この記事は、名前付きテーブル式に関するシリーズの第12部です。これまで、ステートメントスコープの名前付きテーブル式である派生テーブルとCTE、および再利用可能な名前付きテーブル式であるビューについて説明してきました。今月は、インラインテーブル値関数(iTVF)を紹介し、他の名前付きテーブル式と比較した場合の利点について説明します。また、主にデフォルトの最適化戦略の違いに焦点を当てて、それらをストアドプロシージャと比較し、キャッシュと再利用の動作を計画します。最適化に関してはカバーすべきことがたくさんあるので、今月から議論を開始し、来月も続けます。
私の例では、TSQLV5というサンプルデータベースを使用します。これを作成してデータを設定するスクリプトはここにあり、そのER図はここにあります。
インラインテーブル値関数とは何ですか?
以前に説明した名前付きテーブル式と比較すると、iTVFはほとんどビューに似ています。ビューと同様に、iTVFはデータベース内の永続オブジェクトとして作成されるため、ビューと対話する権限を持つユーザーは再利用できます。ビューと比較したiTVFの主な利点は、入力パラメーターをサポートしているという事実です。したがって、iTVFを記述する最も簡単な方法は、パラメータ化されたビューとして作成することですが、技術的には、CREATEVIEWステートメントではなくCREATEFUNCTIONステートメントを使用して作成します。
iTVFをマルチステートメントテーブル値関数(MSTVF)と混同しないことが重要です。前者は、ビューに似た単一のクエリに基づく、インライン化できない名前付きテーブル式であり、この記事の焦点です。後者は、テーブル変数を出力として返すプログラムモジュールであり、返されたテーブル変数にデータを入力することを目的としたマルチステートメントフローが本体に含まれています。
構文
iTVFを作成するためのT-SQL構文は次のとおりです。
CREATE [OR ALTER]FUNCTION[<スキーマ名>。 ]<関数名>[(<入力パラメータ>)]
返品表
[WITH
AS
戻る
<テーブル式>[; ]
構文で、入力パラメーターを定義する機能を確認してください。
SCHEMABIDNING属性の目的はビューの場合と同じであり、同様の考慮事項に基づいて評価する必要があります。詳細については、シリーズのパート10を参照してください。
例
iTVFの例として、顧客ID(@custid)と数値(@n)を入力として受け入れ、Sales.Ordersテーブルから要求された最新の注文数を返す再利用可能な名前付きテーブル式を作成する必要があるとします。入力顧客向け。
ビューには入力パラメーターのサポートがないため、ビューを使用してこのタスクを実装することはできません。前述のように、iTVFはパラメータ化されたビューと考えることができるため、このタスクに適したツールです。
関数自体を実装する前に、Sales.Ordersテーブルにサポートインデックスを作成するコードを次に示します。
USE TSQLV5; GO CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(empid);
そして、Sales.GetTopCustOrdersという名前の関数を作成するためのコードは次のとおりです。
CREATE OR ALTER FUNCTION Sales.GetTopCustOrders ( @custid AS INT, @n AS BIGINT ) RETURNS TABLE AS RETURN SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
ベーステーブルやビューの場合と同様に、データを取得した後は、SELECTステートメントのFROM句でiTVFを指定します。これは、顧客1の最新の3つの注文をリクエストする例です:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
この例をクエリ1と呼びます。クエリ1の計画を図1に示します。
 図1:クエリ1の計画
図1:クエリ1の計画
iTVFのインラインとは何ですか?
