先月、効率的な数級数ジェネレーターを作成するためのチャレンジを投稿しました。応答は圧倒的でした。多くの素晴らしいアイデアや提案があり、この特定の課題をはるかに超えた多くのアプリケーションがありました。コミュニティの一員であることの素晴らしさ、そして賢い人々のグループが力を合わせることで驚くべきことが達成できることを実感しました。アイデアやコメントを共有してくれたAlanBurstein、Joe Obbish、Adam Machanic、Christopher Ford、Jeff Moden、Charlie、NoamGr、Kamil Kosno、Dave Mason、JohnNumber2に感謝します。
当初は、投稿されたアイデアをまとめた記事を1つだけ書くことを考えていましたが、多すぎました。そこで、カバレッジをいくつかの記事に分割します。今月は、dbo.GetNumsItzikBatchおよびdbo.GetNumsItzikと呼ばれるインラインTVFの形式で先月投稿した2つの元のソリューションに対するCharlieとAlanBursteinの提案された改善に主に焦点を当てます。改善されたバージョンにそれぞれdbo.GetNumsAlanCharlieItzikBatchとdbo.GetNumsAlanCharlieItzikという名前を付けます。
これはとてもエキサイティングです!
Itzikのオリジナルソリューション
先月取り上げた関数は、16行のテーブル値コンストラクターを定義するベースCTEを使用しています。関数は一連のカスケードCTEを使用し、それぞれが先行するCTEの2つのインスタンスの積(クロス結合)を適用します。このように、ベース1を超える5つのCTEを使用すると、最大4,294,967,296行のセットを取得できます。 Numsと呼ばれるCTEは、ROW_NUMBER関数を使用して、1から始まる一連の数値を生成します。最後に、外部クエリは、入力@lowと@highの間の要求された範囲の数値を計算します。
dbo.GetNumsItzikBatch関数は、列ストアインデックスを持つテーブルへのダミー結合を使用して、バッチ処理を取得します。ダミーテーブルを作成するコードは次のとおりです。
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
そして、これがdbo.GetNumsItzikBatch関数を定義するコードです:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; 次のコードを使用して、SSMSで[実行後に結果を破棄する]を有効にして関数をテストしました。
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
この実行で得られたパフォーマンス統計は次のとおりです。
CPU time = 16985 ms, elapsed time = 18348 ms.
dbo.GetNumsItzik関数も同様ですが、ダミーの結合がない点が異なり、通常はプラン全体で行モードの処理が行われます。関数の定義は次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; 関数のテストに使用したコードは次のとおりです。
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
この実行で得られたパフォーマンス統計は次のとおりです。
CPU time = 19969 ms, elapsed time = 21229 ms.
アランバースタインとチャーリーの改善
アランとチャーリーは、私の機能にいくつかの改善を提案しました。パフォーマンスに中程度の影響を与えるものと、より劇的な影響を与えるものがあります。まず、コンパイルのオーバーヘッドと定数畳み込みに関するチャーリーの調査結果から始めます。次に、1ベースのシーケンスと@lowベースのシーケンス(CharlieとJeff Modenも共有)、不要な並べ替えの回避、逆の順序での数値範囲の計算など、Alanの提案について説明します。
コンパイル時の結果
