これは、SQLServerの行モード並列プランの実行を開始する方法を深く掘り下げた5部構成のシリーズの3番目です。パート1は親タスクの実行コンテキストゼロを初期化し、パート2はクエリスキャンツリーを作成しました。これで、クエリスキャンを開始し、初期段階を実行する準備が整いました。 処理し、最初の追加の並列タスクを開始します。
親タスクのみを思い出してください 現在存在し、取引所(並列処理オペレーター)には消費者側しかありません。それでも、親タスクのワーカースレッドでクエリの実行を開始するには、これで十分です。クエリプロセッサは、CQueryScan::StartupQueryの呼び出しを介してクエリスキャンプロセスを開始することで実行を開始します。 。計画のリマインダー(クリックして拡大):
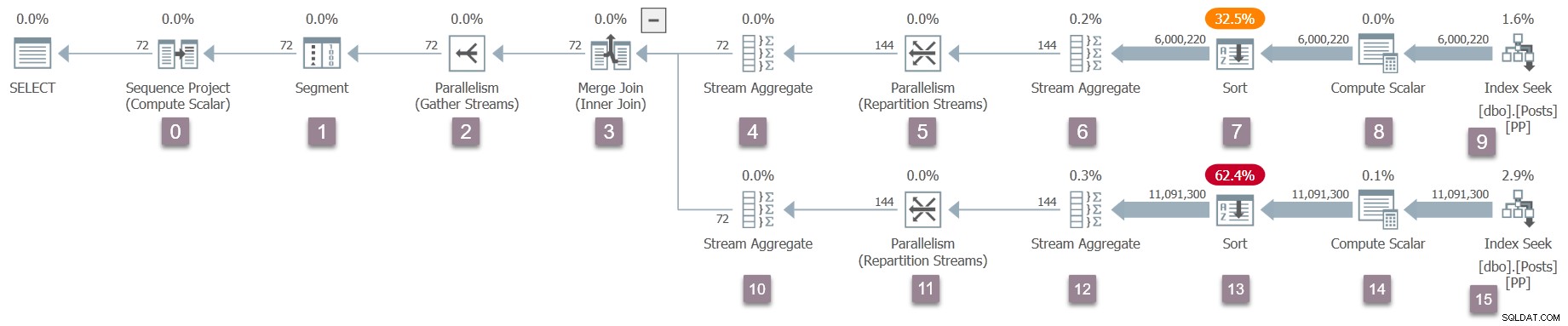
これは、これまでのプロセスの最初のポイントであり、実行中の実行計画 sys.dm_exec_query_statistics_xmlで利用可能(SQL Server 2016 SP1以降) 。すべての一時的なカウンターがゼロであるため、この時点でそのような計画に特に興味深いものはありませんが、計画は少なくとも利用可能です 。並列タスクがまだ作成されていないこと、または取引所にプロデューサー側がないことを示唆するものはありません。計画はすべての点で「正常」に見えます。
これは並行計画であるため、ブランチに分割して表示すると便利です。これらは下に陰影が付けられ、ブランチAからDとしてラベル付けされています:
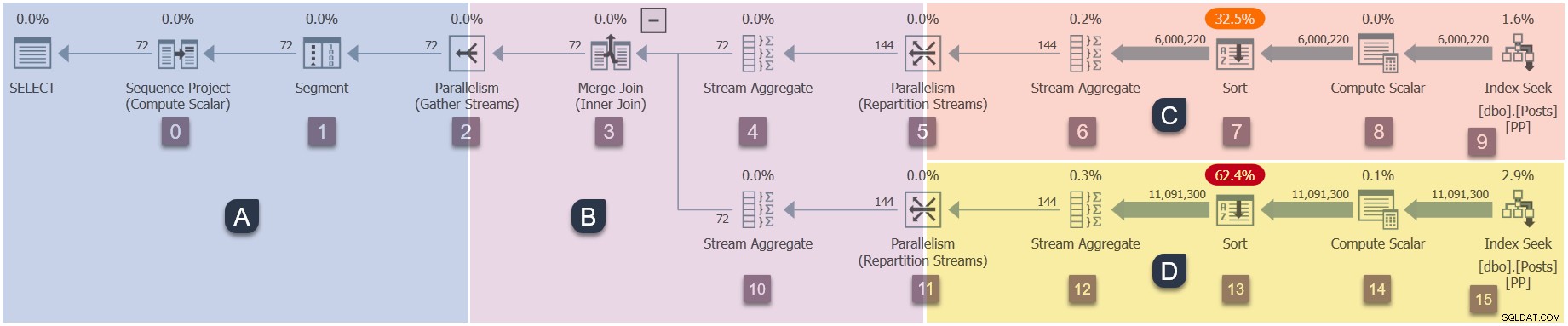
ブランチAは親タスクに関連付けられており、セッションによって提供されるワーカースレッドで実行されます。 追加の並列タスクを実行するために、追加の並列ワーカーが開始されます ブランチB、C、およびDに含まれています。これらのブランチは並列であるため、それぞれにDOPの追加タスクとワーカーがあります。
この例のクエリはDOP2で実行されているため、ブランチBは2つの追加タスクを取得します。同じことがブランチCとブランチDにも当てはまり、合計 6 追加のタスク。各タスクは、独自の実行コンテキストで独自のワーカースレッドで実行されます。
2人のスケジューラー (S 1 およびS2 )は、追加の並列ワーカーを実行するためにこのクエリに割り当てられます。追加の各ワーカーは、これら2つのスケジューラーのいずれかで実行されます。親ワーカーは別のスケジューラーで実行される可能性があるため、DOP2クエリは最大3つを使用する可能性があります いつでもプロセッサコア。
要約すると、私たちの計画は最終的に次のようになります。
- ブランチA (親)
- 親タスク。
- 親ワーカーのスレッド。
- 実行コンテキストゼロ。
- クエリで使用できる単一のスケジューラ。
- ブランチB (追加)
- 2つの追加タスク。
- 新しい各タスクにバインドされた追加のワーカースレッド。
- 2つの新しい実行コンテキスト(新しいタスクごとに1つ)。
- 1つのワーカースレッドがスケジューラーS1で実行されます 。もう1つはスケジューラS2で実行されます 。
