生産停止は、ある時点で発生することがほぼ保証されています。この事実を受け入れ、データベース停止のタイムラインと障害シナリオを分析すると、次のシナリオからの準備、診断、および回復を改善するのに役立ちます。ダウンタイムの影響を軽減するために、組織には適切なディザスタリカバリ(DR)計画が必要です。 DR計画は、多くのSysOps / DevOpsにとって重要なタスクですが、それは予見されていますが、多くの場合、存在しません。
このブログ投稿では、MongoDBデータベースシステムのさまざまなバックアップと障害のシナリオを分析します。また、それぞれのシナリオのリカバリとフェイルオーバーの手順についても説明します。これらのユースケースは、単一ノードの復元、既存のreplicaSetでのノードの復元、replicaSetでの新しいノードのシードとは異なります。これにより、直面する可能性のあるリスクと、インフラストラクチャを設計する際に考慮すべきことを十分に理解できるようになることを願っています。
考えられる障害シナリオについて説明する前に、MongoDBがデータを保存する方法と、使用可能なバックアップの種類を見てみましょう。
MongoDBはドキュメント指向のデータベースです。 (リレーショナルデータベースのように)個々の行で作成されたテーブルにデータを格納する代わりに、個々のドキュメントで作成されたコレクションにデータを格納します。 MongoDBでは、ドキュメントは特定の形式やスキーマを持たない大きなJSONブロブです。さらに、データを共有してさまざまなクラスターノードに分散したり、replicaSetを使用してスレーブサーバーに複製したりできます。
MongoDBでは、デフォルトで非常に高速な書き込みと更新が可能です。トレードオフは、多くの場合、障害が明示的に通知されないことです。デフォルトでは、ほとんどのドライバーは非同期の安全でない書き込みを行います。これは、MySQLでのINSERT DELAYEDのように、ドライバーがエラーを直接返さないことを意味します。何かが成功したかどうかを知りたい場合は、getLastErrorを使用して手動でエラーをチェックする必要があります。
最適なパフォーマンスを得るには、ストレージにHDDではなくSSDを使用することをお勧めします。ストレージがローカルかリモートかを管理し、それに応じて対策を講じる必要があります。ハードウェアの欠陥と回復スキームの保護にはRAIDを使用することをお勧めしますが、有害な障害に対する保護を提供しないため、RAIDに完全に依存しないでください。適切なハードウェアは、パフォーマンスを最適化し、大きな障害を回避するためのアプリケーションの構成要素です。
ディスクレベルのデータ破損またはデータファイルの欠落により、mongodインスタンスの起動が妨げられる可能性があり、ジャーナルファイルが自動的に回復するには不十分な場合があります。
ジャーナリングを有効にして実行している場合、サーバーはジャーナルファイルを使用してデータファイルを自動的にクリーンな状態に復元できるため、修復を実行する必要はほとんどありません。ただし、ディスクレベルのデータ破損から回復する必要がある場合は、修復を実行する必要がある場合があります。
ジャーナリングが有効になっていない場合、唯一のオプションは修復コマンドを実行することです。 mongod --repairは、修復プロセス中に操作によって破損したデータが削除される(保存されない)ため、他にオプションがない場合にのみ使用する必要があります。このタイプの操作の前には、常にバックアップを実行する必要があります。
MongoDBディザスタリカバリシナリオ
障害復旧計画では、目標復旧時点(RPO)は、失う余裕のあるデータの量を決定する主要な復旧パラメーターです。 RPOは、ミリ秒から数日までの時間で一覧表示され、バックアップシステムに直接依存します。通常の操作を再開するために回復する必要があるバックアップデータの経過時間を考慮します。
RPOを見積もるには、いくつか質問する必要があります。データはいつバックアップされますか?データの取得に関連するSLAとは何ですか?データのバックアップを復元することは許容されますか、それともデータがオンラインであり、いつでもクエリを実行できるようにする必要がありますか?
これらの質問への回答は、必要なバックアップソリューションの種類を促進するのに役立ちます。
MongoDBバックアップソリューション
バックアップ手法は、実行中のデータベースのパフォーマンスにさまざまな影響を及ぼします。一部のバックアップソリューションは、データベースのパフォーマンスを十分に低下させるため、ピーク使用量またはメンテナンスウィンドウを回避するためにバックアップをスケジュールする必要がある場合があります。バックアップをサポートするためだけに、新しいセカンダリサーバーを導入することもできます。
MongoDBサーバー/クラスターをバックアップするための最も一般的な3つのソリューションは...
