多くの場合、ストアドプロシージャを作成するときは、ユーザー入力に基づいてさまざまな方法で動作させたいと考えています。次の例を見てみましょう:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
このストアドプロシージャは、AdventureWorks2017データベースで作成したもので、@CustomerIDと@SortOrderの2つのパラメーターがあります。最初のパラメーター@CustomerIDは、返される行に影響します。特定の顧客IDがストアドプロシージャに渡されると、この顧客のすべての注文(上位10件)が返されます。それ以外の場合、NULLの場合、ストアドプロシージャは、顧客に関係なく、すべての注文(上位10)を返します。 2番目のパラメーター@SortOrderは、データの並べ替え方法(OrderDateまたはSalesOrderID)を決定します。ソート順に従って、最初の10行のみが返されることに注意してください。
したがって、ユーザーは2つの方法でクエリの動作に影響を与えることができます。つまり、返す行とそれらの並べ替え方法です。より正確に言うと、このクエリには4つの異なる動作があります。
- OrderDateでソートされたすべての顧客の上位10行を返します(デフォルトの動作)
- 特定の顧客の上位10行をOrderDateで並べ替えて返します
- SalesOrderIDで並べ替えられたすべての顧客の上位10行を返します
- SalesOrderIDで並べ替えられた特定の顧客の上位10行を返します
4つのオプションすべてを使用してストアドプロシージャをテストし、実行プランと統計IOを調べてみましょう。
OrderDateでソートされたすべての顧客の上位10行を返す
ストアドプロシージャを実行するためのコードは次のとおりです。
EXECUTE Sales.GetOrders; GO
実行計画は次のとおりです。
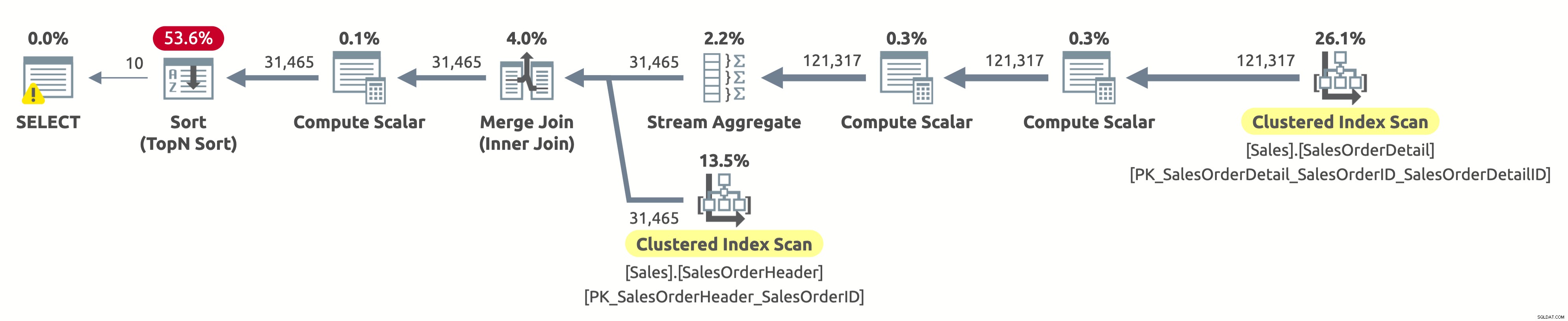
顧客によるフィルタリングを行っていないため、テーブル全体をスキャンする必要があります。オプティマイザーは、SalesOrderIDのインデックスを使用して両方のテーブルをスキャンすることを選択しました。これにより、効率的なStreamAggregateと効率的なMergeJoinが可能になりました。
Sales.SalesOrderHeaderテーブルのClusteredIndexScan演算子のプロパティを確認すると、次の述語が見つかります:[AdventureWorks2017]。[Sales]。[SalesOrderHeader]。[CustomerID]as[SalesOrders]。[CustomerID]=[ @CustomerID]または[@CustomerID]がNULLです。クエリプロセッサは、テーブルの各行に対してこの述語を評価する必要がありますが、常にtrueと評価されるため、あまり効率的ではありません。
