ページ付けは、あらゆる場所のクライアントおよびWebアプリケーション全体で一般的なユースケースです。 Googleは一度に10件の結果を表示し、オンラインバンクは1ページあたり20件の請求書を表示し、バグ追跡およびソース管理ソフトウェアは画面に50個のアイテムを表示する場合があります。
SQLServer2012の一般的なページングアプローチであるOFFSET/FETCH(MySQLのprioprietary LIMIT句に相当する標準)を確認し、最適なだけでなく、セット全体でより線形のページングパフォーマンスを実現するバリエーションを提案したいと思いました。最初に。悲しいことに、多くの店がテストするのはこれだけです。
SQL Serverのページネーションとは何ですか?
テーブルのインデックス付け、必要な列、および選択した並べ替え方法に基づいて、ページ付けは比較的簡単に行うことができます。 「最初の」20人の顧客を探していて、クラスター化インデックスがその並べ替えをサポートしている場合(たとえば、IDENTITY列またはDateCreated列のクラスター化インデックス)、クエリは比較的効率的になります。非クラスター化インデックスを必要とする並べ替えをサポートする必要がある場合、特にインデックスでカバーされていない出力に必要な列がある場合(サポートするインデックスがない場合でもかまいません)、クエリのコストが高くなる可能性があります。また、同じクエリ(@PageNumberパラメータが異なる)でも、@ PageNumberが高くなると、データの「スライス」に到達するためにより多くの読み取りが必要になる可能性があるため、はるかにコストがかかる可能性があります。
セットの最後に向かって進むことは、問題により多くのメモリを投入する(つまり、物理I / Oを排除する)か、アプリケーションレベルのキャッシュを使用する(つまり、データベース)。この投稿の目的のために、すべての顧客がメモリスロットが不足している、または制御できないサーバーにRAMを追加できるわけではないため、または単に指を鳴らして新しい、より大きなサーバーを準備できるわけではないため、より多くのメモリが常に可能であるとは限らないと仮定しましょう。トーゴ。特に一部のお客様はStandardEditionを使用しているため、64GB(SQL Server 2012)または128GB(SQL Server 2014)に制限されているか、Express(1GB)や多くのクラウド製品の1つなどのさらに限定されたエディションを使用しています。