チャーリーが指摘したように、数系列ジェネレーターは、行数が非常に少ない系列を生成するためによく使用されます。このような場合、コードのコンパイル時間は、クエリ処理時間全体のかなりの部分になる可能性があります。ストアドプロシージャとは異なり、最適化されるのはパラメータ化されたクエリコードではなく、パラメータの埋め込みが行われた後のクエリコードであるため、iTVFを使用する場合は特に重要です。つまり、最適化の前にパラメーターが入力値に置き換えられ、定数を含むコードが最適化されます。このプロセスには、マイナスとプラスの両方の影響があります。マイナスの影響の1つは、関数が異なる入力値で呼び出されると、より多くのコンパイルが得られることです。このため、特に範囲が狭い場合に関数を頻繁に使用する場合は、コンパイル時間を確実に考慮する必要があります。
チャーリーがさまざまな基本CTEカーディナリティについて見つけたコンパイル時間は次のとおりです。
2: 22ms 4: 9ms 16: 7ms 256: 35ms
これらの中で16が最適であり、次のレベルである256に上がると、非常に劇的なジャンプがあることを知りたいと思います。関数dbo.GetNumsItzikBacthおよびdbo.GetNumsItzikは、16の基本CTEカーディナリティを使用することを思い出してください。 。
定数畳み込み
定数畳み込みは、iTVFが経験するパラメーター埋め込みプロセスのおかげで、適切な条件で有効になる可能性があるという肯定的な意味を持つことがよくあります。たとえば、関数に式@x + 1があるとします。ここで、@xは関数の入力パラメーターです。 @x=5を入力として関数を呼び出します。インライン化された式は5+1になり、定数畳み込みに適している場合(これについては後ほど詳しく説明します)、6になります。この式が列を含むより複雑な式の一部であり、数百万行に適用される場合、これは次のようになります。その結果、CPUサイクルが無視できないほど節約されます。
トリッキーな部分は、SQL Serverが定数畳み込みを行うものと、定数畳み込みを行わないものについて非常に慎重であるということです。たとえば、SQLServerはしません 定数畳み込みcol1+5 + 1、または5 + col1 + 1を折りたたむこともありません。ただし、5 + 1+col1を6+col1に折り畳みます。知っている。したがって、たとえば、関数がSELECT @x + col1 + 1 AS mycol1 FROM dbo.T1を返した場合、次の小さな変更を加えて定数畳み込みを有効にできます:SELECT @x + 1 + col1 AS mycol1FROMdbo.T1。信じられない? PerformanceV5データベース内の次の3つのクエリ(またはデータを使用した同様のクエリ)の計画を調べて、自分の目で確かめてください。
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
これら3つのクエリのComputeScalar演算子で、それぞれ次の3つの式を取得しました。
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
これでどこに行くのか分かりますか?私の関数では、次の式を使用して結果列nを定義しました。
@low + rownum - 1 AS n
チャーリーは、次の小さな変更で、定数畳み込みを有効にできることに気付きました。
@low - 1 + rownum AS n
たとえば、@ low =1のdbo.GetNumsItzikに対して提供した以前のクエリの計画には、元々、ComputeScalar演算子によって定義された次の式がありました。
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
上記の小さな変更を適用すると、計画の式は次のようになります。
[Expr1154] = Scalar Operator((0)+[Expr1153])
それは素晴らしいです!
パフォーマンスへの影響については、変更前にdbo.GetNumsItzikBatchに対するクエリで取得したパフォーマンス統計が次のとおりであることを思い出してください。
CPU time = 16985 ms, elapsed time = 18348 ms.
変更後に取得した数値は次のとおりです。
CPU time = 16375 ms, elapsed time = 17932 ms.
dbo.GetNumsItzikに対するクエリで最初に取得した数値は次のとおりです。
CPU time = 19969 ms, elapsed time = 21229 ms.
変更後の数値は次のとおりです。
CPU time = 19266 ms, elapsed time = 20588 ms.