最初の10行を返すには、すべてのデータをOrderDateで並べ替える必要があります。 OrderDateにインデックスがあった場合、オプティマイザーはおそらくそれを使用してSales.SalesOrderHeaderの最初の10行のみをスキャンしますが、そのようなインデックスはないため、使用可能なインデックスを考慮すると計画は問題ないようです。
統計IOの出力は次のとおりです。
- テーブル'SalesOrderHeader'。スキャンカウント1、論理読み取り689
- テーブル'SalesOrderDetail'。スキャンカウント1、論理読み取り1248
SELECT演算子に警告がある理由を尋ねている場合、それは過度の許可警告です。この場合、実行プランに問題があるためではなく、クエリプロセッサが1,024KB(デフォルトでは最小)を要求し、16KBしか使用しなかったためです。
プランキャッシングがあまり良いアイデアではない場合があります
次に、OrderDateでソートされた特定の顧客の上位10行を返すシナリオをテストします。以下はコードです:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
実行計画は以前とまったく同じです。今回は、両方のテーブルをスキャンして3つの注文のみを返すため、この計画は非常に非効率的です。このクエリを実行するためのより良い方法があります。
この場合の理由は、プランのキャッシュです。実行プランは、最初の実行で、その特定の実行のパラメーター値に基づいて生成されました。これは、パラメータースニッフィングと呼ばれる方法です。そのプランは再利用のためにプランキャッシュに保存され、今後、このストアドプロシージャを呼び出すたびに、同じプランが再利用されます。
これは、プランのキャッシュがあまり適切ではない例です。このストアドプロシージャの性質上、4つの異なる動作があるため、動作ごとに異なるプランを取得することを期待しています。しかし、最初の実行で使用されたオプションに基づいて、4つのオプションのうちの1つにのみ有効な単一の計画に固執しています。
このストアドプロシージャのプランキャッシュを無効にして、オプティマイザーが他の3つの動作のそれぞれについて考え出すことができる最適なプランを確認できるようにします。これを行うには、EXECUTEコマンドにWITHRECOMPILEを追加します。
OrderDateでソートされた特定の顧客の上位10行を返す
以下は、OrderDateでソートされた特定の顧客の上位10行を返すコードです。
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
実行計画は次のとおりです。
今回は、CustomerIDのインデックスを使用するより良いプランを取得します。オプティマイザは、 CustomerID =11006に対して2.6行を正しく推定します。 (実際の数は3です)。ただし、インデックスシークの代わりにインデックススキャンを実行することに注意してください。テーブルの各行に対して次の述語を評価する必要があるため、インデックスシークを実行できません:[AdventureWorks2017]。[Sales]。[SalesOrderHeader]。[CustomerID]as[SalesOrders]。[CustomerID]=[@ CustomerID ]または[@CustomerID]がNULLです。