>そこで、SQL Server 2012での一般的なページングアプローチ(OFFSET / FETCH)を確認し、最初から最適であるだけでなく、セット全体でより線形のページングパフォーマンスを実現するバリエーションを提案したいと思いました。悲しいことに、多くの店がテストするのはこれだけです。
ページネーションデータの設定/例
別の投稿から借用します。悪い習慣:キーを選択するときにディスクスペースのみに焦点を当て、次のテーブルに1,000,000行のランダムな(ただし完全に現実的ではない)顧客データを入力しました:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
ここでI/Oをテストし、ウォームキャッシュとコールドキャッシュの両方からテストすることを知っていたので、断片化を最小限に抑えるためにすべてのインデックスを再構築することで、テストを少なくとももう少し公平にしました(破壊的ですが、定期的に、あらゆるタイプのインデックスメンテナンスを実行しているほとんどのビジーシステムで):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
再構築後、断片化はすべてのインデックスで0.05%〜0.17%になり(インデックスレベル=0)、ページは99%を超えて埋められ、インデックスの行数/ページ数は次のようになります。
| インデックス | ページ数 | 行数 |
|---|---|---|
| C_PK_Customers_I(クラスター化されたインデックス) | 19,210 | 1,000,000 |
| C_Email_Customers_I | 7,344 | 1,000,000 |
| C_Active_Customers_I(フィルター処理されたインデックス) | 13,648 | 815,235 |
| C_Name_Customers_I | 16,824 | 1,000,000 |
インデックス、ページ数、行数
これは明らかに超ワイドテーブルではないので、今回は圧縮を省略しました。おそらく、将来のテストでさらに多くの構成を検討する予定です。
SQLクエリを効果的にページ分割する方法
ページネーションの概念(一度に1行だけをユーザーに表示する)は、説明するよりも視覚化する方が簡単です。物理的な本の索引について考えてみてください。本内のポイントへの参照が複数ページある場合がありますが、アルファベット順に整理されています。簡単にするために、10個のアイテムがインデックスの各ページに収まるとしましょう。これは次のようになります:
