バックアップ-データベースを管理する際に注意すべき最も重要なことの1つ。データをバックアップする人とバックアップする人の2種類があると言われています。このブログ投稿では、バックアップに関するグッドプラクティスについて説明し、ClusterControlを使用して信頼性の高いバックアップシステムを構築する方法を示します。
ClusterControlがMySQL、MariaDB、MongoDB、PostgreSQLの集中バックアップ管理をどのように提供するかを見ていきます。大規模なデータセットのホットバックアップ、ポイントインタイムリカバリ、保存中および転送中のデータ暗号化、自動復元検証によるデータの整合性、ディザスタリカバリ用のクラウドバックアップ(AWS、Google、Azure)、コンプライアンスを確保するための保持ポリシーを提供します、および自動アラートとレポート。
バックアップの種類
ClusterControlで実行できるバックアップには主に2つのタイプがあります。
- 論理バックアップ-データのバックアップは、SQLなどの人間が読める形式で保存されます
- 物理バックアップ-バックアップにはバイナリデータが含まれています
どちらも互いに補完し合っています。論理バックアップを使用すると、(多かれ少なかれ簡単に)最大1行のデータを取得できます。物理バックアップはそれを達成するためにより多くの時間を必要としますが、一方で、ホスト全体を非常に迅速に復元することができます(論理バックアップを使用する場合は数時間または数日かかる場合があります)。
ClusterControlは、MySQL / MariaDB / Perconaサーバー、PostgreSQL、およびMongoDBのバックアップをサポートしています。