統計IOの出力は次のとおりです。
- テーブル'SalesOrderDetail'。スキャンカウント3、論理読み取り9
- テーブル'SalesOrderHeader'。スキャンカウント1、論理読み取り66
SalesOrderIDでソートされたすべての顧客の上位10行を返す
以下は、SalesOrderIDでソートされたすべての顧客の上位10行を返すコードです。
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
実行計画は次のとおりです。
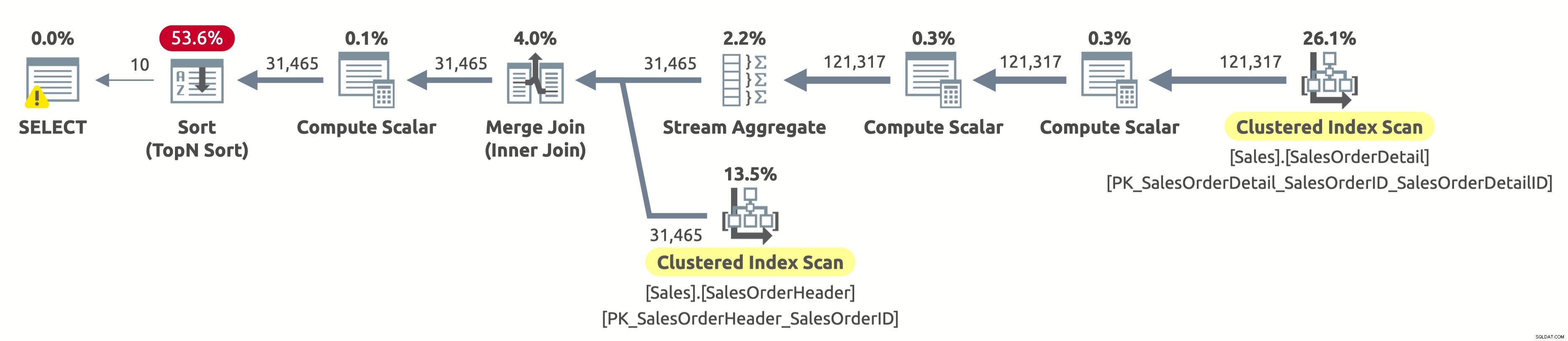
ねえ、これは最初のオプションと同じ実行プランです。しかし、今回は何かがおかしい。両方のテーブルのクラスター化インデックスがSalesOrderIDでソートされていることはすでにわかっています。また、プランが両方を論理的な順序でスキャンして、並べ替え順序を保持することもわかっています(OrderedプロパティはTrueに設定されています)。結合結合演算子もソート順を保持します。現在、SalesOrderIDで結果を並べ替えるように求められており、すでにその方法で並べ替えられているのに、なぜ高価な並べ替え演算子を支払う必要があるのでしょうか。
さて、並べ替え演算子をチェックすると、Expr1004に従ってデータが並べ替えられていることがわかります。また、Sort演算子の右側にあるCompute Scalar演算子を確認すると、Expr1004が次のようになっていることがわかります。

それはきれいな光景ではありません、私は知っています。これは、クエリのORDERBY句にある式です。問題は、オプティマイザがコンパイル時にこの式を評価できないため、実行時に行ごとに式を計算し、それに基づいてレコードセット全体を並べ替える必要があることです。
統計IOの出力は、最初の実行と同じです。
- テーブル'SalesOrderHeader'。スキャンカウント1、論理読み取り689
- テーブル'SalesOrderDetail'。スキャンカウント1、論理読み取り1248
SalesOrderIDで並べ替えられた特定の顧客の上位10行を返す
以下は、SalesOrderIDでソートされた特定の顧客の上位10行を返すコードです。
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
実行プランは2番目のオプションと同じです(OrderDateでソートされた特定の顧客の上位10行を返します)。この計画には、すでに述べたのと同じ2つの問題があります。最初の問題は、WHERE句の式が原因で、インデックスシークではなくインデックススキャンを実行することです。 2番目の問題は、ORDERBY句の式が原因でコストのかかるソートを実行することです。
では、どうすればよいですか?
