O統計があります:
テーブル'NullBits4B'。スキャンカウント1、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り194 、lob物理読み取り0、lobページサーバー読み取り0、lob先読み読み取り0、lobページサーバー先読み読み取り0。テーブル'NullBits4B'。 セグメントは96を読み取ります 、セグメントは0をスキップしました。
基本的に、注文なしのテストと同じです。
ソリューション2byJohn Nelson#2、Dave Mason、Joe Obbish、Alan、Charlie、Itzik
ジョンのソリューションは高速でシンプルです。それは素晴らしいです。 1つの欠点は、ロード時間です。ロードは1回だけ行われるため、これが問題にならない場合もあります。ただし、問題がある場合は、テーブルに4B行ではなく102,400行を入力し、テーブルの2つのインスタンス間のクロス結合とTOPフィルターを使用して、必要な最大4B行を生成できます。 4B行を取得するには、テーブルに65,536行を入力してから、クロス結合を適用するだけで十分であることに注意してください。ただし、行ストアベースのデルタストアにロードするのではなく、データをすぐに圧縮するには、少なくとも102,400行のテーブルをロードする必要があります。
テーブルを作成してデータを入力するためのコードは次のとおりです。
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO 読み込み時間はごくわずかです—私のマシンでは43ミリ秒です。
ディスク上のテーブルのサイズを確認してください:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
データに必要な56KBのスペースがあります。
