今日の世界では、ほとんどの人がMongoDBに切り替えていることがわかりますが、従来のリレーショナルデータベースを使用することを好む人はまだたくさんいます。ここでは、MongoDBを選択する理由について説明します。すべてのコインに2つの面があるように、それには独自の利点と制限があります。
では、MongoDBを学ぶ理由を探る準備はできていますか?
なぜMongoDBなのか
これはNoSQLデータベースであるため、MongoDBを学ぶ理由はたくさんあります。これらの理由により、MongoDBの世界的な人気が生まれました。
これらは、MongoDBが人気がある理由のいくつかです。
- 集約フレームワーク
- BSON形式
- シャーディング
- アドホッククエリ
- 上限付きコレクション
- インデックス作成
- ファイルストレージ
- レプリケーション
- MongoDB管理サービス(MMS)

MongoDBを学ぶ主な理由
i)集約フレームワーク
MongoDBで非常に効率的に使用できます。 MapReduce データのバッチ処理や集計操作にも使用できます。 MapReduceはプロセスに他なりません。このプロセスでは、大規模なデータセットがクラスター上の並列分散アルゴリズムを使用して結果を処理および生成します。
Map()とReduce()の2つの操作セットで構成されています。
- Map(): データをフィルタリングしてから、そのデータセットで並べ替えを実行するなどの操作を実行します。
- Reduce(): map()操作の後にすべてのデータを要約する操作を実行します。
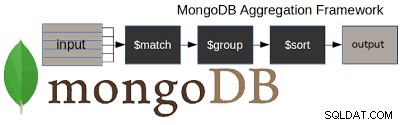
集約フレームワーク
ii)BSON形式
これは、JSONのようなストレージ形式です。 BSONはBinaryJSONの略です 。 BSONは、ドキュメントのようなJSONのバイナリエンコードされたシリアル化です。 MongoDBは、ドキュメントをコレクションに保存するときにこれを使用します。日付やバイナリなどのデータ型を追加できます(JSONはサポートしていません)。
BSON形式では、ここで主キーとして_idを使用します。前述のように、_idは主キーとして使用されているため、アプリケーションドライバーまたはMongoDBサービスによって生成されるObjectIdと呼ばれるそれ自体に関連付けられた一意の値を持っています。
以下は、BSON形式をより適切に理解するための例です。
例-
{
"_id": ObjectId("12e6789f4b01d67d71da3211"),
"title": "Key features Of MongoDB",
"comments": [
...
]
} BSON形式を使用するもう1つの利点は、ドキュメントのプロパティを内部的にインデックス付けしてマップできることです。サイズと速度がより効率的になるように設計されているため、MongoDBの読み取り/書き込みスループットが向上します。
iii。シャーディング
Web /モバイルアプリケーションの主な問題は、スケーリングです。この問題を克服するために、MongoDBはシャーディング機能を追加しました。これは、データが複数のマシンに分散される方法です。シャーディングにより、水平方向のスケーラビリティが提供されます。