まず、私たちが何を扱っているかを思い出してみましょう。クエリの構造を決定するパラメータがあります。パラメータ値の組み合わせごとに、異なるクエリ構造を取得します。 @CustomerIDパラメーターの場合、2つの異なる動作はNULLまたはNOT NULLであり、WHERE句に影響します。 @SortOrderパラメーターの場合、2つの可能な値があり、それらはORDERBY句に影響します。結果は4つの可能なクエリ構造であり、それぞれに異なる計画を取得したいと思います。
次に、2つの明確な問題があります。 1つは、プランのキャッシュです。ストアドプロシージャのプランは1つだけであり、最初の実行のパラメータ値に基づいて生成されます。 2番目の問題は、新しいプランが生成された場合でも、オプティマイザーがコンパイル時にWHERE句とORDER BY句の「動的」式を評価できないため、効率的ではないことです。
これらの問題はいくつかの方法で解決できます。
- 一連のIF-ELSEステートメントを使用する
- プロシージャを個別のストアドプロシージャに分割します
- OPTION(RECOMPILE)を使用する
- クエリを動的に生成する
一連のIF-ELSEステートメントを使用する
考え方は単純です。WHERE句とORDERBY句の「動的」式の代わりに、IF-ELSEステートメントを使用して実行を4つのブランチに分割できます。可能な動作ごとに1つのブランチです。
たとえば、最初のブランチのコードは次のとおりです。
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
このアプローチは、より良い計画を作成するのに役立ちますが、いくつかの制限があります。
まず、ストアドプロシージャが非常に長くなり、書き込み、読み取り、および保守がより困難になります。そして、これはパラメータが2つしかない場合です。 3つのパラメーターがある場合、8つのブランチがあります。 SELECT句に列を追加する必要があると想像してください。 8つの異なるクエリで列を追加する必要があります。メンテナンスの悪夢となり、人為的ミスのリスクが高くなります。
