友人のPeterLarssonから、供給と需要のマッチングを含むT-SQLチャレンジが送られてきました。挑戦する限り、それは手ごわいものです。これは、実際の生活ではかなり一般的なニーズです。説明は簡単で、カーソルベースのソリューションを使用して妥当なパフォーマンスで解決するのは非常に簡単です。トリッキーな部分は、効率的なセットベースのソリューションを使用してそれを解決することです。
ピーターが私にパズルを送ってくると、私は通常、提案された解決策で応答し、彼は通常、より優れた、優れた解決策を考え出します。彼が私にパズルを送ってくれて、素晴らしい解決策を思いつくように動機付けているのではないかと思うことがあります。
このタスクは共通のニーズを表しており、非常に興味深いので、私はピーターに、それと彼のソリューションをsqlperformance.comの読者と共有してもよいかどうか尋ねました。彼は、喜んで私に任せてくれました。
今月は、課題と従来のカーソルベースのソリューションを紹介します。以降の記事では、Peterと私が取り組んだソリューションを含むセットベースのソリューションを紹介します。
チャレンジ
課題には、次のコードを使用して作成したAuctionsというテーブルのクエリが含まれます。
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); このテーブルには、需要と供給のエントリが含まれます。需要エントリはコードDでマークされ、供給エントリはSでマークされます。タスクは、IDの順序に基づいて需要と供給の数量を照合し、結果を一時テーブルに書き込むことです。エントリは、BTC / USDなどの暗号通貨の売買注文、MSFT / USDなどの株式売買注文、または供給と需要を一致させる必要があるその他のアイテムまたは商品を表すことができます。オークションエントリに価格属性がないことに注意してください。前述のように、IDの順序に基づいて需要と供給の数量を一致させる必要があります。この順序付けは、価格(供給エントリの場合は昇順、需要エントリの場合は降順)またはその他の関連する基準から導き出された可能性があります。この課題では、物事を単純に保ち、IDがすでにマッチングに関連する順序を表していると想定するというアイデアでした。
例として、次のコードを使用して、オークションテーブルにサンプルデータの小さなセットを入力します。
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
次のように、需要と供給の数量を一致させる必要があります。
- 需要1と供給1000の数量が5.0に一致し、需要1が使い果たされ、供給1000の3.0が残ります 。
- 需要2と供給1000の数量が3.0に一致し、需要2と供給1000の両方が使い果たされます
- 需要3と供給2000の数量が6.0に一致し、需要3の2.0が残り、供給2000が枯渇します
- 需要3と供給3000の数量が2.0に一致し、需要3と供給3000の両方が使い果たされます
- 数量2.0は需要5と供給4000に一致し、需要5と供給4000の両方を使い果たします
- 需要6と供給5000の数量が4.0に一致し、需要6の4.0が残り、供給5000が枯渇します
- 需要6と供給6000の数量は3.0に一致し、需要6の1.0が残り、供給6000が使い果たされます
- 需要6と供給7000の数量が1.0に一致し、需要6が使い果たされ、供給7000の1.0が残ります 。
- 需要7と供給7000の数量が1.0に一致し、需要7の3.0が残り、供給7000が使い果たされます。需要8はどの供給エントリとも一致しないため、全数量2.0が残ります。
ソリューションは、結果の一時テーブルに次のデータを書き込むことになっています。
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
サンプルデータの大規模なセット
ソリューションのパフォーマンスをテストするには、より多くのサンプルデータのセットが必要になります。これを支援するために、次のコードを実行して作成した関数GetNumsを使用できます。
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO この関数は、要求された範囲の整数のシーケンスを返します。
この関数を使用すると、Peterが提供する次のコードを使用して、オークションテーブルにサンプルデータを入力し、必要に応じて入力をカスタマイズできます。
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; ご覧のとおり、買い手と売り手の数、および買い手と売り手の最小数と最大数をカスタマイズできます。上記のコードは、200,000の買い手と200,000の売り手を指定しているため、オークションテーブルに合計400,000行が表示されます。最後のクエリは、テーブルに書き込まれた需要(D)および供給(S)エントリの数を示します。前述の入力に対して次の出力を返します。
Code Items ---- ----------- D 200000 S 200000