- Mongodump/Mongorestore-論理バックアップ。
- Mongo Management System(Cloud)-本番データベースは、MongoDB Ops Managerを使用してバックアップできます。また、MongoDB Atlasサービスを使用している場合は、フルマネージドバックアップソリューションを使用できます。
- データベーススナップショット(ディスクレベルのバックアップ)
Mongodump / Mongorestore
mongodumpを実行すると、指定されたデータベース内のすべてのコレクションがBSON出力としてダンプされます。データベースが指定されていない場合、MongoDBは、内部使用のために予約されているため、管理データベース、テストデータベース、およびローカルデータベースを除くすべてのデータベースをダンプします。
デフォルトでは、mongodumpはdumpというディレクトリを作成します。各データベースのディレクトリには、そのデータベースのコレクションごとにBSONファイルが含まれます。または、バックアップを1つのアーカイブファイルに保存するようにmongodumpに指示することもできます。アーカイブパラメータは、すべてのデータベースとコレクションからの出力をバイナリデータの単一のストリームに連結します。さらに、gzipパラメーターはgzipを使用してこのアーカイブを自然に圧縮できます。 ClusterControlでは、すべてのバックアップをストリーミングするため、アーカイブとgzipの両方のパラメーターを有効にします。
MySQLを使用したmysqldumpと同様に、MongoDBでバックアップを作成すると、コンテンツをバックアップファイルにダンプしている間、コレクションがフリーズします。 MongoDBはトランザクション(4.2で変更)をサポートしていないため、oplogパラメーターを使用してバックアップを作成しない限り、100%完全に整合性のあるバックアップを作成することはできません。バックアップでこれを有効にすると、バックアップの作成中に実行されていたoplogからのトランザクションが含まれます。
自動化を改善するには、コマンドラインからMongoDBを実行するか、ClusterControlなどの外部ツールを使用できます。 ClusterControlは、さまざまなオープンソースデータベースシステムの高度なバックアップ戦略を作成できるため、バックアップ管理とバックアップ自動化に推奨されるオプションです。
ClusterControlを使用すると、バックアップをクラウドにアップロードできます。フルバックアップをサポートし、mongodumpの暗号化を復元します。それがどのように機能するかを知りたい場合は、当社のWebサイトにデモがあります。
BSON形式のダンプを使用する方法は基本的に2つあります。
- バックアップディレクトリから直接mongodを実行します
- mongorestoreを実行し、バックアップを復元します
バックアップから直接mongodを実行するための前提条件は、バックアップターゲットが標準ダンプであり、gzip圧縮されていないことです。
MongoDBデーモンは、データディレクトリの整合性をチェックし、管理データベース、ジャーナル、コレクションとインデックスのカタログ、およびMongoDBの実行に必要なその他のファイルを追加します。以前にWiredTigerをストレージエンジンとして実行したことがある場合は、既存のコレクションをMMAPとして実行するようになります。単純なデータダンプまたは整合性チェックの場合、これは正常に機能します。
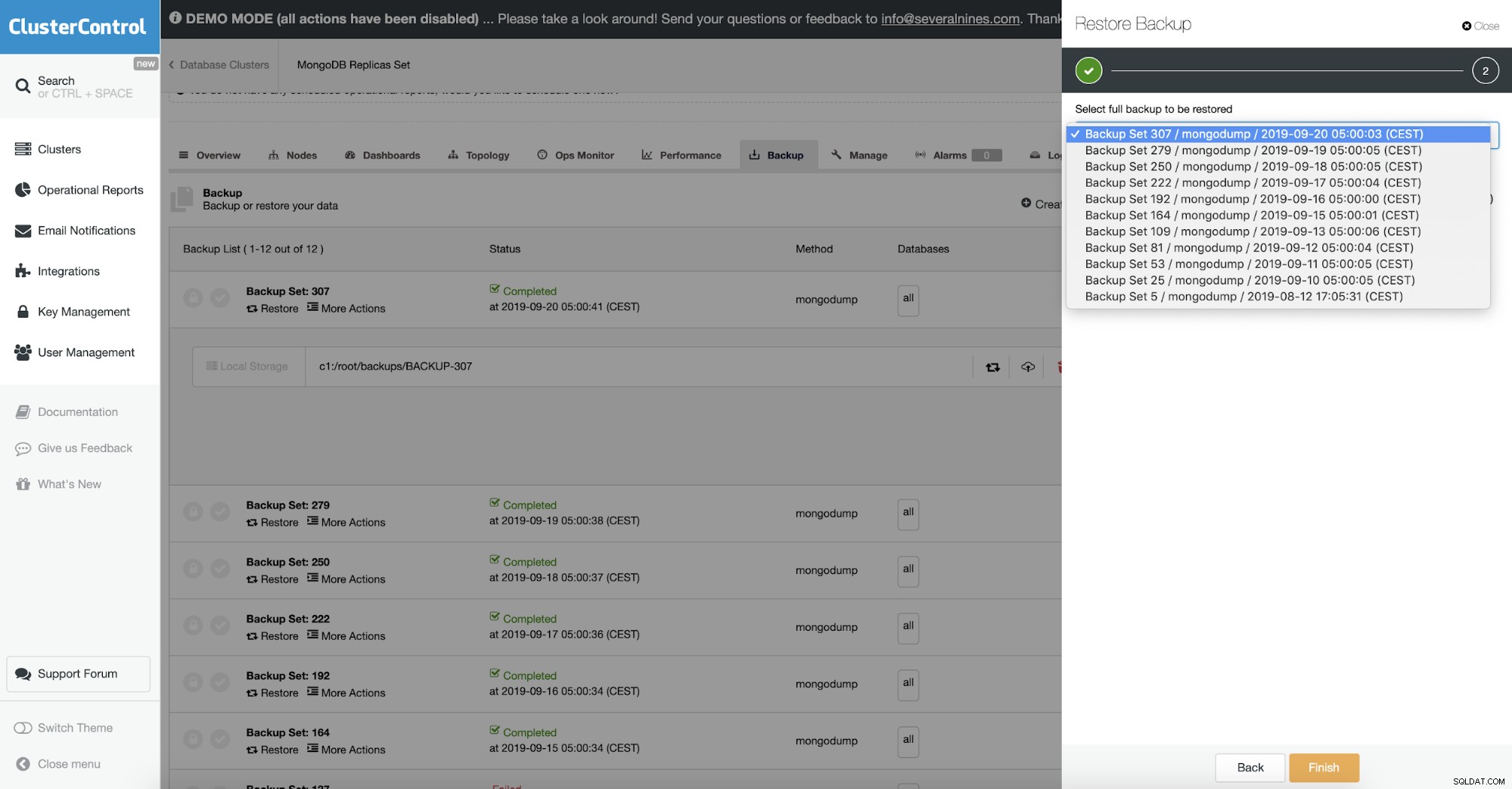
mongorestoreの実行
復元するためのより良い方法は、明らかに、mongorestoreを使用してノードを復元することです。
mongorestore dump/これにより、バックアップがデフォルトのサーバー設定(localhost、ポート27017)に復元され、このサーバーに存在するバックアップ内のデータベースが上書きされます。これで、復元プロセスを操作するためのパラメータがたくさんあります。重要なパラメータのいくつかを取り上げます。