パフォーマンスはわずか数パーセント向上しました。しかし、待ってください、もっとあります!注文したデータを処理する必要がある場合は、注文に関するセクションの後半で説明するように、パフォーマンスへの影響がはるかに劇的になる可能性があります。
1ベースと@lowベースのシーケンスおよび反対の行番号
アラン、チャーリー、ジェフは、ある範囲の数値が必要な実際のケースの大部分では、1から始める必要があり、場合によっては0から始める必要があると述べています。別の開始点が必要になることはほとんどありません。したがって、関数が常にたとえば1で始まる範囲を返すようにし、別の開始点が必要な場合は、関数に対するクエリで外部から計算を適用する方が理にかなっています。
Alanは実際に、インラインTVFがrnとしてエイリアスされた1(ROW_NUMBER関数の直接の結果)で始まる列と、nとしてエイリアスされた@lowで始まる列の両方を返すという洗練されたアイデアを思いつきました。関数がインライン化されるため、外部クエリが列rnとのみ対話する場合、列nは評価されません。これにより、パフォーマンスが向上します。 @lowで始まるシーケンスが必要な場合は、列nを操作し、該当する追加コストを支払うため、明示的な外部計算を追加する必要はありません。アランは、逆の順序で数値を計算し、そのようなシーケンスが必要な場合にのみそれと対話するopと呼ばれる列を追加することさえ提案しました。列opは、次の計算に基づいています:@high + 1 –rownum。この列は、後で順序付けのセクションで説明するように、行を番号の降順で処理する必要がある場合に重要です。
それでは、チャーリーとアランの改善を私の機能に適用しましょう。
バッチモードバージョンの場合、列ストアインデックスがまだ存在しない場合は、最初にダミーテーブルを作成してください。
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
次に、dbo.GetNumsAlanCharlieItzikBatch関数に次の定義を使用します。
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; 関数の使用例は次のとおりです。
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
このコードは次の出力を生成します:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
次に、1億行で関数のパフォーマンスをテストし、最初に列nを返します:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
この実行で得られたパフォーマンス統計は次のとおりです。
CPU time = 16375 ms, elapsed time = 17932 ms.
ご覧のとおり、ここで行われた定数畳み込みのおかげで、CPUと経過時間の両方でdbo.GetNumsItzikBatchと比較してわずかな改善があります。
関数をテストしますが、今回はrn列を返します:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
この実行で得られたパフォーマンス統計は次のとおりです。
CPU time = 15890 ms, elapsed time = 18561 ms.
CPU時間はさらに短縮されましたが、この実行では、列nを照会する場合と比較して、経過時間が少し長くなったようです。
図1には、両方のクエリの計画があります。
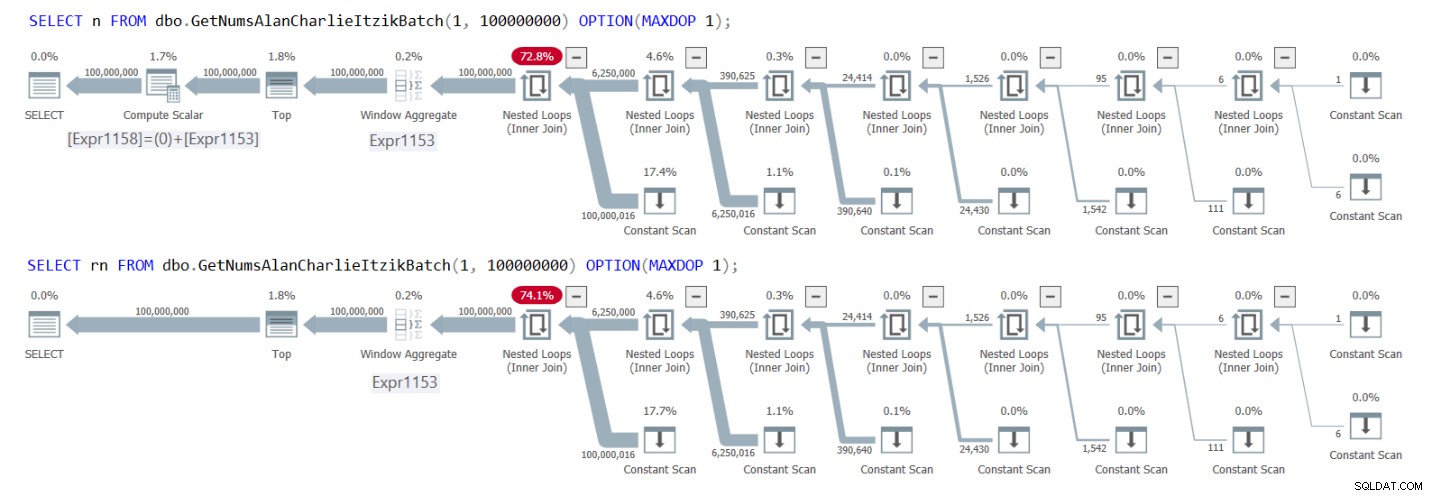 図1:GetNumsAlanCharlieItzikBatchがnとrnを返す計画
図1:GetNumsAlanCharlieItzikBatchがnとrnを返す計画
計画では、列rnを操作するときに、追加のComputeScalar演算子は必要ないことがはっきりとわかります。また、最初の計画では、@ low – 1 +rownumが1– 1 + rownumにインライン化され、次に0+rownumに折りたたまれた定数畳み込みアクティビティの結果に注意してください。
dbo.GetNumsAlanCharlieItzikと呼ばれる関数の行モードバージョンの定義は次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; 次のコードを使用して関数をテストし、最初に列nをクエリします。
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
これが私が得たパフォーマンス統計です:
CPU time = 19047 ms, elapsed time = 20121 ms.