インデックスの1ページと2ページをすでに読んでいる場合、3ページに進むには、2ページをスキップする必要があることがわかります。しかし、各ページに10個のアイテムがあることを知っているので、これは2 x 10個のアイテムをスキップして、21番目のアイテムから開始することと考えることもできます。または、言い換えると、最初の(10 *(3-1))項目をスキップする必要があります。これをより一般的にするには、nページから始めるために、最初の(10 *(n-1))項目をスキップする必要があると言えます。最初のページに移動するには、10 *(1-1)アイテムをスキップして、アイテム1で終了します。2番目のページに移動するには、10 *(2-1)アイテムをスキップして、アイテム11で終了します。オン。
SQLServer2012で追加されたOFFSET/FETCH句は、その数の行をスキップするように特別に設計されているため、ユーザーはその情報を使用して、次のようなページングクエリを作成します。
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
上で述べたように、これは、ORDER BYをサポートし、SELECT句(および、より複雑なクエリの場合はWHERE句とJOIN句)のすべての列をカバーするインデックスがある場合に問題なく機能します。ただし、サポートするインデックスがないと、並べ替えのコストが高額になる可能性があります。出力列がカバーされていない場合は、大量のキールックアップが発生するか、シナリオによってはテーブルスキャンが発生する可能性があります。
SQLページネーションのベストプラクティスの並べ替え
上記のテーブルとインデックスを前提として、ページごとに100行を表示し、テーブル内のすべての列を出力するこれらのシナリオをテストしたいと思いました。
- デフォルト –
ORDER BY CustomerID(クラスター化されたインデックス)。これは、追加の並べ替えを必要とせず、表示に必要になる可能性のあるこのテーブルのすべてのデータが含まれているため、データベースユーザーにとって最も便利な順序です。一方、テーブルのサブセットを表示している場合、これは使用するのに最も効率的なインデックスではない可能性があります。特にCustomerIDが外部的な意味を持たない代理識別子である場合、この順序はエンドユーザーにとって意味がない場合もあります。 - 電話帳 –