インラインという用語の出典について疑問がある場合 インラインテーブル値関数では、それらがどのように最適化されるかに関係しています。インライン化の概念は、T-SQLがサポートする4種類の名前付きテーブル式すべてに適用でき、一部には、シリーズのパート4でネスト解除/置換として説明したものが含まれます。復習が必要な場合は、必ずパート4の関連セクションに戻ってください。
図1に示すように、関数がインライン化されたおかげで、SQL Serverは、基になるベーステーブルのインデックスと直接対話する最適なプランを作成できました。この場合、プランは以前に作成したサポートインデックスでシークを実行します。
iTVFは、デフォルトでパラメーター埋め込み最適化を適用することにより、インライン化の概念をさらに一歩進めます。 Paul Whiteは、彼の優れた記事「パラメータースニッフィング、埋め込み、およびRECOMPILEオプション」でパラメーター埋め込みの最適化について説明しています。パラメータ埋め込みの最適化では、クエリパラメータ参照が現在の実行からのリテラル定数値に置き換えられ、定数を含むコードが最適化されます。
図1の計画で、Index Seek演算子のseek述語と、Top演算子のtop式の両方が、現在のクエリ実行からの埋め込みリテラル定数値1と3を示していることを確認してください。それぞれ、パラメータ@custidと@nは表示されません。
iTVFでは、パラメータ埋め込みの最適化がデフォルトで使用されます。ストアドプロシージャでは、パラメータ化されたクエリがデフォルトで最適化されます。パラメータ埋め込みの最適化を要求するには、ストアドプロシージャのクエリにOPTION(RECOMPILE)を追加する必要があります。 iTVFとストアドプロシージャの最適化の詳細(影響を含む)については、後ほど説明します。
iTVFを介したデータの変更
シリーズのパート11から、特定の要件が満たされている限り、名前付きテーブル式が変更ステートメントのターゲットになる可能性があることを思い出してください。この機能は、ビューに適用されるのと同様にiTVFに適用されます。たとえば、顧客1の最新の3つの注文を削除するために使用できるコードは次のとおりです(実際にはこれを実行しないでください):
DELETE FROM Sales.GetTopCustOrders(1, 3);
特に私たちのデータベースでは、このコードを実行しようとすると、参照整合性が適用されるため失敗します(影響を受ける注文には、Sales.OrderDetailsテーブルに関連する注文行があります)が、有効でサポートされているコードです。
iTVFとストアドプロシージャ
前述のように、iTVFのデフォルトのクエリ最適化戦略は、ストアドプロシージャの戦略とは異なります。 iTVFの場合、デフォルトではパラメータ埋め込み最適化を使用します。ストアドプロシージャの場合、デフォルトでは、パラメータスニッフィングを適用しながらパラメータ化されたクエリを最適化します。ストアドプロシージャクエリのパラメータ埋め込みを取得するには、OPTION(RECOMPILE)を追加する必要があります。
多くの最適化戦略や手法と同様に、パラメーターの埋め込みには長所と短所があります。
主な利点は、クエリを簡素化できることです。これにより、より効率的な計画が作成される場合があります。それらの単純化のいくつかは本当に魅力的です。 Paulは、彼の記事のストアドプロシージャを使用してこれを示しています。これは、来月iTVFを使用して示します。
パラメータ埋め込みの最適化の主な欠点は、パラメータ化されたプランの場合のように、効率的なプランのキャッシュと再利用の動作が得られないことです。パラメータ値の個別の組み合わせごとに、個別のクエリ文字列を取得します。したがって、個別のコンパイルにより、個別のキャッシュプランが生成されます。一定の入力を持つiTVFを使用すると、同じパラメーター値が繰り返される場合にのみ、プランの再利用動作を取得できます。明らかに、OPTION(RECOMPILE)を使用したストアドプロシージャクエリは、同じパラメータ値を繰り返しても、リクエストによってプランを再利用しません。
3つのケースを示します:
- 定数を使用したiTVFクエリのデフォルトのパラメータ埋め込み最適化から得られた定数を使用した再利用可能なプラン
- パラメータ化されたストアドプロシージャクエリのデフォルトの最適化から生じる再利用可能なパラメータ化されたプラン
- OPTION(RECOMPILE)を使用したストアドプロシージャクエリのパラメータ埋め込み最適化の結果として生じる定数を含む再利用不可能なプラン
ケース1から始めましょう。
次のコードを使用して、@ custid=1および@n=3でiTVFをクエリします。
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
念のため、これは同じコードの2回目の実行になります。これは、以前に同じパラメーター値を使用して1回実行したため、図1に示す計画になります。