ご覧のとおり、dbo.GetNumsItzikよりも少し高速です。
次に、列rnをクエリします:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
CPUと経過時間の両方で、パフォーマンスの数値がさらに向上します。
CPU time = 17656 ms, elapsed time = 18990 ms.
注文に関する考慮事項
前述の改善は確かに興味深いものであり、パフォーマンスへの影響は無視できませんが、それほど重要ではありません。数値列順にデータを処理する必要がある場合は、はるかに劇的で深刻なパフォーマンスへの影響が見られます。これは、順序付けられた行を返す必要があるのと同じくらい簡単ですが、グループ化と集約のためのStream Aggregate演算子、結合のためのMerge Joinアルゴリズムなど、順序ベースの処理のニーズにも同様に関連します。
dbo.GetNumsItzikBatchまたはdbo.GetNumsItzikにクエリを実行し、nで並べ替える場合、オプティマイザは、基になる順序付け式@low + rownum –1が順序を保持することを認識しません。 rownumに関して。この意味は、非SARGableフィルタリング式の意味と少し似ていますが、順序付け式を使用する場合にのみ、プラン内で明示的な並べ替え演算子が生成されます。追加の並べ替えは、応答時間に影響します。また、スケーリングにも影響します。スケーリングは通常、nではなくnlognになります。
これを示すために、dbo.GetNumsItzikBatchにクエリを実行し、nの順に列nを要求します。
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
次のパフォーマンス統計を取得しました:
CPU time = 34125 ms, elapsed time = 39656 ms.
実行時間は、ORDERBY句を使用しないテストと比較して2倍以上になります。
同様の方法でdbo.GetNumsItzik関数をテストします:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
このテストで次の番号を取得しました:
CPU time = 52391 ms, elapsed time = 55175 ms.
