SantanderUKでApacheFlume、Apache Kafka、およびRocksDBを使用してデータストリームを変換および強化するためのほぼリアルタイムのデータ取り込みアーキテクチャについて学びます。
Cloudera Professional Servicesは、Santander UKと協力して、Apache Hadoop上にほぼリアルタイム(NRT)のトランザクション分析システムを構築しています。目的は、カードの購入が行われてから数秒以内にトランザクションをキャプチャ、変換、強化、カウント、および保存することです。システムは、銀行の小売顧客カードトランザクションを受信し、アカウント所有者によって、およびいくつかのディメンションと分類法にわたって集計された関連するトレンド情報を計算します。この情報は、サンタンデールの「Spendlytics」アプリ(以下を参照)に安全に提供され、顧客が最新の支出パターンを分析できるようにします。
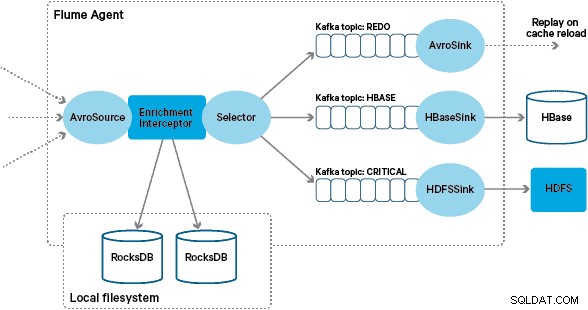
Apache HBaseは、高スループットのランダム書き込みと低遅延のランダム読み取りをサポートできるため、基盤となるストレージソリューションとして選択されました。ただし、NRT要件では、トランザクションの変換とエンリッチメントをバッチで実行することは除外されているため、トランザクションがHBaseにストリーミングされている間にこれらを実行する必要があります。これには、メッセージをXMLからAvroに変換し、ブランドや販売者の情報などのトレンド可能な情報でメッセージを充実させることが含まれます。
この投稿では、SantanderがApache Flume、Apache Kafka、およびRocksDBを使用して、トランザクションをHBaseに変換、強化、およびストリーミングする方法について説明します。これは、外部コンテキストを使用したNRTイベント処理の実装です。 この投稿でテッドマラスカによって説明されたストリーミングパターン。
フラフカ
サンタンデールが最初に決定しなければならなかったのは、データをHBaseにストリーミングする最善の方法でした。 Flumeは、そのシンプルさ、信頼性、豊富なソースとシンクの配列、および固有のスケーラビリティを考慮すると、ほとんどの場合、Hadoopへの取り込みをストリーミングするための最良の選択です。
最近、Kafkaへの優れた統合が追加され、必然的に名前が付けられたFlafkaになりました。 Flumeは、ファイルチャネルを介して保証されたイベント配信をネイティブに提供できますが、イベントを再生する機能と、Kafkaがもたらす柔軟性と将来性の向上が、統合の重要な推進力でした。
このアーキテクチャでは、SantanderはKafkaチャネルを使用して、信頼性が高く、自己バランスが取れた、スケーラブルな取り込みバッファを提供します。このバッファでは、すべての変換と処理が連鎖したKafkaトピックで表されます。特に、Flafkaのソースとシンク、およびInterceptorsを使用して飛行中の処理を実行するFlumeの機能を幅広く活用しています。これにより、独自のKafkaプロデューサーとコンシューマーをコーディングする必要がなくなり、SantanderはCloudera Managerを最大限に活用して、エージェントとブローカーを構成、デプロイ、監視できるようになりました。
変換
勘定系システムによってキャプチャされたトランザクションは、ログレプリケーションを介してソースデータベースから読み取られたXMLメッセージとしてFlumeに配信されます。 (この方法でデータベースログをKafkaトピックに結び付けることは、ますます一般的なパターンであり、ログの圧縮と組み合わせると、変更データキャプチャのユースケースのためにデータベースの「最新のビュー」を提供できます。)
Flumeは、これらのXMLメッセージを「生の」Kafkaトピックに保存します。ここから、そして他のすべての処理の前身として、標準化されたダウンストリーム処理を容易にするために、半構造化XMLを構造化バイナリレコードに変換することが決定されました。この処理は、XMLメッセージを汎用のAvro表現に変換するカスタムFlume Interceptorによって実行され、必要に応じて特定のタイプを適用し、そうでない場合は文字列表現にフォールバックします。その後のすべてのNRT処理では、派生した結果が専用のKafkaトピックにAvroに保存されるため、処理チェーンの任意の時点でストリームを利用してイベントフィードを簡単に取得できます。