バックアップのスケジュール
ClusterControlでバックアップを開始するのは、ウィザードを使用すると簡単で効率的です。バックアップをスケジュールすると、暗号化、バックアップの自動テスト/検証、クラウドアーカイブなどの他の機能への使いやすさとアクセス性が提供されます。
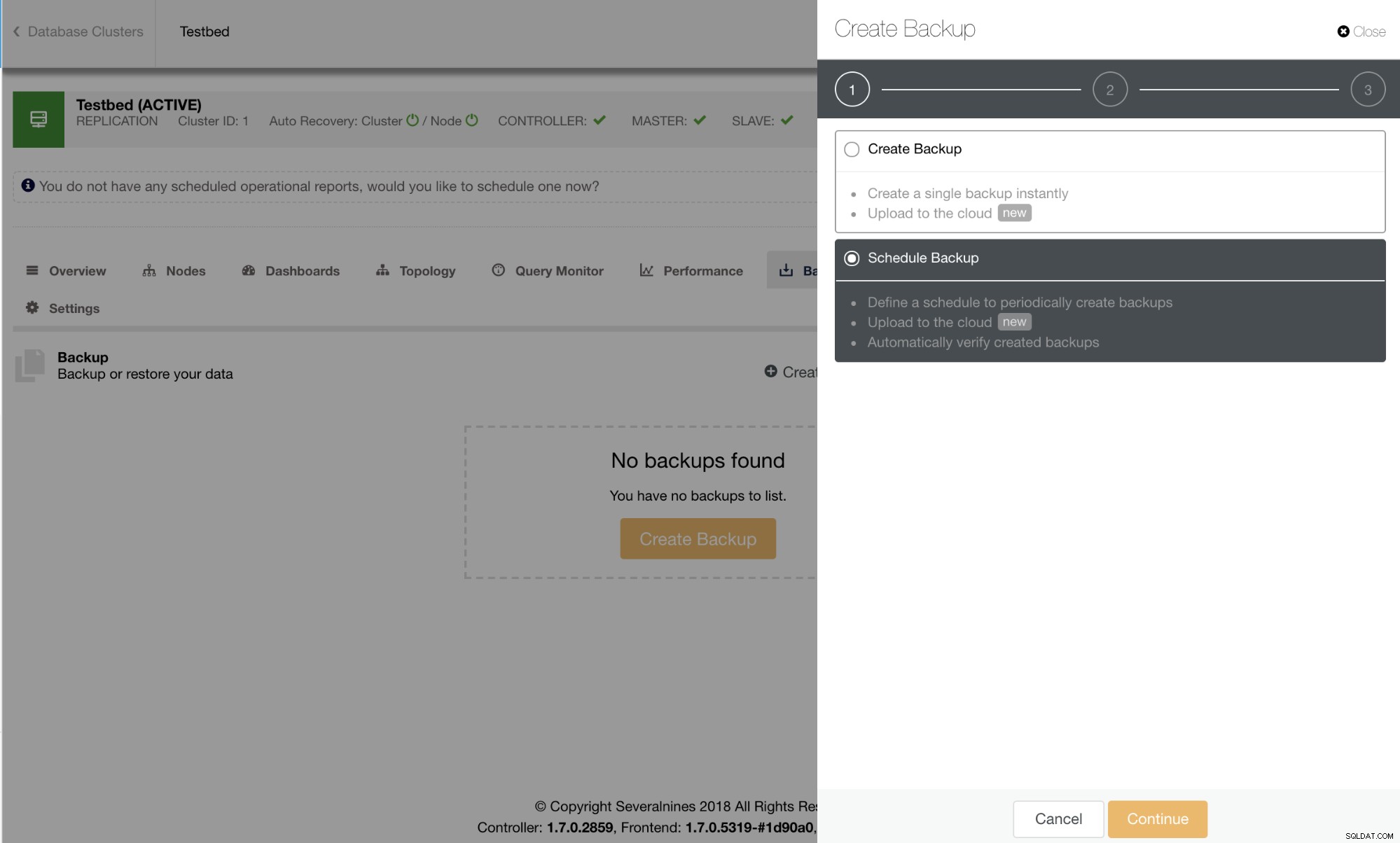
利用可能なスケジュールバックアップは、下の画像に示すように、[スケジュールバックアップ]タブに一覧表示されます。
バックアップをスケジュールするための良い習慣として、すでに定義済みのバックアップ保持が必要であり、毎日のバックアップをお勧めします。ただし、必要なデータ、予想されるトラフィック、および必要なときにいつでもデータを利用できるかどうかにも依存します。特に、データが誤って削除された場合やディスクが破損した場合は、避けられません。また、レポートの生成、サムネイル、キャッシュされたデータなど、データの損失が再現可能であるか、手動で複製できる場合もあります。質問は、災害が発生したときにどれだけすぐにそれらが必要になるかに依存しますが、可能であれば、論理的および物理的なバックアップの可用性を活用して、MySQLのmysqldumpとxtrabackupの両方のバックアップを毎日作成することをお勧めします。さらに多くのベースをカバーするために、1日に複数の増分エクストラバックアップ実行をスケジュールすることをお勧めします。これにより、完全バックアップを作成するよりも、ディスクスペース、ディスクI / O、さらにはCPU I/Oを節約できます。
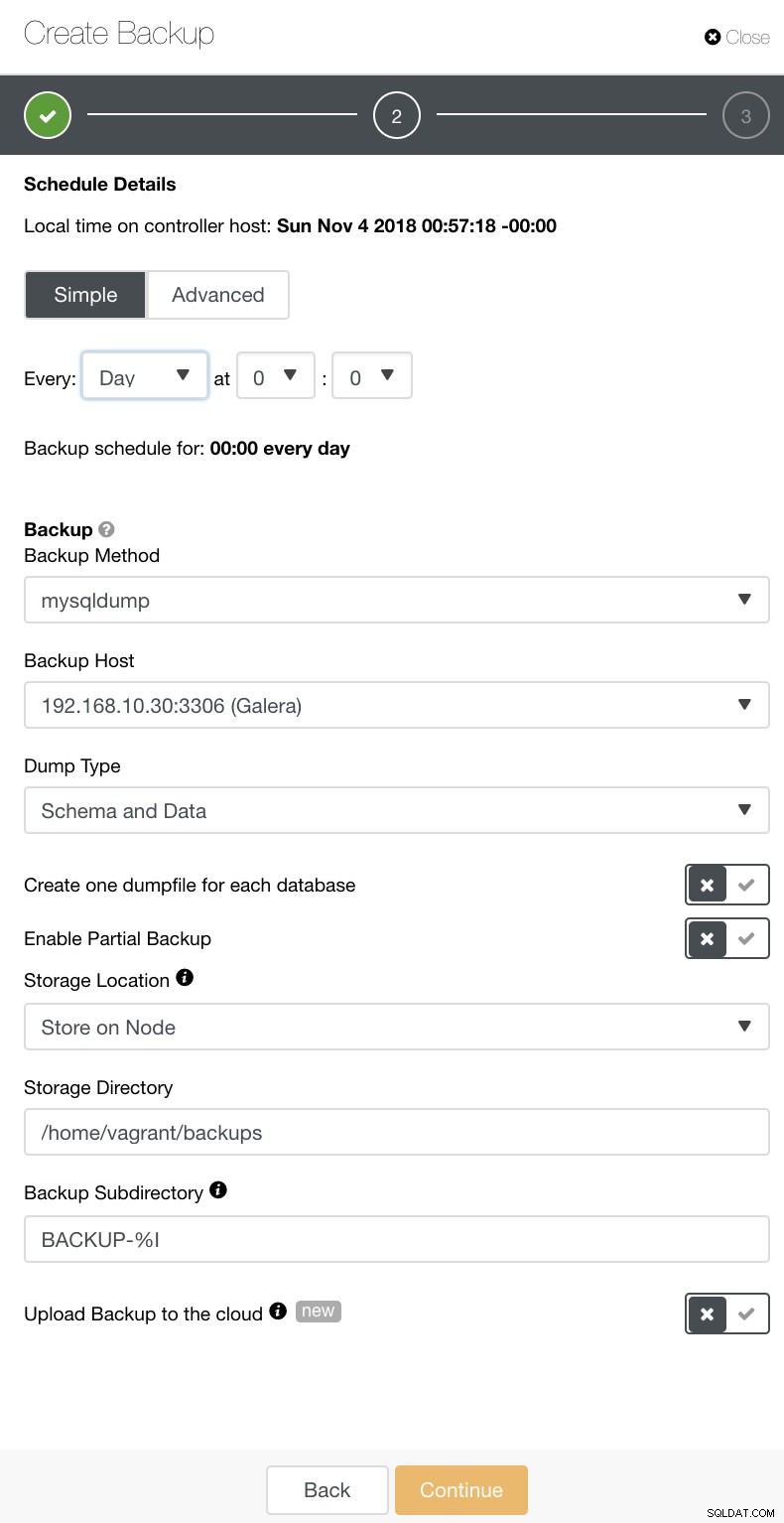