- ブランチC (追加)
- 2つの追加タスク。
- 新しい各タスクにバインドされた追加のワーカースレッド。
- 2つの新しい実行コンテキスト(新しいタスクごとに1つ)。
- 1つのワーカースレッドがスケジューラーS1で実行されます 。もう1つはスケジューラS2で実行されます 。
- ブランチD (追加)
- 2つの追加タスク。
- 新しい各タスクにバインドされた追加のワーカースレッド。
- 2つの新しい実行コンテキスト(新しいタスクごとに1つ)。
- 1つのワーカースレッドがスケジューラーS1で実行されます 。もう1つはスケジューラS2で実行されます 。
問題は、これらすべての追加のタスク、ワーカー、および実行コンテキストがどのように作成され、いつ実行を開始するかです。
追加のタスクの順序 この特定の計画の実行を開始 は:
- ブランチA(親タスク)。
- ブランチC(追加の並列タスク)。
- ブランチD(追加の並列タスク)。
- ブランチB(追加の並列タスク)。
それはあなたが期待していた起動順序ではないかもしれません。
大幅な遅延が発生する可能性があります これらの各ステップの間に、理由を説明します。この段階での重要なポイントは、追加のタスク、ワーカー、および実行コンテキストがないことです。 すべてが一度に作成され、そうではありません すべてが同時に実行を開始します。
SQL Serverは、すべての余分な並列ビットを一度に開始するように設計されている可能性があります。それは理解しやすいかもしれませんが、一般的にはあまり効率的ではありません。これにより、クエリで使用される追加のスレッドやその他のリソースの数が最大化され、不要な並列待機が大量に発生します。
SQL Serverで採用されている設計では、並列プランで使用されるワーカースレッドの総数は(DOPにブランチの総数を掛けたもの)よりも少ないことがよくあります。これは、他のブランチを開始する必要がある前に、一部のブランチが完了するまで実行できることを認識することによって実現されます。これにより、同じクエリ内でスレッドを再利用できるようになり、通常、全体的なリソース消費が削減されます。
次に、並行計画の開始方法の詳細に移りましょう。
クエリスキャンは、親タスクがOpen()を呼び出して実行を開始します ツリーのルートにあるイテレータ上。これが実行シーケンスの開始です:
- ブランチA(親タスク)。
- ブランチC(追加の並列タスク)。
- ブランチD(追加の並列タスク)。
- ブランチB(追加の並列タスク)。
このクエリは「実際の」計画が要求された状態で実行されているため、ルートイテレータはではありません ノード0のシーケンスプロジェクト演算子。むしろ、これは非表示のプロファイリングイテレータです。 行モードプランでランタイムメトリックを記録します。
次の図は、プランのブランチAにあるクエリスキャンイテレータを示しています。非表示のプロファイリングイテレータの位置は「眼鏡」アイコンで表されています。
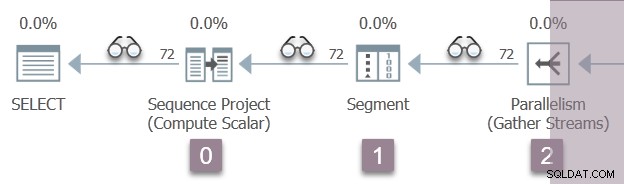
実行は、最初のプロファイラーCQScanProfileNew::Openを開くための呼び出しから始まります。 。これにより、営業時間が設定されます オペレーティングシステムのQueryPerformanceCounterAPIを介した子シーケンスプロジェクトオペレーター向け。