行グループの数、状態(圧縮または開いている)、およびサイズを確認します。
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); 次の出力が得られました:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
ここで必要な行グループは1つだけです。圧縮されており、サイズは293バイトです。
テーブルに1行少ない(102,399)を入力すると、行ストアベースの非圧縮のオープンデルタストアが得られます。このような場合、sp_spaceusedは1MBを超えるディスク上のデータサイズを報告し、sys.column_store_row_groupsは次の情報を報告します。
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
したがって、テーブルに102,400行を入力するようにしてください!
関数dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2の定義は次のとおりです:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
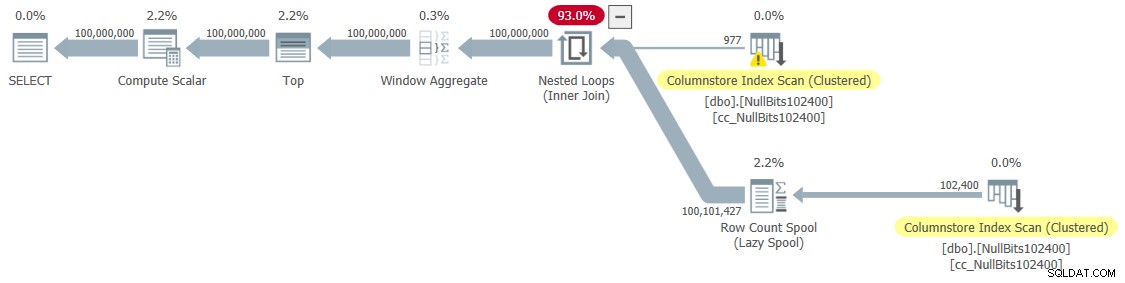 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
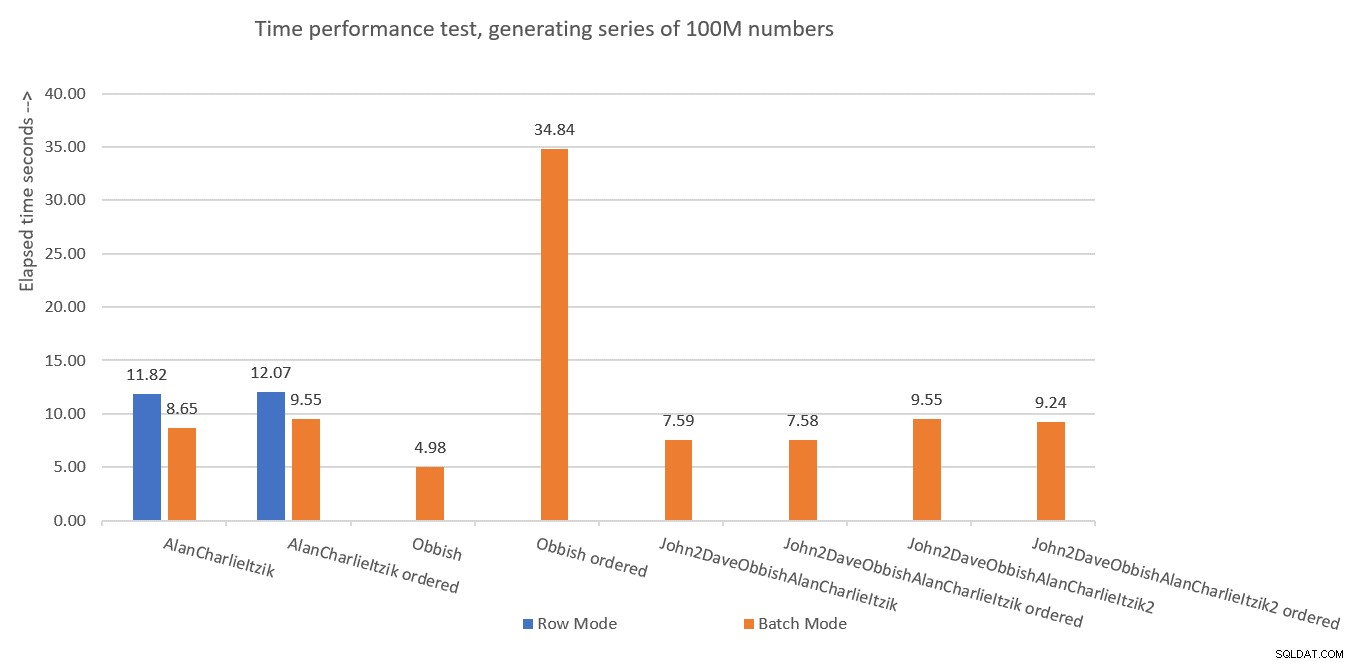 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
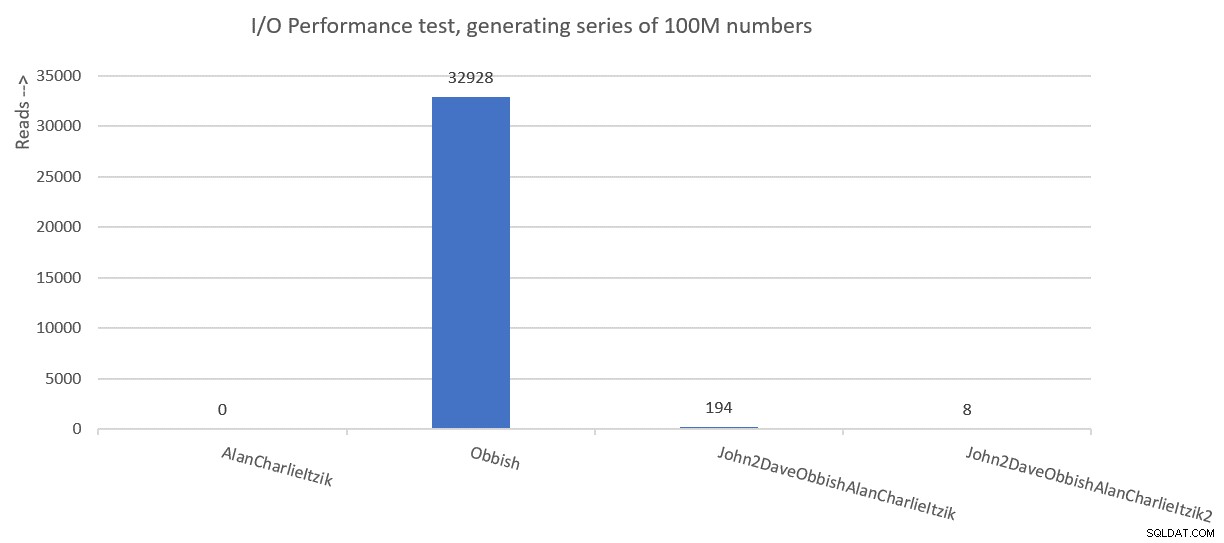 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.