ORDER BY LastName, FirstName(非クラスター化インデックスをサポート)。これはユーザーにとって最も直感的な順序ですが、並べ替えとカバレッジの両方をサポートするには、クラスター化されていないインデックスが必要になります。サポートするインデックスがないと、テーブル全体をスキャンする必要があります。 - ユーザー定義 –
ORDER BY FirstName DESC, EMail(サポートインデックスなし)。これは、ユーザーが希望する並べ替え順序を選択できることを表しています。MichaelJ. Swartが、「スケーリングしないUIデザインパターン」で警告しているパターンです。
ウォームキャッシュとコールドキャッシュの両方のシナリオで、1ページ、500ページ、5,000ページ、および9,999ページを確認するときに、これらのメソッドをテストし、計画とメトリックを比較したいと思いました。これらのプロシージャを作成しました(ORDER BY句のみが異なります):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail 実際には、動的SQL(私の「キッチンシンク」の例のように)またはCASE式を使用して順序を指定するプロシージャはおそらく1つだけです。
いずれの場合も、クエリでOPTION(RECOMPILE)を使用して、すべてではないが1つの並べ替えオプションに最適なプランの再利用を回避することで最良の結果が得られる場合があります。これらの変数を取り除くために、ここで個別のプロシージャを作成しました。これらのテストにOPTION(RECOMPILE)を追加して、プランキャッシュ全体を繰り返しフラッシュすることなく、パラメーターのスニッフィングやその他の最適化の問題を回避しました。
パフォーマンスを向上させるためのSQLServerページネーションの代替アプローチ
少し異なるアプローチは、あまり実装されていないと思いますが、クラスタリングキーのみを使用して使用している「ページ」を見つけて、それに参加することです。
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
もちろん、より冗長なコードですが、SQL Serverに強制的に実行させることができることは明らかです。スキャンを回避するか、少なくとも、はるかに小さい結果セットが削除されるまでルックアップを延期します。 Paul White(@SQL_Kiwi)は、初期のSQLServer2012ベータ版でOFFSET/FETCHが導入される前の、2010年に同様のアプローチを調査しました(私はその年の後半に最初にブログを書きました)。