この番号はsys.dm_exec_query_profilesで確認できます。 :
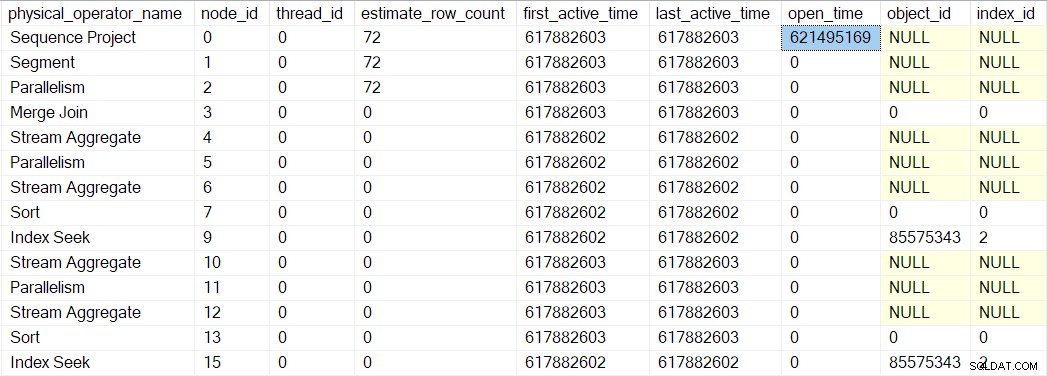
そこのエントリには演算子名がリストされている場合がありますが、データはプロファイラーから取得されます オペレーター自体ではなく、オペレーターの上にあります。
たまたま、シーケンスプロジェクト (CQScanSeqProjectNew )開いたときに作業を行う必要はありません 、したがって、実際にはOpen()はありません 方法。シーケンスプロジェクトの上のプロファイラーは と呼ばれるので、シーケンスプロジェクトのオープンタイムはDMVに記録されます。
プロファイラーのOpen メソッドはOpenを呼び出しません シーケンスプロジェクトで(これがないため)。代わりに、Openを呼び出します 次のイテレータのプロファイラで順番に。これはセグメントです ノード1のイテレータ。これにより、前のプロファイラーがシーケンスプロジェクトに対して行ったように、セグメントのオープン時間が設定されます。
セグメントイテレータはします 開いたときにやることがあるので、次の呼び出しはCQScanSegmentNew::Openです。 。セグメントが必要な処理を実行すると、次のイテレータ(コンシューマー)のプロファイラーを順番に呼び出します。 ストリーム交換の収集の側面 ノード2:
開くプロセスでクエリスキャンツリーを下る次の呼び出しは、CQScanExchangeNew::Openです。 、それは物事がより面白くなり始めるところです。
取引所の消費者側に開くように依頼する:
- ローカル(並列ネスト)トランザクションを開きます(
CXTransLocal::Open)。すべてのプロセスには包含トランザクションが必要であり、追加の並列タスクも例外ではありません。親(ベース)トランザクションを直接共有することはできないため、ネストされたトランザクションが使用されます。並列タスクが基本トランザクションにアクセスする必要がある場合、ラッチで同期し、NESTING_TRANSACTION_READONLYに遭遇する可能性があります またはNESTING_TRANSACTION_FULL待ちます。 - 現在のワーカースレッドを交換ポート(
CXPort::Register)に登録します 。 - エクスチェンジのコンシューマー側の他のスレッドと同期します(
sqlmin!CXTransLocal::Synchronize)。ギャザーストリームのコンシューマー側には他のスレッドがないため、この場合、これは基本的にノーオペレーションです。
親タスクがブランチAのエッジに到達しました。次のステップは特定です。 行モードの並列計画へ:親タスクは、CQScanExchangeNew::EarlyPhasesを呼び出して実行を継続します ノード2のギャザーストリーム交換イテレータ上。これは、通常のOpenを超える追加のイテレータメソッドです。 、GetRow 、およびClose あなたの多くが精通している方法。 EarlyPhases 行モードの並列プランでのみ呼び出されます。