次のコードを使用して、@ custid=2および@n=3でiTVFを1回クエリします。
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(2, 3);
このコードをクエリ2と呼びます。クエリ2の計画を図2に示します。
 図2:クエリ2の計画
図2:クエリ2の計画
図1のクエリ1の計画は、シーク述語の一定の顧客ID 1を参照していましたが、この計画は一定の顧客ID2を参照していることを思い出してください。
次のコードを使用して、クエリ実行統計を調べます。
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders(%';
このコードは次の出力を生成します:
plan_handle execution_count text query_plan ------------------- --------------- ---------------------------------------------- ---------------- 0x06000B00FD9A1... 1 SELECT ... FROM Sales.GetTopCustOrders(2, 3); <ShowPlanXML...> 0x06000B00F5C34... 2 SELECT ... FROM Sales.GetTopCustOrders(1, 3); <ShowPlanXML...> (2 rows affected)
ここで作成される2つの別個のプランがあります。1つは2回使用された顧客ID1のクエリ用で、もう1つは1回使用された顧客ID2のクエリ用です。パラメータ値の非常に多くの個別の組み合わせを使用すると、多数のコンパイルとキャッシュされたプランが作成されます。
ケース2に進みましょう:パラメータ化されたストアドプロシージャクエリのデフォルトの最適化戦略。次のコードを使用して、Sales.GetTopCustOrders2というストアドプロシージャにクエリをカプセル化します。
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
次のコードを使用して、@ custid=1および@n=3でストアドプロシージャを2回実行します。
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
最初の実行によりクエリの最適化がトリガーされ、図3に示すパラメータ化された計画が作成されます。
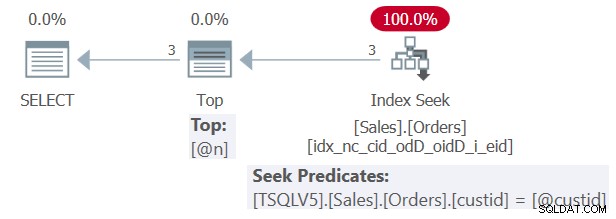 図3:Sales.GetTopCustOrders2procの計画
図3:Sales.GetTopCustOrders2procの計画
シーク述語のパラメーター@custidと、最上位の式のパラメーター@nへの参照を確認してください。
次のコードを使用して、@ custid=2および@n=3でストアドプロシージャを1回実行します。
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
図3に示すキャッシュされたパラメーター化されたプランは、再利用されます。
次のコードを使用して、クエリ実行統計を調べます。
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
このコードは次の出力を生成します:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 3 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
顧客ID値が変更されたにもかかわらず、パラメーター化されたプランが1つだけ作成およびキャッシュされ、3回使用されました。
ケース3に進みましょう。前述のように、ストアドプロシージャクエリでは、OPTION(RECOMPILE)を使用するときにパラメータ埋め込みの最適化が得られる場合があります。次のコードを使用して、このオプションを含めるようにプロシージャクエリを変更します。
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC OPTION(RECOMPILE); GO
@custid=1および@n=3でprocを2回実行します:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
定数が埋め込まれた、図1で前に示したのと同じ計画が得られます。
@custid=2および@n=3でprocを1回実行します:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
定数が埋め込まれた、図2で前に示したのと同じ計画が得られます。
クエリ実行統計を調べます:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
このコードは次の出力を生成します:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 1 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
