このHadoopチュートリアルでは 、MapReduce KeyValuePairの完全な紹介を提供します。
まず最初に、Hadoopでのキーと値のペアとは何か、MapReduceでキーと値のペアがどのように生成されるかについて説明します。最後に、MapReduceのキーと値のペアの生成について例を挙げて説明します。
Hadoopのキーバリューペアとは何ですか?
MapReduceのキーと値のペアは、HadoopMapReduceが実行のために受け入れるレコードエンティティです。
Hadoopは主にデータ分析に使用します。構造化データ、非構造化データ、半構造化データを扱います。 Hadoopを使用すると、スキーマが静的である場合、キー値の代わりに列を直接操作できます。ただし、スキーマが静的でない場合は、キー値を処理します。
キー値は、データの固有のプロパティではありません。ただし、データを分析するユーザーによって選択されます。
MapReduceは、データ処理を提供するHadoopのコアコンポーネントです。ジョブを次の2つのフェーズに分割して処理を実行します。マップフェーズ およびフェーズの削減 。各フェーズには、入力および出力としてキー値があります。
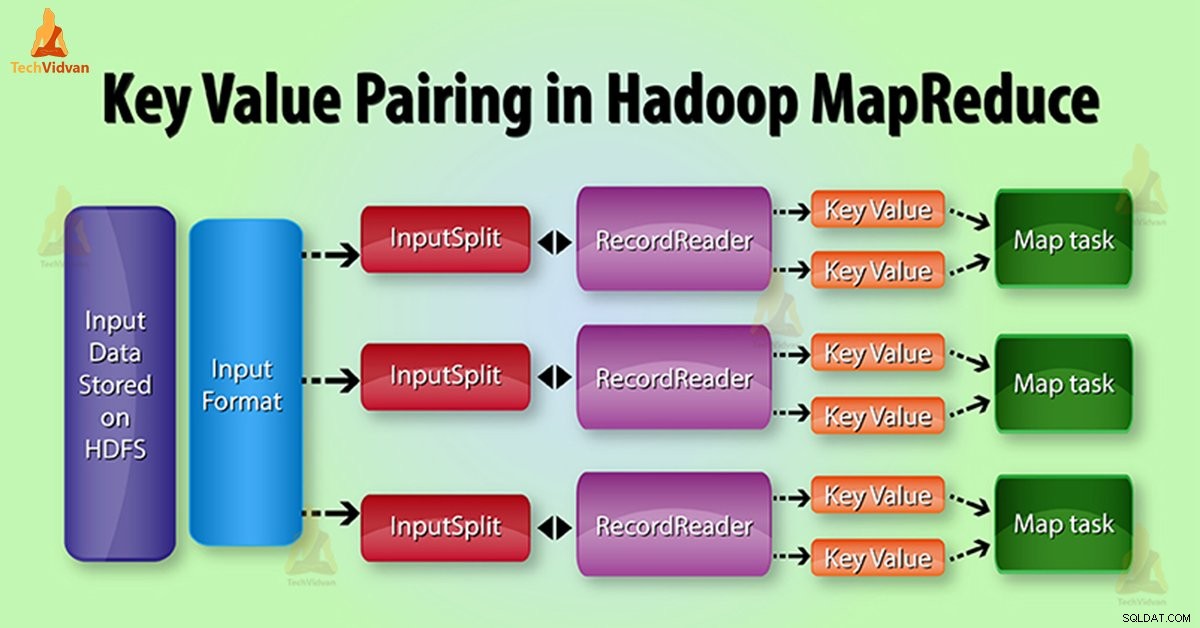
HadoopでのMapReduceキー値ペアの生成
MapReduceジョブの実行で、データをマッパーに送信する前 、最初にそれをキーと値のペアに変換します。マッパーはデータのキーと値のペアのみであるため。
MapReduceのキーと値のペアは次のように生成されます:
InputSplit – これは、 InputFormatが使用するデータの論理表現です。 を生成します。 MapReduceプログラムでは、単一のマップタスクを含む作業単位を記述します。
RecordReader – InputSplitと通信します。その後、データをマッパーによる読み取りに適したキーと値のペアに変換します。 RecordReaderは、デフォルトでTextInputFormatを使用してデータをキーと値のペアに変換します。
MapReduceジョブの実行では、map関数は特定のキーと値のペアを処理します。次に、特定の数のキーと値のペアを発行します。削減機能は、同じキーでグループ化された値を処理します。
次に、別のキーと値のペアのセットを出力として出力します。 Mapの出力タイプは、以下に示すように、Reduceの入力タイプと一致する必要があります。
- 地図: (K1、V1)->リスト(K2、V2)
- 削減: {(K2、リスト(V2})->リスト(K3、V3)
Hadoopで生成されるキーと値のペアはどのような基準で生成されますか?
MapReduce Key-Valueペアの生成は、データセットに完全に依存します。また、必要な出力によって異なります。フレームワークは、キーと値のペアを4つの場所で指定します:マップ入力/出力、リデュース入力/出力。
1。マップ入力
マップ入力は、デフォルトでラインオフセットをキーとして使用します。行の内容はテキストとしての値です。それらを変更できます。カスタム入力形式を使用します。
2。マップ出力
マップはデータをフィルタリングする責任があります。また、キーに基づいてデータをグループ化するための環境も提供します。
- キー– リデューサーでデータがグループ化および集計されるのは、フィールド/テキスト/オブジェクトです。 。
- 価値– これは、各個人がメソッドのハンドルを減らすフィールド/テキスト/オブジェクトです。
3。入力を減らす
マップ出力は縮小するために入力されます。つまり、Map-Outputと同じです。
4。出力を減らす
必要な出力に完全に依存します。
MapReduceのキーと値のペアの例
たとえば、 HDFSであるファイルのコンテンツ 店舗はチャンドラーはジョーイマークはジョンです 。したがって、ここでInputFormatを使用して、このファイルがどのように分割されて読み取られるかを定義します。デフォルトでは、RecordReaderはTextInputFormatを使用して、このファイルをキーと値のペアに変換します。
- キー– ファイル内の行頭のオフセットです。
- 価値– これは、ラインターミネータを除くラインの内容です。
ここで、キー は0で、値 チャンドラーはジョーイマークはジョンです。
結論
結論として、key-valueは、MapReduceが実行のために受け入れる単なるレコードエンティティであると言えます。 InputSplitとRecordReaderは、キーと値のペアを生成します。したがって、キーはバイトオフセットであり、値は行の内容です。
あなたがこのブログを気に入ってくれたことを願っています。 MapReduceのキーと値のペアに関連する提案やクエリがある場合は、以下のセクションにコメントを残してください。