ClusterControlでは、これらのさまざまなタイプのバックアップを簡単にスケジュールできます。決定する設定がいくつかあります。バックアップは、コントローラーに保存することも、バックアップが作成されるデータベースノードにローカルに保存することもできます。バックアップを保存する場所と、バックアップするデータベース(すべてのデータセットまたは個別のスキーマ)を決定する必要があります。下の画像を参照してください:
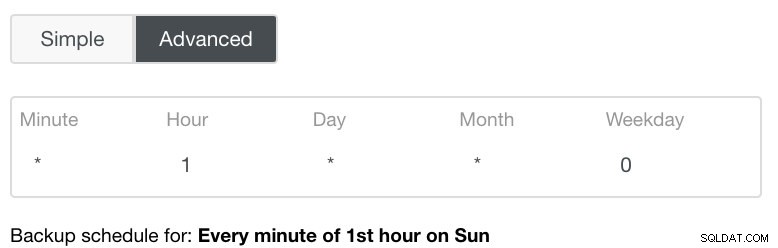
詳細設定では、cronのような構成を利用して、より細かく設定します。下の画像を参照してください:
障害が発生するたびに、ClusterControlはこれらの問題を効率的に処理し、バックアップ障害をさらに診断するためのログを生成します。
選択したバックアップの種類に応じて、構成する個別の設定があります。 XtrabackupおよびGaleraClusterの場合、実行時に物理バックアップを適用する設定を選択するオプションがある場合があります。以下を参照してください:
- 圧縮を使用する
- 圧縮レベル
- バックアップ中にノードの同期を解除します
- バックアップロック
- テーブルごとにDDLをロックする
- エクストラバックアップ並列コピースレッド
- ネットワークストリーミングスロットルレート(MB /秒)
- 並列gzipにPIGZを使用する
- 暗号化を有効にする
- 保持
下の画像では、それに応じてオプションにフラグを立てる方法を確認できます。また、バックアップポリシーに活用したいオプションの詳細情報を提供するツールチップアイコンがあります。
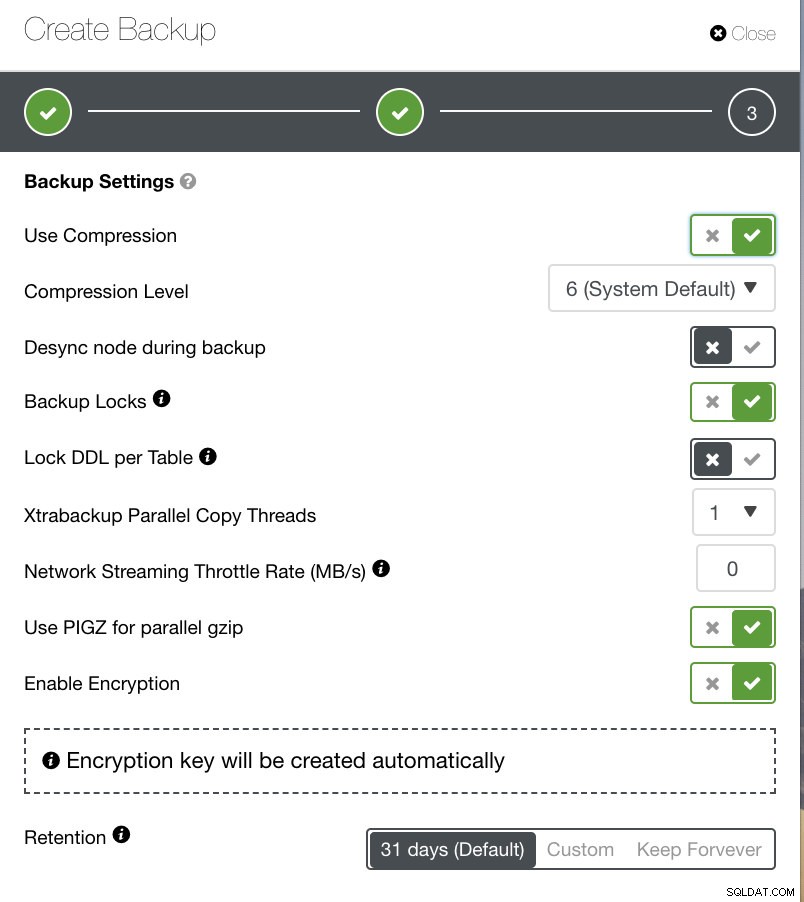