実行回数は1で、最後の実行だけを反映しています。 SQL Serverは最後に実行されたプランをキャッシュするため、その実行の統計を表示できますが、要求によって、プランを再利用しません。 query_plan属性の下に表示されているプランを確認すると、図2で前述したように、前回の実行で定数に対して作成されたプランであることがわかります。
コンパイルが少なく、効率的なプランのキャッシュと再利用の動作が必要な場合は、パラメータ化されたクエリのデフォルトのストアドプロシージャ最適化アプローチが最適です。
iTVFベースの実装には、ストアドプロシージャベースの実装よりも大きな利点があります。テーブルの各行に関数を適用し、テーブルの列を入力として渡す必要がある場合です。たとえば、Sales.Customersテーブルの各顧客の最新の3つの注文を返す必要があるとします。テーブルの行ごとにストアドプロシージャを適用できるクエリ構造はありません。カーソルを使用して反復ソリューションを実装することもできますが、カーソルを回避できるのは常に良い日です。 APPLY演算子をiTVF呼び出しと組み合わせると、次のようにタスクを適切かつクリーンに実行できます。
SELECT C.custid, O.orderid, O.orderdate, O.empid FROM Sales.Customers AS C CROSS APPLY Sales.GetTopCustOrders( C.custid, 3 ) AS O;
このコードは、次の出力(省略形)を生成します:
custid orderid orderdate empid ----------- ----------- ---------- ----------- 1 11011 2019-04-09 3 1 10952 2019-03-16 1 1 10835 2019-01-15 1 2 10926 2019-03-04 4 2 10759 2018-11-28 3 2 10625 2018-08-08 3 ... (263 rows affected)
関数呼び出しはインライン化され、パラメーター@custidへの参照は相関C.custidに置き換えられます。これにより、図4に示す計画が作成されます。
 図4:APPLYとSales.GetTopCustOrdersiTVFを使用したクエリの計画
図4:APPLYとSales.GetTopCustOrdersiTVFを使用したクエリの計画
プランは、Sales.Customersテーブルのいくつかのインデックスをスキャンして、顧客IDのセットを取得し、顧客ごとのSales.Ordersで以前に作成したサポートインデックスにシークを適用します。関数が外部クエリにインライン化され、相関結合または横方向結合に変わってから、計画は1つだけです。このプランは、特にSales.Ordersの顧客の列が非常に密集している場合、つまり、個別の顧客IDが少数である場合に非常に効率的です。
もちろん、ROW_NUMBER関数でCTEを使用するなど、このタスクを実装する方法は他にもあります。このようなソリューションは、Sales.Ordersテーブルのcustid列の密度が低い場合、APPLYベースのソリューションよりもうまく機能する傾向があります。いずれにせよ、私の例で使用した特定のタスクは、議論の目的にとってそれほど重要ではありません。私のポイントは、SQLServerがさまざまなツールで採用しているさまざまな最適化戦略を説明することでした。
完了したら、次のコードを使用してクリーンアップします。
DROP INDEX IF EXISTS idx_nc_cid_odD_oidD_i_eid ON Sales.Orders;
概要と次のステップ
では、これから何を学びましたか?
iTVFは、再利用可能なパラメーター化された名前付きテーブル式です。
SQL Serverは、デフォルトでiTVFを使用したパラメーター埋め込み最適化戦略と、ストアドプロシージャクエリを使用したパラメーター化されたクエリ最適化戦略を使用します。ストアドプロシージャクエリにOPTION(RECOMPILE)を追加すると、パラメータ埋め込みが最適化される場合があります。
コンパイルを減らし、プランのキャッシュと再利用の動作を効率的にしたい場合は、パラメーター化されたプロシージャクエリプランが最適です。
iTVFクエリのプランはキャッシュされ、同じパラメータ値が繰り返される限り、再利用できます。
APPLY演算子とiTVFの使用を便利に組み合わせて、左側のテーブルの各行にiTVFを適用し、左側のテーブルの列をiTVFへの入力として渡すことができます。
前述のように、iTVFの最適化については多くのことをカバーする必要があります。今月は、デフォルトの最適化戦略の観点からiTVFとストアドプロシージャを比較し、キャッシュと再利用の動作を計画しました。来月は、パラメータ埋め込みの最適化による単純化についてさらに深く掘り下げます。