第二に、プランのキャッシュとパラメータのスニッフィングの問題がまだある程度あります。これは、最初の実行で、オプティマイザーがその実行のパラメーター値に基づいて4つのクエリすべてのプランを生成するためです。最初の実行でパラメータのデフォルト値を使用するとします。具体的には、@CustomerIDの値はNULLになります。 WHERE句(SalesOrders.CustomerID =@CustomerID)を含むクエリを含め、すべてのクエリはその値に基づいて最適化されます。オプティマイザは、これらのクエリに対して0行を推定します。ここで、2番目の実行で@CustomerIDにnull以外の値が使用されるとします。顧客がテーブルに大量の注文を持っている場合でも、0行を見積もるキャッシュされたプランが使用されます。
プロシージャを個別のストアドプロシージャに分割する
同じストアドプロシージャ内に4つのブランチを作成する代わりに、それぞれに関連するパラメータと対応するクエリを使用して、4つの個別のストアドプロシージャを作成できます。次に、アプリケーションを書き直して、目的の動作に従って実行するストアドプロシージャを決定できます。または、アプリケーションに対して透過的にしたい場合は、元のストアドプロシージャを書き直して、パラメータ値に基づいて実行するプロシージャを決定できます。同じIF-ELSEステートメントを使用しますが、各ブランチでクエリを実行する代わりに、個別のストアドプロシージャを実行します。
利点は、各ストアドプロシージャに独自のプランがあり、各ストアドプロシージャのプランがパラメータスニッフィングに基づいて最初の実行で生成されるため、プランのキャッシュの問題を解決できることです。
しかし、まだメンテナンスの問題があります。複数のストアドプロシージャを維持する必要があるため、今ではさらに悪化していると言う人もいるかもしれません。繰り返しになりますが、パラメータの数を3に増やすと、8つの異なるストアドプロシージャになります。
OPTION(RECOMPILE)を使用
OPTION(RECOMPILE)は魔法のように機能します。単語を言う(またはクエリに追加する)だけで、魔法が起こります。実際、実行時にクエリをコンパイルし、実行ごとにコンパイルするため、非常に多くの問題を解決します。
しかし、彼らが言うことを知っているので、注意しなければなりません:「大きな力には大きな責任が伴います」。ビジーなOLTPシステムで頻繁に実行されるクエリでOPTION(RECOMPILE)を使用する場合、サーバーは実行のたびに多くのCPUリソースを使用して新しいプランをコンパイルおよび生成する必要があるため、システムを強制終了する可能性があります。これは本当に危険です。ただし、クエリがたまにしか実行されない場合、たとえば数分に1回だけ実行される場合は、おそらく安全です。ただし、常に特定の環境での影響をテストしてください。