バックアップポリシーに応じて、ClusterControlは、最新の状態で利用可能なバックアップを取るためのベストプラクティスに従って調整できます。バックアップポリシーを定義する際には、ハードウェアからソフトウェア、クラウド、耐久性、高可用性、またはスケーラビリティに至るまで、必要なセットアップを利用できるようにする必要があります。
Galeraクラスターでバックアップを作成する場合は、バックアップの実行中にGaleraノードwsrep_desync=ONを設定することをお勧めします。これにより、ノードがフロー制御に参加できなくなり、特にバックアップするデータが大きい場合に、クラスター全体がレプリケーションの遅延から保護されます。 ClusterControlでは、これによりターゲットバックアップノードが負荷分散セットから削除される可能性があることに注意してください。これは、HAProxy、ProxySQL、またはMaxScaleプロキシを使用する場合に特に当てはまります。ノードが非同期化された場合に備えてアラートマネージャを設定している場合は、バックアップがトリガーされている間はオフにすることができます。
Galeraクラスターまたはレプリケーションマスターへのバックアップの影響を最小限に抑えるもう1つの一般的な方法は、レプリケーションスレーブを展開し、それをバックアップのソースとして使用することです。これにより、GaleraClusterはどの時点でもバックアップとして影響を受けません。スレーブはクラスターから切り離されています。
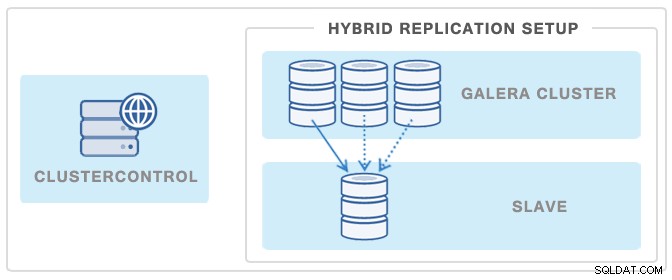
ClusterControlを使用すると、数回クリックするだけでこのようなスレーブをデプロイできます。下の画像を参照してください:
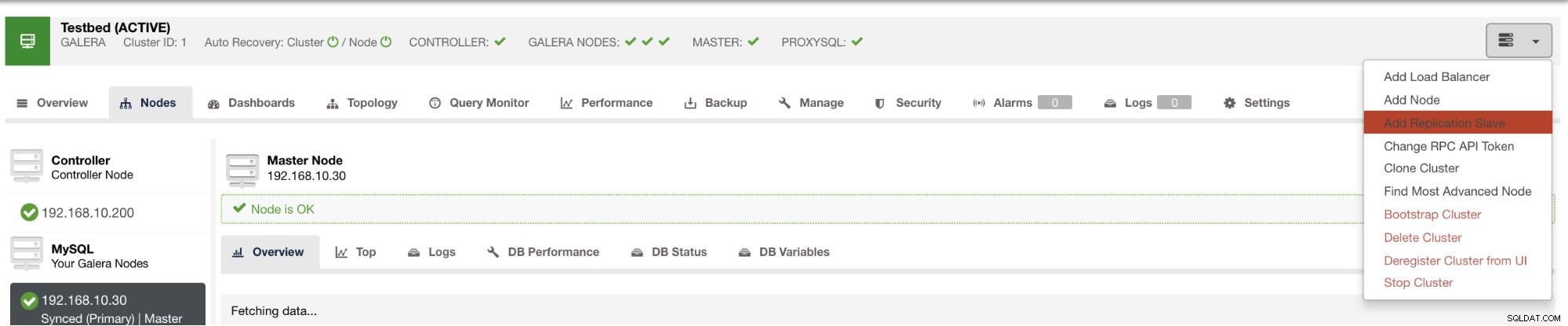
そのボタンをクリックすると、スレーブをセットアップするノードを選択できます。ノードのバイナリロギングが有効になっていることを確認してください。バイナリログの有効化は、ClusterControlを介して実行することもできます。これにより、目的のマスターを管理するための実現可能性が高まります。下の画像を参照してください:
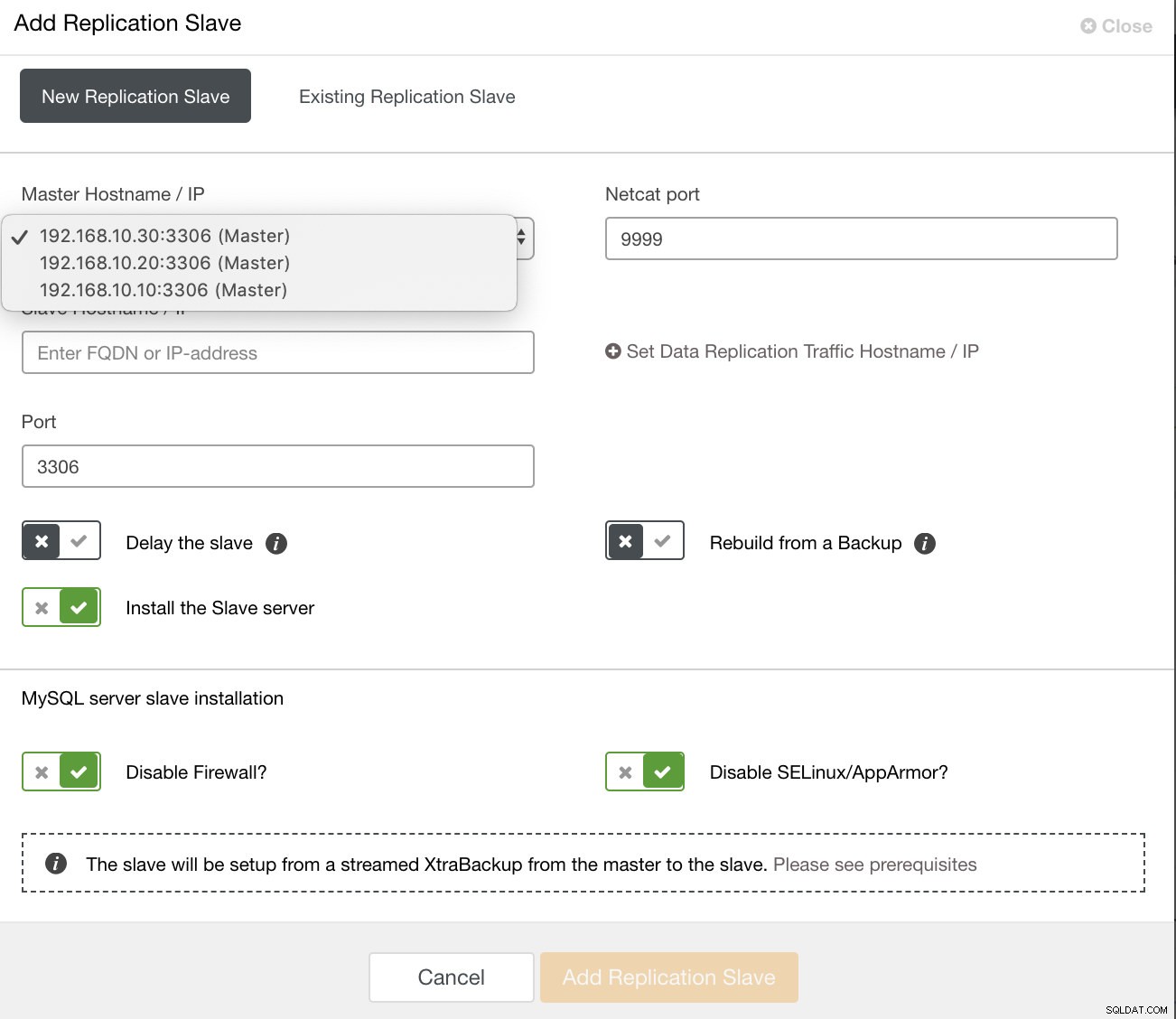
また、既存のレプリケーションスレーブをセットアップすることもできます
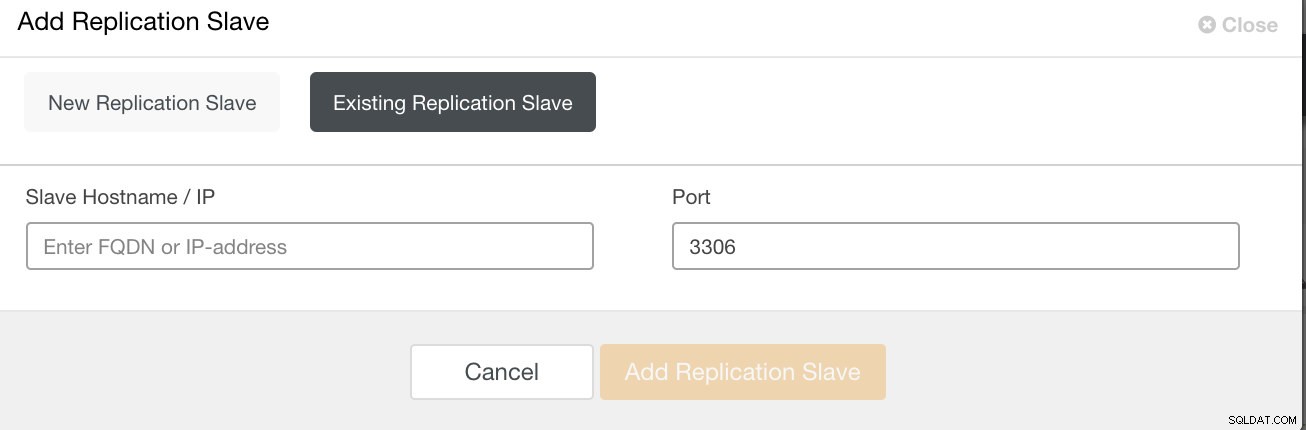
PostgreSQLの場合、論理バックアップまたは物理バックアップのいずれかをバックアップするオプションがあります。 ClusterControlでは、pg_dumpまたはpg_basebackupを選択することにより、PostgreSQLバックアップを活用できます。 pg_basebackupは、9.3より古いバージョンでは機能しません。
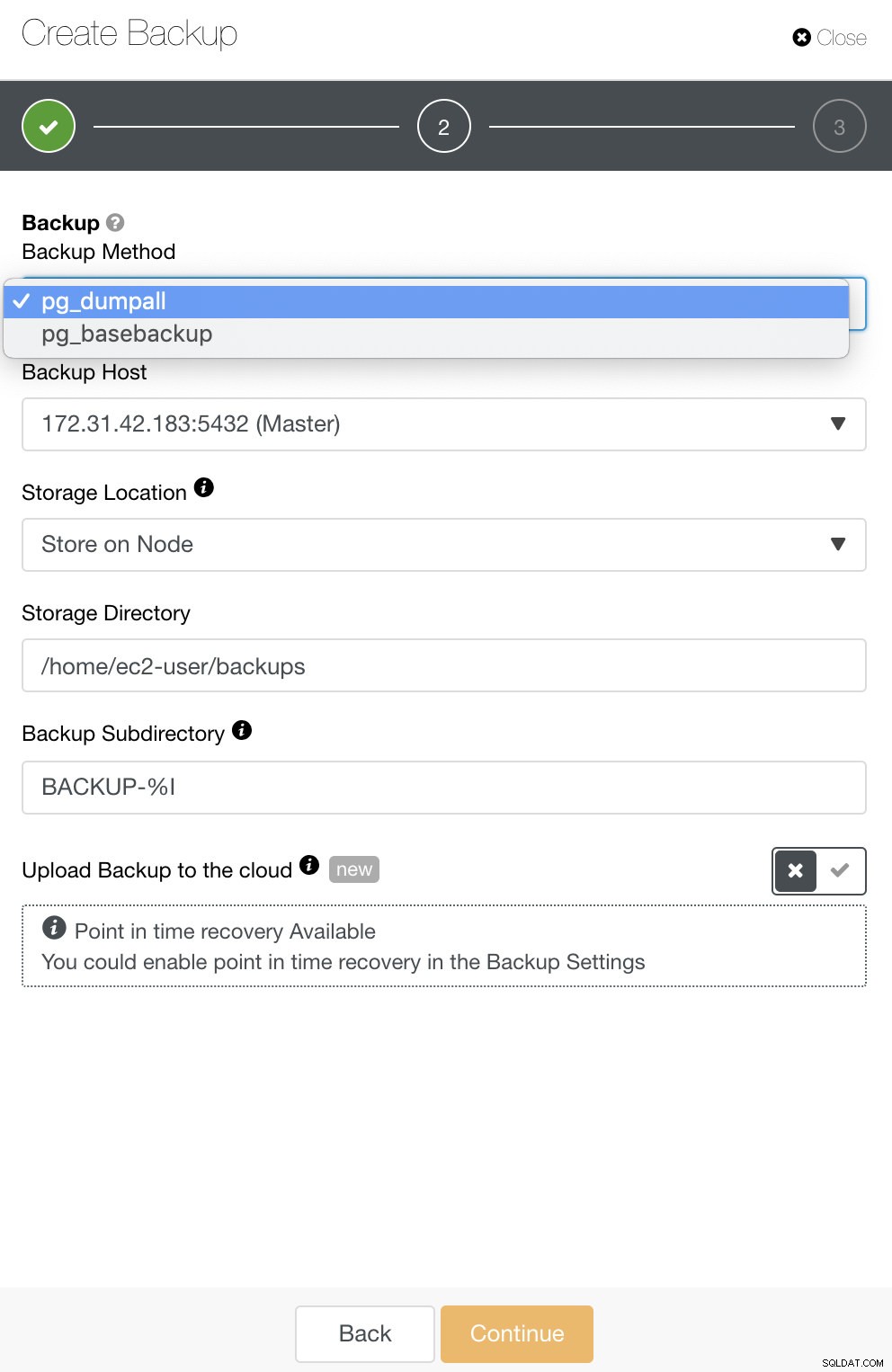
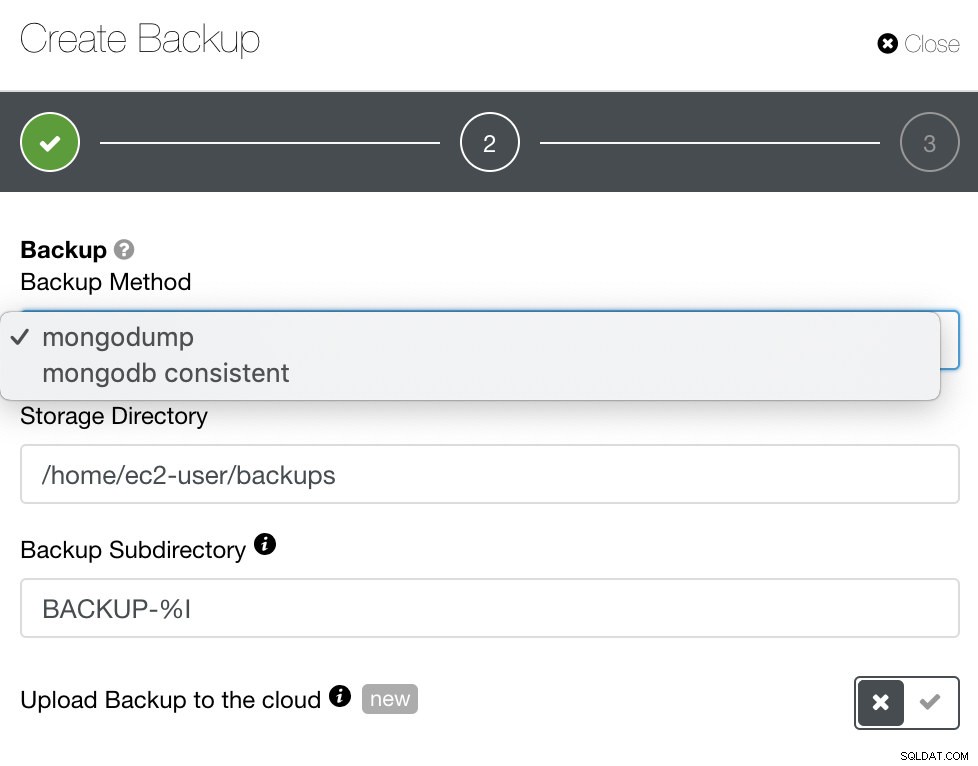
MongoDBの場合、ClusterControlはmongodumpまたはmongodb整合性を提供します。 mongodbconsistentはRHEL7をサポートしていないことに注意する必要があるかもしれませんが、手動でインストールできる可能性があります。
デフォルトでは、ClusterControlは、実行されたすべてのバックアップ、成功したバックアップ、または失敗したバックアップのレポートを一覧表示します。以下を参照してください:
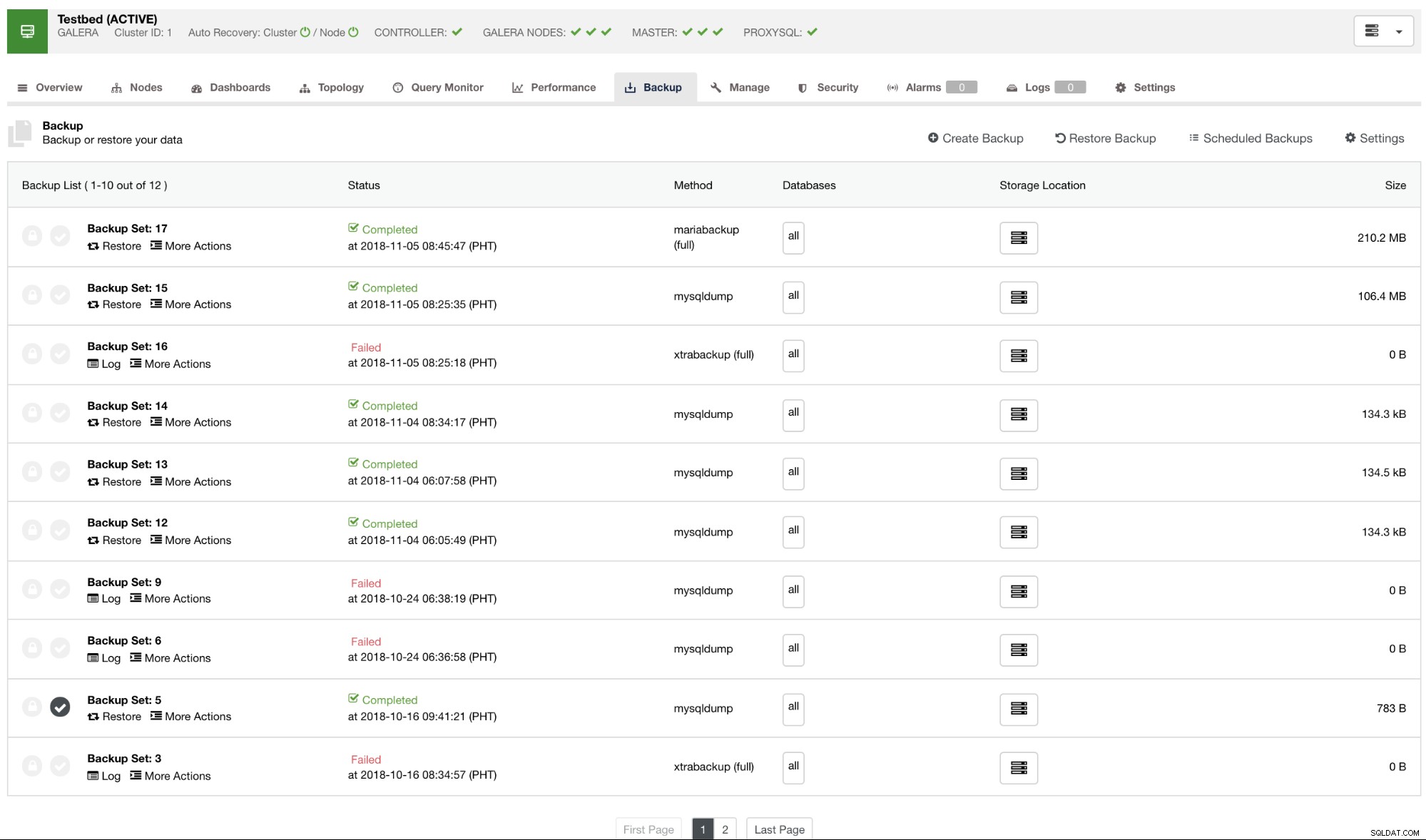
ClusterControlを使用して作成またはスケジュールされたバックアップレポートのリストを確認できます。リスト内で、ログを表示してさらに調査および診断することができます。たとえば、バックアップが目的のバックアップポリシーに従って正しく終了した場合、圧縮と暗号化が正しく設定されているかどうか、または目的のバックアップデータサイズが正しいかどうかなどです。これは、迅速な健全性チェックを行うための良い方法です。データセットのサイズが約1 GBの場合、完全バックアップを100 KBまで小さくすることはできません。ある時点で、問題が発生した可能性があります。
災害復旧
データをすばやく復元する場合は、クラスター内(データベースノードまたはClusterControlホストに直接)にバックアップを保存すると便利です。すべてのバックアップファイルが配置されており、解凍してすぐに復元できます。ディザスタリカバリ(DR)に関しては、これは最善のオプションではない場合があります。さまざまな問題が発生する可能性があります。サーバーがクラッシュしたり、ネットワークが確実に機能しなかったり、何らかの停止のためにデータセンター全体にアクセスできなくなったりする可能性があります。単一のデータセンターを持つ小規模なサービスプロバイダーと連携している場合でも、アマゾンウェブサービスのようなグローバルベンダーと連携している場合でも発生する可能性があります。したがって、すべての卵を1つのバスケットに保管することは安全ではありません。バックアップのコピーを、外部の場所に保存しておく必要があります。 ClusterControlは、Amazon S3、Google Storage、AzureCloudStorageをサポートしています。