上記のコードを使用して、さまざまなソリューションのパフォーマンスをテストし、購入者と販売者の数をそれぞれ50,000、100,000、150,000、および200,000に設定します。これは、テーブル内の行の総数が100,000、200,000、300,000、および400,000になることを意味します。もちろん、ソリューションのパフォーマンスをテストしたい場合は、入力をカスタマイズできます。
カーソルベースのソリューション
Peterはカーソルベースのソリューションを提供しました。それはかなり基本的であり、それはその重要な利点の1つです。ベンチマークとして使用されます。
このソリューションでは、2つのカーソルを使用します。1つはID順に並べられた需要エントリ用で、もう1つはID順に並べられた供給エントリ用です。フルスキャンとカーソルごとの並べ替えを回避するには、次のインデックスを作成します。
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
完全なソリューションのコードは次のとおりです。
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; ご覧のとおり、コードは一時テーブルを作成することから始まります。次に、2つのカーソルを宣言し、それぞれから行をフェッチして、現在の需要量を変数@DemandQuantityに書き込み、現在の供給量を@SupplyQuantityに書き込みます。次に、最後のフェッチが成功する限り、ループ内のエントリを処理します。このコードは、ループの本体に次のロジックを適用します。
現在の需要量が現在の供給量以下の場合、コードは次のことを行います。
- 一致した数量として需要数量(@DemandQuantity)を使用して、現在のペアで一時テーブルに行を書き込みます
- 現在の供給量(@SupplyQuantity)から現在の需要量を差し引きます
- デマンドカーソルから次の行を取得します
それ以外の場合、コードは次のことを行います。
- 現在の供給量がゼロより大きいかどうかをチェックし、ゼロより大きい場合は、次のことを行います。
- 供給量を一致した量として、現在のペアで一時テーブルに行を書き込みます
- 現在の需要量から現在の供給量を差し引きます
- 供給カーソルから次の行をフェッチします
ループが完了すると、一致するペアがなくなるため、コードはカーソルリソースをクリーンアップするだけです。
パフォーマンスの観点からは、カーソルのフェッチとループの一般的なオーバーヘッドが発生します。次に、このソリューションは、需要データに対して1回の順序付きパスを実行し、供給データに対して1回の順序付きパスを実行します。それぞれ、前に作成したインデックスのシークスキャンと範囲スキャンを使用します。カーソルクエリの計画を図1に示します。

図1:カーソルクエリの計画
計画では、並べ替えを伴わずに各部品(需要と供給)のシークおよび順序付き範囲スキャンを実行するため、線形スケーリングが使用されます。これは、図2に示すように、テスト時に得られたパフォーマンスの数値によって確認されました。
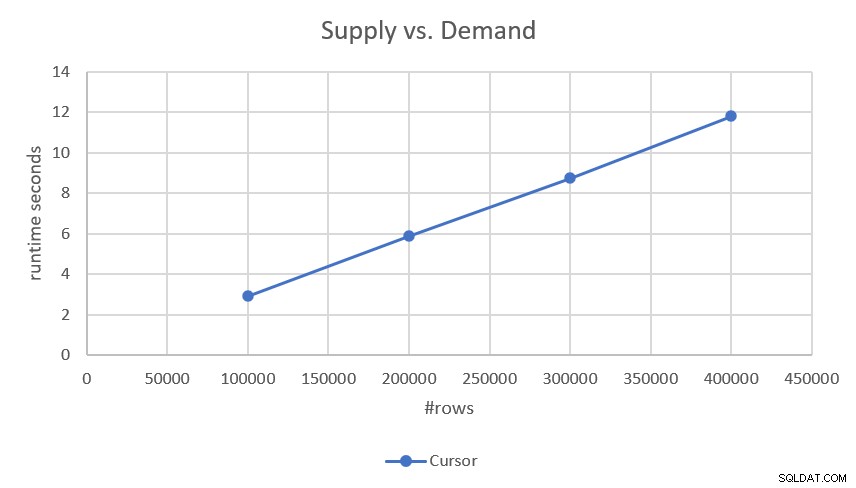
図2:カーソルベースのソリューションのパフォーマンス
より正確な実行時間に興味がある場合は、次のとおりです。
- 100,000行(50,000の要求と50,000の供給):2.93秒
- 200,000行:5.89秒
- 300,000行:8.75秒
- 400,000行:11.81秒
ソリューションに線形スケーリングがある場合、他のスケールで実行時間を簡単に予測できます。たとえば、100万行(たとえば、500,000のデマンドと500,000のサプライ)の場合、実行には約29.5秒かかります。
チャレンジはオンです
カーソルベースのソリューションには線形スケーリングがあり、そのため、悪くはありません。ただし、通常のカーソルフェッチとループのオーバーヘッドが発生します。明らかに、CLRベースのソリューションを使用して同じアルゴリズムを実装することにより、このオーバーヘッドを減らすことができます。問題は、このタスクに対してパフォーマンスの高いセットベースのソリューションを思い付くことができるかということです。
前述のように、来月から、パフォーマンスの低いソリューションとパフォーマンスの高いソリューションの両方を検討します。それまでの間、課題に取り組んでいる場合は、独自のセットベースのソリューションを考え出すことができるかどうかを確認してください。
ソリューションの正しさを検証するには、最初にその結果を、サンプルデータの小さなセットについてここに示されている結果と比較します。カーソルソリューションの結果と結果の対称差が空であることを確認することで、大量のサンプルデータを使用してソリューションの結果の妥当性を確認することもできます。カーソルの結果が#PairingsCursorという一時テーブルに格納され、カーソルの結果が#MyPairingsという一時テーブルに格納されているとすると、次のコードを使用してこれを実現できます。
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
結果は空になります。
頑張ってください!
[ソリューションにジャンプ:パート1 |パート2|パート3]