より複雑なイベント処理が必要な場合(たとえば、Spark Streamingを使用した集約)、これらのトピックの1つ以上を消費し、新しい派生トピックに公開するのは簡単なことです。 (Apache Avroは、この形式の自然な選択です。これは、スキーマの進化をサポートするコンパクトなバイナリプロトコルであり、柔軟なスキーマ定義を持ち、Hadoopスタック全体でサポートされます。Avroは、エンタープライズデータハブであり、分析ワークロード用のApache Parquetへの変換に最適です。)
エンリッチメント
ストリーミングエンリッチメントソリューションの設計のインスピレーションは、Jay Krepsによって書かれたO’ReillyRadarの投稿から得られました。ジェイは彼の投稿で、ローカルストアを使用して、分散データベースにリモート呼び出しを行うのではなく、ストリームプロセッサが入力に応じてローカル状態をクエリまたは変更できるようにすることの利点について説明しています。
サンタンデールでは、このパターンを採用して、Flumeを介してストリーミングするトランザクションのクエリと強化に使用されるローカルリファレンスストアを提供しました。なぜHBaseをリファレンスストアとして使用しないのですか?このタイプの問題の典型的なパターンは、単純に状態をHBaseに格納し、エンリッチメントメカニズムに直接クエリを実行させることです。いくつかの理由で、このアプローチに反対することにしました。まず、参照データは比較的小さく、単一のHBaseリージョンに収まり、リージョンのホットスポットが発生する可能性があります。次に、HBaseは顧客向けのSpendlyticsアプリにサービスを提供し、Santanderは追加の負荷がアプリのレイテンシーに影響を与えることを望んでいませんでした。これが、起動時にローカルストアをブートストラップするためにHBaseを使用しないことにした理由でもあります。
そのため、サンタンデールは、飛行中のイベントを充実させるための高速なローカルストアを各Flume Agentに提供することで、飛行中の強化とSpendlyticsアプリの両方に対してより優れたパフォーマンス保証を提供できます。 RocksDBを使用してローカルストアを実装することにしました。これは、大量のオフヒープデータへの高速アクセスを提供でき(GCの負担を排除)、Java APIを備えているため、カスタムFlumeインターセプター。このアプローチにより、独自のオフヒープストアをコーディングする必要がなくなりました。 RocksDBは、別のローカルストアの実装に簡単に交換できますが、この場合、Santanderのユースケースに最適でした。
カスタムFlumeエンリッチメントインターセプターの実装は、アップストリームの「変換された」トピックからのイベントを処理し、ローカルストアにクエリを実行してイベントをエンリッチメントし、結果に応じて結果をダウンストリームのKafkaトピックに書き込みます。このプロセスについては、以下で詳しく説明します。
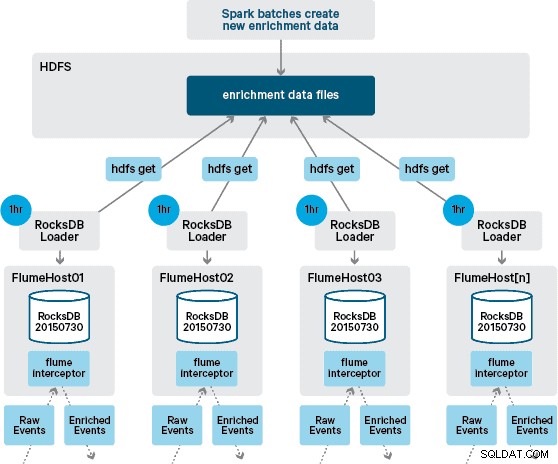
この時点で、疑問に思われるかもしれません。HBaseが提供する永続性がない場合、ローカルストアはどのように生成されますか?参照データは、結合する必要のあるさまざまなデータセットで構成されています。これらのデータセットはHDFSで毎日更新され、RocksDBストアを生成するスケジュールされたApacheSparkアプリケーションへの入力を形成します。新しく生成されたRocksDBストアは、Flume Agentによってダウンロードされるまで、HDFSでステージングされ、イベントストリームが最新の情報で強化されていることを確認します。
理想的には、これらのデータセットがすべてHDFSで利用可能になるのを待ってから、処理する必要はありません。この場合、参照データの更新をFlafkaパイプラインを介してストリーミングして、ローカルの参照データの状態を継続的に維持できます。