これは複雑なプロセスであり、いくつかのシャードの助けを借りて行われます。各シャードはデータの一部を保持し、個別のデータベースとして機能します 。すべてのシャードをマージすると、単一の論理データベースが形成されます。ここでの操作はクエリルーターによって実行されています。
iv。アドホッククエリ
MongoDBは、範囲クエリ、正規表現、その他多くの種類の検索をサポートしています。クエリにはユーザー定義のJavascript関数が含まれ、ドキュメントから特定のフィールドを返すこともできます。 MongoDBは、独自のクエリ言語を使用するか、BSONドキュメントにインデックスを付けることで、アドホッククエリをサポートできます。
SQLSELECTクエリと類似クエリの違いを見てみましょう:
例えば。 ABCのような学生名で学生テーブルのすべてのレコードを取得します。
- SQLステートメント– SELECT * FROM Student WHERE stud_name LIKE‘%ABC%’;
- MongoDBクエリ– db.Students.find({stud_name:/ ABC /});
v。スキーマレス
スキーマのないデータベース(C ++で記述)であるため、従来のデータベースよりもはるかに柔軟性があります。このため、データ自体を設定するために多くのことを必要とせず、OOPとの摩擦が減少します。オブジェクトを保存する場合は、JSONにシリアル化して、MongoDBに送信します。
vi。上限付きコレクション
MongoDBは、コレクションのサイズが固定されているため、上限付きコレクションをサポートしています。 初期化。挿入順序を維持します。制限に達すると、循環キューのように動作し始めます。
例–上限のあるコレクションを2MBに制限する
- db.createCollection(’logs’、{capped:true、size:2097152})
viii。インデックス作成
検索のパフォーマンスを向上させるためにインデックスが作成されています 。 MongoDBドキュメントの任意のフィールドにプライマリまたはセカンダリのインデックスを付けることができます。
このため、データベースエンジンはクエリを効率的に解決できます。
インデックス作成
viii。ファイルストレージ
MongoDBは、ファイル保存システムとしても使用できます。これにより、負荷の不均衡やデータの複製が回避されます。この機能は、グリッドファイルシステムの助けを借りて実行されました 、ファイルを保存するドライバーに含まれています。

MongoDBのファイルストレージ
ix。レプリケーション
レプリケーションは、異なるマシンにデータを分散することによって提供されています。 1つのプライマリノードと複数のセカンダリノードを含めることができます(レプリカセット)。
このセットはマスタースレーブのように機能します。ここでは、マスターは読み取りと書き込みを実行でき、スレーブは読み取り操作のバックアップとしてマスターからデータをコピーします。
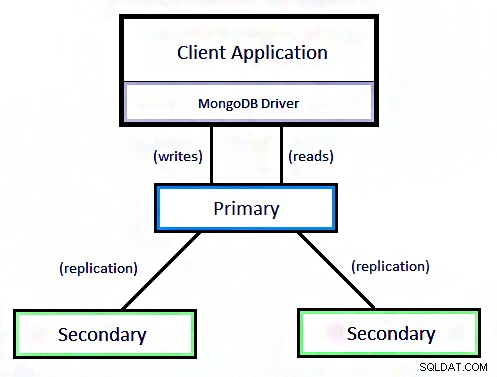
レプリケーション
x。 MongoDB管理サービス(MMS)