独自のDRポリシーを実装したい場合は、ClusterControlバックアップが適切に構造化されたディレクトリに保存されます。バックアップをクラウドにアップロードするオプションもあります。下の画像を参照してください:
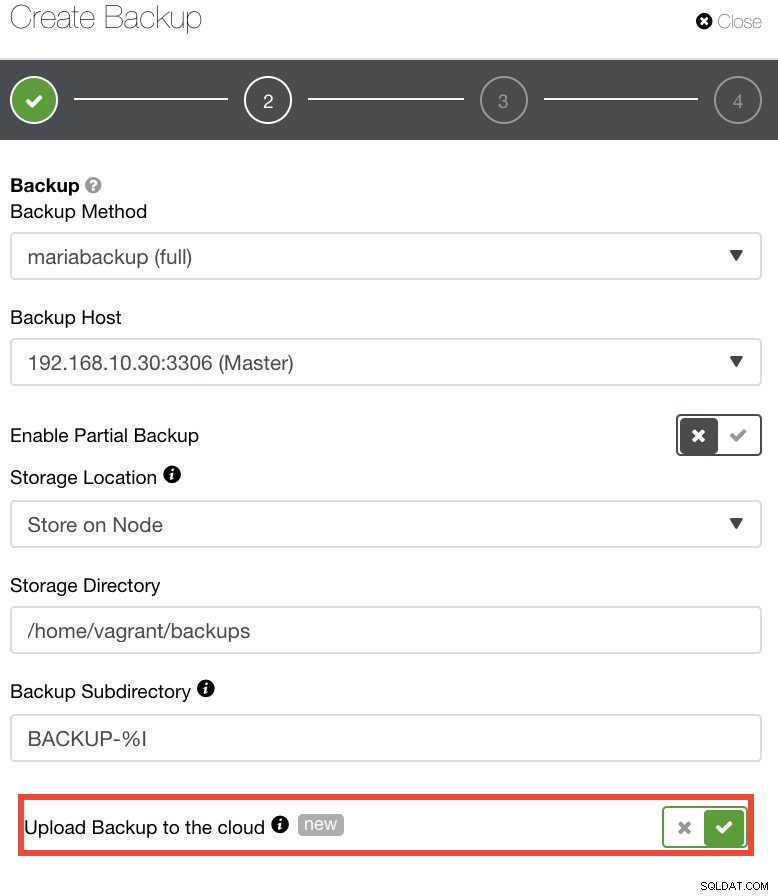
アマゾンウェブサービス、Google Cloud、MicrosoftAzureを選択してアップロードできます。下の画像を参照してください:
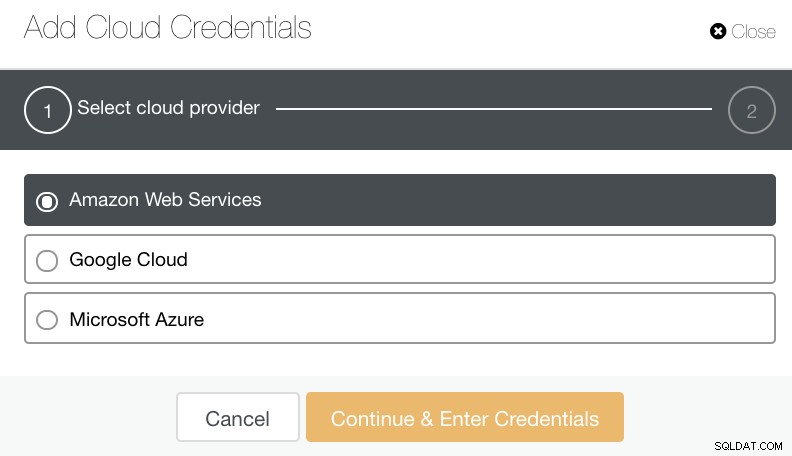
データベースバックアップをアーカイブする際の良い習慣として、ターゲットクラウドの宛先がデータベースサーバーと同じリージョン、または少なくとも最も近いリージョンに基づいていることを確認してください。高可用性、耐久性、およびスケーラビリティを提供することを確認してください。データが必要になる頻度と即時性を考慮する必要があるためです。
DRの論理バックアップまたは物理バックアップを作成するだけでなく、特定のノードでデータの完全なスナップショットを作成すると(たとえば、LVMスナップショット、Amazon EBSスナップショット、またはVeritasファイルシステムを使用している場合はボリュームスナップショットを使用)、バックアップのリカバリを向上させることができます。 Point In Time Recovery(PITR)にWAL(Postgres用)を使用したり、PITRにMySQLバイナリログを使用したりすることもできます。したがって、PITR用に独自のアーカイブを作成する必要があるかもしれないことを考慮する必要があります。したがって、独自のスクリプトセットを作成して展開し、正確な要件に従ってDRを処理することはまったく問題ありません。