上記のシナリオを前提として、ORDER BY句で指定された列の違いだけを使用して、さらに3つのプロシージャを作成しました(2つ必要です。1つはページ自体用で、もう1つは結果の順序付け用です):
>CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail 注:主キーがクラスター化されていない場合、これはうまく機能しない可能性があります。サポートインデックスを使用できる場合、これをより良く機能させるトリックの一部は、クラスター化キーがすでにインデックスに含まれていることです。ルックアップはしばしば避けられます。
クラスタリングキーソートのテスト
最初に、クラスタリングキーによる並べ替えという2つの方法の間に大きな差異がないと予想した場合をテストしました。これらのステートメントをSQLSentryPlan Explorerでバッチで実行し、期間、読み取り、およびグラフィカルプランを観察して、各クエリが完全にコールドキャッシュから開始されていることを確認しました:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
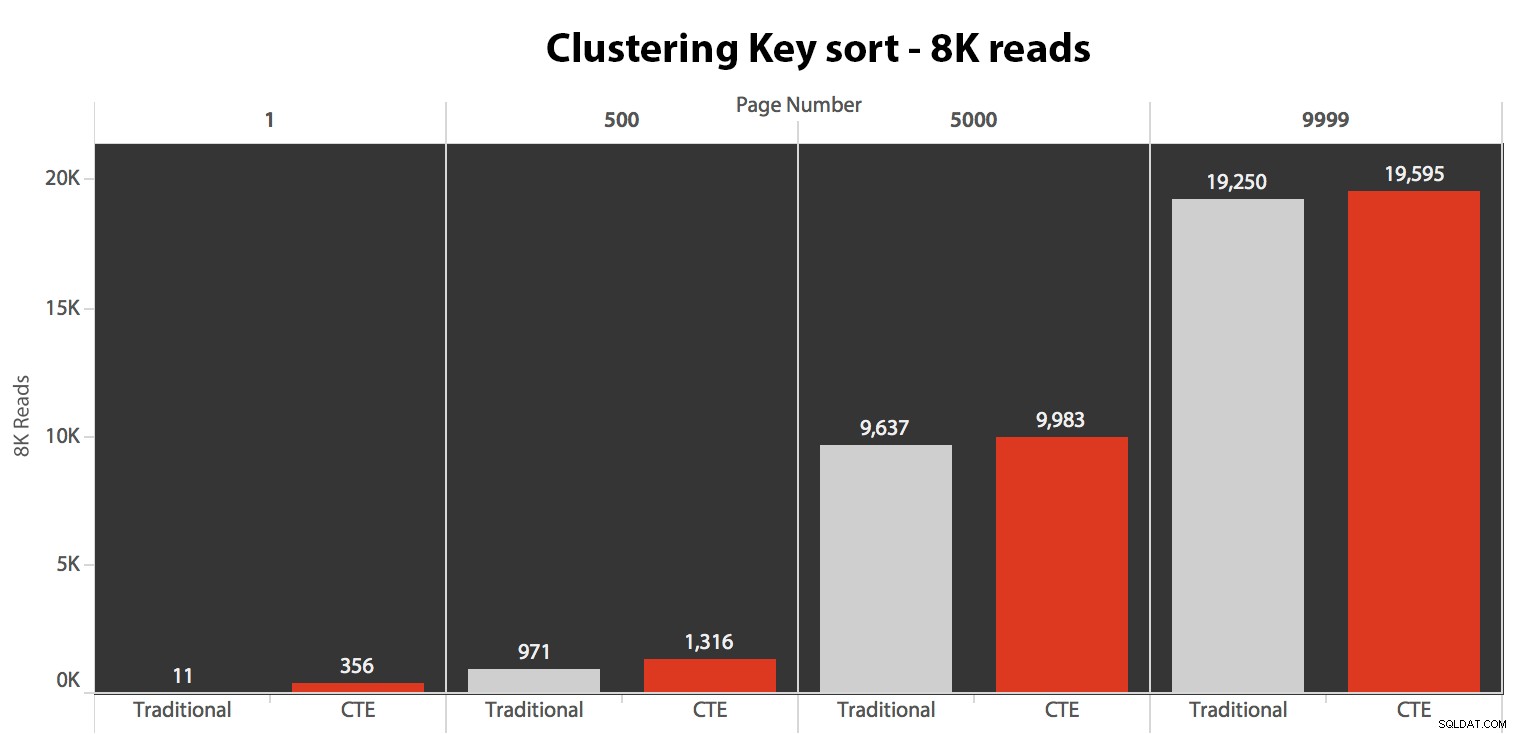
ここでの結果は驚くべきものではありませんでした。 5回以上の実行で、平均読み取り数がここに表示されます。クラスタリングキーで並べ替えた場合、すべてのページ番号で2つのクエリの違いはごくわずかです。
すべての場合のデフォルトの方法(プランエクスプローラーに表示)の計画は次のとおりです。
CTEベースの方法の計画は次のようになりましたが:
これで、キャッシュに関係なくI / Oは同じでしたが(コールドキャッシュシナリオでは先読み読み取りがはるかに多い)、コールドキャッシュとウォームキャッシュ(DROPCLEANBUFFERSコマンドをコメントアウトした場所)を使用して期間を測定しました。測定する前にクエリを複数回実行しました)。これらの期間は次のようになりました:
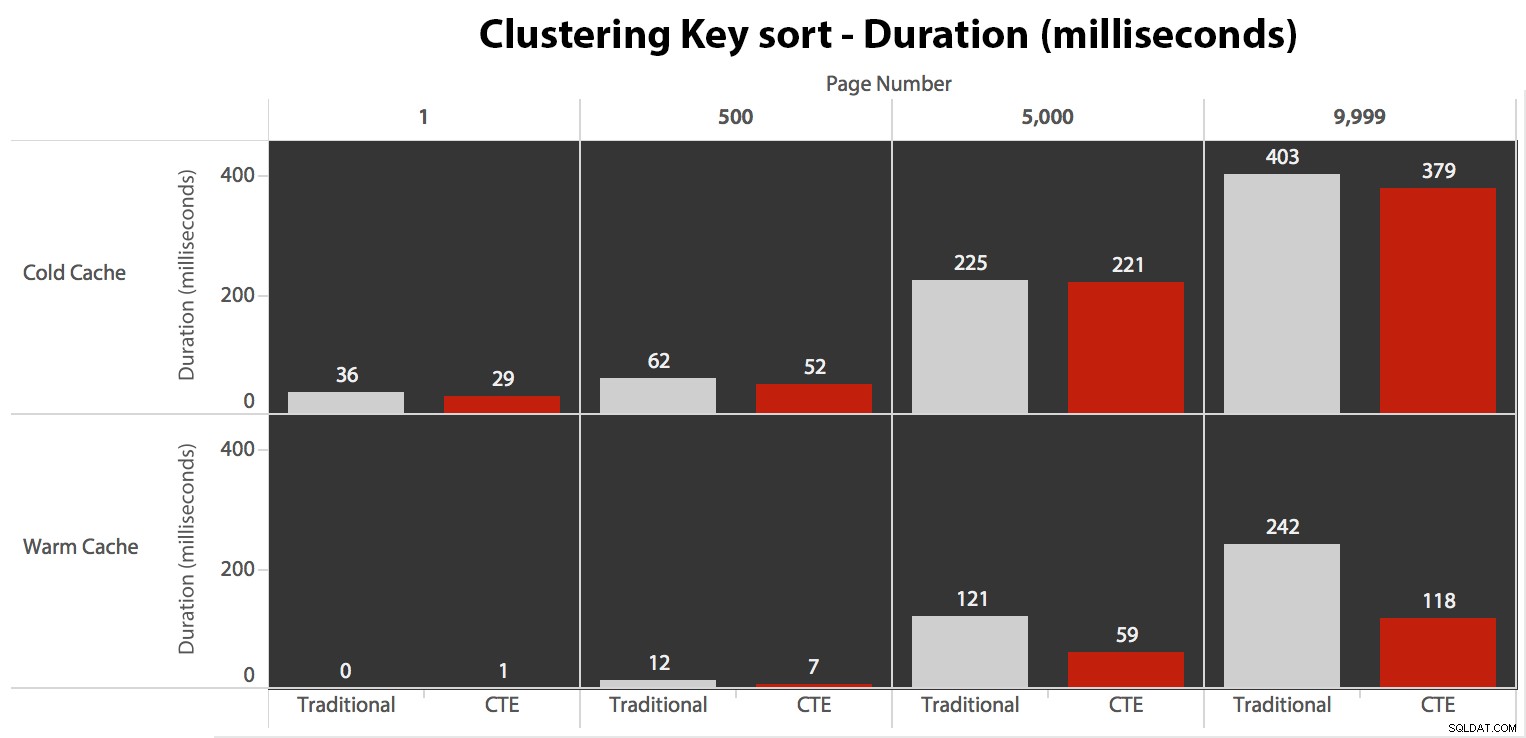
ページ数が増えるにつれて期間が長くなるパターンを見ることができますが、スケールを覚えておいてください。行999,801-> 999,900に到達するには、最悪の場合は0.5秒、最良の場合は118ミリ秒です。 CTEアプローチが勝ちますが、全体ではありません。
電話帳の並べ替えのテスト
次に、2番目のケースをテストしました。このケースでは、LastName、FirstNameの非カバーインデックスによって並べ替えがサポートされていました。上記のクエリは、Test_1のすべてのインスタンスを変更しただけです Test_2へ 。コールドキャッシュを使用した読み取りは次のとおりです。