ClusterControlでは、これはバックアップの復元オプションで行われます。バックアップを復元するマシンを選択し、残りを処理して処理することができます。これには、通常はバックアップを復号化する必要がある暗号化されたバックアップが含まれます。
バックアップにはBSONデータが含まれているため、バックアップの内容が正しいことが期待されます。しかし、そもそも、ダンプされたドキュメントの形式が正しくなかった可能性があります。 Mongodumpは、ダンプするデータの整合性をチェックしません。
これに対処するには、--objcheckを使用します。これにより、mongorestoreは、受信時にクライアントからのすべての要求を検証して、クライアントがデータベースに無効なドキュメントを挿入しないようにします。パフォーマンスにわずかな影響を与える可能性があります。
Oplog Replay
バックアップへのOplogを使用すると、一貫性のあるバックアップを実行し、ポイントインタイムリカバリを実行できます。 oplogReplayパラメーターを有効にして、復元プロセス中にoplogを適用します。 oplogを再生する距離を制御するには、oplogLimitパラメーターでタイムスタンプを定義できます。その後、タイムスタンプまでのトランザクションのみが適用されます。
ReplicaSetの復元は、単一ノードの復元と大差ありません。最初にreplicaSetを設定してから、replicaSetに直接復元する必要があります。または、最初に単一のノードを復元してから、この復元されたノードを使用してreplicaSetを構築します。
最初にノードを復元してから、replicaSetを作成します
これで、2番目と3番目のノードが最初のノードからのデータを同期します。同期が完了すると、replicaSetが復元されました。
最初にReplicaSetを作成してから、復元します
前のプロセスとは異なり、最初にreplicaSetを作成できます。まず、replicaSetを有効にして3つのホストすべてを構成し、3つのデーモンすべてを起動して、最初のノードでreplicaSetを開始します。
ReplicaSetを作成したので、バックアップを直接復元できます。
私たちの意見では、この方法でreplicaSetを復元する方がはるかにエレガントです。これは、通常、新しいreplicaSetを最初から設定してから、(本番)データで埋める方法に近いものです。
MongoDBに新しいノードを追加してクラスターをスケールアウトする場合、データセットの初期同期が行われる必要があります。 MySQLレプリケーションとGaleraを使用すると、バックアップを使用して初期同期をシードすることに慣れています。 MongoDBを使用すると、これが可能になりますが、データディレクトリのバイナリコピーを作成する必要があります。ファイルシステムのスナップショットを作成する手段がない場合は、既存のノードの1つでダウンタイムに直面する必要があります。ダウンタイムを伴うプロセスを以下に説明します。
では、代わりにmongodumpバックアップから新しいノードを復元し、それをreplicaSetに参加させるとどうなるでしょうか。バックアップからの復元は、理論的には同じデータセットを提供するはずです。この新しいノードはバックアップから復元されているため、replicaSetIdがなく、MongoDBが認識します。 MongoDBはこのノードをreplicaSetの一部として認識しないため、rs.add()コマンドは常にMongoDBの初期同期をトリガーします。初期同期では、常にMongoDBノード上の既存のデータの削除がトリガーされます。
ReplicaSetIdは、replicaSetの開始時に生成されますが、残念ながら手動で設定することはできません。バックアップからのリカバリ(oplogの再生を含む)では、理論的には100%同一のデータセットが得られるため、これは残念です。このユースケースを満たすために、MongoDBで初期同期がオプションであると便利です。