この時点で何かを明確にしたいと思います。ノード2でのストリームの収集交換のプロデューサー側にはありません まだ作成されており、いいえ 追加の並列タスクが作成されました。現在実行中の唯一のスレッドを使用して、親タスクのコードをまだ実行しています。
すべてのイテレータがEarlyPhasesを実装しているわけではありません 、行モードの並列プランでは、現時点ですべてのユーザーが特別なことを行うわけではないためです。これは、Openを実装していないシーケンスプロジェクトに類似しています。 当時は何の関係もないからです。 EarlyPhasesを使用する主なイテレータ メソッドは次のとおりです:
-
CQScanConcatNew(連結)。 -
CQScanMergeJoinNew(結合をマージします)。 -
CQScanSwitchNew(スイッチ)。 -
CQScanExchangeNew(並列処理)。 -
CQScanNew(行セットアクセス(スキャンやシークなど)) -
CQScanProfileNew(非表示のプロファイラー)。 -
CQScanLightProfileNew(目に見えない軽量プロファイラー)。
親タスク EarlyPhasesを呼び出して続行します ノード2でのストリームの収集交換を超えた子オペレーターの場合。ブランチ境界を越えて移動するタスクは異常に見えるかもしれませんが、実行コンテキスト0には、交換を含むシリアルプラン全体が含まれていることに注意してください。初期段階の処理は並列処理の初期化に関するものであるため、カウントされません 実行としてそれ自体 。
追跡しやすくするために、次の図は、プランのブランチBのイテレータを示しています。
まだ実行コンテキストがゼロであることを忘れないでください。便宜上、これをブランチBとだけ呼んでいます。 まだ開始していません まだ並列実行。
ブランチBでの初期フェーズのコード呼び出しのシーケンスは次のとおりです。
-
CQScanProfileNew::EarlyPhasesノード3の上のプロファイラーの場合。 -
CQScanMergeJoinNew::EarlyPhasesノード3でマージ結合 。 -
CQScanProfileNew::EarlyPhasesノード4の上のプロファイラーの場合。ノード4のストリームアグリゲート それ自体には初期段階の方法はありません。 -
CQScanProfileNew::EarlyPhasesノード5の上のプロファイラー上。 -
CQScanExchangeNew::EarlyPhases再パーティションストリームの場合 ノード5で交換します。
この段階では、マージ結合への外部(上部)入力のみを処理していることに注意してください。これは、通常の行モード実行の反復シーケンスです。並行計画に特有のものではありません。
初期段階の処理は、ブランチCのイテレータで続行されます:

ここでの呼び出しの順序は次のとおりです。
-
CQScanProfileNew::EarlyPhasesノード6の上のプロファイラーの場合。 -
CQScanProfileNew::EarlyPhasesノード7の上のプロファイラーの場合。 -