ディザスタリカバリポリシーを実装するもう1つの優れた方法は、非同期レプリケーションスレーブを使用することです。これは、このブログ投稿で前述したものです。このような非同期スレーブをリモートの場所(他のデータセンターなど)に展開し、それを使用してバックアップを実行し、そのスレーブにローカルに保存することができます。もちろん、クラスターを回復する必要がある場合は、クラスターのローカルバックアップを作成して、ローカルに保存することをお勧めします。データセンター間でのデータの移動には時間がかかる場合があるため、バックアップファイルをローカルで利用できるようにしておくと、時間を節約できます。メインの本番クラスターにアクセスできなくなった場合でも、スレーブにアクセスできる可能性があります。この設定は非常に柔軟です。まず、本番データを使用して実行中のMySQLホストがあるため、DRサイトに完全なアプリケーションをデプロイするのはそれほど難しくありません。また、DR環境をスケールアウトするために使用できる本番データのバックアップもあります。
最後に、そして最も重要なこととして、テストされていないバックアップは未確認のバックアップ、別名シュレーディンガーバックアップのままです。バックアップが機能していることを確認するには、リカバリテストを実行する必要があります。 ClusterControlは、バックアップを自動的に検証およびテストする方法を提供します。
これにより、オープンソースデータベースの安全で信頼性の高いバックアップ手順を構築するための十分な情報が得られることを願っています。