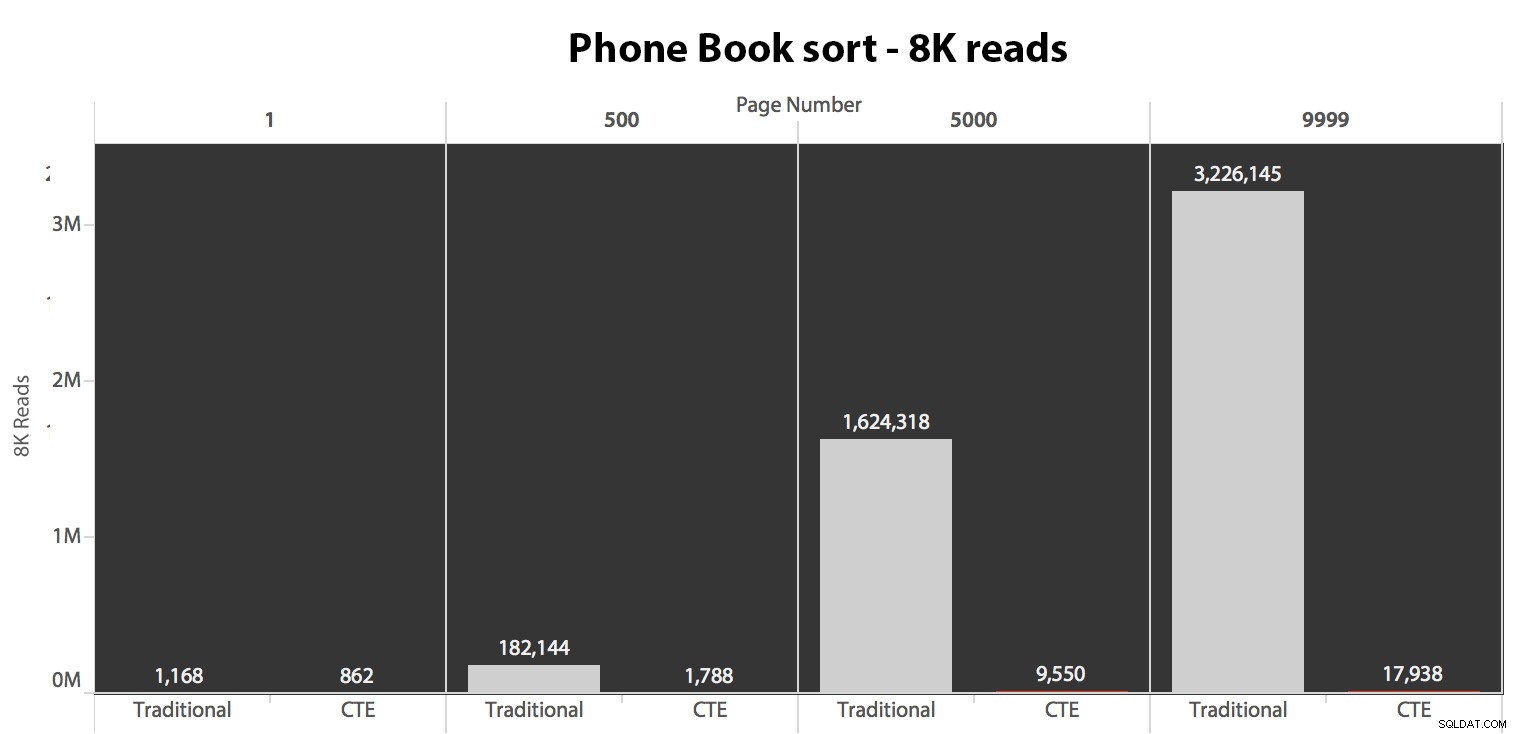
(ウォームキャッシュでの読み取りは同じパターンに従いました。実際の数はわずかに異なりますが、別のグラフを正当化するには不十分です。)
クラスター化されたインデックスを使用して並べ替えを行わない場合、OFFSET/FETCHの従来の方法に関連するI/Oコストは、CTEで最初にキーを識別し、残りの列をプルする場合よりもはるかに悪いことは明らかです。そのサブセットのためだけに。
従来のクエリアプローチの計画は次のとおりです。
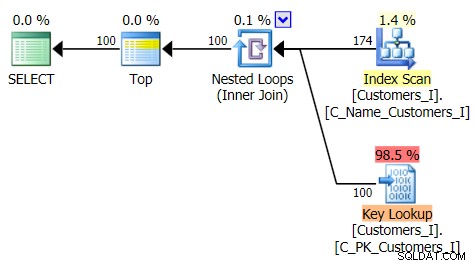
そして、私の代替のCTEアプローチの計画:
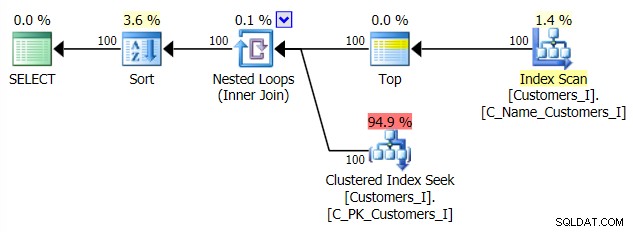
最後に、期間:
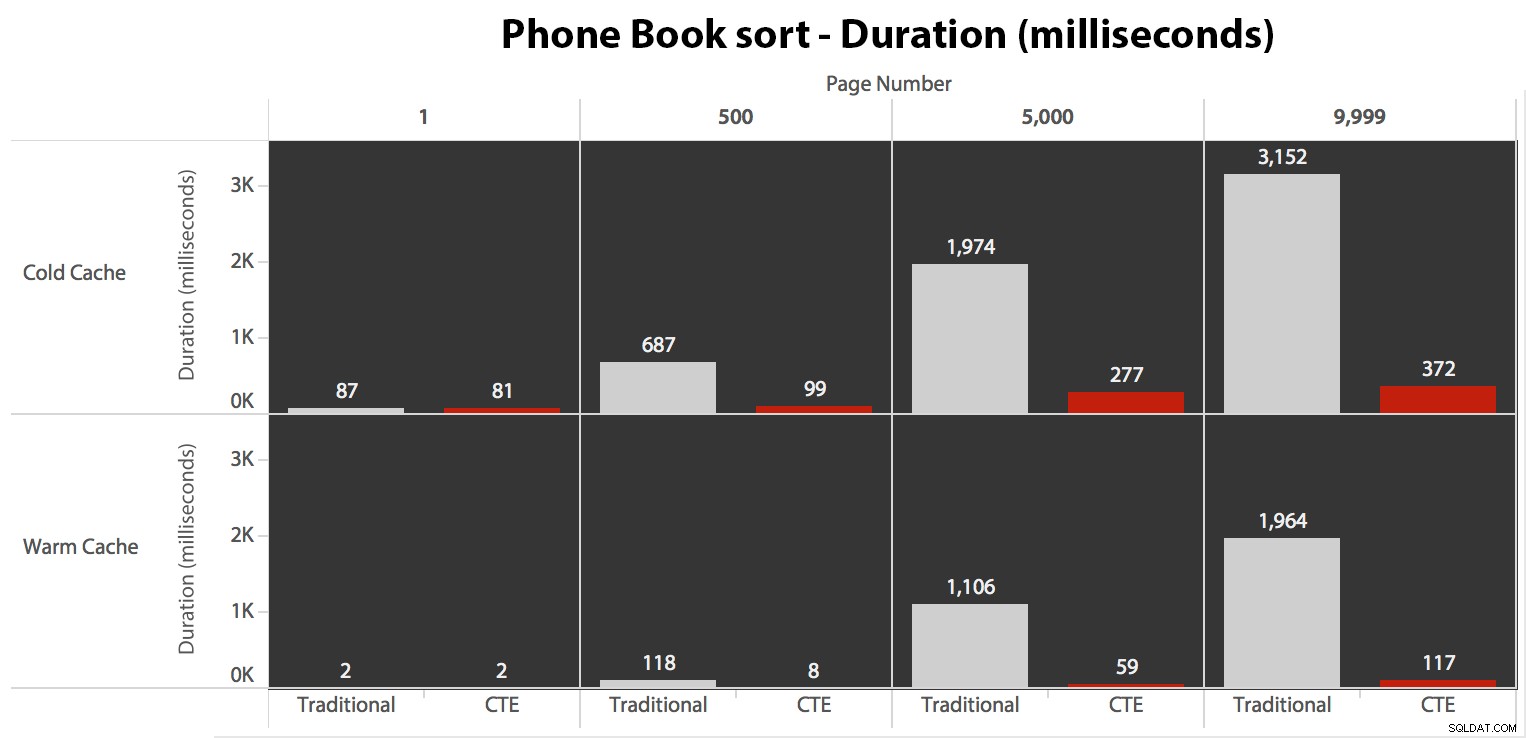
従来のアプローチでは、ページネーションの終わりに向かって行進するにつれて、持続時間が非常に明らかに上昇します。 CTEアプローチも非線形パターンを示しますが、それははるかに目立たず、すべてのページ番号でより良いタイミングをもたらします。最後から2番目のページで117ミリ秒が表示されますが、従来のアプローチでは2秒近くかかります。
ユーザー定義の並べ替えのテスト
最後に、Test_3を使用するようにクエリを変更しました ストアドプロシージャ。ソートがユーザーによって定義され、サポートするインデックスがない場合をテストします。 I / Oは、テストの各セットで一貫していました。グラフはあまり面白くないので、リンクします。簡単に言うと、すべてのテストで19,000を少し超える読み取りがありました。その理由は、順序付けをサポートするインデックスがないため、すべてのバリエーションでフルスキャンを実行する必要があったためです。従来のアプローチの計画は次のとおりです。
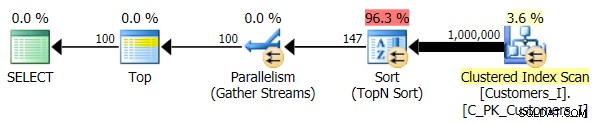
そして、クエリのCTEバージョンの計画は驚くほど複雑に見えますが…
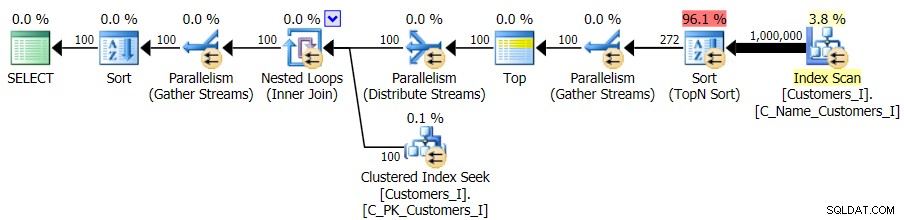
…1つの場合を除いて、期間が短くなります。期間は次のとおりです。
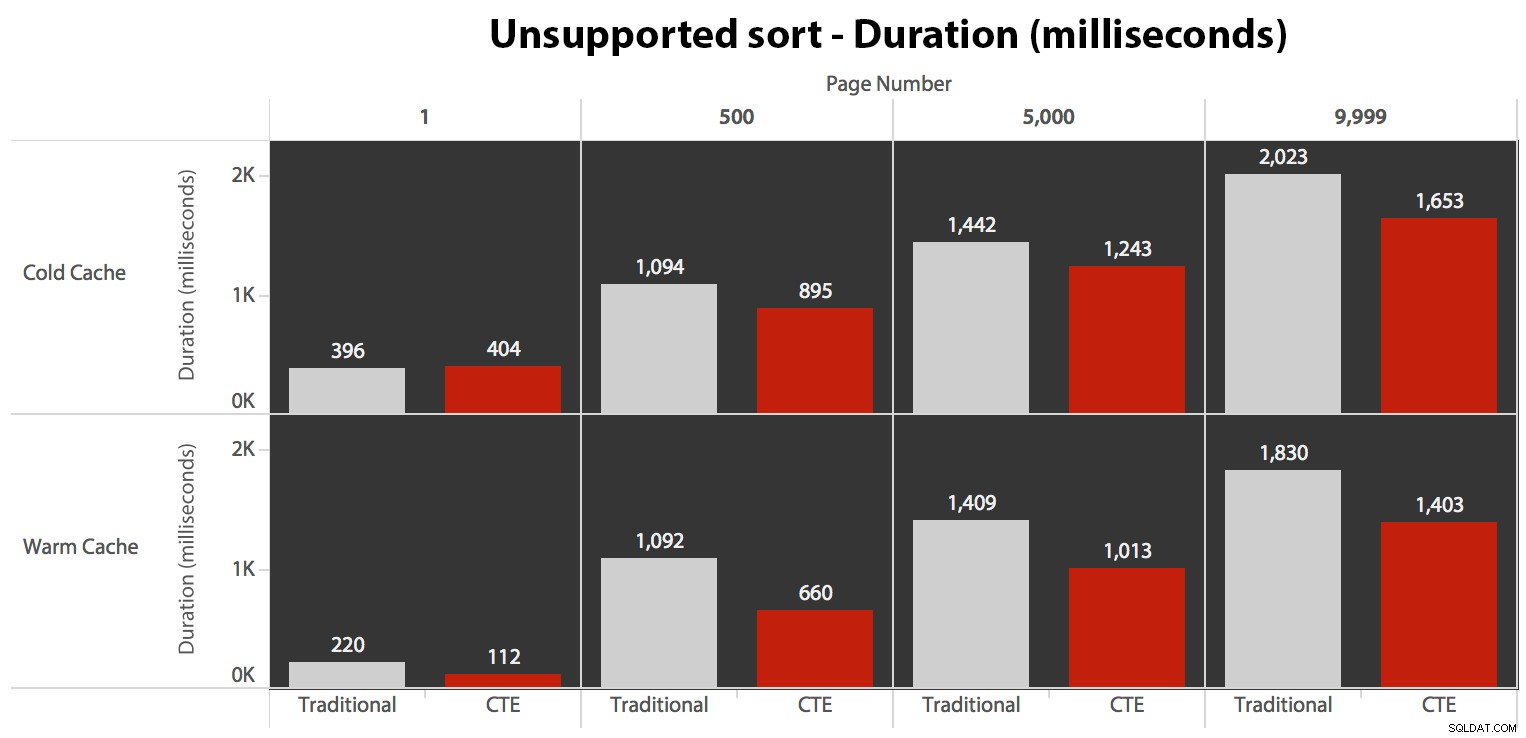