MongoDBにはMMSの非常に強力な機能があります。これにより、データベースまたはマシンを追跡し、必要に応じてデータをバックアップできます。また、展開を管理するためのハードウェアメトリックも追跡します。
カスタムアラートの機能を提供します。これにより、MongoDBインスタンスが影響を与える前に問題を発見できます。
MongoDB管理サービス(MMS)
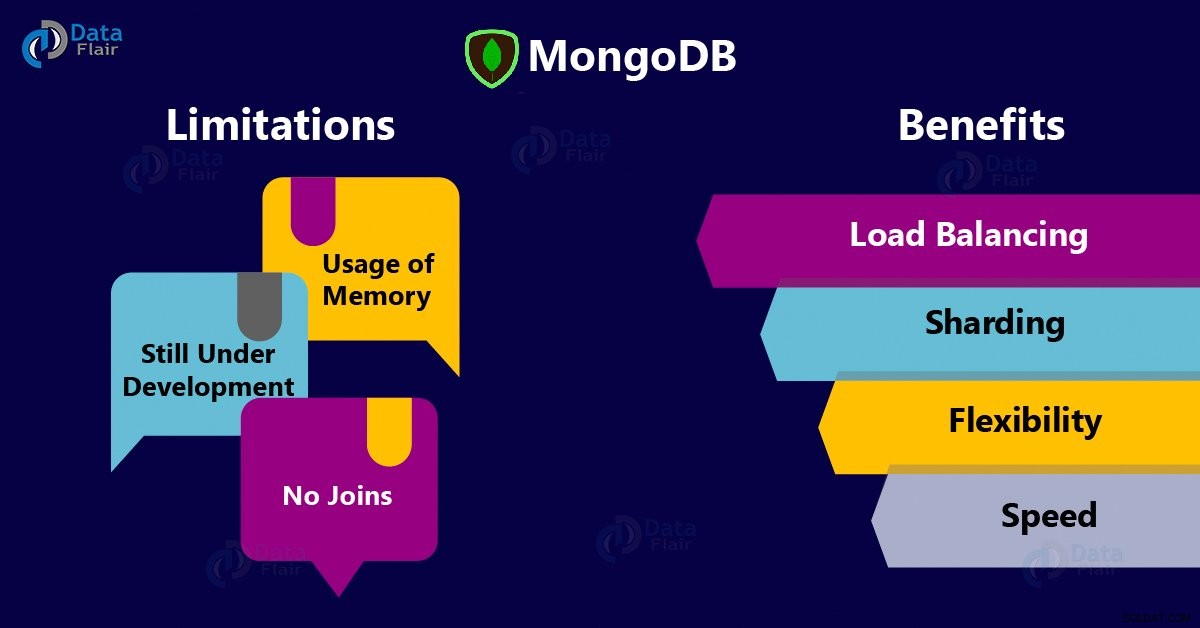
MongoDBのメリット
これは、なぜMongoDBの利点の第2フェーズです。
i。負荷分散
処理する必要のある大量のデータセットがある場合は、負荷分散を利用してトラフィックをさまざまなマシンに分散できます。
これは、ノード/マシンの1つが何らかの理由で動作を停止した場合でも、作業を続行できるようにユーザーを支援します。他のノードは作業を継続し、処理は停止しません。
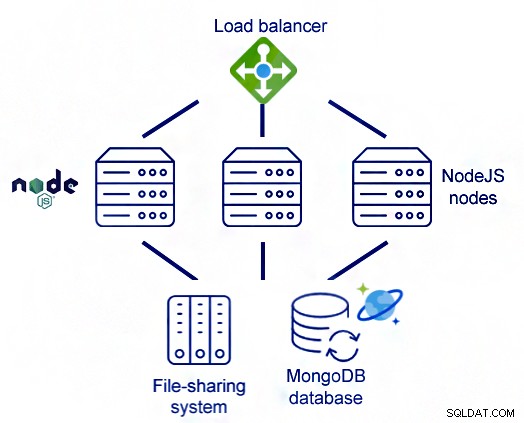
負荷分散
ii。シャーディング
シャーディングの助けを借りて、水平スケーリングを行うことができます。これは、リレーショナルデータベースの助けを借りては不可能です。この方法を使用することで、さまざまなマシンにデータを分散できます。
私たちは自分たちで持っているデータの断片を作り、それから処理タスクを少し簡単にするように努めています。
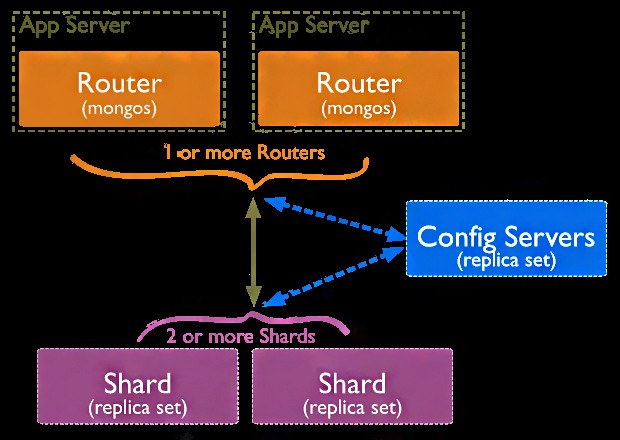
MongoDBでのシャーディング
iii。柔軟性
使用されているすべてのオブジェクト間で本質的に統合されているデータ構造は必要ありません。これにより、MongoDBが使いやすくなります。動的スキーマの助けを借りて、MongoDBを非常に簡単に使用できます。

柔軟性
iv。速度
MongoDBは、データをすばやく簡単に処理できます。ただし、これはデータがドキュメント形式になるまで有効です。数秒以内に大量の非構造化データを処理しているため、魔法のように感じられるため、速度は自動的に向上すると言えます。
MongoDBの長所と短所
MongoDBの欠点/制限
これは、MongoDBを選ぶ理由の第3フェーズです。 、制限。
i。メモリの使用
MongoDBはすべてのドキュメントと一緒にキー名を保存することがわかっているので、大量のメモリを消費することは明らかです。また、結合も不可能であるため、重複データを処理することは非常に困難になります。
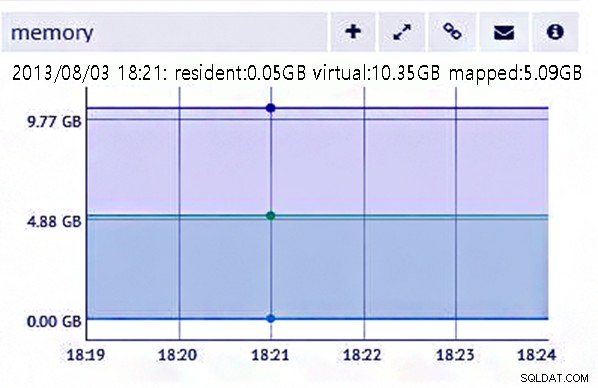
メモリの使用
ii。参加なし
リレーショナルデータベースでは非常に簡単に結合を適用できるため、MongoDBでは結合を適用できません。したがって、結合を適用する場合は、ここで結合操作を実行するために多くの複雑なクエリを作成する必要があります。
iii。まだ開発中
SQLが開発されました 1980年代、および MongoDB 2009年に登場したばかりです。そのため、MongoDBはまだ完全に文書化またはテストされておらず、その専門家からの完全なサポートはありません。
概要
それで、それを読んだ後、なぜそれを使うべきなのか、その長所と短所は何かという考えを得ることができます。また、質問がある場合は、下のコメントセクションでお気軽にお問い合わせください。