また、ここでは、ORDERBY句を使用しないテストと比較して実行時間が2倍以上になります。
図2には、両方のクエリの計画があります。
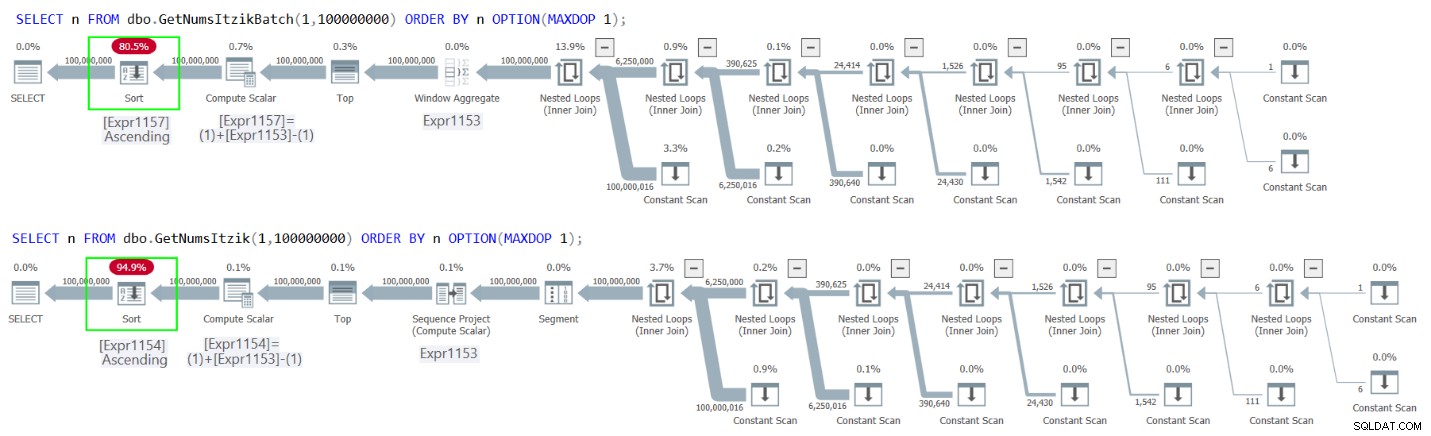 図2:GetNumsItzikBatchおよびGetNumsItzikのnによる順序付けの計画
図2:GetNumsItzikBatchおよびGetNumsItzikのnによる順序付けの計画
どちらの場合も、プランに明示的な並べ替え演算子が表示されます。
dbo.GetNumsAlanCharlieItzikBatchまたはdbo.GetNumsAlanCharlieItzikにクエリを実行し、rnで並べ替える場合、オプティマイザーはプランに並べ替え演算子を追加する必要はありません。したがって、nを返すことはできますが、rnで並べ替えると、並べ替えを回避できます。ただし、少し衝撃的なのは、つまり、良い意味で、定数畳み込みを経験するnの改訂バージョンが、順序を保持していることです。オプティマイザは、0 + rownumがrownumに関して順序を保持する式であることに気づきやすいため、並べ替えを回避できます。
それを試してみてください。 dbo.GetNumsAlanCharlieItzikBatchにクエリを実行し、nを返し、次のようにnまたはrnのいずれかで並べ替えます。
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
次のパフォーマンス数値を取得しました:
CPU time = 16500 ms, elapsed time = 17684 ms.
もちろん、これはプランに並べ替え演算子が必要なかったためです。
dbo.GetNumsAlanCharlieItzikに対して同様のテストを実行します:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
次の番号を取得しました:
CPU time = 19546 ms, elapsed time = 20803 ms.