ここではどちらの方法でも線形パフォーマンスを得ることができないことがわかりますが、最初のコールドキャッシュクエリを除くすべてのケースで、CTEはかなりのマージン(16%から65%のどこかで優れています)でトップになりますページ(なんと8ミリ秒で失われた場所)。また、従来の方法は「中央」(500ページと5000ページ)のウォームキャッシュではほとんど役に立たないことに注意してください。セットの終わりに向かってのみ、言及する価値のある効率があります。
大音量
いくつかの実行を個別にテストして平均をとった後、ビジー状態のシステムで実際のトラフィックをある程度シミュレートする大量のトランザクションをテストすることも理にかなっていると思いました。そこで、クエリ方法(従来のページングとCTE)と並べ替えの種類(クラスタリングキー、電話帳、サポートされていない)の組み合わせごとに1つずつ、6つのステップでジョブを作成し、上記の4つのページ番号を100ステップのシーケンスでヒットしました。 、各10回、およびランダムに選択された60個の他のページ番号(ただし、各ステップで同じ)。ジョブ作成スクリプトを生成した方法は次のとおりです。
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; 結果のジョブステップリストとステップのプロパティの1つは次のとおりです。
ジョブを5回実行してから、ジョブ履歴を確認しました。各ステップの平均実行時間は次のとおりです。
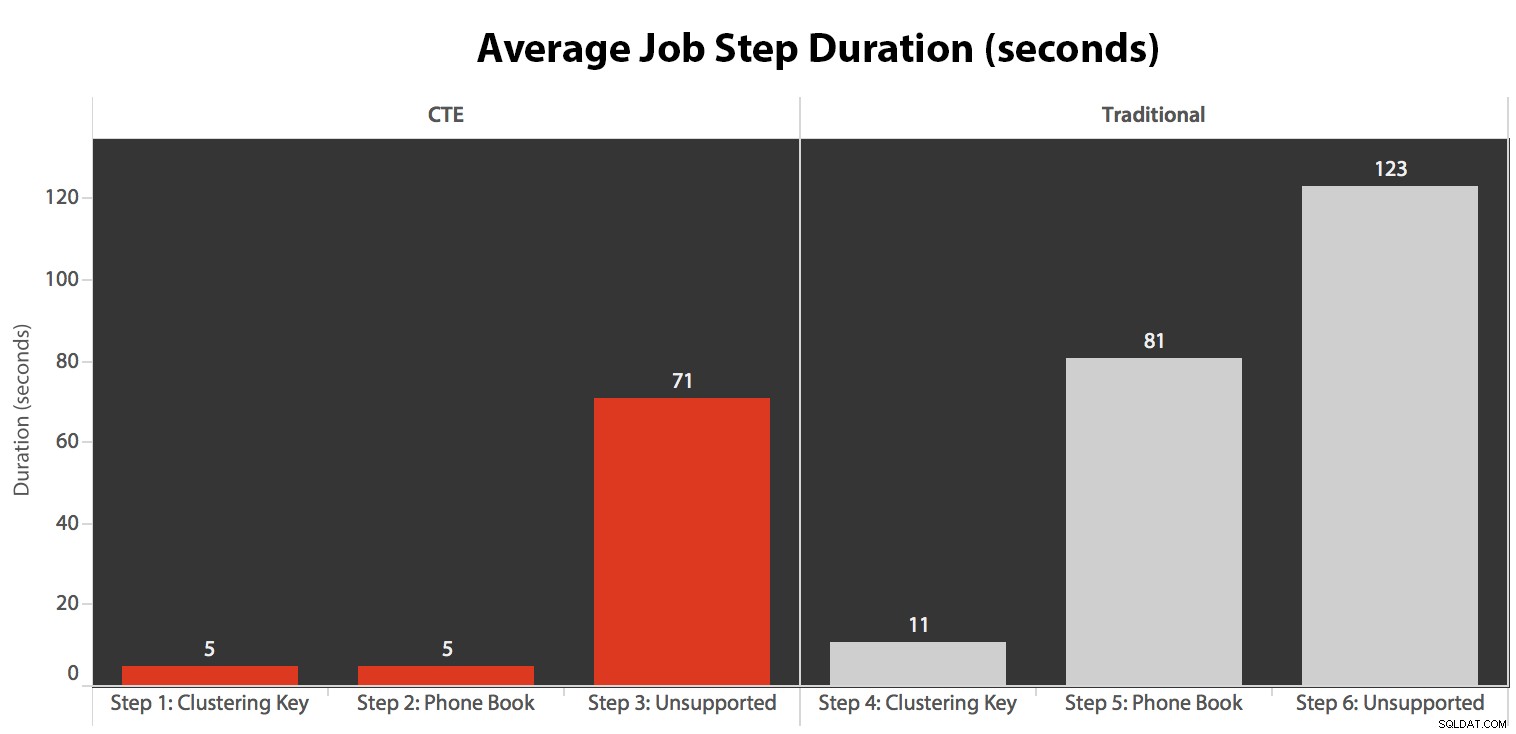
また、SQL SentryEventManagerカレンダーの実行の1つを関連付けました…
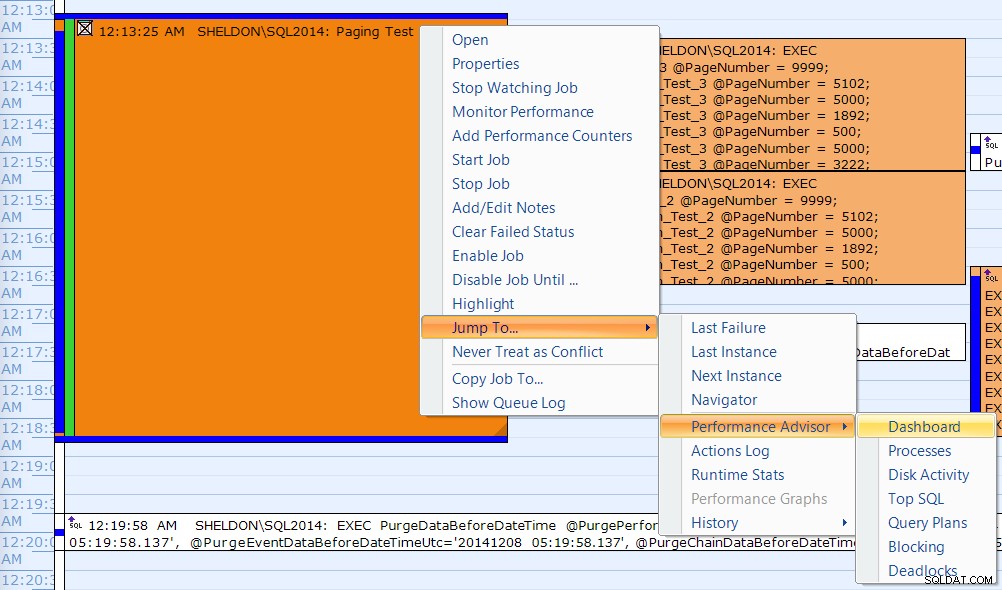
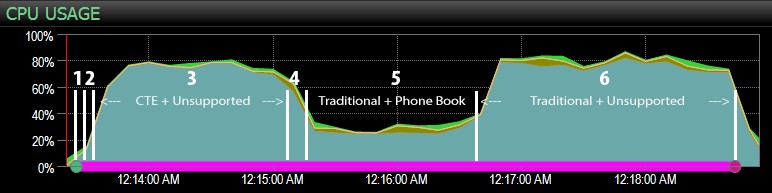
…SQLSentryダッシュボードを使用して、6つのステップのそれぞれが実行された場所を大まかに手動でマークします。ダッシュボードのWindows側からのCPU使用率チャートは次のとおりです。
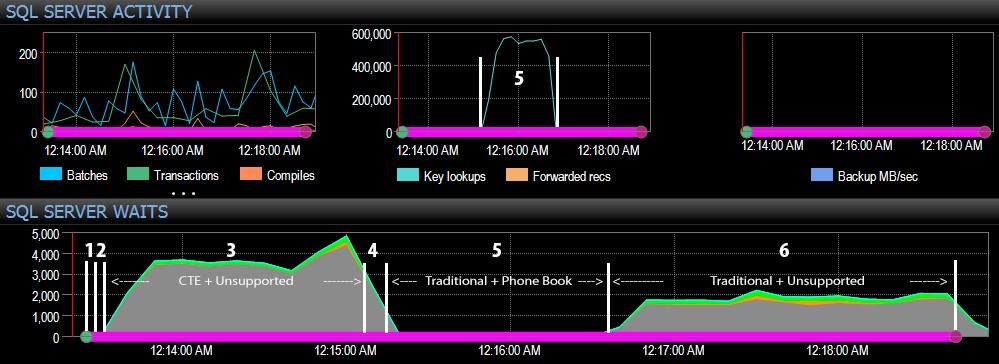
また、ダッシュボードのSQL Server側から見ると、興味深い指標はキールックアップと待機のグラフにありました。
純粋に視覚的な観点からの最も興味深い観察:
- ステップ3(CTE +サポートインデックスなし)およびステップ6(従来型+サポートインデックスなし)の間、CPUは約80%とかなり高温になっています。
- CXPACKETの待機時間は、ステップ3では比較的長く、ステップ6ではそれほどではありません。