CQScanProfileNew::EarlyPhasesノード9の上のプロファイラー上。 -
CQScanNew::EarlyPhasesノード9でのインデックスシークの場合。
EarlyPhasesはありません ストリームの集計または並べ替えのメソッド。ノード8でスカラーの計算によって実行される作業は延期されます (並べ替える)ため、クエリスキャンツリーには表示されず、プロファイラーが関連付けられていません。
親タスク初期段階の処理 ノード2でのストリームの収集交換で開始しました。マージ結合への外部(上部)入力に続いて、ノード9でのインデックスシークに至るまで、クエリスキャンツリーを下降しました。途中で、親タスクは次のように呼び出しました。 EarlyPhases それをサポートするすべてのイテレータのメソッド。
これまでのところ、初期段階のアクティビティはどれも更新されていません プロファイリングDMVでいつでも。具体的には、初期段階の処理に影響を受けたイテレータには、「オープンタイム」が設定されていません。初期段階の処理は並列実行を設定するだけなので、これは理にかなっています—これらの演算子は開かれます 後で実行するため。
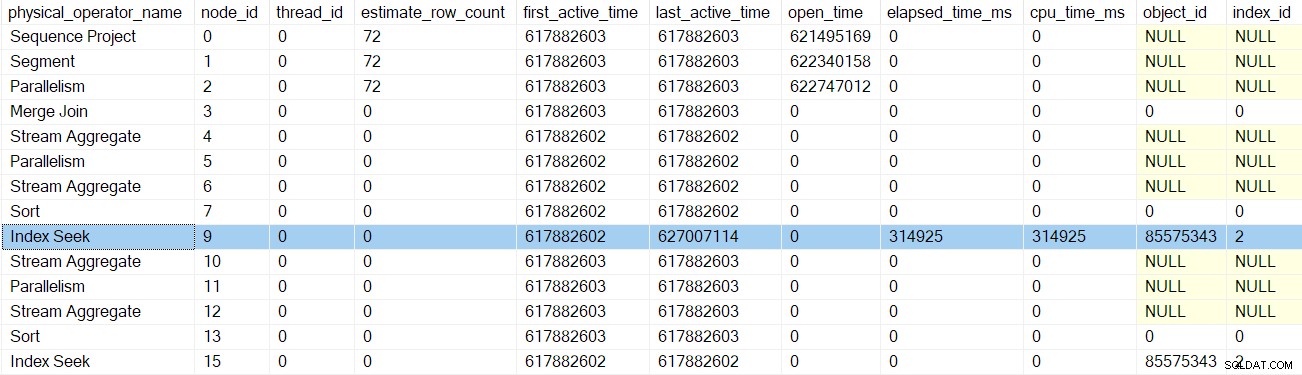
ノード9でのインデックスシークはリーフノードであり、子はありません。親タスクは、ネストされたEarlyPhasesから戻り始めます。 呼び出し、昇順 クエリスキャンツリーは、ストリームの収集交換に戻ります。
各プロファイラーはクエリパフォーマンスカウンターを呼び出します EarlyPhasesへのエントリ時のAPI メソッド、そして彼らは途中でそれを再び呼び出します。 2つの数値の差は、経過時間を表します イテレータとそのすべての子 (メソッド呼び出しはネストされているため)
インデックスシークのプロファイラーが戻った後、プロファイラーDMVはインデックスシークの経過時間とCPU時間を表示します のみ、および更新された最後のアクティブ 時間。この情報は親タスクに対して記録されていることにも注意してください (現時点での唯一のオプション):
初期フェーズの呼び出しが影響を与えた以前のイテレータはいずれも経過時間、または最後のアクティブ時間を更新していません。これらの数字は、ツリーを上るときにのみ更新されます。
次のプロファイラーの初期段階でリターンを呼び出した後、並べ替え 時間は更新されます:
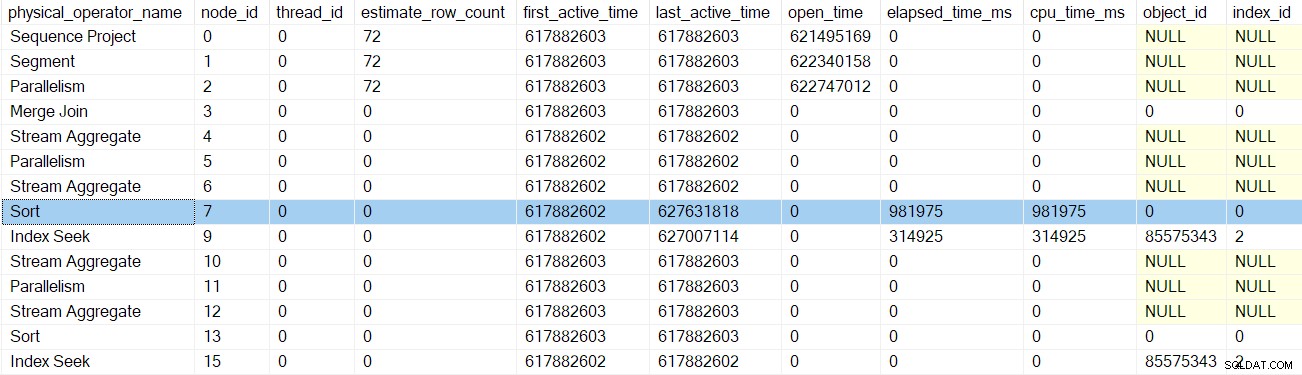
次のリターンでは、ストリームアグリゲートのプロファイラーを通過します。 ノード6で:
このプロファイラーから戻ると、EarlyPhasesに戻ります。 再パーティションストリームに電話する ノード5で交換 。これは、初期フェーズの呼び出しのシーケンスが開始された場所ではないことに注意してください。これは、ノード2でのストリームの収集交換でした。
プロファイリングデータを更新することを除けば、以前の初期段階の呼び出しはあまり効果がなかったようです。それはすべて再パーティションストリームで変わります ノード5で交換します。