この場合、OPTION(RECOMPILE)を安全に使用できると仮定すると、以下に示すように、クエリの最後に魔法の単語を追加するだけです。
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
それでは、魔法の動作を見てみましょう。たとえば、2番目の動作の計画は次のとおりです。
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
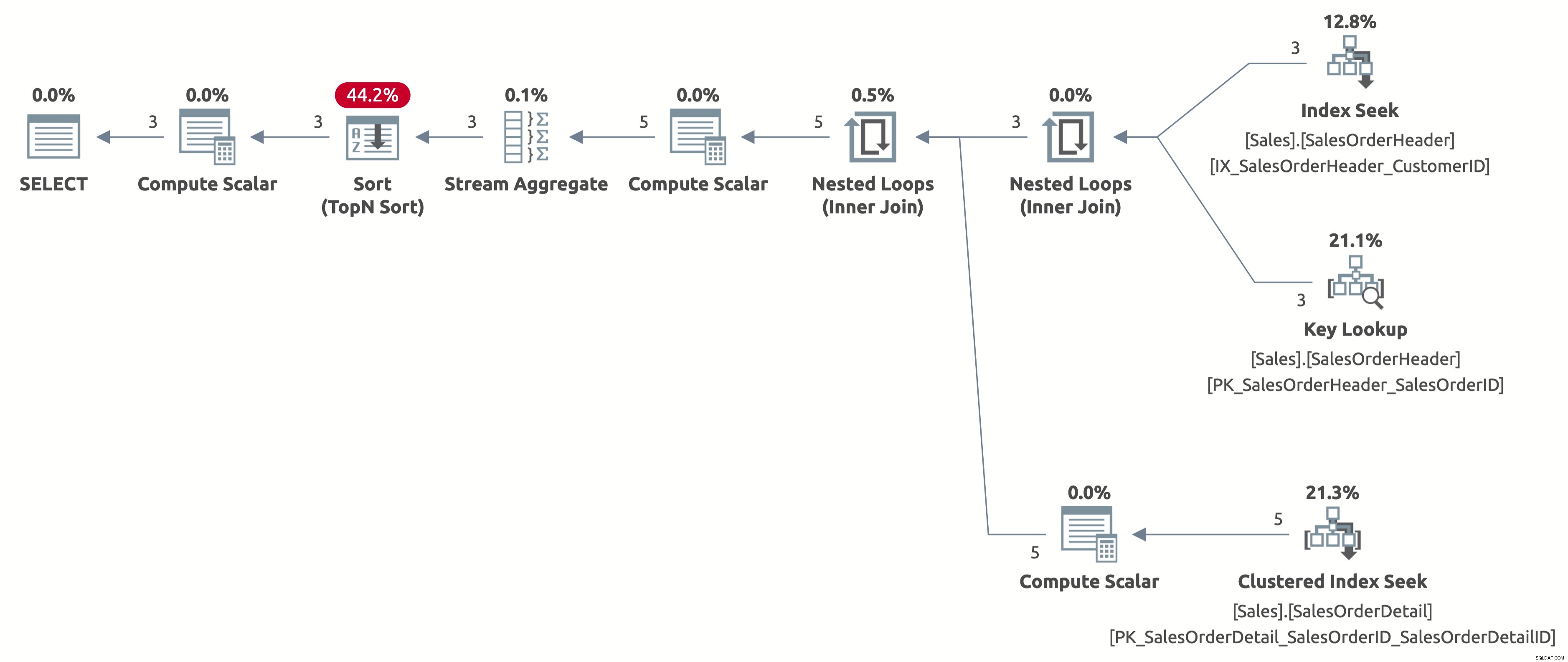
これで、2.6行の正しい推定で効率的なインデックスシークが得られます。引き続きOrderDateで並べ替える必要がありますが、並べ替えはOrder Dateで直接行われるようになり、ORDERBY句でCASE式を計算する必要がなくなりました。これは、使用可能なインデックスに基づいて、このクエリ動作に対して可能な最善の計画です。
統計IOの出力は次のとおりです。
- テーブル'SalesOrderDetail'。スキャンカウント3、論理読み取り9
- テーブル'SalesOrderHeader'。スキャンカウント1、論理読み取り11
この場合、OPTION(RECOMPILE)が非常に効率的である理由は、ここで発生する2つの問題を正確に解決するためです。最初の問題はプランのキャッシュであることを忘れないでください。 OPTION(RECOMPILE)は、クエリを毎回再コンパイルするため、この問題を完全に排除します。 2番目の問題は、オプティマイザがコンパイル時にWHERE句とORDERBY句の複雑な式を評価できないことです。 OPTION(RECOMPILE)は実行時に発生するため、問題を解決します。実行時に、オプティマイザはコンパイル時と比較してより多くの情報を持っているため、すべての違いが生じます。
それでは、3番目の動作を試してみるとどうなるか見てみましょう:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
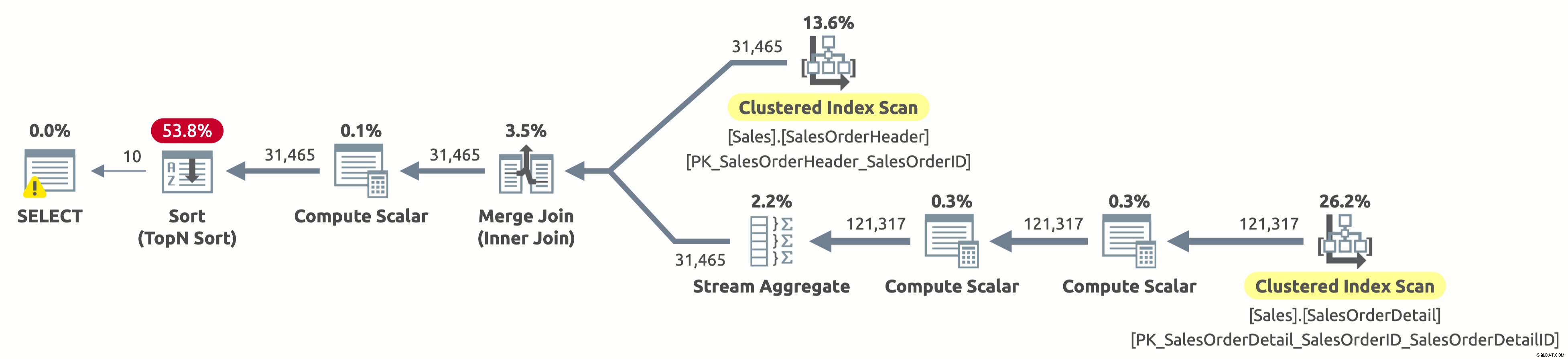
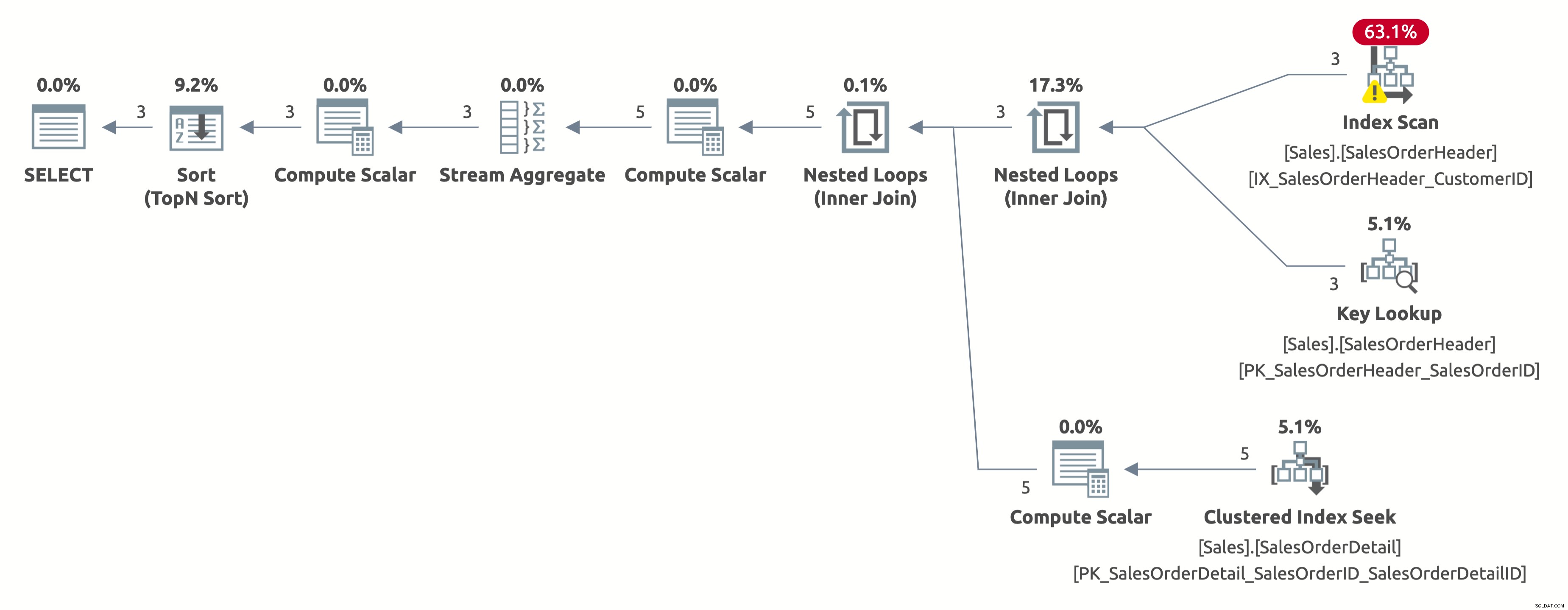