- 約1分間でキールックアップが約600,000に大幅に増加することがわかります(ステップ5 –電話帳スタイルのインデックスを使用した従来のアプローチに関連)。
将来のテストでは、GUIDに関する以前の投稿と同様に、データがメモリに収まらない(シミュレートしやすい)システムとディスクが遅い(シミュレートしにくい)システムでこれをテストしたいと思います。 、これらの結果の一部は、すべての本番システムにあるわけではないもの、つまり高速ディスクと十分なRAMの恩恵を受ける可能性があるためです。また、テストを拡張して、より多くのバリエーションを含める必要があります(スキニーとワイドの列、スキニーとワイドのインデックス、実際にすべての出力列をカバーする電話帳のインデックス、および両方向の並べ替えを使用)。スコープクリープは、この最初の一連のテストのテストの範囲を確実に制限しました。
SQLServerのページネーションを改善する方法
ページネーションは必ずしも苦痛である必要はありません。 SQL Server 2012は確かに構文を簡単にしますが、ネイティブ構文をプラグインするだけでは、必ずしも大きなメリットが得られるとは限りません。ここでは、CTEを使用して少し冗長な構文を使用すると、最良の場合はパフォーマンスが大幅に向上し、最悪の場合はパフォーマンスの違いが無視できることを示しました。データの場所とデータの取得を2つの異なるステップに分けることで、一部のシナリオでは、CXPACKETの待機時間が長くなる以外に、大きなメリットが見られます(その場合でも、並列クエリは、待機をほとんどまたはまったく表示しない他のクエリよりも速く終了しました。したがって、彼らが「悪い」CXPACKETである可能性は低く、誰もが警告するのを待っています。
それでも、サポートするインデックスがない場合は、より高速な方法でも低速です。ユーザーが選択する可能性のあるすべての並べ替えアルゴリズムにインデックスを実装したくなるかもしれませんが、提供するオプションを少なくすることを検討することをお勧めします(インデックスは無料ではないことは誰もが知っているため)。たとえば、アプリケーションは、LastNameの昇順*および* LastNameの降順による並べ替えを絶対にサポートする必要がありますか?姓がZで始まる顧客に直接アクセスしたい場合は、*最後の*ページに移動して逆方向に作業することはできませんか?これは、技術的な決定よりもビジネスと使いやすさの決定です。最もあいまいな並べ替えオプションでも最高のパフォーマンスを得るには、すべての並べ替え列のインデックスを両方向に叩く前に、オプションとして保持してください。