ブランチCについてかなり詳細に説明し、他の並列ブランチにも適用されるいくつかの重要な概念を紹介します。この分野を一度カバーするということは、後のブランチディスカッションがより簡潔になる可能性があることを意味します。
サブツリーのネストされた初期段階の処理(ノード9でのインデックスシークまで)が完了すると、交換は独自の初期段階の作業を開始できます。これは、オープニングと同じように始まります ギャザーストリームはノード2で交換されます:
-
CXTransLocal::Open(ローカル並列サブトランザクションを開きます。) -
CXPort::Register(交換ポートに登録します)。
ブランチCには完全にブロッキングが含まれているため、次の手順は異なります イテレータ(ノード7でのソート)。ノード5の再パーティションストリームでの初期フェーズ処理は、次のことを行います。
-
CQScanExchangeNew::StartAllProducersを呼び出します 。 プロデューサー側を参照するものに遭遇したのはこれが初めてです 交換の。ノード5は、この計画でプロデューサー側を作成する最初の交換です。 - mutexを取得します そのため、他のスレッドが同時にタスクをキューに入れることはできません。
- プロデューサータスクの並列ネストトランザクションを開始します(
CXPort::StartNestedTransactionsおよびReadOnlyXactImp::BeginParallelNestedXact。 - サブトランザクションを親クエリスキャンオブジェクトに登録します(
CQueryScan::AddSubXact。 - プロデューサー記述子を作成します(
CQScanExchangeNew::PxproddescCreate。 - 新しいプロデューサー実行コンテキストを作成します (
CExecContext)実行コンテキストゼロから派生。 - プランイテレータのリンクされたマップを更新します。
- 新しいコンテキストのDOPを設定します(
CQueryExecContext::SetDop)したがって、すべてのタスクが全体的なDOP設定を認識します。 - パラメータキャッシュを初期化します(
CQueryExecContext::InitParamCache。 - 並列ネストされたトランザクションをベーストランザクションにリンクします(
CExecContext::SetBaseXact。 - 実行のために新しいサブプロセスをキューに入れます(
SubprocessMgr::EnqueueMultipleSubprocesses。 - 新しい並列タスクを作成
sqldk!SOS_Node::EnqueueMultipleTasksDirectを介したタスク 。
この時点での親タスクのコールスタック(これらのことを楽しんでいる人向け)は次のとおりです。
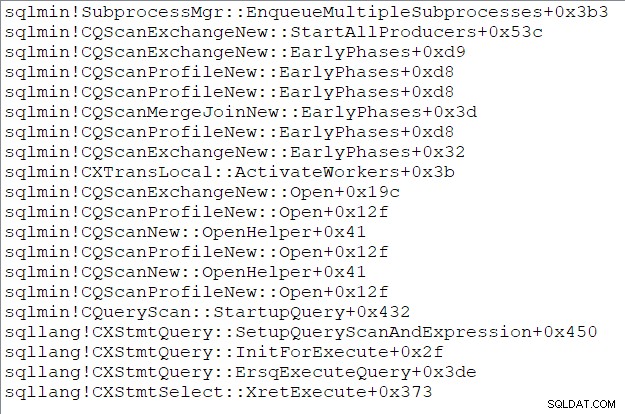
プロデューサー側を作成しました ノード5で交換される再パーティションストリームのうち、追加の並列タスクを作成しました ブランチCを実行し、すべてを親にリンクします 必要に応じて構造。ブランチCは最初です 分岐して並列タスクを開始します。このシリーズの最後のパートでは、ブランチCの開始について詳しく見ていき、残りの並列タスクを開始します。