ヒューストン、問題があります。プランでは、Sales.SalesOrderHeaderの最初の10行だけをスキャンして並べ替えを完全に回避するのではなく、両方のテーブルを完全にスキャンしてからすべてを並べ替えます。どうしたの?
これは興味深い「ケース」であり、ORDERBY句のCASE式と関係があります。 CASE式は条件のリストを評価し、結果式の1つを返します。ただし、結果の式のデータ型は異なる場合があります。では、CASE式全体のデータ型はどうなるでしょうか。そうですね、CASE式は常に最優先のデータ型を返します。この場合、列OrderDateにはDATETIMEデータ型があり、列SalesOrderIDにはINTデータ型があります。 DATETIMEデータ型の優先順位が高いため、CASE式は常にDATETIMEを返します。
つまり、SalesOrderIDで並べ替える場合、CASE式は、並べ替える前に、まず各行のSalesOrderIDの値を暗黙的にDATETIMEに変換する必要があります。上記の計画のSort演算子の右側にあるComputeScalar演算子を参照してください。それがまさにそれです。
これはそれ自体が問題であり、単一のCASE式にさまざまなデータ型を混在させることがいかに危険であるかを示しています。
ORDER BY句を他の方法で書き直すことでこの問題を回避できますが、コードがさらに醜くなり、読み取りと保守が困難になります。だから、私はその方向には行きません。
代わりに、次の方法を試してみましょう…
クエリを動的に生成する
私たちの目標は単一のクエリ内で4つの異なるクエリ構造を生成することであるため、この場合、動的SQLは非常に便利です。アイデアは、パラメータ値に基づいて動的にクエリを作成することです。このようにして、クエリの4つのコピーを維持することなく、1つのコードで4つの異なるクエリ構造を構築できます。各クエリ構造は、最初に実行されたときに1回コンパイルされ、複雑な式が含まれていないため、最適なプランが得られます。
このソリューションは、複数のストアドプロシージャを使用するソリューションと非常に似ていますが、3つのパラメータに対して8つのストアドプロシージャを維持する代わりに、クエリを動的に構築する単一のコードのみを維持します。
動的SQLも醜く、保守が非常に難しい場合もありますが、複数のストアドプロシージャを保守するよりも簡単であり、パラメーターの数が増えても指数関数的に拡張されることはないと思います。
コードは次のとおりです。