最初の設計では、cronを介してHDFSをポーリングし、RocksDBストアの新しいバージョンをチェックし、利用可能な場合はHDFSからダウンロードするスクリプトを作成してスケジュールすることを計画していました。 Santanderの本番環境の内部統制とガバナンスのために、このメカニズムは、エンリッチメントの実行に使用されるのと同じFlume Interceptorに組み込む必要がありました(1時間に1回更新をチェックするため、コストのかかる操作ではありません)。ストアの新しいバージョンが利用可能になると、タスクがワーカースレッドにディスパッチされ、HDFSから新しいストアをダウンロードしてRocksDBにロードします。このプロセスは、エンリッチメントインターセプターがストリームを処理し続けている間、バックグラウンドで発生します。ストアの新しいバージョンがRocksDBにロードされると、Interceptorは最新バージョンに切り替わり、期限切れのストアは削除されます。同じメカニズムを使用して、Interceptorがイベントの強化を開始する前に、コールドスタートアップからRocksDBストアをブートストラップします。
正常に強化されたメッセージはKafkaトピックに書き込まれ、HBaseEventSerializerを使用してHBaseに直接書き込まれます。
イベントストリームは継続的に処理されますが、ローカルストアの新しいバージョンは毎日しか生成できません。ローカルストアの新しいバージョンがFlumeによってロードされた直後は、フレッシュと見なされます。」ただし、新しいバージョンが利用可能になる前に、ローカルストアはますます古くなっています。その結果、ローカルストアの新しいバージョンが利用可能になるまで、「キャッシュミス」の数が増加します。たとえば、新規および更新されたブランドおよびマーチャント情報を参照データに追加できますが、Flumeのエンリッチメントで利用できるようになるまで、Interceptorトランザクションはエンリッチメントに失敗するか、後で必要になる古い情報でエンリッチメントされる可能性があります。 HBaseで永続化された後に調整されました。
このケースを処理するために、キャッシュミス(エンリッチに失敗したイベント)は、FlumeSelectorを使用して「やり直し」Kafkaトピックに書き込まれます。その後、新しいローカルストアが利用可能になると、やり直しトピックがエンリッチメントインターセプターのソーストピックに再生されます。
「ポイズンメッセージ」(継続的にエンリッチメントに失敗するイベント)を防ぐために、REDOトピックに追加する前に、イベントのヘッダーにカウンターを追加することにしました。そのトピックに繰り返し表示されるイベントは、最終的に「重要な」トピックにリダイレクトされ、後で検査および修正するためにHDFSに書き込まれます。このアプローチは最初の図に示されています。
結論
この投稿からの主なポイントを要約すると:
- Kafkaトピックのチェーンを使用して、取り込みパイプラインの一部として中間共有データを保存することは効果的なパターンです。
- NRT取り込みパイプラインで状態または参照データを永続化および照会するための複数のオプションがあります。補足データが大きい場合の一般的なパターンとして、この目的のためにHBaseを優先しますが、HBaseを使用する場合は、組み込みローカルストア(RocksDBなど)またはJVMメモリの使用を検討してください。
- 障害の処理は重要です。 (そのヘルプについては、#1を参照してください。)
フォローアップの投稿では、HBaseコプロセッサーを使用して、過去の購入傾向の顧客ごとの集計を提供する方法と、(Cloudera Labsプロジェクト)SparkOnHBase(最近コミットされた)を使用してオフライントランザクションをバッチで処理する方法について説明します。 HBaseトランク)。また、お客様のクロスデータセンターの高可用性要件を満たすようにソリューションがどのように設計されたかについても説明します。
James Kinley、Ian Buss、RobSiwickiはClouderaのソリューションアーキテクトです。