図3には、両方のクエリの計画があります。
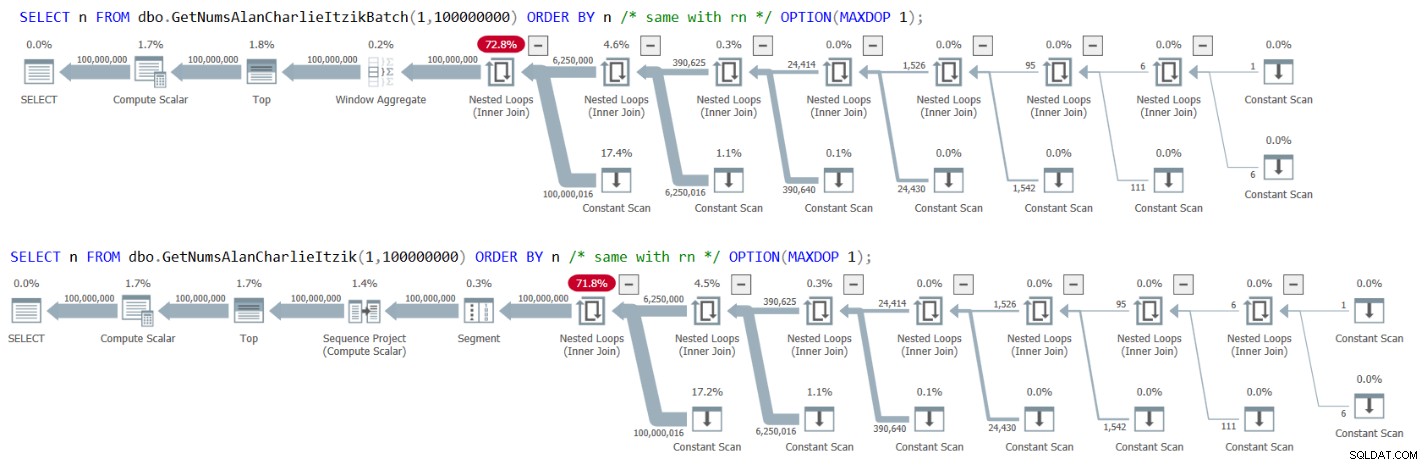
図3:GetNumsAlanCharlieItzikBatchおよびGetNumsAlanCharlieItzikのnまたはrnによる順序付けの計画
プランに並べ替え演算子がないことを確認してください。
歌いたくなる…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
ありがとうチャーリー!
しかし、番号を降順で返すか処理する必要がある場合はどうなりますか?明らかな試みは、次のようにORDER BYnDESCまたはORDERBYrnDESCを使用することです。
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
ただし、残念ながら、どちらの場合も、図4に示すように、プランが明示的に並べ替えられます。
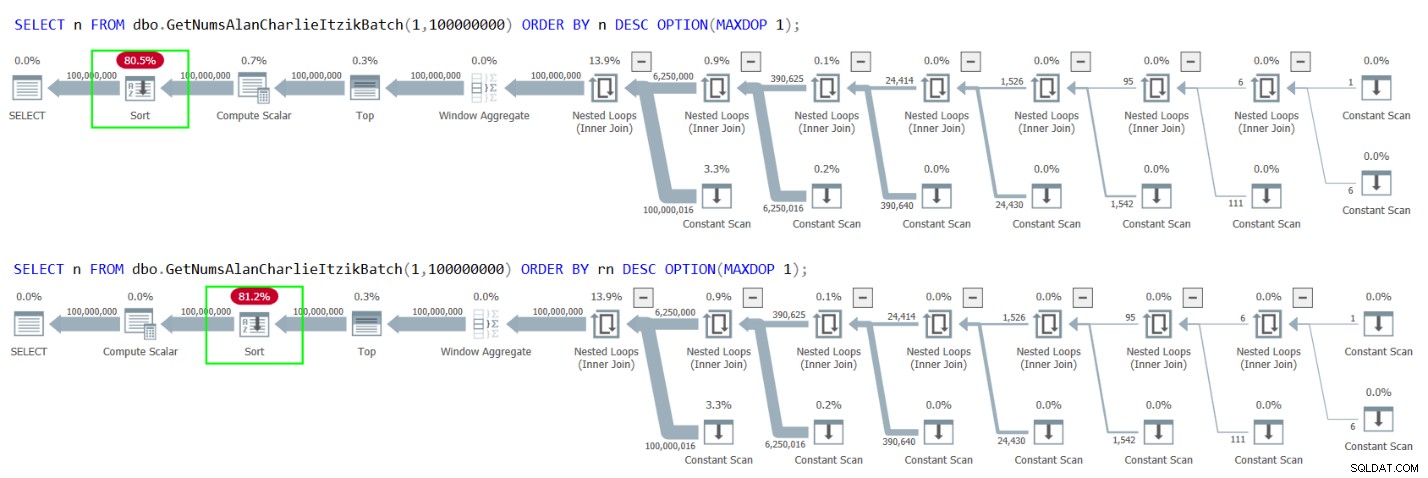 図4:GetNumsAlanCharlieItzikBatchのnまたはrnの降順による順序付けの計画
図4:GetNumsAlanCharlieItzikBatchのnまたはrnの降順による順序付けの計画
これは、コラムopでのアランの巧妙なトリックが命の恩人になる場所です。次のように、nまたはrnのいずれかで順序付けしながら、列opを返します。
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
このクエリの計画を図5に示します。
 図5:GetNumsAlanCharlieItzikBatchがopを返し、nまたはrnの昇順で並べ替える計画
図5:GetNumsAlanCharlieItzikBatchがopを返し、nまたはrnの昇順で並べ替える計画
データはnの降順で並べ替えられ、プランで並べ替える必要はありません。
ありがとうアラン!