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
引き続き顧客IDの内部パラメーターを使用し、sys.sp_executesqlを使用して動的コードを実行することに注意してください。 パラメータ値を渡します。これは2つの理由で重要です。まず、@CustomerIDの値が異なる場合に同じクエリ構造が複数回コンパイルされるのを防ぐためです。次に、SQLインジェクションを回避します。
異なるパラメータ値を使用してストアドプロシージャを実行しようとすると、各クエリ動作またはクエリ構造が最適な実行プランを取得し、4つのプランのそれぞれが1回だけコンパイルされることがわかります。
例として、以下は3番目の動作の計画です。
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
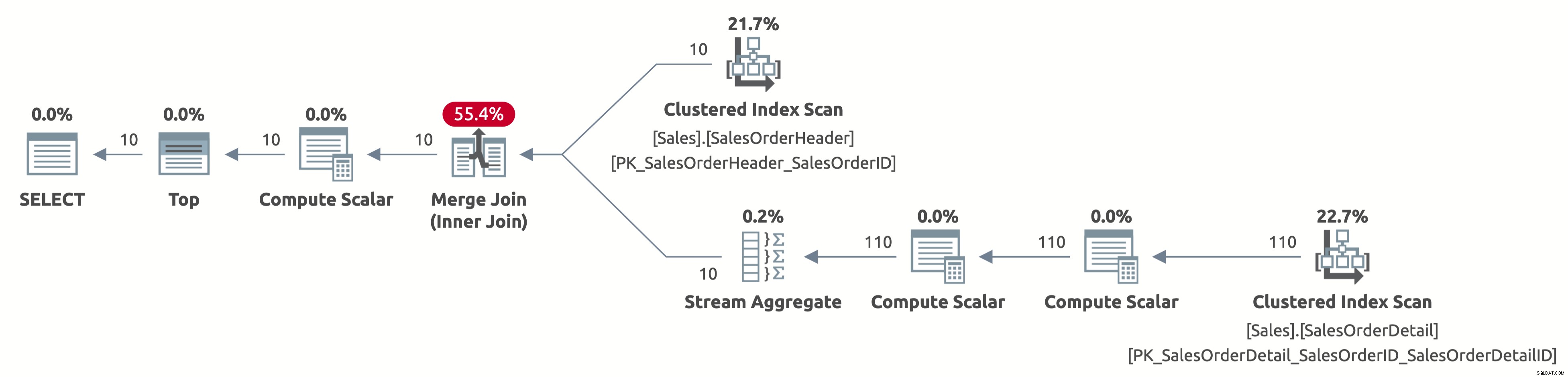
ここで、Sales.SalesOrderHeaderテーブルの最初の10行のみをスキャンし、Sales.SalesOrderDetailテーブルの最初の110行のみもスキャンします。さらに、データはすでにSalesOrderIDで並べ替えられているため、並べ替え演算子はありません。
統計IOの出力は次のとおりです。
- テーブル'SalesOrderDetail'。スキャンカウント1、論理読み取り4
- テーブル'SalesOrderHeader'。スキャンカウント1、論理読み取り3
結論
パラメータを使用してクエリの構造を変更する場合は、クエリ内で複雑な式を使用して期待される動作を導き出さないでください。ほとんどの場合、これはパフォーマンスの低下につながりますが、それには正当な理由があります。最初の理由は、最初の実行に基づいてプランが生成され、その後のすべての実行で同じプランが再利用されるためです。これは、1つのクエリ構造にのみ適切です。 2番目の理由は、オプティマイザがコンパイル時にこれらの複雑な式を評価する能力が制限されていることです。
これらの問題を克服する方法はいくつかありますが、この記事ではそれらを検討しました。ほとんどの場合、最良の方法は、パラメーター値に基づいて動的にクエリを作成することです。そうすれば、各クエリ構造は可能な限り最良の計画で1回コンパイルされます。
動的SQLを使用してクエリを作成するときは、必要に応じてパラメータを使用し、コードが安全であることを確認してください。