パフォーマンスの概要
では、これらすべてから何を学びましたか?
特に範囲が狭い関数を頻繁に使用する場合は、コンパイル時間が要因になる可能性があります。 2を底とする対数スケールでは、甘い16は素晴らしい魔法の数のようです。
定数畳み込みの特性を理解し、それらを有利に使用します。 iTVFにパラメーター、定数、および列を含む式がある場合は、式の先頭部分にパラメーターと定数を配置します。これにより、フォールディングの可能性が高まり、CPUオーバーヘッドが削減され、注文保存の可能性が高まります。
iTVFでさまざまな目的に使用される複数の列があり、参照されていない列の料金を気にすることなく、それぞれの場合に関連する列をクエリすることは問題ありません。
逆の順序で返される数列が必要な場合は、ORDER BY句の元のn列またはrn列を昇順で使用し、逆の順序で数を計算する列opを返します。
図6は、さまざまなテストで得られたパフォーマンスの数値をまとめたものです。
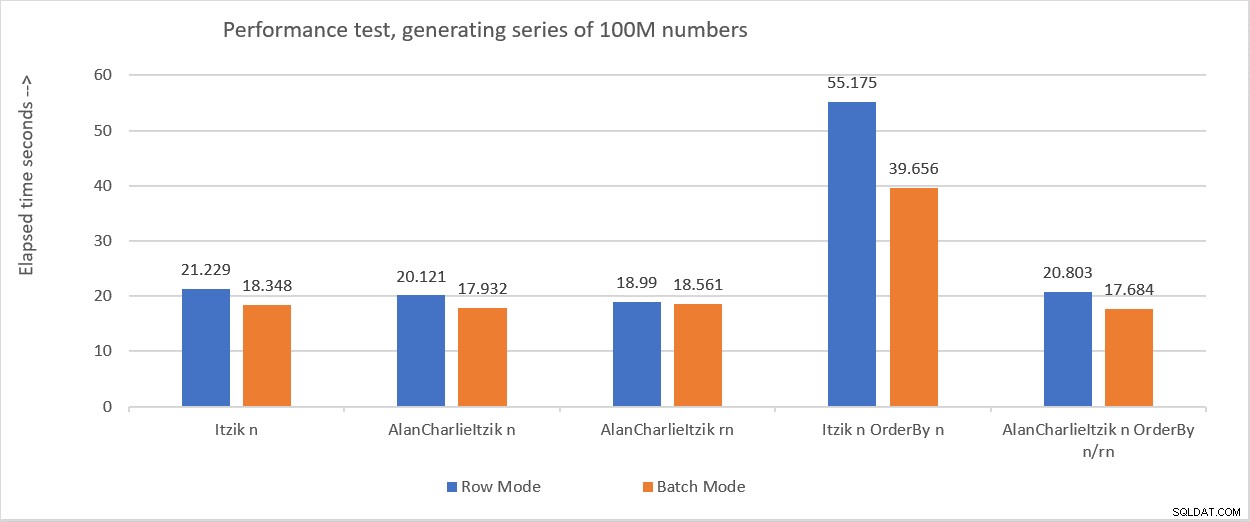 図6:パフォーマンスの概要
図6:パフォーマンスの概要
来月は、ナンバーシリーズジェネレーターの課題に対する追加のアイデア、洞察、解決策を引き続き検討します。